- The paper’s main contribution is its dual-actor architecture that decouples reward maximization from smoothness supervision to achieve zero-phase action smoothing.
- It leverages a Savitzky–Golay filter and magnitude-matched MSE loss to obtain up to 21× steering jitter reduction while maintaining near-parity in rewards.
- Empirical results on MetaDrive and Webots ACC demonstrate that ZAPS-DA can effectively suppress temporal jitter, providing a robust and scalable solution for continuous control tasks.
ZAPS-DA: Architectural Decoupling for Zero-Phase Jitter Suppression in RL
Introduction and Motivation
Temporal inconsistency in action sequences—commonly referred to as action jitter—is a persistent failure mode of off-policy RL algorithms in continuous control, particularly when deploying feed-forward policies trained with agents such as Soft Actor-Critic (SAC). The paper "ZAPS-DA: Zero-Phase Action Policy Smoothing with Decoupled Actor for Continuous Control in Reinforcement Learning" (2605.30612) addresses this issue by proposing ZAPS-DA, a training-time architectural framework that leverages non-causal smoothness oracles—zero-phase filters—while maintaining causal, low-latency action selection at deployment.
Conventional approaches, such as applying low-pass filters post-hoc or directly regularizing the actor loss, are criticized for introducing undesirable phase lag or coupling reward maximization and smoothness objectives in a way that either saturates the dual variable or destabilizes learning. The core contribution of ZAPS-DA is the strict decoupling of the RL reward objective and the smoothness supervision, allowing the separately trained decoupled actor to distill zero-phase smoothness without requiring future context or additional filtering infrastructure at deployment.
ZAPS-DA Framework
ZAPS-DA introduces a dual-actor architecture in which the main actor πϕ is trained using vanilla SAC, and a separate decoupled actor πψ is trained via supervised regression to zero-phase-filtered action targets. The deployment strategy shifts entirely to the decoupled actor, which operates as a standard feed-forward policy from current observation to action—crucially, it does not require action history or lookahead filtering at inference.
This is enabled by maintaining a replay buffer in which each transition is augmented with a zero-phase-filtered action label, produced using a Savitzky–Golay (SG) filter operating non-causally over a centered window within a fixed-length history buffer.
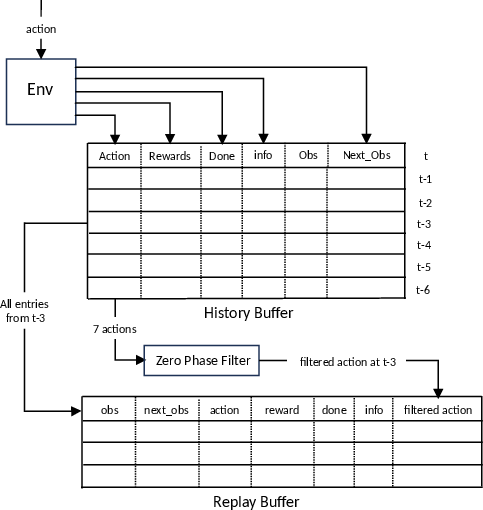
Figure 1: ZAPS-DA training-time data flow, with the environment wrapper appending transitions to a history buffer and pushing SG-filtered actions as supervisory targets.
The decoupled actor is trained with a magnitude-matched MSE loss, using a dynamically computed scaling factor that ensures robust optimization across both adaptive (e.g., Adam) and non-adaptive (e.g., SGD) optimizers, thus guaranteeing hyperparameter-free portability and avoiding training instabilities from mismatched gradient magnitudes.
Empirical Evaluation
The dual-actor ZAPS-DA framework is evaluated on two distinct continuous-control environments: MetaDrive (procedural autonomous driving) and a custom Webots adaptive cruise control (ACC) simulation. Both environments lack explicit smoothness rewards in their native configurations, with Webots exhibiting mildly smoothness-friendly reward shaping. The empirical protocol utilizes strict paired-seed evaluation to control for rollout stochasticity, and reports results over large batched episode samples (n=150, multiple seeds).
In MetaDrive, ZAPS-DA achieves steering jitter reductions of $14$–21× and throttle jitter reductions of $3$–5× across all step-difference metrics (JE, MAD, MDD, variance) with maintained task completion statistics and a marginal reward penalty (6.3%), which is shown to be sensitive to the SG window size—effectively a Pareto knob between smoothness and fidelity to the SAC baseline.
The qualitative effect is visualized by inspecting command traces:
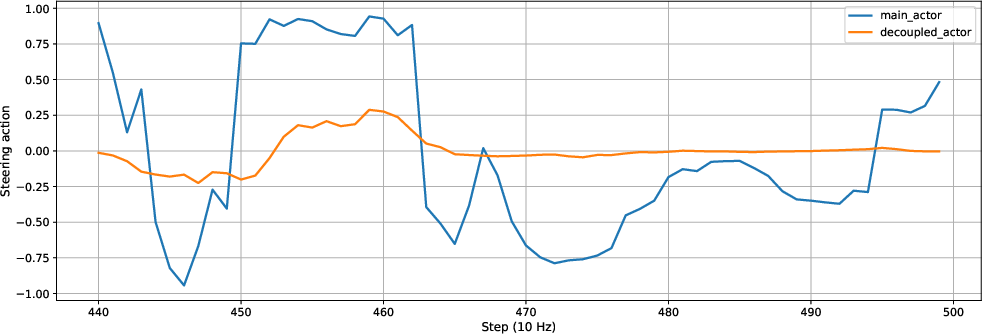
Figure 2: Decoupled actor steering commands attenuate high-frequency oscillations while closely tracking the mean intent of the main actor.
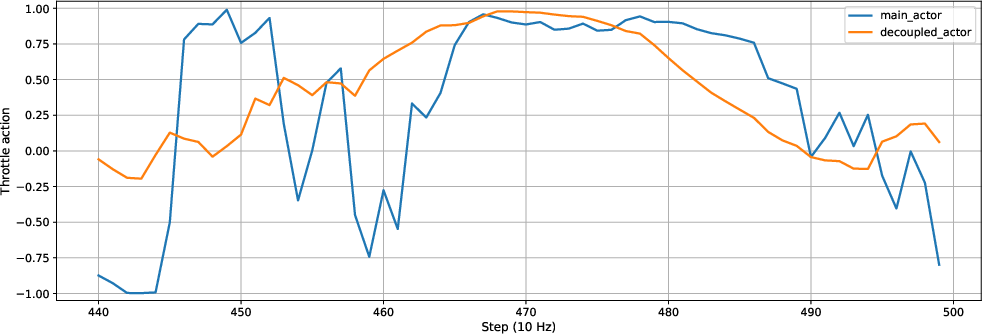
Figure 3: The throttle control trace shows reduced rapid reversals without introducing observable lag, maintaining the envelope of vehicle acceleration and deceleration.
Spectral analysis further corroborates the frequency-domain attenuation:
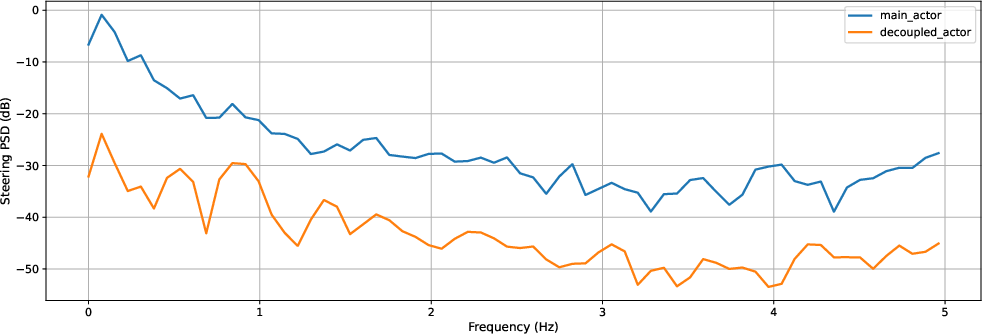
Figure 4: Steering action power spectral density reveals 10–20 dB attenuation of high-frequency components with the decoupled actor.
Webots ACC Results
On the Webots ACC task, ZAPS-DA yields reward parity (+0.9\%), steering jitter reductions up to 45×, and a task-failure rate reduction from 2.0% to πψ0. This demonstrates that when environmental rewards are mildly smoothness-aligned, ZAPS-DA can deliver a strict Pareto improvement.
Ablation Studies
Smoothness–Reward Tradeoff
SG window sweep experiments confirm the existence of a Pareto frontier: increasing window size monotonically increases smoothness at the cost of reward until excessive windowing induces negative side-lobe artifacts, deteriorating both metrics. The necessity of narrower smoothing on throttle is empirically validated; over-smoothing this axis directly increases collision rates due to under-responsiveness.
Magnitude-Matching Portability
Optimizing the decoupled actor with SGD without magnitude-matching results in catastrophic training collapse, confirming the scaling mechanism’s essentiality for optimizer-agnostic deployment. In contrast, Adam's effective scale-invariance renders the matching step redundant, but including it incurs no negative side-effects.
Theoretical and Practical Implications
ZAPS-DA’s architecture formally demonstrates that distilling a non-causal oracle into a causally deployed policy is practical and effective for jitter suppression, without compromising step-wise reactiveness or incurring deployment latency. This decoupling paves the way for leveraging more sophisticated temporal-smoothing or lookahead supervision strategies—including learned kernel filters or offline optimal control signals—extending far beyond hand-crafted smoothness losses or action-conditioned architectures.
From a safety and reliability standpoint, the framework removes the need to artificially tune smoothness–reward coefficients or to develop architectures that maintain action history, offering a robust, interpretable, and easily retrofittable path toward actuator-friendly policy deployment in physical systems.
Limitations and Future Directions
The study is confined to SAC and feed-forward MLPs in simulation, with smoothness supervision restricted to a fixed SG filter. Generalization to other zero-lag temporal operators (e.g., Butterworth via filtfilt, learned filters), broader action domains (manipulation, legged locomotion), and deployment on real hardware remain open areas for future exploration. Real-world validation would need to account for sensor noise, actuator dynamics, and unmodeled degradation, potentially revealing new challenges or necessitating additional robustness mechanisms.
The potential interplay between the zero-phase filter and more complex reward structures or adversarial environments also warrants further investigation.
Conclusion
ZAPS-DA provides a rigorous and extensible methodological advance for mitigating action jitter in continuous-control policies trained by off-policy RL, achieving state-of-the-art suppression while retaining reward-optimality parity (or achieving a favorable smoothness–performance tradeoff). Its architectural principle—that non-causal supervision can be distilled via decoupled actors into causal, real-time policies—constitutes a generalizable paradigm for embedding trajectory-level structure into deployed agents. This decoupling enables flexible application of sophisticated temporal or domain-specific supervision during training, without sacrificing simplicity and responsiveness at deployment.