- The paper introduces a novel hierarchical multimodal knowledge graph that fuses text and visual data to support scalable and interpretable reasoning.
- It employs lightweight dependency parsing and open-vocabulary segmentation to bypass costly extraction methods and preserve atomic visual information.
- Empirical results highlight significant boosts in retrieval, VQA, and classification tasks, reducing processing time and cost by up to 77× and 45× respectively.
MG2-RAG: Multi-Granularity Graph Construction for Multimodal Retrieval-Augmented Generation
Introduction and Motivation
The MG2-RAG framework represents a significant advance in multimodal retrieval-augmented generation (MM-RAG) for Multimodal LLMs (MLLMs). While prior MM-RAG systems partially mitigate generation hallucinations by retrieving external evidence, they frequently rely on vector-based retrieval approaches or costly and lossy graph construction pipelines. Vector-based retrieval decomposes complex queries into isolated multimodal elements, discarding structure and limiting cross-modal and multi-hop reasoning. Conversely, graph-based MM-RAG methods often depend on translation-to-text pipelines and MLLM-based triplet extraction, resulting in high financial and computational overhead while losing essential atomic-level visual information.
MG2-RAG eliminates these bottlenecks through an efficient hierarchical multimodal knowledge graph (MMKG) construction protocol and a unified, multi-granularity retrieval and reasoning mechanism. The methodology enables scalable, interpretable, structured reasoning over both text and vision, directly addressing deficiencies in both semantic abstraction and practical deployment.
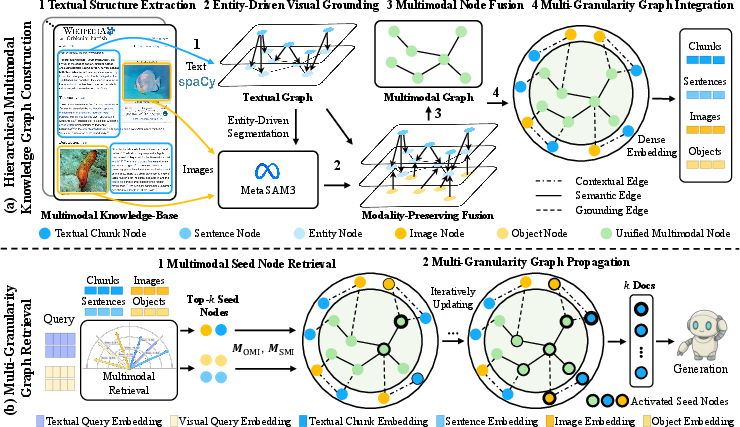
Figure 1: Framework overview showing efficient construction and graph-driven multi-granularity retrieval supporting MLLM generation.
Hierarchical Multimodal Knowledge Graph Construction
MG2-RAG's MMKG construction process is centered on two core insights: lightweight, high-fidelity extraction and native multimodal node fusion. Textual parsing leverages transformer-based spaCy dependency analysis to extract entity sets and parse sentence-level structure efficiently, circumventing the cost and error rates of LLM-based OpenIE. Visual grounding is realized via semantic prompts into an open-vocabulary segmentation model (SAM3), enabling direct localization of entity-relevant regions instead of global image captioning.
Unified multimodal nodes are created by fusing textual entities with their grounded visual segments. Incidence matrices link objects-to-multimodal nodes and sentences-to-multimodal nodes, explicitly preserving fine-grained provenance and narrative context. Graph topology is encoded at three hierarchical levels: document chunks, images, and unified multimodal nodes. Edges span contextual provenance, syntactic dependencies (between multimodal nodes), and visual grounding with confidences to the source images.
This design results in a hierarchical heterogeneous MMKG reflecting atomic evidence from text and vision, while maintaining the contextual and relational information necessary for effective retrieval and complex reasoning.
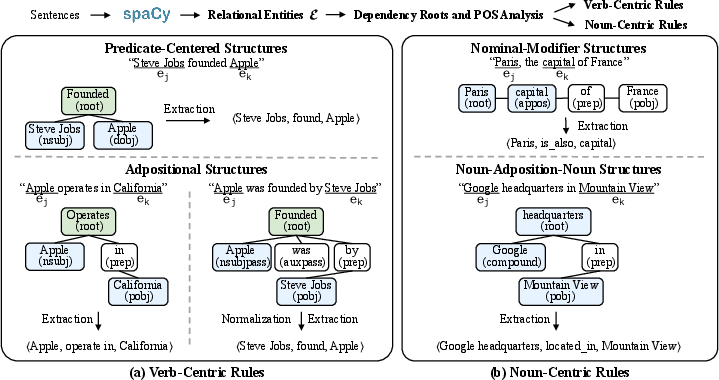
Figure 3: Schematic of rule-based relation extraction, showcasing verb-centric (syntactic predicate) and noun-centric (nominal/adpositional) mechanisms used in lightweight textual graph construction.
Multi-Granularity Retrieval and Reasoning
MG2-RAG’s retrieval architecture deploys staged evidence activation and propagation. Candidate seed nodes are selected via text and/or visual queries, activating relevance at all semantic levels (sentences, chunks, images, objects) leveraging dense joint embedding spaces (EVA-CLIP-8B). These scores are aggregated—using modality-specific weights and top-k pooling—onto the unified multimodal node layer.
Relevance is then propagated through the graph structure using Personalized PageRank, achieving multi-hop, structure-aware evidence diffusion in contrast to the shallow similarity search of vector-based systems. Final chunk-level relevance scores support the selection of supporting context for MLLM prompts.
This process produces improved retrieval granularity and structurally-grounded multi-hop reasoning—a requirement for knowledge-based VQA, scientific QA, and noise-robust multimodal classification.

Figure 4: Case studies on VQA/multimodal retrieval; MG2-RAG retrieves atomic multimodal evidence critical for factual, detailed answers, outperforming vanilla MLLMs and prior graph approaches.
Empirical Results and Comparative Analysis
MG2-RAG establishes new state-of-the-art performance across diverse multimodal task classes: entity-centric multimodal retrieval, knowledge-based VQA (E-VQA, InfoSeek), scientific reasoning (ScienceQA), and noisy multimodal classification (CrisisMMD). Gains are significant and stable across both zero-shot and RAG-augmented scenarios.
Key empirical highlights:
- Retrieval: On E-VQA and InfoSeek, MG2-RAG consistently achieves the best Recall@K scores, outperforming both cross-modal retrieval baselines (EVA-CLIP-8B) and previous graph-based systems (mKG-RAG) by substantial margins (e.g., +9.9 absolute at R@1 on InfoSeek).
- VQA: Strong improvements are observed over both vanilla MLLMs (e.g., Qwen3.5-27B, GPT-5.2) and retrieval-augmented methods (EchoSight, RORA-VLM), attaining, for instance, 60.24 on E-VQA (5k) and 42.26 on InfoSeek (5k) with Qwen3.5-27B.
- Reasoning: On ScienceQA, MG2-RAG with advanced MLLMs surpasses even human benchmarks and provides significant boosts in structured reasoning (from 89.25 in MMGraphRAG to 97.85 with Qwen3.5-27B).
- Classification: Robustness under real-world noise is demonstrated on CrisisMMD, with MG20-RAG achieving top average accuracy using both LLM and MLLM backbones (e.g., 61.7 with GPT-5.2).
Crucially, these gains are achieved with striking practical advantages: graph construction is up to 21 faster and 22 less costly (average 23 speedup, 24 cost reduction) than systems that rely on MLLM triplet extraction, demonstrating real viability for large-scale, continual knowledge augmentation.
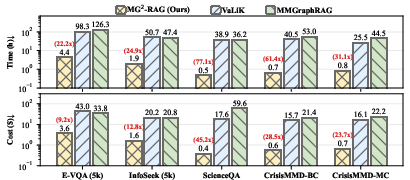
Figure 2: Construction time and cost for MG25-RAG versus strong baselines; efficiency gains typically exceed 26.
Case Studies and Structural Inspectability
Qualitative analysis reveals that MG27-RAG effectively links questions to fine-grained atomic evidence, supporting reliable, interpretable reasoning even when queries require aggregation across modalities or multiple relational hops. Unlike baseline MLLMs prone to hallucinations or generic answers, MG28-RAG provides answers substantiated by explicit visual and textual context.
This is observed across domains:
- Knowledge-based VQA where factual details (e.g., precise measurements, named entities) are required.
- ScienceQA, where retrieval and reasoning must connect rules, diagrams, and descriptive passages.
- CrisisMMD, where contextual disambiguation is required under adversarial real-world noise.

Figure 5: Qualitative examples on multimodal science reasoning, illustrating structured retrieval and evidence aggregation.

Figure 6: Qualitative results for classification under noisy real-world conditions, highlighting robust cross-modal context utilization.
Implications and Future Directions
MG29-RAG demonstrates the critical role of structure-centric, multi-granularity evidence modeling in MM-RAG. By unifying text and vision at the node level and leveraging lightweight, interpretable relation extraction, the framework circumvents traditional tradeoffs between semantic richness, retrieval precision, and scalability.
The system directly facilitates robust, cost-effective continual learning, lifelong knowledge augmentation, and explainable reasoning essential for MLLM deployment in high-stakes and dynamic real-world environments. Its methodology is well-positioned for further advances in:
- Domain adaptation and privacy-preserving personalized knowledge augmentation via scalable graph construction.
- Online graph expansion and incremental evidence integration.
- Advanced graph propagation algorithms enabling even deeper, dynamic, and context-specific multi-hop reasoning.
- The integration of more granular object-centric visual detectors and task-conditional edge weighting for adaptive retrieval.
Conclusion
MG20-RAG provides a unified, efficient, and scalable solution for multimodal retrieval-augmented generation, demonstrating clear superiority in both accuracy and practical deployment metrics. By harmonizing lightweight multimodal graph construction with structured, multi-granularity retrieval and reasoning, the framework delivers robust, interpretable, and high-fidelity MLLM outputs for knowledge-intensive applications. This design paradigm paves the way for the next generation of modular, structure-aware AI systems capable of reliable multimodal evidence synthesis and reasoning in real-world environments.