Mellum2 Technical Report
Abstract: We present Mellum 2, an open-weight 12B-parameter Mixture-of-Experts (MoE) LLM with 2.5B active parameters per token. Mellum 2 is a general-purpose LLM specialized in software engineering, spanning code generation and editing, debugging, multi-step reasoning, tool use and function calling, agentic coding, and conversational programming assistance, and it is the successor to the completion-focused 4B dense Mellum model. The architecture builds on the Mixture-of-Experts (64 experts, 8 active) and combines Grouped-Query Attention with 4 KV heads, Sliding Window Attention on three of every four layers, and a single Multi-Token Prediction head that doubles as both an auxiliary pre-training objective and a built-in draft model for speculative decoding; each choice was validated by ablation with inference efficiency on commodity GPUs as a design constraint. Pre-training spans approximately 10.6 trillion tokens through a three-phase curriculum that progressively shifts the mixture from diverse web data toward curated code and mathematical content, optimized with Muon under FP8 hybrid precision and a Warmup-Hold-Decay schedule with linear decay to zero. The pre-trained base is extended to a 128K context window via a layer-selective YaRN and then post-trained in two stages (supervised fine-tuning followed by RLVR), yielding two released variants: an Instruct model that answers directly and a Thinking model that emits an explicit reasoning trace before its final answer. Across code generation, math and reasoning, tool use, knowledge, and safety benchmarks, Mellum 2 is competitive with open-weight baselines in the 4B-14B range while running at the per-token compute of a 2.5B dense model. We release the base, instruct, and thinking checkpoints, together with this report on the architecture decisions, data pipeline, and training recipe behind them, under the Apache 2.0 license.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Mellum 2, a new open-source AI LLM designed to help with software engineering. It can write and edit code, find bugs, plan multi-step tasks, use tools, and chat about programming. The big idea is to get strong coding and reasoning skills without making the model too slow or expensive to run.
Think of Mellum 2 as a “coding teammate” that’s fast enough to use on everyday computers but smart enough to handle tricky tasks.
What questions were the researchers trying to answer?
In simple terms, they asked:
- How can we build a coding model that’s smart like a big model, but runs as fast as a much smaller one?
- What design choices (architecture) make the model both high-quality and efficient?
- How should we train it—what data and schedule—to make it good at code, math, and reasoning?
- Can we make it handle very long inputs (like big files or long chats) without slowing down?
- How well does it perform compared to other popular open models?
How did they build and train the model?
Here’s the approach, explained with everyday analogies.
The model’s design: a team of specialists, not one giant brain
- Mixture-of-Experts (MoE): Imagine a classroom with 64 subject experts. For each sentence the model reads, it only asks 8 of those experts to help. That means it uses “just enough brains” per step, keeping it fast, while still having lots of total knowledge. Mellum 2 has about 12 billion parameters in total, but only about 2.5 billion are “active” for each token it processes. That’s why it acts like a small model in speed, but a bigger one in ability.
Speed tricks that keep quality high
To make it fast without losing smarts, they added three key ideas:
- Grouped-Query Attention with 4 KV heads: Attention is how the model “remembers” what it already read. Fewer “note-takers” (KV heads) means less memory work and more speed. They found 4 was the sweet spot: faster than 8, better quality than 2.
- Sliding Window Attention: Visualize reading through a moving window over a long text. Most layers look only at the recent 1,024 tokens, while some layers see everything. This keeps long-range understanding but cuts a lot of compute, so it runs faster, especially on long inputs.
- Multi-Token Prediction (MTP): The model doesn’t just guess the next word—it also has a small extra head that guesses one more token ahead. During training this helps it learn better. During generation, it doubles as a built-in “draft writer” for speculative decoding, where a quick draft is checked by the main model to speed things up (like a fast sketch before the final drawing).
Training data and schedule: start broad, then specialize
They trained on about 10.6 trillion tokens in three phases:
- Phase 1 (Foundation): Mostly web and general text, some code and math. This gives the model broad language skills.
- Phase 2 (Quality Uplift): More high-quality, curated data and more code.
- Phase 3 (Capability Sharpening): Even more code and math, and the learning rate slowly drops to zero to polish skills.
They also used Fill-in-the-Middle (FIM) for code: the model learns to fill a missing chunk when given both the beginning and the end of a file. That’s important for code editors, where the cursor is in the middle of a function.
Training efficiently: smarter coaching, lighter math
- Optimizer (Muon): Think of this as the coach deciding how to adjust the model’s “knobs.” They chose Muon for stability and speed over AdamW in their tests.
- Mixed precision (FP8 + BF16): Using smaller numbers where possible is like writing with a thinner pencil—enough detail without wasting effort—so training runs faster and uses less memory.
- Routing without drops (MoE): The model doesn’t “drop” tokens when assigning them to experts; it balances the work so every token gets processed, improving quality.
- Sequence packing: They pack training examples neatly to reduce waste and weird mixing of unrelated texts.
Long context and post-training
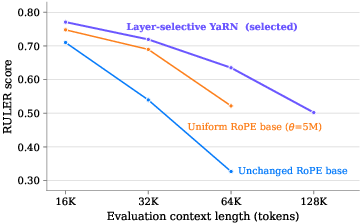
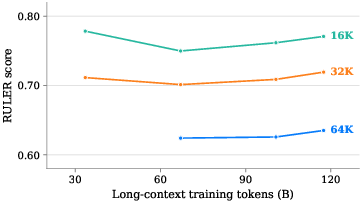
- Long context (up to 128K tokens): That’s enough to handle long files, many code files together, or very long chats. They used a method called YaRN and adjusted only certain layers to scale up context length efficiently.
- Two released variants:
- Instruct: Answers directly.
- Thinking: Writes out its reasoning first, then gives the answer. This helps on multi-step problems in math and code.
- Final polish with reinforcement learning and verifiable rewards: For math and coding, you can often check if the answer is correct (like running test cases). The model is rewarded when it produces correct, verifiable results.
What did they find?
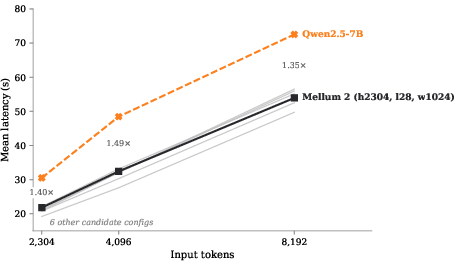
- Strong performance for its speed: Mellum 2 competes well with popular open models in the 4B–14B range on code generation, reasoning, math, tool use, and safety—while running each token with the compute cost of roughly a 2.5B dense model.
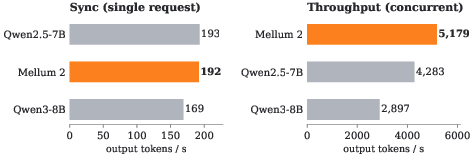
- Fast in practice: Thanks to the design choices (MoE with 8 active experts, 4 KV heads, Sliding Window Attention, built-in draft head), it matches or beats the speed of well-known 7B dense models on a single modern GPU.
- MTP helps quality: Adding the multi-token prediction head improved results on coding and reasoning benchmarks in tests with only a small training-time cost.
- Long context works: They stretched the model’s memory to 128K tokens successfully, which is valuable for real-world coding where you navigate big projects.
- Open release: They’re releasing the base, instruct, and thinking models under Apache 2.0, so people can use, modify, and deploy them freely.
Why does this matter?
- Better coding assistants: Developers get a model that can write, edit, and reason about code, run tools, and handle long tasks—while being fast and affordable to run.
- Practical at scale: It’s designed to run on common hardware without massive costs, making it usable in real products like IDEs.
- Transparent and open: Because it’s open-weight and well-documented, researchers and companies can learn from it, improve it, and build on top of it.
- Safer and more reliable steps: Using verifiable rewards and a “Thinking” mode can make reasoning more trustworthy, especially for math and code where answers can be checked.
Key takeaway
Mellum 2 shows you don’t need a huge, slow model to get strong coding and reasoning. By combining a “team of specialists” design (MoE) with clever speedups and a thoughtful training plan, it delivers big-model skills at small-model cost—and it’s open for everyone to use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that the paper leaves unresolved, aimed to guide future research.
- Real-world deployment evidence in IDEs is missing: no user-centric metrics (autocomplete acceptance rate, edit success, task time, developer satisfaction) or A/B studies in JetBrains IDE workflows.
- Serving results are reported on a single H100; there is no latency/throughput, memory, or energy characterization on commodity or consumer hardware (A100, L40S, RTX 4090/3090, CPU-only) despite “commodity” being a design target.
- No quantification of memory footprint, KV-cache size, or bandwidth limits for 8K vs 128K contexts under the 3:1 SWA pattern and 4 KV heads; especially important for multi-session IDE concurrency.
- Sliding Window Attention design is fixed (3 of 4 layers, window 1,024) without an ablation of:
- different ratios of full/SWA layers,
- adaptive windows by layer or position,
- sensitivity of long-range retrieval and global reasoning to this choice.
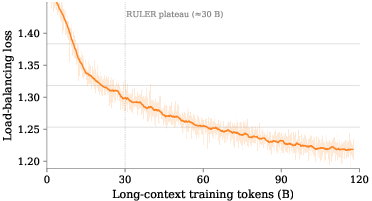
- Long-context (128K) capability is claimed but not evaluated on standard long-context tasks (e.g., Needle-in-a-Haystack, LongBench, LV-Eval, RULER) or on retrieval accuracy vs token distance.
- Computational feasibility of 128K with full-attention layers is not addressed (O(N2) cost on full-attention layers): no evidence of practical decoding throughput at 128K or mitigation strategies (chunked attention, blockwise KV, flash/tiling tricks).
- Grouped-Query Attention with 4 KV heads is selected for throughput, but the impact on:
- factual recall at long range,
- multi-document code navigation,
- multi-hop reasoning,
- is not measured across context lengths.
- MoE routing dynamics are underexplored: no reporting of expert utilization/entropy over training, specialization patterns (e.g., per-language, math, NL vs code), or expert collapse/pathological routing risks over long runs.
- Dropless routing is adopted without a full trade-off study vs capacity-limited routing:
- early training overheads are noted but not quantified at scale,
- no head-to-head final-quality/throughput comparison over long training,
- memory/communication overheads and their impact under high concurrency are not reported.
- Load-balancing strategy is fixed to global-batch auxiliary loss; per-sequence balancing only appears in short runs. No long-run comparison of quality, stability, or inference-time variance under variable-length requests.
- No analysis of the effect of “no shared expert” vs a shared/base expert on stability, specialization, and small-batch inference.
- The number of experts (64) is fixed by memory constraints; there is no exploration of alternative expert counts or hierarchical/semistructured routing that might reduce memory or improve quality at this scale.
- Multi-Token Prediction (MTP-1) is shown to improve benchmarks on a 14B/105B-token ablation, but:
- no confirmation that the same gains hold for the final 12B model trained on 10.6T tokens,
- no ablation of k>1 MTP steps, head placement, or loss weight α across scales,
- no analysis of MTP interactions with SFT/RL or potential overfitting/hallucination trade-offs.
- Speculative decoding with the single MTP head is not empirically quantified:
- draft acceptance rates, speedups, and quality preservation vs a separate small draft model are not reported,
- end-to-end serving gains under varying temperatures/decoding parameters remain unknown.
- Post-training (SFT and RL with verifiable rewards) lacks detail:
- datasets, task distributions, and sizes are not specified,
- reward definitions, failure modes (reward hacking), and safety constraints are not described,
- regression analyses (helpfulness, calibration, toxicity) after RLVR are absent.
- “Thinking” variant is introduced without systematic process-evaluation:
- no measurement of reasoning trace correctness, faithfulness, or process-supervision signals,
- no analysis of trace length/cost vs accuracy trade-offs or user experience in IDE workflows.
- Tool use/function calling and agentic coding claims are not supported by standardized evaluations (e.g., SWE-bench, RepoBench, ToolBench) or by schema/JSON compliance/error rates.
- Safety and security are only briefly indicated via benchmarks:
- no red-teaming, jailbreak resilience, or insecure code-generation auditing (e.g., vulnerabilities, outdated APIs),
- no testing for data exfiltration, prompt injection, or unsafe tool use in agentic settings.
- Data contamination/decontamination is not discussed:
- no explicit decontamination against HumanEval/MBPP/GSM8K/MATH/ARC/etc.,
- risk of leakage from web/code corpora (including Common Crawl-derived code snippets) remains unquantified.
- License and provenance filtering for code from web pages is unspecified; methodology for ensuring permissive licensing in mixed web-code sources is unclear and unaudited.
- The heavy use of synthetic code data is not dissected:
- which generators prompted the synthetic data,
- its domain balance and failure modes,
- its effect on overfitting, stereotype propagation, or evaluation inflation.
- The tokenizer (98,304 vocab from Mellum-4B) is reused without analysis of:
- impact on multilingual code/math tokens,
- compression efficiency vs modern code/math-specialized tokenizers,
- potential gains from tokenizer updates on small MoE scales.
- FIM scheduling (50% → 10% → 50% on code-only) is not ablated to quantify:
- impact on in-IDE completion vs left-to-right generation,
- effects on non-code tasks or long-context recall.
- Sequence packing via best-fit is asserted beneficial, but:
- there is no quantitative comparison vs standard chunking on loss/quality,
- no analysis of residual cross-sample leakage and its training-time artifacts.
- The unique-token filter (≥82 unique tokens per 8,192) to remove low-diversity sequences is heuristic; its impact on genuine highly repetitive but valid data (e.g., minified code, logs) is not evaluated.
- Curriculum design (web-early, curated-late) is not stress-tested:
- no ablation on phase boundaries, code/math ratios, or repetition limits (≤4×) to determine compute-optimality,
- no study on how repetition vs new data affects MoE expert specialization.
- Mixed-precision FP8 training portability and stability are underexplored:
- reproducibility across hardware vendors and FP8 variants (E4M3/E5M2) is not reported,
- numerical pathologies (amax calibration, overflow/underflow) and their mitigations are not quantified,
- comparison vs pure BF16 or alternative hybrid recipes is missing.
- Inference-time quantization (e.g., 4-bit/8-bit weights, KV-cache quantization) for MoE is not addressed; effects on routing accuracy, latency, and quality on consumer hardware remain unknown.
- No cost accounting (GPU-hours, energy) or compute–quality scaling analysis is provided to justify the 10.6T-token run vs smaller/cheaper alternatives.
- Cross-lingual and long-tail programming language performance is not analyzed beyond a 7-language MultiPL-E slice; per-language/code-domain breakdowns and data–performance alignment are absent.
- Catastrophic forgetting across phases and post-training is not assessed (e.g., general knowledge vs code, math vs reasoning) nor are guardrails to retain base capabilities described.
- Reproducibility gaps:
- training data are not released (only checkpoints), preventing data audits and contamination checks,
- training scripts/hparams beyond summaries are not provided,
- RLVR reward implementations and SFT data sources are not made available for replication.
Practical Applications
Immediate Applications
Below are concrete ways Mellum 2 and its techniques can be deployed today across sectors, with notes on dependencies and assumptions.
- IDE-embedded coding assistant for generation, editing, and debugging
- Sector(s): Software, Developer Tools
- What: Integrate Mellum 2 (Instruct or Thinking) into IDEs/editors for inline completions (enabled by Fill-in-the-Middle), function-calling guided refactors, quick-fix suggestions, and multi-step repair.
- Products/workflows: JetBrains/VS Code plugins; “apply fix” and “explain change” flows; conversational coding panels.
- Dependencies/assumptions: Stable function-calling orchestration; editor integration; guardrails to avoid unsafe edits; telemetry optional for improvement.
- Self-hosted, on-prem code assistant for enterprises
- Sector(s): Software, Finance, Healthcare, Public Sector
- What: Deploy behind the firewall for privacy-preserving coding help; Apache 2.0 licensing enables commercial integration.
- Products/workflows: Internal developer portals; enterprise chat-coding servers; secure code analysis endpoints.
- Dependencies/assumptions: An inference stack that supports MoE + GQA + SWA (e.g., TensorRT-LLM/compatible); GPUs with sufficient memory; optional quantization for lower-end hardware.
- CI/CD “autofix” and code review bots
- Sector(s): Software, DevOps
- What: Automated PR review, test generation, bug localization, suggested patches, and cross-language transpilation; can call external tools (tests, linters).
- Products/workflows: GitHub/GitLab bots that propose diffs, run unit tests, and annotate PRs.
- Dependencies/assumptions: Secure sandbox for executing code/tests; policy for human-in-the-loop approval; function-calling schemas.
- Repository-level agentic workflows using 128K context
- Sector(s): Software, Enterprise IT
- What: Plan-and-edit agents that navigate large repos (monorepos, SDKs), apply multi-file refactors, migrate frameworks, and update APIs in batches.
- Products/workflows: “Migration assistant” pipelines; large-PR planners; changelog-aware refactoring agents.
- Dependencies/assumptions: Robust context construction; memory budget for long contexts; rollback/review gates; repo-indexing and code search integration.
- Faster serving via built-in MTP speculative decoding
- Sector(s): Software Infrastructure, SaaS
- What: Use Mellum 2’s MTP head as a draft model to accelerate decoding without a separate small model.
- Products/workflows: High-concurrency inference services with lower latency/cost per token.
- Dependencies/assumptions: Serving framework implements speculative decoding with the MTP head; throughput testing/monitoring; acceptance thresholds for draft/verify strategy.
- High-concurrency, cost-efficient coding assistance
- Sector(s): SaaS, Platforms
- What: Leverage 4 KV heads + SWA (3/4 layers, window 1,024) to improve throughput at scale while keeping quality competitive with 7B dense models.
- Products/workflows: Multi-tenant API services; developer platform add-ons; usage-based plans.
- Dependencies/assumptions: Concurrency-aware KV cache management; request batching; scheduling tuned for MoE latencies.
- Long-context log and incident analysis
- Sector(s): DevOps/SRE, IT Operations
- What: Analyze long logs, traces, and config files in a single pass (up to 128K tokens) to summarize incidents and propose remediation.
- Products/workflows: “Paste logs for RCA” tools; postmortem drafting aids; config consistency checks.
- Dependencies/assumptions: Sensitive log handling; structured prompt templates; token-cost management for very long inputs.
- Documentation and knowledge maintenance at scale
- Sector(s): Software, Enterprise IT, Education
- What: Generate/update API docs, READMEs, and onboarding guides; align code and docs using repo-wide context.
- Products/workflows: Doc-sync bots; code-to-doc consistency checks; tutorial generation.
- Dependencies/assumptions: Style guides; doc repos integrated with CI; content ownership policies.
- Programming and math tutoring (Thinking variant)
- Sector(s): Education, EdTech
- What: Step-by-step programming and math guidance, with executable examples and reasoning traces.
- Products/workflows: Classroom assistants; auto-grading with test execution; individualized feedback.
- Dependencies/assumptions: Policies for chain-of-thought (disclosure vs. hidden reasoning); content filters; safe execution sandboxes.
- Research baseline for efficient MoE, MTP, and SWA
- Sector(s): Academia, AI Research
- What: Use open checkpoints to study router dynamics, dropless routing, Muon + FP8 training, YaRN long-context scaling, and curriculum strategies.
- Products/workflows: Reproducible ablations; teaching materials for advanced training recipes.
- Dependencies/assumptions: Compute availability; compatible training code; dataset/licensing considerations for retraining.
- Private-sector adoption in regulated environments
- Sector(s): Government, Defense, Healthcare, Finance
- What: Use Apache 2.0 open weights for procurement-friendly, auditable coding assistants in secure enclaves.
- Products/workflows: On-prem AI service endpoints; auditable reasoning logs (Thinking variant).
- Dependencies/assumptions: Security review; red-teaming; compliance with data handling regulations.
- Day-to-day automation for knowledge workers and hobbyists
- Sector(s): Consumer Software, Makers/Robotics
- What: Generate scripts, glue code, and home-automation routines; troubleshoot small projects.
- Products/workflows: Desktop app with local or LAN-hosted inference; smart-home script generation.
- Dependencies/assumptions: Quantized models for smaller GPUs; accessible UIs; basic user familiarity with code.
Long-Term Applications
These opportunities require further research, scaling, integration work, or ecosystem maturation before broad deployment.
- On-device or lightweight edge deployment
- Sector(s): Consumer Devices, Mobile, Industrial Edge
- What: Run Mellum 2 (or derivatives) on laptops/edge boxes for offline coding help.
- Products/workflows: Local assistants for air-gapped environments; factory-floor script helpers.
- Dependencies/assumptions: 4–8-bit quantization for MoE; optimized MoE runtimes in llama.cpp/exllama-like stacks; memory-efficient KV caches; acceptable quality at lower precision.
- Safety-critical and formally verified code generation
- Sector(s): Automotive, Aerospace, Medical Devices, Finance
- What: Integrate with static analyzers, model checkers, and proof assistants to produce verifiable patches and code.
- Products/workflows: “Verified fix” pipelines; DO-178C/ISO 26262 vetting workflows with AI assistance.
- Dependencies/assumptions: Expanded RL with verifiable rewards beyond math/exec code; curated datasets; toolchain integration; rigorous evaluation frameworks.
- Large-scale, autonomous refactoring and modernization
- Sector(s): Finance, Energy, Telecom, Manufacturing
- What: Orchestrate multi-thousand-file migrations (e.g., legacy to modern frameworks), enforce architectural patterns, and deprecate APIs.
- Products/workflows: Multi-agent planners (planner/coder/tester/reviewer roles) with rollback and staging gates.
- Dependencies/assumptions: Strong guardrails and human oversight; accurate repository indexing; reliable execution sandboxes; robust diff application and conflict resolution.
- Industry-specific code assistants (PLC/SCADA, HDL, ROS)
- Sector(s): Industrial Automation, Semiconductors, Robotics
- What: Fine-tune domain adapters on Mellum 2 for PLC ladder logic, SCADA scripts, Verilog/VHDL, ROS nodes, etc.
- Products/workflows: Shop-floor automation assistant; HDL code review/generation; robot behavior design tools.
- Dependencies/assumptions: High-quality domain datasets; toolchain connectors (e.g., PLC simulators, HDL synthesizers); safety constraints.
- Multi-agent software development teams
- Sector(s): Software, Platforms
- What: Specialized Mellum 2 agents (planner, implementer, tester, reviewer) coordinating via function calling and shared memory.
- Products/workflows: “AI sprint” orchestrations; continuous improvement loops with feedback.
- Dependencies/assumptions: Reliable orchestration frameworks; failure recovery; hallucination mitigation; governance for agent autonomy.
- Advanced speculative decoding co-designed with hardware
- Sector(s): AI Infrastructure, Cloud
- What: Extend MTP to multi-step drafts and fuse with GPU kernels to achieve larger speedups.
- Products/workflows: Model-serving accelerators tuned for draft/verify loops; adaptive draft depth by latency targets.
- Dependencies/assumptions: Kernel and compiler support; careful quality-speed tradeoffs; vendor collaboration.
- Explainable, auditable reasoning for compliance
- Sector(s): Public Sector, Regulated Industries
- What: Use the Thinking variant to produce reasoning traces as audit artifacts for code changes and tool decisions.
- Products/workflows: Audit-ready change logs; explainability dashboards; compliance documentation generation.
- Dependencies/assumptions: Policies on chain-of-thought storage; privacy controls; standards alignment (e.g., NIST AI RMF, EU AI Act transparency).
- Cross-modal, long-context engineering assistants
- Sector(s): Software, Design/Architecture, Education
- What: Combine long-context code analysis with diagrams/specs (future multimodal extension) for end-to-end design-to-implementation support.
- Products/workflows: Architecture-to-code pipelines; design doc consistency checks; spec-driven test generation.
- Dependencies/assumptions: Multimodal model extensions; OCR/diagram parsers; prompt and UI design for mixed modalities.
- Curriculum and data-mix transfer for internal model training
- Sector(s): Academia, Enterprise AI
- What: Adopt the three-phase “web early, curated late” curriculum and repetition strategy to train high-quality, small MoEs.
- Products/workflows: Internal training playbooks; capability-sharpening stages with linear decay to zero.
- Dependencies/assumptions: Access to curated datasets; compute for multi-trillion token runs; MoE-friendly pipelines.
- Adaptive attention and memory-efficient long-context serving
- Sector(s): AI Infrastructure
- What: Research dynamic SWA windows and adaptive attention patterns to scale beyond 128K with manageable cost.
- Products/workflows: Smart attention controllers; token-pruning policies; hybrid retrieval + long-context strategies.
- Dependencies/assumptions: Algorithmic advances; kernel support; quality evaluation at ultra-long context lengths.
- Policy frameworks for safe AI-assisted coding
- Sector(s): Policy, Governance
- What: Develop procurement guidelines, risk assessments, and auditing standards for AI coding tools in public and critical sectors.
- Products/workflows: Adoption playbooks; red-team/blue-team exercises; certification criteria.
- Dependencies/assumptions: Interagency collaboration; standardized evaluation benchmarks for code safety and reliability.
Glossary
- ablation: A controlled experimental comparison where design choices are systematically removed or varied to assess their impact. "We systematically ablate dense versus MoE backbones, Grouped-Query Attention configurations, Multi-head Latent Attention, Sliding Window Attention patterns, and expert sparsity ratios."
- active parameters per token: In sparse models, the subset of total parameters that are actually used for computing each token. "with 2.5B active parameters per token."
- amax algorithm: A method for tracking activation maxima used in FP8 quantization scaling. "using tensorwise FP8 recipe with the most-recent amax algorithm."
- AdamW: An adaptive gradient optimizer with decoupled weight decay. "We compared AdamW~\cite{loshchilov2019adamw} and Muon"
- BF16: Brain floating point format (16-bit) used to accelerate training with reduced precision while maintaining stability. "We use BF16 as the base precision"
- best-fit packing: A sequence-packing strategy that minimizes truncation by optimally fitting documents into fixed-length sequences. "using best-fit packing"
- capacity factor: A limit on how many tokens an MoE expert can process per batch before extra tokens are dropped or rerouted. "capacity factors of 1.0--1.5"
- capacity-limited routing: MoE routing that enforces expert capacity limits, potentially dropping tokens beyond capacity. "approaches that of capacity-limited routing."
- dropless routing: An MoE routing strategy that avoids dropping tokens by not enforcing expert capacity limits. "We adopt dropless routing~\cite{gale2023megablocks} (no expert capacity factor)"
- expert parallelism: A parallelization strategy that partitions experts across devices for MoE training/inference. "We employ expert parallelism with a degree of 8"
- expert sparsity: The practice of activating only a small number of experts per token in an MoE model to reduce compute. "and expert sparsity ratios."
- Fill-in-the-Middle (FIM): A training objective where the model predicts a missing middle span given prefix and suffix context. "we train Mellum 2 with a Fill-in-the-Middle (FIM) objective"
- FP8 hybrid mixed-precision training: Training that combines FP8 for certain operations with higher-precision formats elsewhere to boost efficiency. "FP8 hybrid mixed-precision training~\cite{micikevicius2022fp8}"
- global auxiliary load-balancing loss: An MoE regularization term encouraging even distribution of tokens across experts. "we use global auxiliary load-balancing loss~\cite{fedus2022switch} with a coefficient of "
- Grouped-Query Attention (GQA): An attention variant where multiple query heads share a smaller set of key-value heads to reduce memory and compute. "Grouped-Query Attention (GQA)~\cite{ainslie2023gqa}"
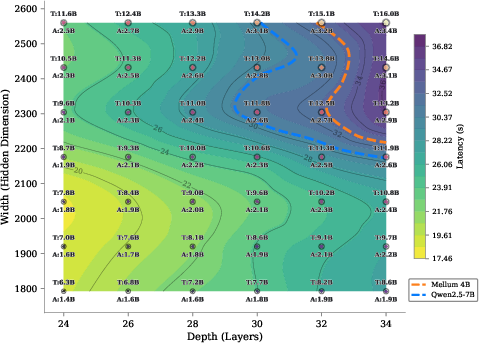
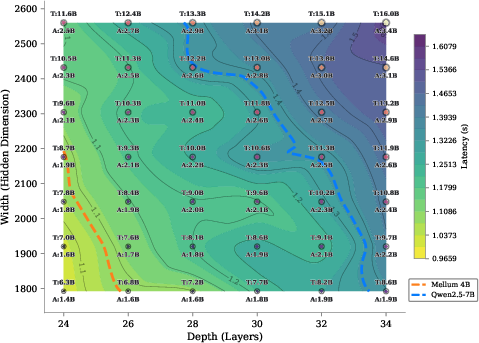
- iso-latency maps: Visualizations showing configurations that yield the same inference latency. "Iso-latency maps for Qwen3-MoE architectures (64 experts, 8 active)"
- KV-cache: A cache of key and value tensors used during autoregressive inference to avoid recomputation. "where KV-cache utilization is low"
- KV heads: The number of key-value head groups in GQA that queries attend to, affecting memory and throughput. "with 4 KV heads"
- MapReduce-like (distributed) system: A distributed data processing setup inspired by MapReduce for large-scale preprocessing. "MapReduce-like distributed storage and compute system"
- Megatron-LM: A large-scale distributed training framework for transformer models. "Megatron-LM~\cite{shoeybi2020megatronlm}-based training framework"
- Mixture-of-Experts (MoE): A neural architecture that routes tokens to a subset of specialized expert networks, enabling sparse activation. "Mixture-of-Experts (MoE) LLM"
- Multi-head Latent Attention (MLA): An attention variant that projects to a lower-rank latent space to reduce compute/memory. "Multi-head Latent Attention (MLA)~\cite{deepseekai2024deepseekv2}"
- Multi-Token Prediction (MTP): An auxiliary objective that predicts multiple future tokens to improve downstream performance and enable drafting. "Multi-Token Prediction (MTP) head"
- Muon optimizer: An optimizer combining orthogonalization-based updates with Adam-like components for stable large-scale training. "We adopt the Muon optimizer~\cite{jordan2024muon,liu2025muon}"
- Nesterov momentum: A momentum variant in gradient descent that looks ahead to improve convergence. "Nesterov momentum & Yes"
- Newton–Schulz iterations: Iterative steps used in Muon to approximate matrix inverses for spectral scaling. "Muon Newton--Schulz iterations & 5"
- orthogonalization-based updates: Parameter updates that enforce or encourage orthogonality to stabilize and regularize training. "Muon applies orthogonalization-based updates to hidden layers"
- per-sequence balancing: An MoE routing balancing method that equalizes expert loads within each sequence rather than globally. "We explored both per-sequence and global-batch balancing strategies"
- pipeline parallelism: Model-parallel training that splits layers across devices and pipelines microbatches. "pipeline parallelism degrees of 1"
- QK-Norm: Normalization applied to query and key projections in attention to stabilize training. "QK-Norm~\cite{henry2020qknorm} applied to the query and key projections"
- reinforcement learning with verifiable rewards (RLVR): RL post-training where rewards come from deterministically checkable signals (e.g., executable tests). "reinforcement learning with verifiable rewards (RLVR)"
- RMSNorm: A normalization technique that normalizes activations by their root-mean-square. "RMSNorm ()"
- Rotary Position Embeddings (RoPE): A positional encoding method that rotates query/key vectors to encode relative positions. "Rotary Position Embeddings (RoPE)~\cite{su2024roformer}"
- router z-loss: A stabilization penalty on MoE router logits to prevent saturation and improve training stability. "a router z-loss of "
- SiLU-gated MLPs: Feed-forward sublayers using SiLU (Swish) gates to control activation flow. "SiLU-gated MLPs~\cite{shazeer2020glu}"
- Sliding Window Attention (SWA): An attention pattern that restricts attention to a local window to reduce compute while retaining periodic global layers. "Sliding Window Attention (SWA)~\cite{jiang2023mistral,beltagy2020longformer}"
- speculative decoding: A generation technique where a draft model proposes tokens that a larger model verifies to accelerate inference. "speculative decoding"
- spectral scale mode: A Muon scaling setting that uses spectral norms to scale layer updates. "Muon scale mode & spectral"
- tensor parallelism: Model-parallel training that splits tensor operations (e.g., matrix multiplications) across devices. "tensor and pipeline parallelism degrees of 1"
- top-8 routing: An MoE routing strategy selecting the top 8 experts per token based on router scores. "8 active per token (top-8 routing)"
- untied input/output embeddings: A design where input and output embedding matrices are separate rather than shared. "untied input/output embeddings"
- Warmup-Hold-Decay schedule: A learning-rate schedule that warms up, holds at a peak, then linearly decays to zero. "Warmup-Hold-Decay schedule"
- YaRN: A method for extending context length by rescaling rotary embeddings across layers. "via a layer-selective YaRN~\cite{peng2024yarn}"
Collections
Sign up for free to add this paper to one or more collections.

