Arcee Trinity Large Technical Report
Abstract: We present the technical report for Arcee Trinity Large, a sparse Mixture-of-Experts model with 400B total parameters and 13B activated per token. Additionally, we report on Trinity Nano and Trinity Mini, with Trinity Nano having 6B total parameters with 1B activated per token, Trinity Mini having 26B total parameters with 3B activated per token. The models' modern architecture includes interleaved local and global attention, gated attention, depth-scaled sandwich norm, and sigmoid routing for Mixture-of-Experts. For Trinity Large, we also introduce a new MoE load balancing strategy titled Soft-clamped Momentum Expert Bias Updates (SMEBU). We train the models using the Muon optimizer. All three models completed training with zero loss spikes. Trinity Nano and Trinity Mini were pre-trained on 10 trillion tokens, and Trinity Large was pre-trained on 17 trillion tokens. The model checkpoints are available at https://huggingface.co/arcee-ai.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces the Trinity family of LLMs. The biggest one, called Trinity Large, is designed to be both powerful and efficient. It uses a “Mixture-of-Experts” (MoE) design so that, for each piece of text it reads, only a small part of the model is active. That makes it faster and cheaper to run while keeping high performance. The paper also covers two smaller models (Trinity Nano and Trinity Mini), explains the special architecture and training tricks used to make the models stable and good at long texts, and describes how huge amounts of training data—including carefully made synthetic data—were created and used.
What were the main goals?
Put simply, the team wanted to:
- Build very large but efficient LLMs that can handle long documents, write and understand code, and reason well.
- Keep training stable (no sudden spikes or crashes) and make inference-time—when the model actually answers your questions—fast.
- Develop better ways to balance work across “experts” inside the model so none gets overloaded.
- Create and use a massive, high-quality data pipeline, including trillions of tokens of synthetic (machine-generated) text, to train the models.
- Release open model weights so organizations can run and audit the models themselves.
How did they do it?
Below is a plain-language tour of the approach, with everyday analogies for the more technical pieces.
The models
They built three versions with the same modern design in different sizes:
| Model | Total parameters | Active per token | Pretraining tokens | Target strengths |
|---|---|---|---|---|
| Trinity Nano | ~6B | ~1B | 10 trillion | Small, fast, good general skills |
| Trinity Mini | ~26B | ~3B | 10 trillion | Medium-sized, stronger reasoning/code |
| Trinity Large | ~400B | ~13B | 17 trillion | Very strong, long context, efficient MoE |
“Total parameters” is like how many knobs the model has; “active per token” means only a fraction of those knobs turn for each word, which saves time and memory.
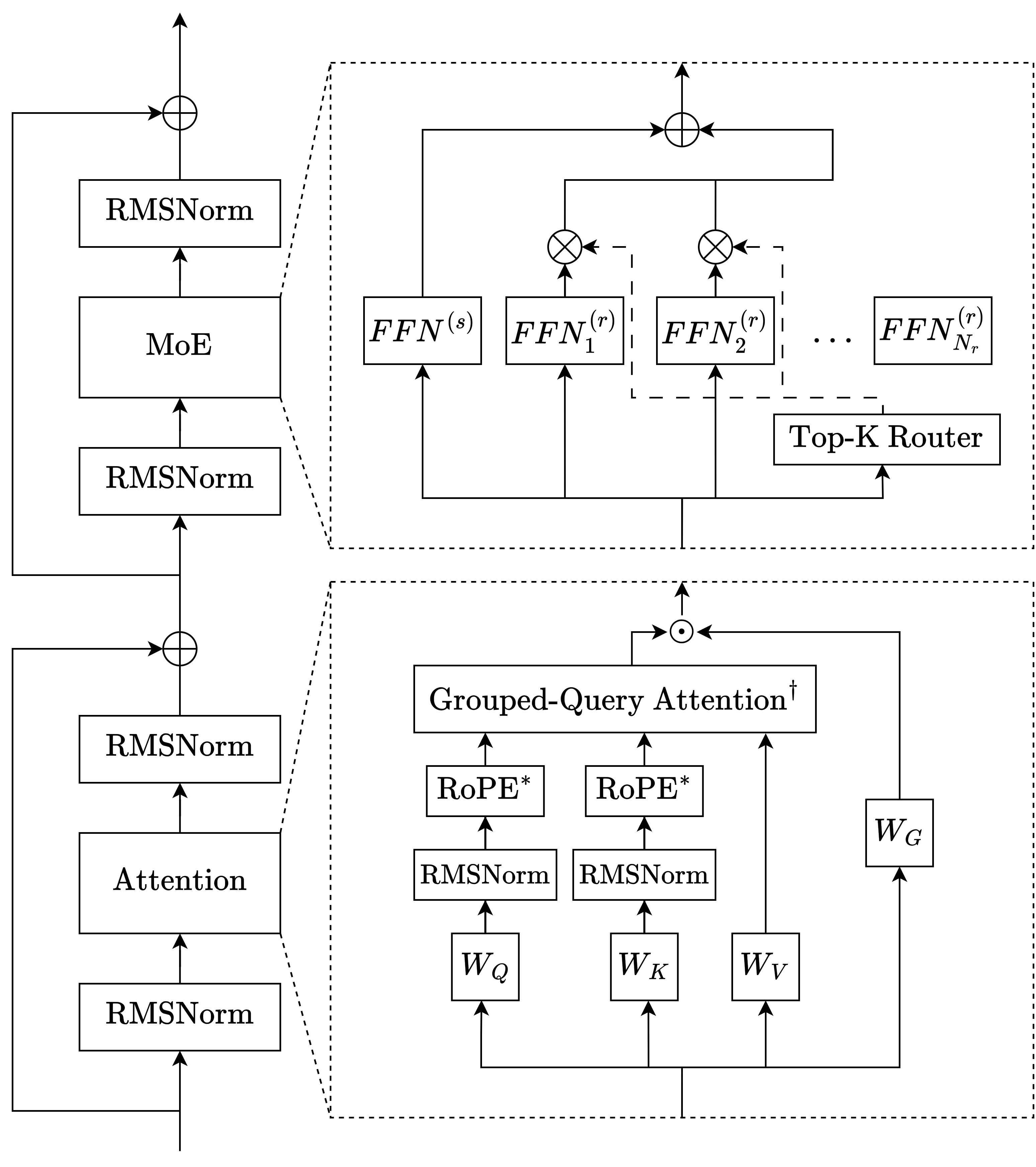
Mixture-of-Experts (MoE): a team of specialists
Think of the model as a school with many teachers (experts). For each sentence you give it, a small group of the most relevant teachers is picked to help. This way, the school can be huge (lots of teachers), but each student only meets a few teachers—making things efficient. Trinity uses:
- Routed experts: specialists chosen per token.
- A shared expert: a generalist always active to keep things steady.
- Sigmoid routing: a smooth, stable way to pick which teachers to use.
- SMEBU: a new method to balance teacher workloads so nobody is overwhelmed. It uses soft clamping (like gently limiting the size of changes) and momentum (like smoothing out jittery moves over time) to keep routing stable.
Attention: how the model focuses
Attention is how the model decides which parts of the text matter. Trinity mixes:
- Local attention (like reading a few pages around your current place) with a sliding window.
- Global attention (like having a summary that can see the whole book). The global layers use “NoPE,” meaning they don’t rely on positional signals that can get messy at long lengths.
- GQA (Grouped-Query Attention), which lets many “questions” share fewer “key/value” resources to save memory while keeping performance.
- Gated attention, which is like adding a volume knob to the attention output to prevent overly loud signals and keep training stable.
- QK-norm, a way to normalize attention inputs so they don’t blow up numerically.
This 3:1 local-to-global pattern makes long-context reading faster and more reliable.
Tokenizer: how text is chopped into pieces
Before training, text is split into tokens—like turning a paragraph into puzzle pieces. They built a custom 200,000-token vocabulary with smart pre-processing:
- Numbers are split into place-based chunks (e.g., 1|234|567), helping the model do math better.
- Script-aware handling for languages that don’t use spaces (like Chinese or Thai), so tokens are learned properly per script.
- A byte-level fallback to guarantee everything is tokenizable.
- The larger vocabulary compresses text better (fewer tokens for the same content), which speeds training and inference. They tested an alternative called SuperBPE that made sequences shorter, but didn’t see performance gains at their scale, so they stuck with standard BPE.
Training data: massive and carefully curated
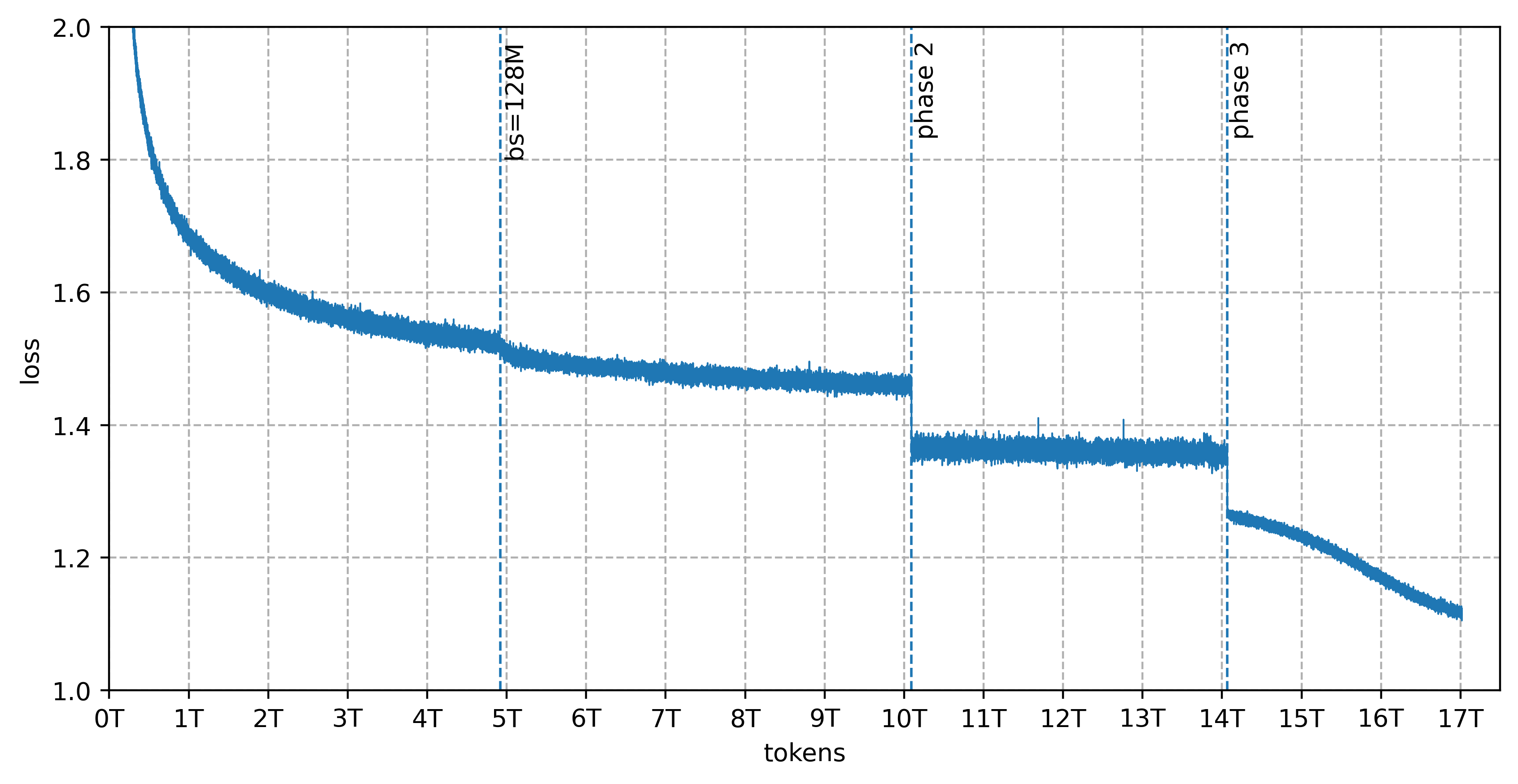
Total pretraining was huge: 10 trillion tokens for the smaller models and 17 trillion for Trinity Large. The mix shifted across three phases toward higher-quality math, code, science, and multilingual data. A key part was synthetic data:
- Over 8 trillion tokens of synthetic web, code, and STEM text.
- For web text, they took good documents and rephrased or restructured them to improve clarity and diversity (e.g., turning articles into Q&A).
- For code, they selected high-quality files and generated variants for style and task diversity.
- This was powered by scalable infrastructure (Ray + vLLM on Kubernetes) to run across many GPUs.
RSDB: making batches fair and stable
Training happens in “batches” of text. If one batch accidentally contains lots of very long documents, it can throw the model off step-to-step. The Random Sequential Document Buffer (RSDB) is like a big playlist of entire documents where each batch samples different parts randomly. This:
- Reduces batch imbalance (“BatchHet”), which is the gap between the hardest microbatch and the average.
- Cuts loss variance and makes gradients more stable.
- Led to big improvements without dropping any tokens.
In their tests, RSDB reduced batch heterogeneity by over 4× and step-to-step loss variance by about 2.4× in Trinity Large’s phase 3.
Optimizers and stabilization tricks
- Muon optimizer (for most layers): a modern method that can use bigger batches and be more sample-efficient than AdamW.
- AdamW (for embeddings and output heads): standard, reliable optimizer.
- Extra numerical stability: QK-norm, gated attention, careful initialization, and “sandwich norm” (normalize before and after sublayers) help avoid loss spikes. All three models trained with zero loss spikes.
Long-context extension
To make the model handle very long inputs, they mainly extended global attention layers (not local ones). Training at sequences longer than the target length helped performance. Trinity Large targets very long contexts (inference up to around 512k tokens), and the process was smooth and efficient.
What did they find, and why does it matter?
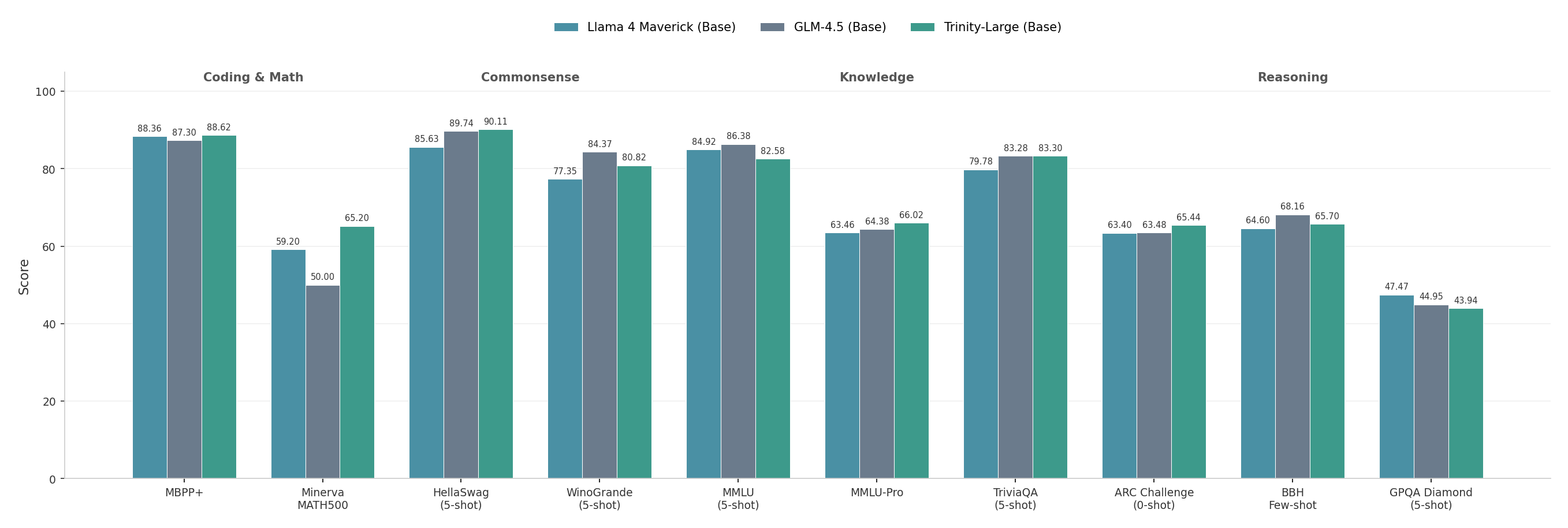
Main results and takeaways:
- Stable training at huge scale: All models completed training without loss spikes. That’s rare at this size and shows the recipe is solid.
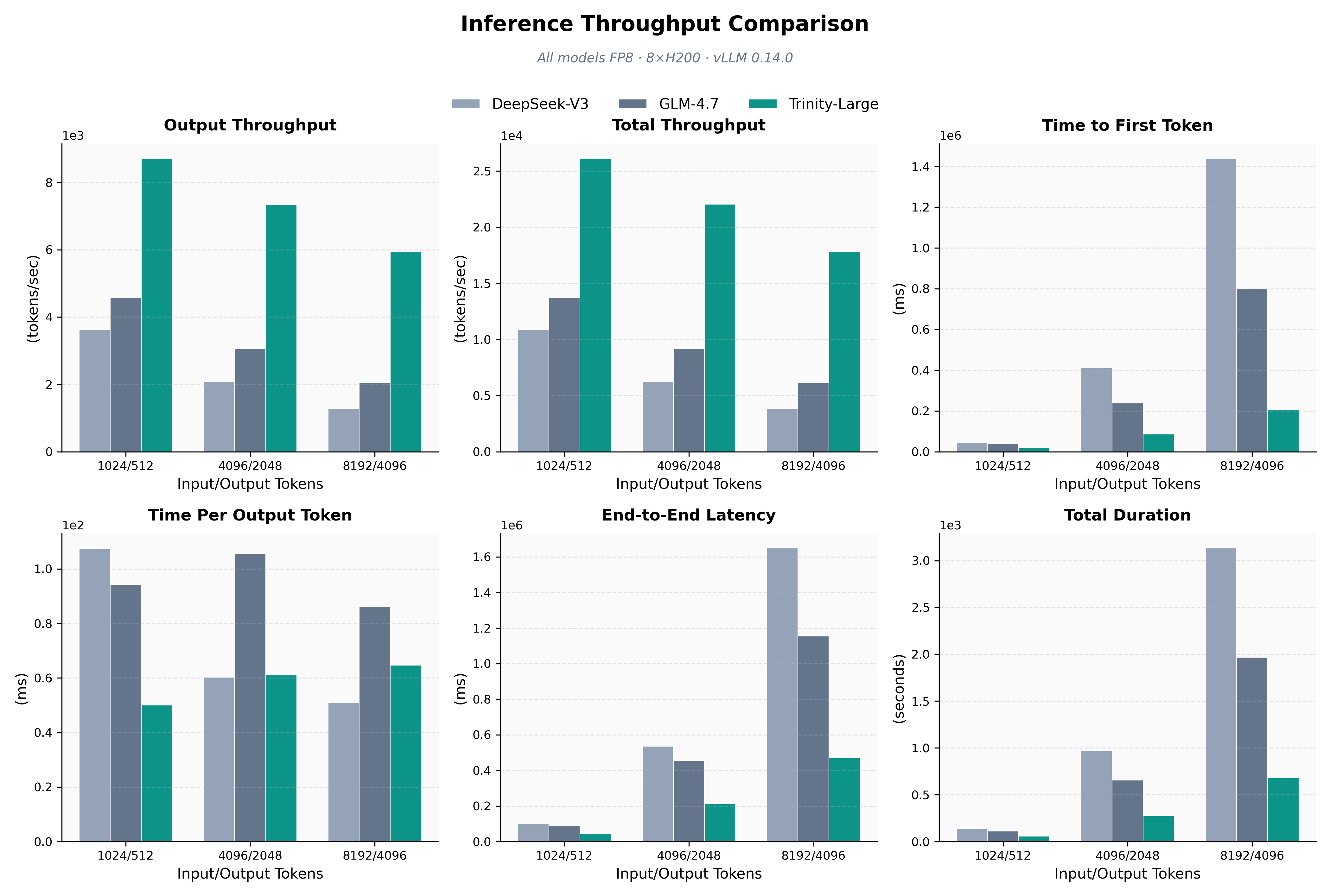
- Efficient and fast: MoE with only a few experts active per token delivers high performance with lower compute cost. GQA and the local/global setup shrink memory needs and speed up inference.
- Strong tokenizer: The 200k-token vocabulary compresses text well, especially for English and French, which reduces tokens and speeds everything up.
- Better load balancing with SMEBU: The new MoE balancing strategy makes expert routing smoother and less jittery, helping stability.
- RSDB lowers batch noise: Random document buffering cut batch heterogeneity and loss variance, which likely improves reliability and data efficiency.
- Long context works: Extending mostly the global layers gave quick loss recovery and strong long-context behavior, supporting tasks like reading long documents or multi-step reasoning.
- Massive, high-quality synthetic data is practical: They showed it’s possible to generate and use multi-trillion-token synthetic data at scale, and that it helps train strong models across code, math, and multilingual tasks.
- Open weights available: Checkpoints are on Hugging Face, which helps organizations adopt, audit, and customize the models.
What’s the impact?
- Better tools for real-world use: Fast, long-context models are ideal for reading big documents, writing and understanding code, and acting as smart agents that think through complex tasks step by step.
- Lower running costs: Activating only a small slice of the model per token means faster responses and cheaper deployments, especially important for businesses.
- Safer and more controllable: Open weights allow companies to host models themselves, comply with regulations, and know what data was used.
- Reusable training ideas: SMEBU and RSDB are practical techniques other teams can adopt to stabilize and speed up MoE training. The tokenizer methods and architecture choices (like local/global attention and gated attention) offer a strong blueprint for building efficient, long-context LLMs.
- A path for scaling with synthetic data: The paper demonstrates that careful synthetic data generation at extreme scale can support frontier-level models, which could speed up future model development.
In short, Trinity shows how to build very large, efficient, and long-context LLMs that are stable to train and practical to deploy—while sharing open checkpoints and useful training tricks the community can build on.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. These are framed to be actionable for future research.
- Lack of controlled ablations quantifying the contribution of each architectural choice (QK-Norm, gated attention, interleaved local/global with NoPE, GQA, depth-scaled sandwich norm, embedding multiplier) to stability, long-context performance, and overall quality across Trinity Nano/Mini/Large.
- No systematic comparison of sigmoid routing vs softmax routing under identical settings (e.g., routing entropy, stability, quality), nor analysis of how sigmoid gating interacts with Top-K selection using expert bias.
- SMEBU load balancing is introduced without theoretical convergence analysis, sensitivity studies (λ, β, κ), or robust empirical comparisons against sign-based aux-free updates, auxiliary-loss methods, or other smooth/clamped updates across scales and expert counts.
- Unclear interaction between SMEBU and the sequence-wise auxiliary balance loss (e.g., do they complement or interfere; how to tune α jointly with SMEBU hyperparameters).
- MoE design choices (coarser-grained experts in Large, 4 active experts/token vs 8 in smaller models) lack quantification of trade-offs in throughput, specialization, load variance, and downstream quality; no search over K, number of experts, and expert width.
- Early “dense replacement” of the first k MoE layers (k varies by model) is claimed to stabilize training but is not ablated for its effect on stability, convergence speed, and final quality.
- Capacity/overflow policy in MoE routing is unspecified (e.g., capacity factor, token dropping/backpressure). The impact of potential overflow on latency spikes, memory use, or quality remains unknown.
- Expert specialization and routing dynamics are unexamined (e.g., entropy over experts, per-domain/language specialization, collapse/degeneracy risks, temporal drift of expert utilization).
- Tokenizer was trained before finalizing the multilingual corpus; the effect of under-represented non-English scripts on multilingual performance (accuracy, B/T, OOV patterns) is not evaluated on standard multilingual benchmarks.
- SuperBPE showed large compression gains but was dropped due to a null result at small scale; it remains open whether SuperBPE would improve performance at full pretraining scale or for specific domains (reasoning/code/CJK).
- Potential inconsistency in how bytes-per-token/characters-per-token “compression” is interpreted and compared across tokenizers; precise metric definitions, statistical significance, and alignment with downstream performance are not clarified.
- Heavy reliance on multi-trillion-token synthetic data (web, multilingual, code, STEM) lacks quantitative audits: duplication/near-duplication rates, contamination with evaluation sets, factuality/consistency metrics, bias/toxicity profiles, and domain-wise real-vs-synthetic proportions.
- No measurement of how synthetic rephrasing (format/style transformations) affects knowledge retention, paraphrase diversity, and factual drift; no causal attribution of synthetic data to downstream gains/risks by domain.
- Code data synthesis quality is not validated via executable correctness metrics (e.g., pass@k, unit-test pass rates) or robustness to distribution shifts (new libraries, languages).
- RSDB packing was introduced mid-run for Trinity Large, confounding evaluation; its effect is primarily shown on loss variance proxies. There is no like-for-like large-scale A/B on final metrics, nor profiling of RSDB’s compute/memory overhead and scaling with buffer/worker sizes.
- Batch Heterogeneity (BatchHet) metric is proposed but only linked to small-scale stability proxies; no evidence that reducing BatchHet improves final model quality, robustness, or reasoning performance at scale; thresholds/targets for BatchHet remain undefined.
- Intra-document attention masking is used for Trinity Large but not in smaller models; the impact on cross-document mixing, context learning, and stability is not isolated via ablations.
- Context extension strategy (extend global layers only) is validated mainly via MK-NIAH; comprehensive long-context evaluations (e.g., RULER beyond needle tasks, LV-Eval, InfiniteBench, LongBench) and end-task outcomes at 128k–512k are not reported.
- No latency/throughput/memory characterization for inference across context lengths (e.g., KV-cache size with interleaved local/global, effect of gated attention on compute, per-token latency vs baselines).
- Length extrapolation claims are qualitative; length-generalization curves, failure modes beyond 512k, and trade-offs with short-context performance are not presented.
- Optimizer choices (Muon for hidden layers; AdamW for embeddings/head) and LR schedule differences are not rigorously ablated against pure AdamW or Muon variants (with/without RMS rescaling), leaving unclear which ingredients deliver stability and sample efficiency.
- z-loss and cut cross-entropy are used but their coefficients, stability impact, and effect on perplexity/generalization are not documented.
- Training compute is under-specified: no total FLOPs/GPU-days/energy, making cost-efficiency comparisons and reproducibility difficult.
- Safety, alignment, and responsible use are not addressed: no details on instruction tuning/RLHF, refusal behavior, toxicity/bias/hallucination audits, jailbreak robustness, or safety filters in data and post-training.
- Reproducibility is limited by missing artifacts: detailed data mixture compositions and sampling weights, RSDB/SMEBU reference implementations, and full training configurations beyond high-level hyperparameters.
- Impact of hardware faults/restarts on optimizer state, data ordering, and convergence is not analyzed; no guidance on resilience best practices beyond infrastructure mitigations.
- No cross-model scaling-law analysis to connect tokens, parameters (activated and total), and performance under extreme MoE sparsity; unclear whether observed trends generalize when scaling corpus, context, or expert granularity.
- Multilingual performance post context extension and under long-context regimes is unreported; whether local-window limits hinder long-range multilingual reasoning is unknown.
- Practical deployment details are missing: memory footprints for different batch sizes/context windows, quantization compatibility (KV/weights), throughput on common GPU tiers, and server cost projections.
Glossary
- AdamW optimizer: A widely used adaptive gradient optimizer with decoupled weight decay. "AdamW optimizer"
- auxiliary-loss-free load balancing: A MoE balancing method that avoids explicit auxiliary losses by adjusting expert biases. "we used the standard formulation of auxiliary-loss-free load balancing"
- Batch Heterogeneity (BatchHet): A metric quantifying per-step microbatch loss imbalance as max minus mean loss. "Batch Heterogeneity, (BatchHet), defined as the difference between the maximum microbatch loss and the average loss for each training step"
- Byte-level fallback: A tokenizer mechanism ensuring coverage of any byte sequence by encoding at the byte level when needed. "Byte-level fallback. A byte-level encoding layer ensures full coverage of any byte sequence without unknown tokens."
- context parallelism: A distributed inference/training strategy that splits long sequences across devices. "For the context extension of Trinity Large, we use a context parallelism degree of 4."
- cosine decay: A learning rate schedule that reduces the rate following a cosine curve over training steps. "During the decay phase, we use a cosine decay to of the peak learning rate"
- Cut Cross-Entropy: A memory-saving loss computation technique for long-context training and fine-tuning. "we use Cut Cross-Entropy \citep{wijmans2025cut}"
- depth-scaled sandwich norm: A normalization scheme applying RMSNorm before and after sublayers, with output gains scaled by depth. "a simplified depth-scaled sandwich norm"
- Expert Parallelism (EP): A distributed MoE training technique that parallelizes experts across devices. "we additionally employ Expert Parallelism (EP) within a GPU node for efficient Mixture-of-Experts Layers."
- expert bias: A per-expert scalar adjusted to balance routing loads among experts. "the expert bias is updated in a decoupled way"
- Fully-Sharded Data Parallel (FSDP): A distributed training method that shards model parameters, gradients, and optimizer states across workers. "Fully-Sharded Data Parallel (FSDP)"
- gated attention: An attention variant that applies an elementwise sigmoid gate to attention outputs for stability and performance. "additionally adopt gated attention"
- Grouped-query attention (GQA): An attention design where multiple query heads share a single key/value head to reduce memory usage. "grouped-query attention (GQA)"
- Hybrid Sharded Data Parallel (HSDP): A data-parallel configuration combining replication with intra-replica sharding (e.g., via FSDP). "a Hybrid Sharded Data Parallel (HSDP) configuration"
- interleaved local and global attention: An attention layout alternating local sliding-window layers with global layers to improve efficiency and long-context handling. "interleaved local and global attention"
- KV-cache: Stored key/value tensors used at inference to avoid recomputation across tokens in attention. "drastically reducing KV-cache size"
- Liger Kernels: Optimized GPU kernels used for efficient fused cross-entropy and z-loss computations. "Liger Kernels \citep{hsu2025ligerkernel} project"
- Mixture-of-Experts (MoE): A model architecture that routes tokens to a subset of specialized feed-forward experts per layer. "Mixture-of-Experts (MoE)"
- Multi-Key Needle-in-a-haystack (MK-NIAH): A long-context retrieval benchmark that measures the ability to find multiple keys in large sequences. "Multi-Key Needle-in-a-haystack (MK-NIAH) task from RULER"
- Muon optimizer: A high-sample-efficiency optimizer enabling larger critical batch sizes compared to AdamW. "Muon optimizer"
- No positional embeddings (NoPE): An attention configuration that omits positional encodings in certain (global) layers. "no positional embeddings (NoPE)"
- QK-normalization (QK-norm): RMS normalization applied to query and key vectors to stabilize attention logits. "QK-normalization (QK-norm)"
- Random Sequential Document Buffer (RSDB): A dataloader strategy that randomly interleaves full documents to reduce intra-batch correlation and imbalance. "Random Sequential Document Buffer (RSDB)"
- Rotary positional embeddings (RoPE): A positional encoding method applying rotations to query/key vectors to encode relative positions. "rotary positional embeddings (RoPE)"
- RMSNorm: Root-mean-square normalization that scales activations based on their RMS, used instead of LayerNorm in several places. "We compute the queries, keys, and values as linear projections of the input and apply RMSNorm to queries and keys (QK-norm)"
- RULER: A suite of long-context benchmarks used to evaluate retrieval and reasoning performance at extended sequence lengths. "from RULER \citep{hsieh2024rulerwhatsrealcontext}"
- Sequence-wise load balance loss: An auxiliary objective promoting balanced expert usage within each sequence. "we use a complementary sequence-wise load balance loss to promote balance within a sequence"
- Sigmoid routing: A MoE routing method that uses normalized sigmoid scores for expert selection and gating instead of softmax. "we use normalized sigmoid routing scores instead of softmax-based routing"
- sliding window attention (SWA): Local attention limited to a fixed-size window of recent tokens to reduce computational cost. "sliding window attention (SWA)"
- Soft-clamped Momentum Expert Bias Updates (SMEBU): A MoE load-balancing scheme using tanh-clamped, momentum-smoothed expert bias updates. "Soft-clamped Momentum Expert Bias Updates (SMEBU)"
- SwiGLU: An activation function variant combining GELU and gated linear units, used in experts’ feed-forward networks. "We use the SwiGLU \citep{shazeer2020gluvariantsimprovetransformer} activation function as the nonlinearity."
- Top-K experts: A routing strategy that selects the K highest-scoring experts for each token. "The Top- experts are selected as follows:"
- truncated normal initialization: Parameter initialization from a normal distribution truncated to a finite range to stabilize training. "All trainable parameters are initialized from a zero-mean truncated normal distribution"
- z-loss: An additional term in the language modeling objective that improves stability or calibration when combined with cross-entropy. "fused cross-entropy and z-loss"
Practical Applications
Immediate Applications
The following applications can be deployed now using the Trinity model family (open weights on Hugging Face) and the paper’s training/infrastructure recipes.
- Enterprise-grade assistants and RAG systems (software; finance; healthcare; legal; government)
- Use case: On‑premise document understanding, retrieval‑augmented generation, and long‑running agent workflows that must satisfy data residency and auditability.
- Why Trinity: Open weights; sparse MoE with only 1–13B parameters active per token; interleaved local/global attention for efficient long‑context inference (128k–512k supported); GQA for small KV caches; gated attention for improved long‑sequence handling.
- Example workflows/products: Privacy‑preserving contract review; regulatory/filing summarization (10‑Ks, clinical protocols); enterprise knowledge bases with long‑document ingestion; on‑prem copilots for secure code and data.
- Assumptions/dependencies: Domain adaptation (SFT/RAG grounding) and safety guardrails are required; GPU availability for inference; evaluate multilingual coverage for non‑English deployments (tokenizer is less optimized for some non‑English scripts).
- Cost‑efficient inference services for long contexts (software; cloud platforms)
- Use case: Offer 128k–512k context chat/completion endpoints at lower cost by leveraging sparse MoE and GQA.
- Why Trinity: 13B active params/token (Large) yields near‑13B inference costs with 400B capacity; local/global NoPE design reduces compute on long inputs.
- Tools/workflows: Triton/vLLM‑based serving with EP+FSDP; KV‑cache aware routing; streaming summarization for archives/emails/logs.
- Assumptions/dependencies: Kernel support for gated attention and SWA; careful memory planning for ultra‑long contexts.
- Domain‑focused fine‑tuning with stable recipes (academia; industry ML teams)
- Use case: Reproduce stable training and SFT without loss spikes using Muon + QK‑norm, depth‑scaled sandwich norm, and the initialization/embedding sqrt(d) scaling.
- Why Trinity: The full stabilization recipe is documented and validated at multi‑trillion token scale.
- Tools/workflows: Fine‑tune with cut cross‑entropy to fit long‑context SFT on commodity GPUs; adopt cosine/linear LR schedules as described.
- Assumptions/dependencies: Muon optimizer availability and correct LR adjustment rule; monitor max attention logits when using Muon.
- MoE training stability upgrades via SMEBU (research labs; foundation model teams)
- Use case: Improve expert load balancing without auxiliary losses by replacing sign updates with tanh‑clamped, momentum‑smoothed expert bias updates.
- Why Trinity: SMEBU reduced router instability in 400B‑parameter MoE training.
- Tools/workflows: Integrate SMEBU into DeepSpeed‑MoE/Megablocks/TorchTitan forks; tune λ, β, κ once per scale; combine with sequence‑wise balance loss.
- Assumptions/dependencies: Framework support for decoupled expert bias updates and Top‑K routing with bias for selection but bias‑free gating.
- Random Sequential Document Buffer (RSDB) for dataloading (all sequence models; ASR/NLP/Vision‑Lang)
- Use case: Reduce batch heterogeneity and gradient norm spikes in online sequence packing with lognormally distributed document lengths.
- Why Trinity: RSDB cut BatchHet by 4.23× and halved loss variance mid‑run.
- Tools/workflows: Package RSDB as a PyTorch DataLoader plugin; monitor BatchHet metric per step; use worker‑sharded buffers and bulk refills for throughput.
- Assumptions/dependencies: On‑the‑fly tokenization; document‑level samples; sufficient RAM for buffering.
- BatchHet as a training health metric (ML Ops; reliability engineering)
- Use case: Early detection of minibatch imbalance, preventing instability and wasted steps.
- Why Trinity: BatchHet correlated with grad‑norm instability and step loss outliers.
- Tools/workflows: Integrate BatchHet into dashboards/alerts alongside gradient norm, loss skew/kurtosis, and router stats.
- Assumptions/dependencies: Access to microbatch losses; consistent logging infrastructure.
- Scalable synthetic data generation pipelines (education; code; multilingual content; policy‑constrained industries)
- Use case: Produce large, license‑clean synthetic corpora (web, code, STEM, multilingual) for pretraining/continued pretraining/domain SFT.
- Why Trinity: Demonstrated 8T+ tokens via Ray + vLLM on Kubernetes with rephrasing/format‑transformation strategies.
- Tools/workflows: Reproducible K8s jobs; content provenance tracking; targeted rephrasing to shift style/pedagogy and structure for downstream quality.
- Assumptions/dependencies: Strong seed data and filters; governance around synthetic content reuse; evaluation loops to avoid model‑mediated data drift.
- Tokenizer design for numeric reasoning and mixed‑script content (finance; data engineering; multilingual apps)
- Use case: Improve arithmetic fidelity and token efficiency via place‑aligned digit chunking and script‑aware pretokenization.
- Why Trinity: Empirically better numeric performance; robust regex pipeline avoiding catastrophic backtracking; strong compression in English/French.
- Tools/workflows: Drop‑in 200k BPE; or adopt the three‑stage digit splitting and script isolation into existing tokenizers; byte‑level fallback.
- Assumptions/dependencies: Re‑training may be needed for specific language distributions; compatibility checks with existing vocabularies.
- On‑prem assistants for sensitive sectors (healthcare; finance; legal; public sector)
- Use case: Deploy chat/coding/retrieval assistants inside controlled environments with auditable weights and data provenance.
- Why Trinity: Open weights + clear data curation narrative; efficient inference per token; long‑context handling for large files/records.
- Tools/workflows: EHR/claims summarizers; internal legal discovery tools; regulated‑market customer support assistants.
- Assumptions/dependencies: Domain‑specific evaluation and safety red‑teaming; PHI/PII handling policies; multilingual coverage as needed.
- Training/inference reliability patterns (infra/SRE for AI)
- Use case: Reduce downtime and MTTR in large training jobs and high‑QPS inference.
- Why Trinity: Proven stack with heartbeat monitoring, fast restart workflows, failover nodes, and NFS optimizations on new GPU generations.
- Tools/workflows: Three‑minute step heartbeats; binary‑search PyTorch nightlies for perf regressions; EP+FSDP group sizing templates.
- Assumptions/dependencies: Access to cluster orchestration and observability; kernel/cuda compatibility on target GPUs.
Long-Term Applications
These opportunities are promising but require further research, scaling, or ecosystem development before broad deployment.
- Frontier‑scale MoE training standardization with SMEBU (AI frameworks; chip vendors)
- Vision: Make SMEBU‑style continuous, momentum‑smoothed load balancing the default in DeepSpeed/Megablocks/Triton kernels for massive expert counts.
- Potential products: “SMEBU Router” libraries; auto‑tuning of λ/β/κ per layer; router stability dashboards.
- Dependencies: Community benchmarks; convergence guarantees; interop with alternative routing (softmax, sigmoid, auxiliary‑loss) and hierarchical MoE.
- Generalized RSDB for multimodal and streaming training (speech; video; robotics logs)
- Vision: Extend RSDB to multi‑source streams (audio‑text, video‑text) to smooth domain skew and length tails; formalize theory linking BatchHet to optimization noise.
- Potential products: “RSDB++” dataloader SDK with per‑source quotas and dynamic reservoir sizes.
- Dependencies: Tokenization across modalities; throughput‑aware scheduling; reproducibility under distributed sharding.
- Ultra‑long‑context agent systems (legal research; finance; scientific literature mining)
- Vision: Agents that operate over 0.5–2M‑token corpora with hybrid local/global attention, efficient KV management, and retrieval‑free reasoning passes.
- Potential products: Litigation strategy copilots; long‑horizon equity research assistants; “lab book” reasoning systems for experiments.
- Dependencies: Robust length extrapolation beyond training; memory/latency constraints; verifiable reasoning and provenance tracing.
- Regulated synthetic data governance and auditing (policy; compliance; standards bodies)
- Vision: Accepted frameworks for tracking, watermarking, and auditing multi‑trillion token synthetic corpora used in training and mid‑training mixture shifts.
- Potential products: Synthetic data registries; provenance attestations integrated with model cards; “BeyondWeb‑style” rephrasing standards.
- Dependencies: Regulator buy‑in; privacy‑preserving watermarking; risk assessments for synthetic feedback loops.
- Multilingual parity and domain specialization at scale (global enterprises; public sector)
- Vision: Retrain tokenizer and mixtures for CJK and under‑represented languages; deliver parity in long‑context tasks across locales.
- Potential products: Trinity‑Multilingual with improved tokenization; localized legal/healthcare copilots.
- Dependencies: Expanded high‑quality multilingual corpora; script‑specific pretokenization refinements; culturally aware evaluation suites.
- Inference‑time compute scaling for reasoning with sparse MoE (education; scientific computing)
- Vision: Marry Trinity’s efficient MoE with chain‑of‑thought trace generation at 100k+ tokens, adaptively increasing expert compute only when beneficial.
- Potential products: Curriculum designers that plan across entire textbooks; theorem‑aided problem solvers with extended scratchpads.
- Dependencies: Policies for safe/secure long‑trace generation; adaptive routing tied to uncertainty; cost‑aware schedulers.
- Hardware–software co‑design for gated attention and NoPE/global layers (GPU/accelerator vendors; systems)
- Vision: New kernels/schedulers exploiting interleaved local/global patterns, gated elementwise ops, and KV cache compression for better throughput.
- Potential products: Library support for gated‑MHA; NoPE‑friendly attention tiling; EP‑aware router hardware hints.
- Dependencies: Compiler support (Triton/CUDA/ROCm); benchmarking suites; cross‑vendor portability.
- Consumer/edge private assistants with sparse activation (mobile; IoT; personal computing)
- Vision: Trinity‑Nano‑class models with 1B active params/token running privately on high‑end laptops/edge devices for offline summarization and note‑taking.
- Potential products: Private PDF/book summarizers; meeting minute generators; on‑device code helpers.
- Dependencies: Quantization and memory‑efficient KV cache; local/global attention kernels on CPUs/NPUs; battery/thermal constraints.
- Safety, evaluation, and governance for open‑weight long‑context models (policy; enterprise risk)
- Vision: Standardized red‑team protocols and long‑context misuse tests; guardrails that operate over hundreds of thousands of tokens.
- Potential products: Long‑context safety filters; retrieval provenance validators; policy compliance packs for data residency and license audits.
- Dependencies: Shared evaluation corpora; runtime monitors for context‑window abuse; auditable RAG pipelines.
- Training‑monitoring standards built around BatchHet and router health (MLOps; platform vendors)
- Vision: Community metrics for minibatch balance, router entropy, expert utilization skew, and stability leading indicators.
- Potential products: “RouterScope” dashboards; SLA alerts tied to BatchHet thresholds; auto‑mitigation playbooks (buffer resizing, mixture shifts).
- Dependencies: Logging APIs in major trainers; privacy constraints for telemetry; cross‑model comparability.
Notes on assumptions and dependencies across applications
- Model availability: Checkpoints are open, but performance on specific domains/languages may require continued pretraining or SFT.
- Compute constraints: Long‑context inference is memory intensive even with GQA; plan for KV‑cache scaling and paging strategies.
- Framework maturity: SMEBU and RSDB require integration into training stacks; kernels for gated attention and SWA must be available/optimized.
- Data governance: Synthetic data pipelines must manage licensing, provenance, and potential feedback‑loop risks; regulators may require new disclosures.
- Safety and evaluation: Domain deployment (healthcare/legal/finance) needs rigorous evaluation, alignment, and guardrails beyond base model capabilities.
Collections
Sign up for free to add this paper to one or more collections.