- The paper introduces BlueFin, a comprehensive benchmark designed to evaluate LLM agents on complex, multi-step financial spreadsheet tasks.
- The paper details a robust evaluation methodology using 3,225 granular rubric criteria across synthesis, manipulation, and interrogation tasks curated by domain experts.
- The paper reveals that current frontier models score below 50% on key tasks, exposing significant deficiencies in dynamic behavior, integration, and cost-efficiency.
BlueFin: A Benchmark for Evaluating LLM Agents on Financial Spreadsheet Tasks
Introduction and Motivation
BlueFin represents a comprehensive benchmark that rigorously evaluates the capacities of LLMs on synthesis, manipulation, and interrogation tasks focused on spreadsheet workbooks within the domain of professional finance. The design of BlueFin addresses the chronic under-representation of complex spreadsheet workflows in existing AI benchmarks, especially those that mirror the multi-step, contextualized reasoning and manipulation intrinsic to high-value professional finance roles. Unlike existing benchmarks, which mostly limit evaluation to formula generation, atomic manipulations, or question-answering on programmatically verifiable tasks, BlueFin emphasizes tasks with structural, computational, and presentational complexity grounded in domain-specific standards and best practices.

Figure 1: BlueFin is a challenging benchmark for characterizing LLM spreadsheet generation.
Benchmark Design and Task Composition
BlueFin is constructed to reflect the depth and diversity of tasks confronted by financial professionals, with strong emphasis on manipulation tasks that dominate real-world analyst workflows. Task creation involved hundreds of hours of domain expert annotation, review, and rubric design. Rubric criteria were iteratively crafted to ensure fine granularity, high specificity, and alignment with expert human judgement, capturing critical aspects ranging from formula correctness and model integration to output validation, perturbation robustness, and presentation. In total, BlueFin encompasses 3,225 granular rubric criteria spanning 10 synthesis, 82 manipulation, and 39 interrogation tasks.
Task distribution is strategically diverse, covering 5 core financial modeling categories and 16 distinct industries. Annotators contributed high-complexity tasks, each estimated at a minimum of 45 minutes (and frequently hours) for a trained finance professional.
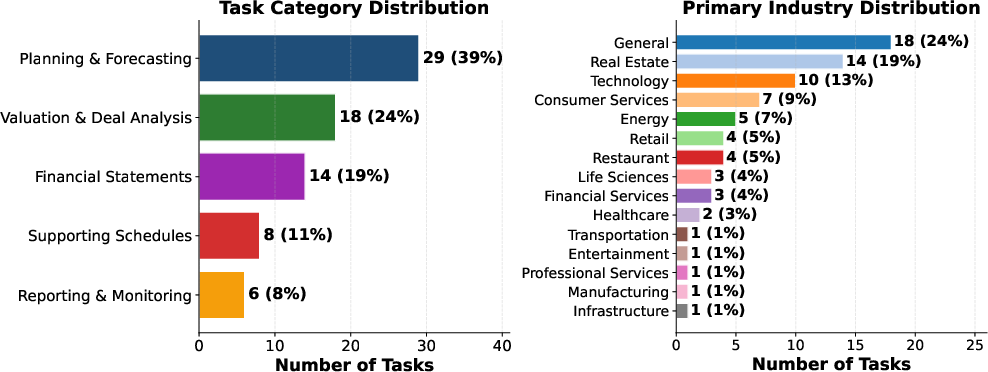
Figure 2: Distribution of manipulation tasks by modeling category and industry; tasks cover key sectors and reflect real diversity in the financial modeling landscape.
The harness delivers 20 agentic tools that collectively cover the spreadsheet lifecycle, exposing both low-level and batch primitives, including read and write accessors, formatting APIs, structural updates, recalculation, and a restricted code execution environment.
Evaluation Methodology
Grading in BlueFin relies on an agentic LLM "judge" (GPT-5.4), operated under a rigorously designed, domain-specific prompt. The judge interacts with outputs using the same toolset as the evaluated agent, enabling direct structural and behavioral interrogation. For synthesis and manipulation, rubric compliance is binary for each criterion, with penalties for clear spreadsheet errors (e.g., hardcoding, reference breaks, or presentation defects) and bonuses for robust integration and presentational fidelity. High inter-rater reliability is validated via Krippendorff’s Alpha (0.826).
For interrogation (comprehension) tasks, model answers are decomposed into component-level comparisons with the gold standard, with normalization for minor notational variants and strict checking of quantitative tolerances.
Empirical results indicate that even "frontier" closed-source LLMs (Claude Opus 4.7, GPT-5.5, Gemini 3.1 Pro, Claude Sonnet 4.6, Grok 4.20) demonstrate consistently sub-50% average task scores, reflecting persistent deficiencies in both static construction and especially dynamic behavior.
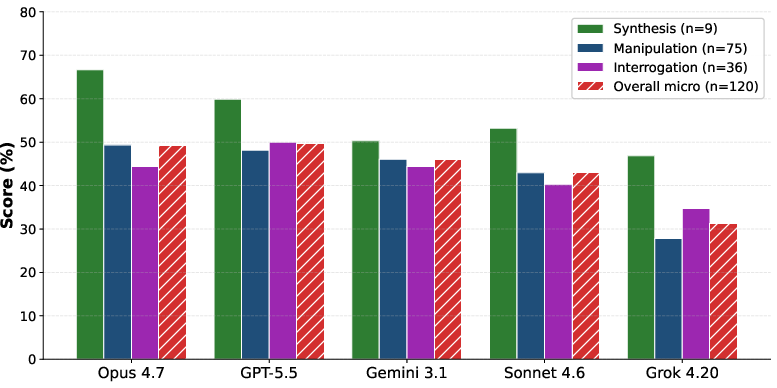
Figure 3: Held-out performance by task type; all evaluated models remain below 50%—performance profiles are notably lower than in code-centric benchmarks such as SWE-bench Pro.
The highest aggregate performance is on synthesis tasks, but manipulation tasks—where integration constraints and legacy workbook dependencies are more salient—reveal severe performance limitations.
Failure Mode Analysis
Detailed rubric-based analysis provides granular insight into salient weaknesses:
- Formula Correctness: The most reliably passed criteria, with scores between 50–68%. Structural/syntactic checks are less demanding.
- Output Validation & Perturbation: Models perform significantly worse (20–48% for output, 15–37% for perturbation), revealing substantial deficits in dynamic consistency and the avoidance of hardcoded or partial recalculation errors. This exposes material gaps relative to human analyst expectations.
- Presentation & Pitfalls: Formatting, labeling, and avoidance of errors receive variable attention from models. Notably, some models (e.g., Grok) have low completion rates, misleadingly inflating pitfall pass rates.
Model performance is heavily right-skewed: few tasks reach 70% and a non-trivial portion are below 30%, signaling that large fractions of the real-world task as operationalized are unsolved by LLMs.
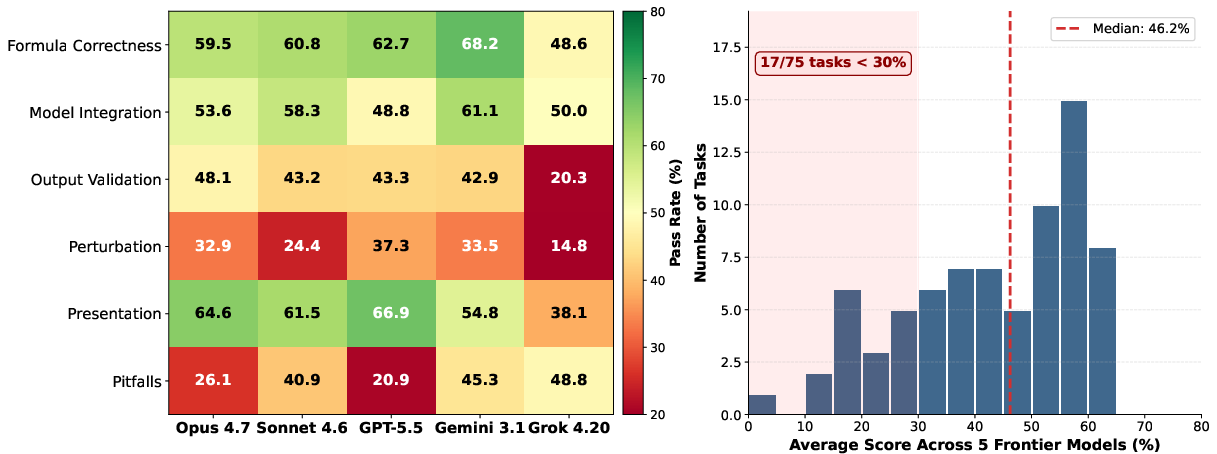
Figure 4: (a) Section-level pass rates show highest reliability for formula structure, but major degradation on output/perturbation/dynamic tests. (b) Distribution of per-task average scores reveals a median below 50% and no tasks exceeding 70%.
BlueFin quantifies the cost-efficiency landscape, showing that higher-cost models (e.g., Claude Opus 4.7) are frequently not on the cost-quality Pareto frontier. For example, GPT-5.5 achieves parity with Opus at more than fivefold lower dollar cost per task.
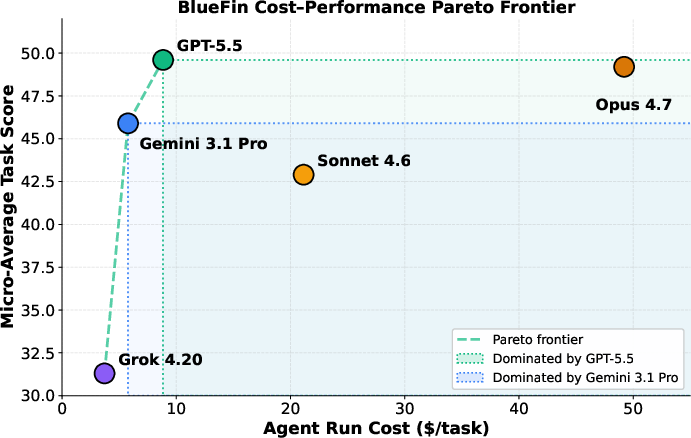
Figure 5: Cost-quality Pareto front for agent runs shows GPT-5.5 and Gemini 3.1 Pro strong in both efficiency and aggregate score, with Opus fully dominated.
This observation is relevant for practical deployment—cost-efficient models may be sufficient or dominant for routine construction, reserving premium models for tasks with greater ambiguity or where reasoning depth justifies the spend.
Model Behavioral Profiles
Qualitative trajectory analysis reveals distinct behavioral priors:
- Opus: Tends toward broader workbook reads, cost-dense bulk formula writes, and verbose outputs, resulting in higher costs.
- GPT-5.5: Favors openpyxl programmatic manipulation, leading to lower turn counts but sometimes less numeric validation.
- Gemini: Excels in structural routines via targeted reads, efficient formula copying, and recalculation.
- Sonnet & Grok: Often fail to recalculate, leading to poor dynamic robustness, and Sonnet sometimes delivers ineffectual no-op trajectories.
Implications and Limitations
BlueFin demonstrates that LLM agents, as currently instantiated, do not robustly address the multi-dimensional demands of professional spreadsheet construction—especially with respect to implicit domain conventions, robust integration, and tolerance to perturbation. This result has strong implications for both practical adoption and research. In professional settings, substitution of human labor by LLM agents on realistic spreadsheet tasks yields outputs requiring substantial post-editing and dynamic checking.
Beyond performance, the high cost and annotation burden to construct BlueFin highlight core challenges for specialized domain benchmarks—chiefly around artifact procurement, annotation quality, and rubric alignment. Moreover, the strictly single-artifact context for BlueFin precludes multi-artifact or retrieval-augmented scenarios commonly seen in enterprise pipelines.
Future Directions
Several research and engineering directions are highlighted by this work:
- Custom Harness Optimization: Exploring model-harness co-design for further performance gains.
- Automated Rubric Generation: Scaling up complex benchmarks while controlling annotation cost via more intelligent, LLM-aided task and criterion generation.
- Tool Use Generalization: Investigating scaffolding that enables models to correctly leverage recalc, validation, and multi-step integration primitives.
The current release provides extensive baselines for future model improvements targeting the high-value spreadsheet reasoning and execution domain.
Conclusion
BlueFin establishes a new, rigorous standard for evaluating LLM agent performance on realistic and highly consequential spreadsheet tasks in finance. Despite rapid progress on structured reasoning benchmarks in code and mathematics, state-of-the-art LLMs remain below 50% pass rates on BlueFin, especially in dynamic behavior and integration. The benchmark, codebase, and evaluation pipeline set a foundation for future research, addressing both technical and applied challenges at the intersection of AI and professional spreadsheet workflows in finance.
Figure 6: Contributor onboarding sequence included training modules to calibrate understanding of frequent errors and task-quality issues.