- The paper introduces a memory-based multi-agent paradigm that integrates hierarchical global memory for consistent graph construction and effective conflict resolution.
- It demonstrates improved QA accuracy with a 2.10% gain over state-of-the-art baselines and achieves an average retrieval latency of 0.061 seconds.
- By merging semantic, logical, and structural cues through coordinated agents, the approach reduces noise and enhances multi-hop reasoning for LLMs.
Memory-based Multi-Agent GraphRAG: The MemGraphRAG Paradigm
Introduction and Motivation
The development of Retrieval-Augmented Generation (RAG) addresses hallucination and factual consistency in LLMs by conditioning generation on retrieved external knowledge. Standard RAG approaches, however, are limited when dealing with fragmented, large-scale, and unstructured corpora that require robust cross-document reasoning and structural disambiguation. Graph-based RAG (GraphRAG) emerged to inject relational structure into the retrieval process, using knowledge graphs (KGs) to scaffold multi-hop retrieval. Nonetheless, existing GraphRAG pipelines frequently perform extraction and indexing locally at the chunk level, failing to maintain a global context, resulting in noisy, logically inconsistent, and fragmented graphs that degrade downstream reasoning and generation.
MemGraphRAG (2606.00610) systematically analyzes these deficiencies and introduces a memory-based multi-agent paradigm for graph construction and retrieval, leveraging a globally consistent multi-tier memory and agent collaboration to iteratively mediate extraction, conflict resolution, and retrieval.
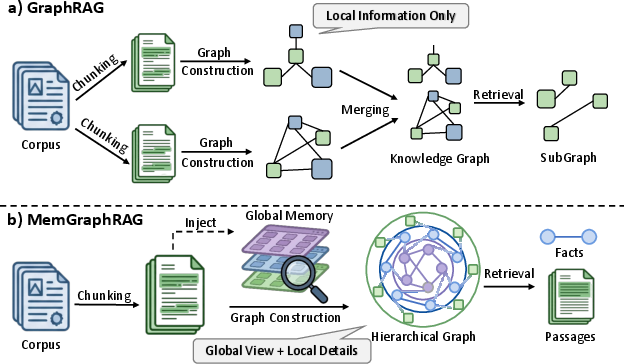
Figure 1: Comparison between existing GraphRAG, which performs isolated chunk-level extraction (left), and MemGraphRAG, which incorporates global memory for consistent indexing (right).
Failure Modes in Existing GraphRAG
Initial empirical analysis demonstrates that representative GraphRAG systems can achieve higher evidence recall relative to vanilla RAG but suffer significant drops in relevance, frequently retrieving irrelevant or contradictory facts due to the isolation of extraction steps. Removing low-frequency (i.e., thematically irrelevant) triples improves accuracy, confirming that thematic irrelevance is endemic to local extraction. Furthermore, the study formally identifies three principal conflict types that undermine the constructed graphs: mutually exclusive (logical) conflicts, temporal conflicts due to time-variant facts without grounding, and granularity conflicts from inconsistent abstraction.
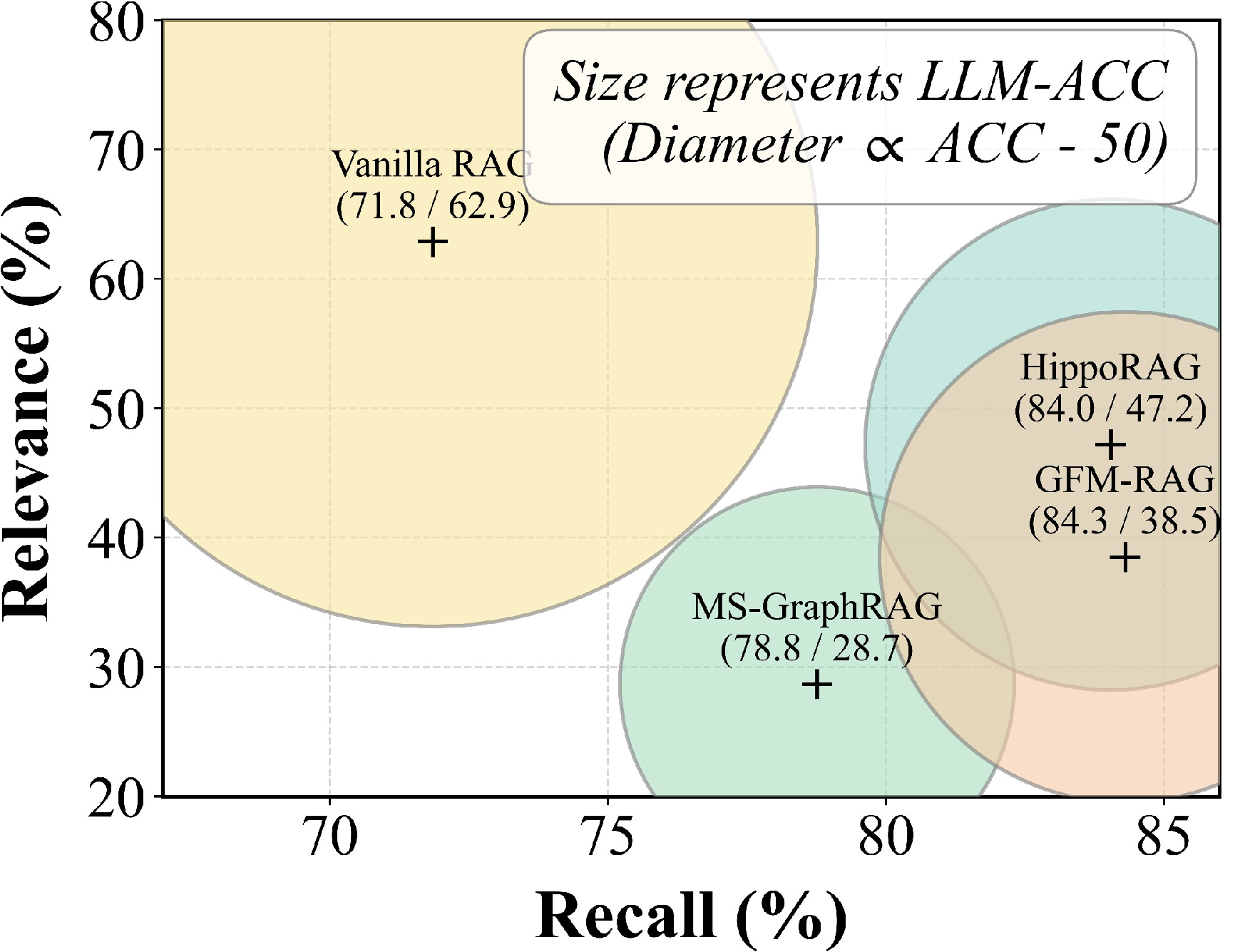
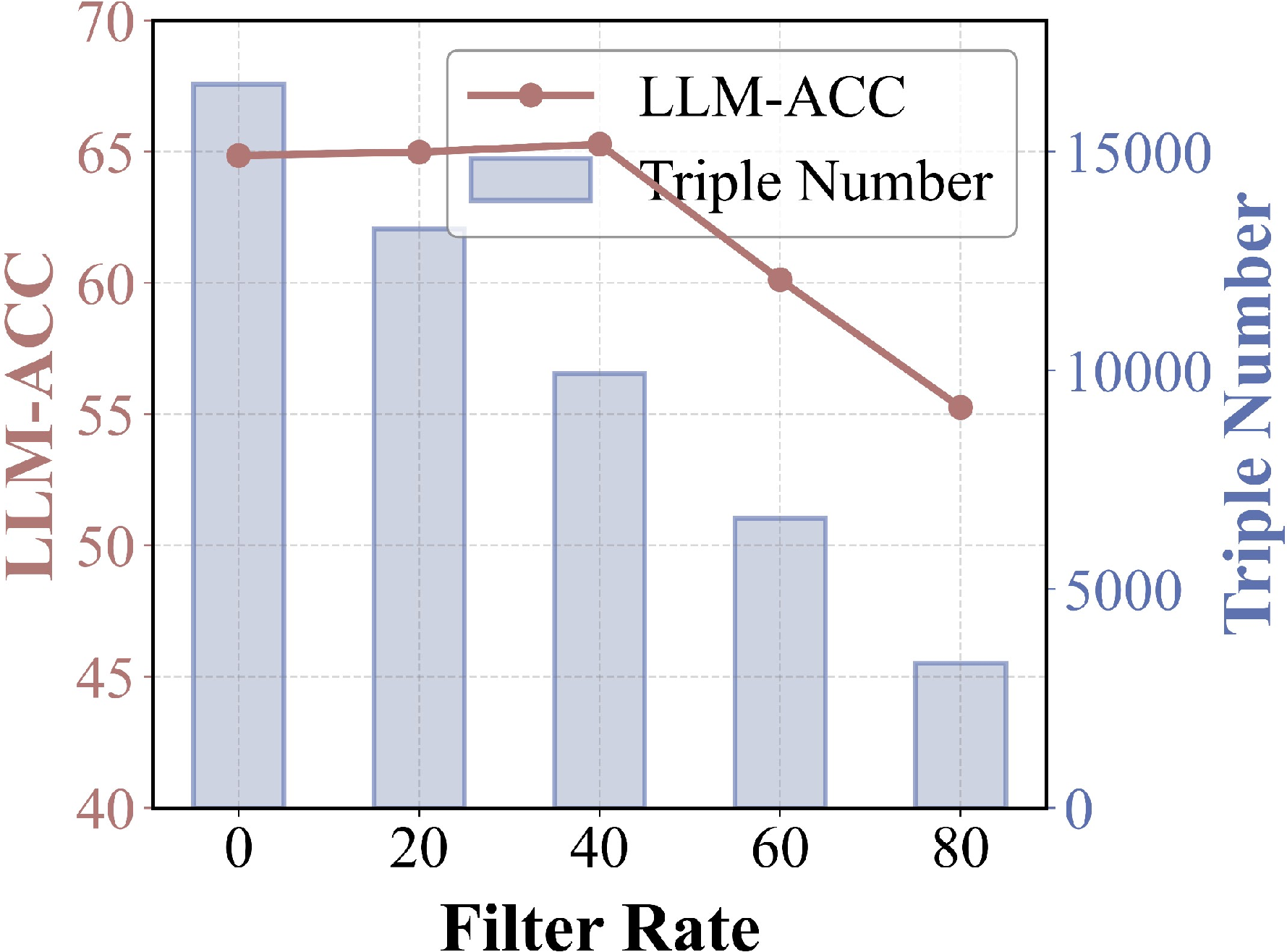
Figure 2: Left: Evaluation of representative RAG and GraphRAG systems, showing the trade-off between recall and relevance. Right: Accuracy gains from filtering irrelevant triples using schema frequency.
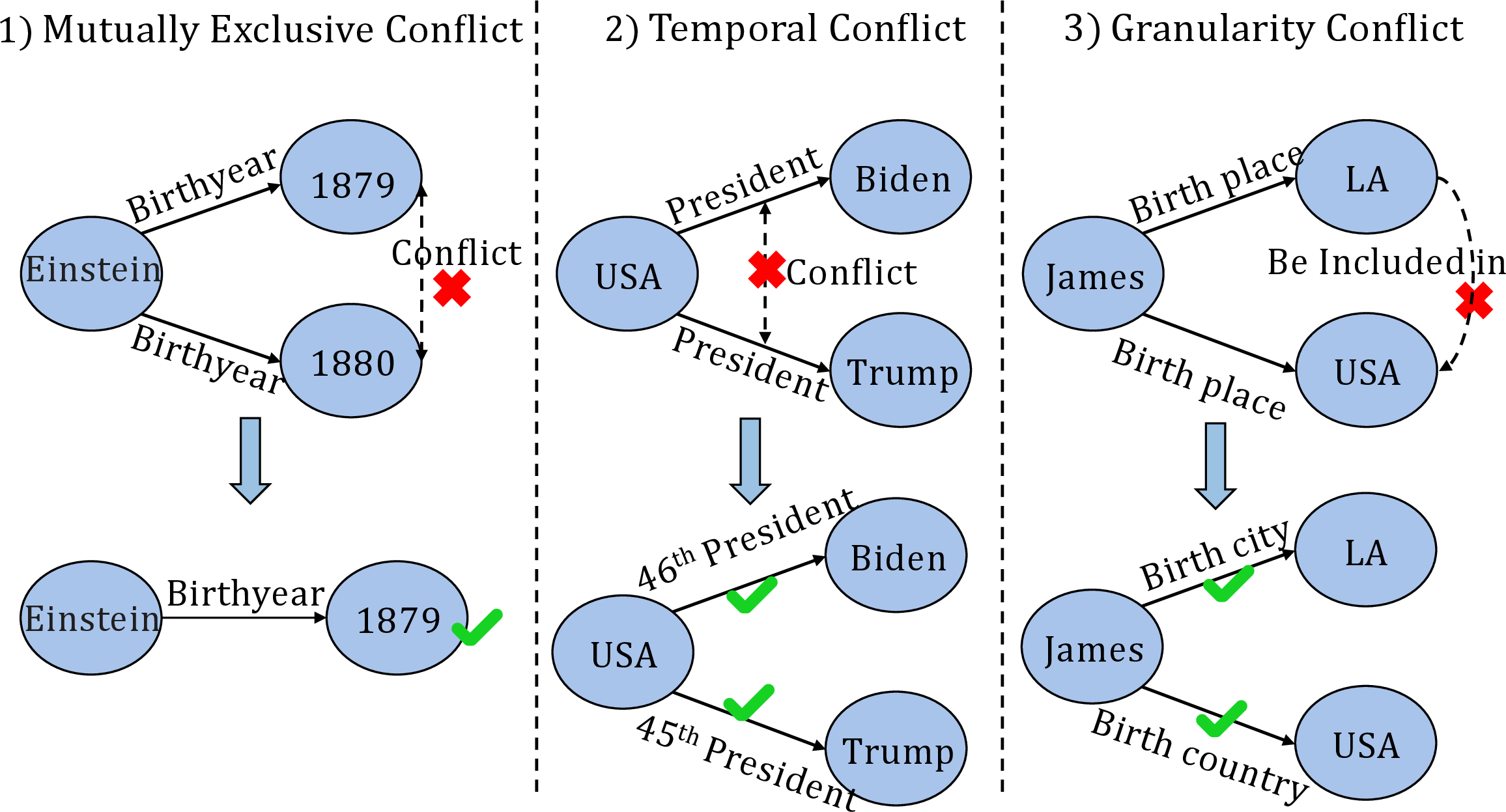
Figure 3: Examples of mutually exclusive, temporal, and granularity conflicts apparent in graphs derived from local extraction.
These observations clarify that high evidence recall in local-extraction-based GraphRAG comes at the expense of semantic focus and logical consistency, directly degrading LLM answer quality.
The MemGraphRAG Architecture
To address these challenges, MemGraphRAG proposes a memory-based multi-agent system with three core components:
- Hierarchical Global Memory (M): Knowledge is segmented into ontology (schemas and type constraints), fact (triple assertions), and passage (raw evidence) layers. Bidirectional mappings reinforce schema-instance alignment and evidence grounding. Only schema patterns with sufficient support (above a frequency threshold) are promoted to "stable" and serve as anchors for fact activation.
- Multi-Agent Group: Separate agents manage extraction (Aext), monitor for redundancy and semantic conflict (Adet), and execute evidence-based conflict resolution (Ares) with persistent access to the global memory. This separation enables reliable detection and correction of inconsistency as the index evolves.
- Hierarchical Indexing Graph (G): The memory contents are projected into a unified graph with complementary semantic, fact, and evidence views, supporting traversal from abstract schema to evidence-grounded facts.
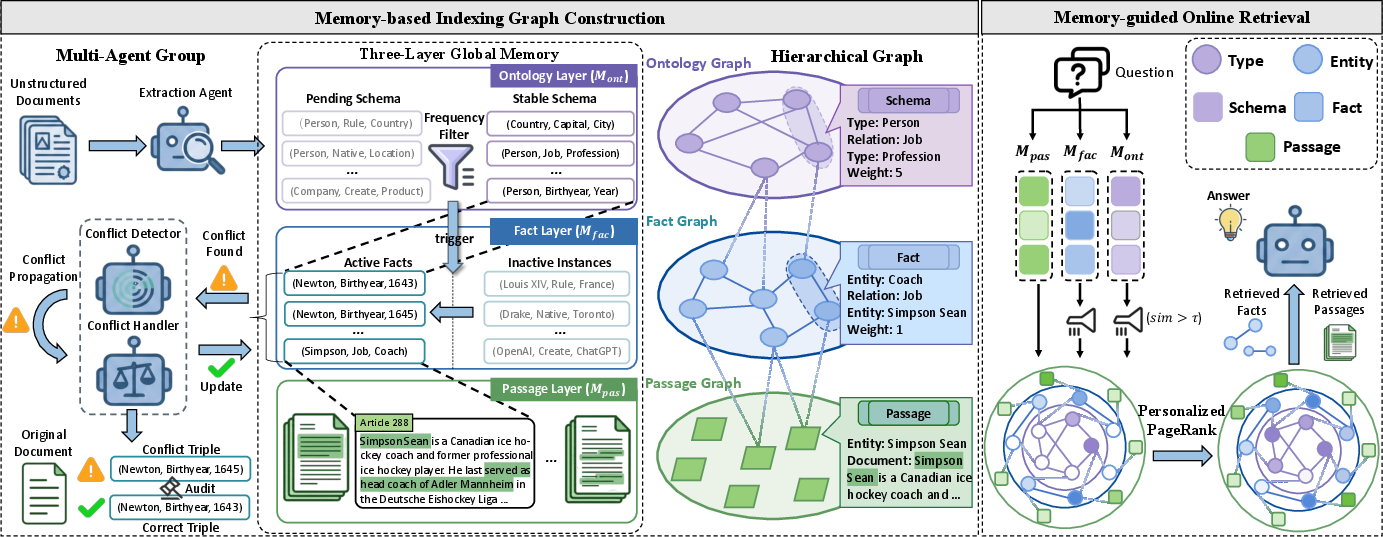
Figure 4: Overview of MemGraphRAG's two phases: memory-based graph construction with continual global adjudication, and memory-guided retrieval via personalized graph propagation.
Graph Construction Workflow
The construction process comprises iterative "extract--verify--modify" cycles, implemented as follows:
- Thematic Denoising: Only schema types with corpus-wide support are activated, and unstable, rare extraction hypotheses are filtered out. This directly addresses thematic irrelevance.
- Consistency Maintenance: On triple activation, agents detect logical, temporal, or granularity conflicts by cross-scanning the existing fact memory. Detected conflicts are resolved by adjudicating among source passages, promoting only consistent facts or updating facts with temporal or granular qualifiers as appropriate.
- Structural Bridging: The system connects disjoint subgraphs using type- and embedding-based similarity, emphasizing long-range entity alignment and reducing graph fragmentation.
Online Retrieval and Reasoning
Inference in MemGraphRAG proceeds via hierarchical, memory-informed multi-hop retrieval:
- Multi-Layer Memory Querying: Queries retrieve candidate schemas, facts, and passages in parallel, with pre-filtering on semantic similarity.
- Structure-Aware Node Initialization: Initial node weights on the graph reflect not only semantic alignment to the query but schema and passage information density. High-degree hubs are structurally regularized to prevent semantic drift.
- Personalized PageRank Propagation: Query importance is diffused across the hierarchical graph to surface both passages and entities with maximal global support for the given question.
Empirical Results and Ablation
MemGraphRAG achieves consistently state-of-the-art QA accuracy across standard multi-hop QA and domain-specific benchmarks, e.g., 59.25% average accuracy, with 2.10% absolute gain over the best previous GraphRAG baseline. Evidence recall and relevance are jointly maximized. Notably, retrieval latency is further minimized, with MemGraphRAG's average retrieval taking only 0.061 seconds, an order of magnitude faster than comparable models.
Strong claims include MemGraphRAG's persistent improvements even when its constructed index graphs are "plugged into" third-party GraphRAG retrievers—demonstrating universality as a foundational graph constructor. Ablation reveals that unified schema filtering, conflict resolution, hub suppression, and IDF-based evidence weighting are all necessary to achieve the observed gains.
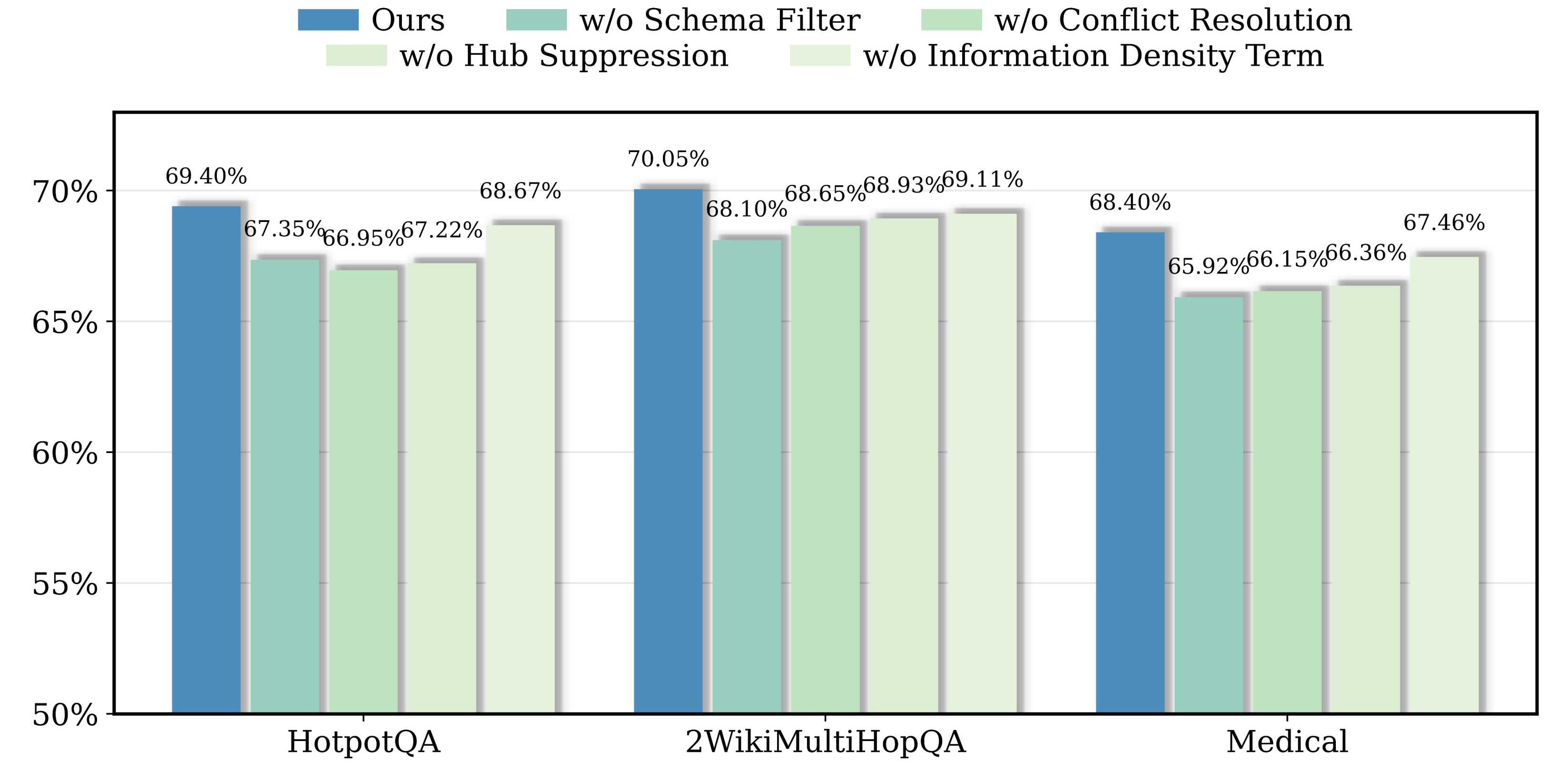
Figure 5: Ablation study showing the impact of disabling each module on multi-hop QA datasets; all memory-driven components contribute materially to final performance.
Graph Quality Analysis
MemGraphRAG's graphs exhibit increased average degree and higher clustering coefficients versus prior baselines, confirming dense connectivity, reduced fragmentation, and enhanced semantic clustering. Qualitative case studies further show its ability to resolve contradictory facts and filter noisy, off-topic schema extractions, yielding more focused and reliable retrieval process for downstream LLMs.

Figure 6: Multi-dimensional radar assessment of graph topological properties, highlighting improved connectivity and semantic coherence in MemGraphRAG’s output.
Implications and Future Directions
MemGraphRAG’s paradigm of continual extraction, conflict resolution, and global memory integration directly reciprocates the needs of RAG systems supporting complex domain-specific and multi-hop inference tasks in LLMs. Its decoupling of semantic, logical, and structural quality via explicit memory and agentic roles is highly extensible and can potentially generalize to multi-modal graph indexing.
The current limitation to text-only inputs leaves open the prospect of integrating visual, structural, and tabular modalities at the memory and graph levels, which would permit verification of cross-modal claims and robust evidence chaining, thus narrowing LLM hallucination risks in practical deployment.
Conclusion
MemGraphRAG establishes a robust and efficient baseline for memory-enriched, graph-based RAG by introducing hierarchical, globally supervised graph construction and online retrieval. It overcomes the fundamental trade-offs suffered by previous GraphRAG systems, markedly enhancing graph quality, retrieval accuracy, and answer generation, and provides a universal, plug-and-play indexing solution for downstream retrieval and reasoning frameworks. Its architecture and insights set a new empirical and conceptual foundation for future advances in hybrid retrieval-generation paradigms in LLM-based systems.

