- The paper introduces a reinforcement learning framework for training LLM agents on realistic Excel tasks using authentic data and multi-turn interactions.
- It combines a native Excel gym, structured tool interfaces, and automated data collection to achieve significant Pass@1 improvements across diverse domains.
- Outcome-based rewards and asynchronous RL drive policy optimization, reducing errors and enhancing task efficiency in complex spreadsheet operations.
Authoritative Summary of "Spreadsheet-RL: Advancing LLM Agents on Realistic Spreadsheet Tasks via Reinforcement Learning" (2605.22642)
Motivation and Problem Statement
Spreadsheet-centric workflows underpin data processing across both individual and enterprise domains—from finance and analytics to logistical planning. Despite a surge in agentic research, most spreadsheet automation efforts depend primarily on prompt engineering for general-purpose LLMs, which are efficient at atomic operations but ineffective at multi-step, long-horizon manipulations characteristic of realistic spreadsheet tasks. Prior specialized agents either rely on closed training infrastructure, proprietary datasets, or narrowly scoped benchmarks, resulting in brittle generalization and limitations on reproducibility.
"Spreadsheet-RL" proposes an end-to-end, reinforcement learning (RL)-based paradigm specifically curated for training LLM spreadsheet agents within a faithful Microsoft Excel environment. The framework systematically bridges robust data collection from real spreadsheet problems, domain-specific benchmarks, a spreadsheet-native gym with structured tool interfaces, and outcome-driven RL post-training.
Framework Architecture
Spreadsheet-RL comprises four principal modules:
- Automated Data Agent: This module autonomously constructs large-scale paired initial-final spreadsheet datasets from public forums, preserving realistic task and operation distributions beyond synthetic or exclusively human-annotated datasets.
- Spreadsheet Gym Environment: Operating within real Excel, the gym exposes a versatile Python sandbox and a spreadsheet-native harness, enabling interleaved reasoning, comprehensive tool use, and robust state management for multi-turn task execution.
- Structured Tool Harness: The framework presents a domain-specific action space, with granular tools (inspection, structural edits, formula propagation, verification) and robust workflow enforcement (inspection, modification, verification loops), reducing low-level execution failures—particularly in small and mid-scale LLMs.
- Asynchronous RL Pipeline: RL post-training leverages GRPO objectives with verifiable, outcome-based rewards, scaling to sparse, terminal signals and batching large training volumes within the VeRL framework.
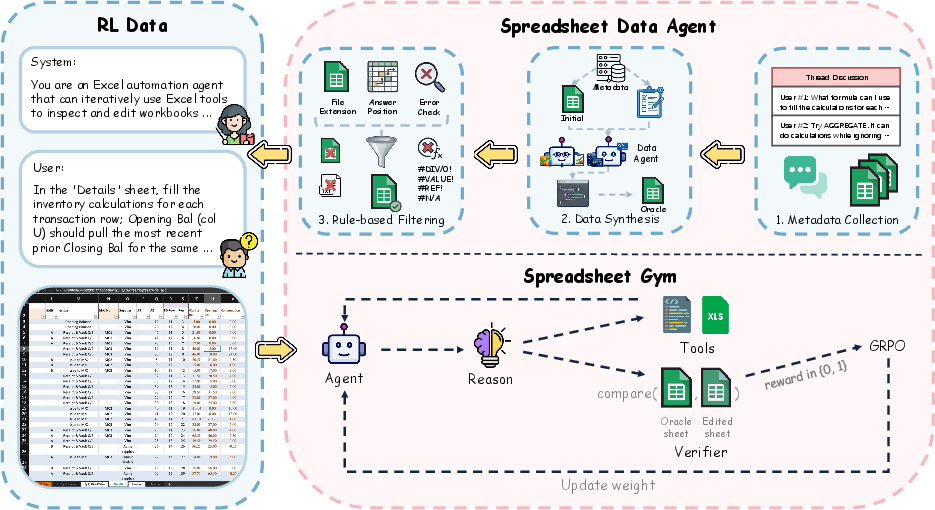
Figure 1: Overview of Spreadsheet-RL depicting the pipeline from dataset construction to policy optimization in the Spreadsheet Gym.
Data Construction and Domain Benchmarks
Training data is sourced by the Spreadsheet Data Agent, which autonomously scrapes and curates thousands of forum tasks (ExcelForum). This pipeline employs coding agents for oracle spreadsheet construction and enforces quality via automated validation and filtering, yielding 5,928 high-fidelity tasks with task diversity across formulas, formatting, structural edits, and complex workflows.
The Domain-Spreadsheet benchmark comprises 1,660 professional spreadsheet tasks spanning finance (beginner to advanced), supply chain, HR, sales, and real estate. Distinct from operation-centric prior datasets, Domain-Spreadsheet captures domain-specific analytical workflows, facilitating rigorous evaluation of cross-domain agent generalization.
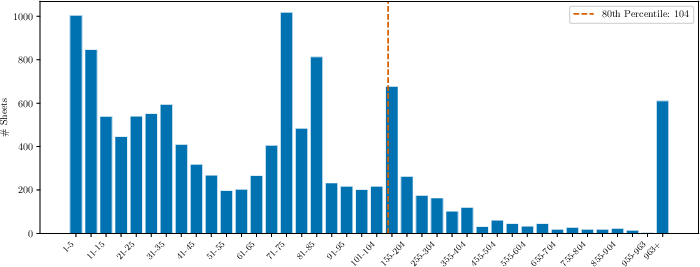
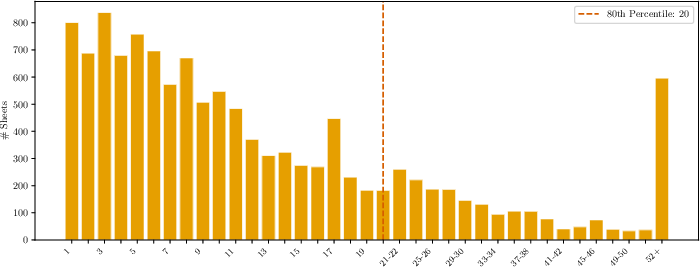
Figure 2: Distribution of row counts across initial spreadsheets in the RL training dataset.
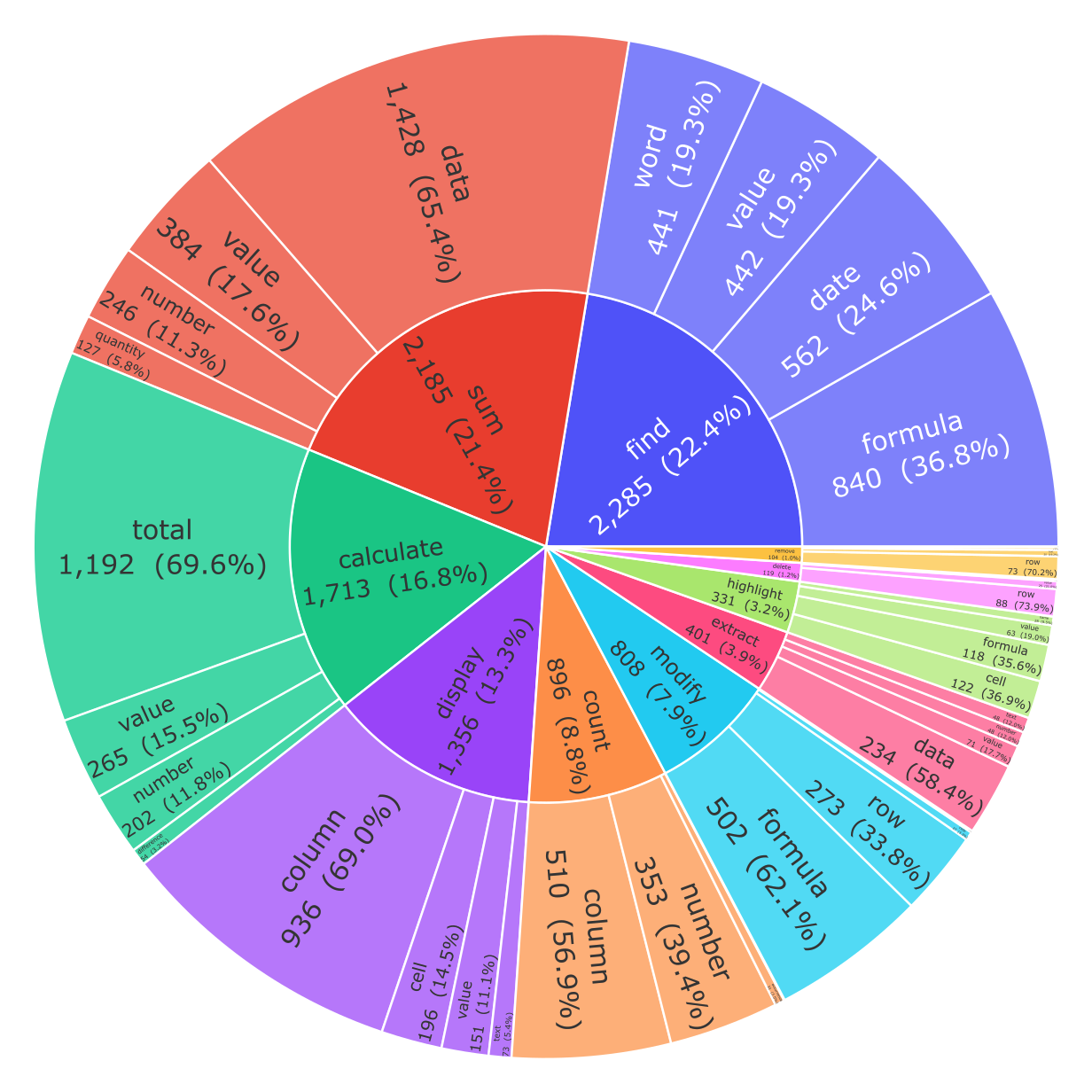
Figure 3: Distribution of sheet operations within the RL training data, emphasizing diversity and realistic task coverage.
RL Training Protocol
The RL policy operates by receiving (initial spreadsheet, natural language instruction, tool interface protocol), generating a sequence of reasoning steps and tool calls per turn, iteratively interacting with Spreadsheet Gym. Terminal rewards are computed by cell-level comparison between the agent-produced terminal state and oracle outcome—with value-level and formula-level fidelity.
Outcome-based rewards, implemented via asynchronous Excel recalculation and comparison APIs, are optimized under a KL-regularized GRPO framework. The RL objective directly encourages trajectory-level task success and efficiently penalizes divergence from reference policy, leveraging group-based Monte Carlo baselines. This enables scalable training in highly asynchronous, long-horizon settings.
Experimental Evaluation
Setup
- Agent: Qwen3-4B-Thinking-2507 as base model.
- Environment: Spreadsheet Gym with Excel 365 (version 2512).
- Training: 60 RL steps, asynchronous VeRL pipeline, batch size of 64, rollout group size of 16.
- Evaluation: Pass@1 on SpreadsheetBench (912 tasks, three-fold cases) and Domain-Spreadsheet (1,660 tasks).
Key Results
- SpreadsheetBench: RL post-training improves Qwen3-4B-Thinking-2507 Pass@1 from 12.0% to 23.4%. Sequential improvements arise from harnessing (15.6%), comprehensive tool addition (19.3%), and final RL optimization (23.4%).
- Domain-Spreadsheet: RL-trained agent achieves Pass@1 of 17.2%, doubling accuracy from the base (8.4%). Largest gains on finance workflows; moderate improvements in supply chain, HR, and sales; negligible progress in real estate.
- The RL agent outperforms representative open-source baselines and matches/exceeds proprietary baseline performance (e.g., OpenAI o3), all within a fully reproducible environment.
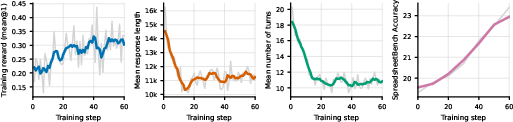
Figure 4: RL training dynamics for Qwen3-4B-Thinking-2507, showing improvement in reward, response length, and interaction efficiency over training steps.
Training Dynamics
Training reward increases from 0.21 to 0.33; task accuracy rises steadily. RL training reduces interaction verbosity and number of turns, indicating improved efficiency and adherence to protocol. Qualitative analysis confirms gains in protocol-following, alternative planning, and reduced error-prone speculative behaviors.
Theoretical and Practical Implications
Spreadsheet-RL demonstrates that domain-specific RL is effective for tool-rich, highly interactive environments like spreadsheets—where outcome-based, verifiable rewards enable systematic policy improvement not achievable through prompt engineering or generic SFT. Structured tool interfaces, harness protocol, and environment isolation are essential for minimizing brittle reasoning, especially in smaller LLMs.
Practically, Spreadsheet-RL's unified pipeline enables reproducible research and development of open-source spreadsheet agents, significantly advancing automation capabilities in professional data workflows. The domain-generalization experiments underscore the viability of RL-trained agents for cross-domain tasks, motivating expansion into new professional domains and more complex LLM architectures.
Theoretically, the approach reinforces outcome-driven RL as a scalable paradigm for agent training on long-horizon, high-fidelity tasks requiring semantic and structural reasoning. The empirical results and design choices suggest promising directions for scaling RL post-training to larger model families, mixture-of-experts architectures, and multimodal settings.
Future Directions
- Scaling RL post-training to larger LLMs and MoE architectures to further close the gap with proprietary agent solutions.
- Expanding tool interface coverage, including advanced formatting and VBA/macros, and incorporating multimodal reasoning capabilities.
- Integrating human-in-the-loop feedback for safety and robustness in high-stakes enterprise workflows.
- Extending benchmarks and datasets to include additional domains, challenging collaborative tasks, and broader data-centric interface automation.
Conclusion
Spreadsheet-RL establishes outcome-based RL as a core post-training strategy for spreadsheet agent automation, emphasizing reproducibility, scalability, and domain generalization. The framework's staged improvements, from harness protocol to RL fine-tuning, yield significant gains in task accuracy and operational efficiency for open-source LLM agents. The release of data, environment, harness, pipeline, and agent models enables future research in agentic spreadsheet automation and, more broadly, LLM-based interaction with professional data interfaces.