- The paper introduces Sim2Sim2Sim, a three-stage dynamics distillation pipeline that accelerates RL policy training by up to 3,000× for autonomous driving control.
- It evaluates four dynamics models—from a kinematic baseline to a residual transformer—demonstrating that physically grounded models yield smoother, safer policies.
- The paper shows that robust policy transfer under abrupt friction changes relies on diverse training and reduced dependence on explicit surface labels.
Dynamics Distillation for Efficient and Transferable Control Learning
Framework Overview
The paper introduces the Sim2Sim2Sim framework, targeting efficient and transferable reinforcement learning (RL) for control policy optimization in autonomous driving scenarios, particularly under challenging vehicle dynamics such as abrupt friction transitions. The key innovation is a three-stage pipeline where high-fidelity simulator dynamics are distilled into a learned transition model, enabling scalable RL policy training in a fast, parallelized environment. Finally, learned policies are deployed back into the original high-fidelity simulator for closed-loop evaluation.
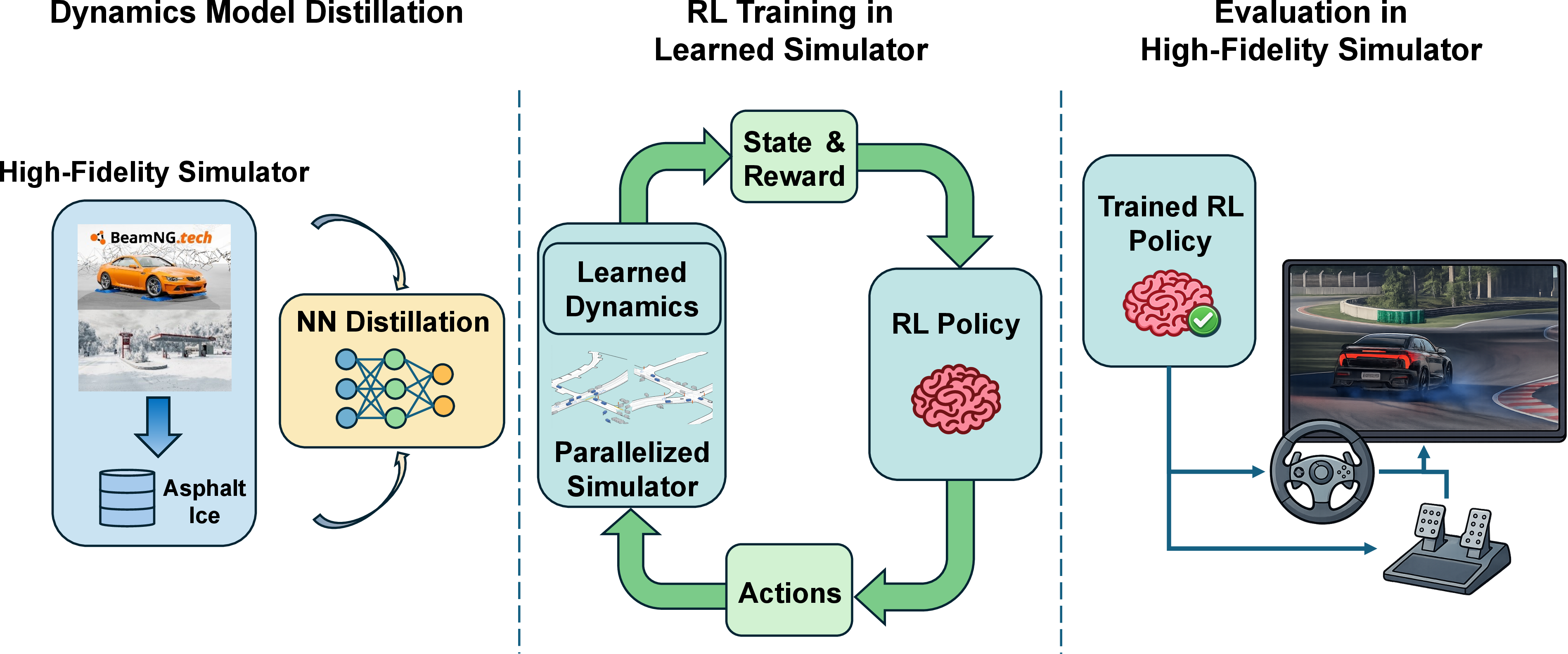
Figure 1: The Sim2Sim2Sim pipeline integrates dynamics distillation, scalable policy training, and zero-shot deployment to high-fidelity evaluation environments.
Dynamics Model Distillation
Sim2Sim2Sim leverages BeamNG.tech as the high-fidelity source for vehicle dynamics, which are distilled into several classes of learned models integrated into GPUDrive for large-scale policy training. Four model families are instantiated:
- Kinematic Model with Learned Actuation: Baseline, lightweight, but limited under low-friction/complex maneuvers.
- Physics-Constrained Deep Dynamics Model (DDM): Augments a dynamic single-track formulation with recurrent parameter estimation and Physics Guard mechanisms.
- Transformer Dynamics Model: Purely data-driven sequence prediction, optionally surface-conditioned.
- Residual Learning Hybrid: Transformer-based residual corrections layered atop DDM, capturing surface-dependent deviations.
These models operate under a unified interface, receiving state–action histories and optional surface labels, trained on a substantial dataset encompassing both nominal asphalt and friction transition scenarios.
RL Policy Optimization in Distilled Dynamics
Policies are trained inside GPUDrive, with the distilled dynamics models serving as custom transition operators. The policy observation combines ego-state data and planned trajectory waypoints extracted from real-world driving logs (WOMD/E2E). The policy architecture employs MLPs for state encoding, a Transformer for trajectory processing, and outputs normalized control actions. Reward design follows multiplicative progress-penalty structure, highly sensitive to tracking errors and scenario termination.
Training in GPUDrive enables throughput on the order of 6,000 SPS, with policies attaining 150M steps in ~7 hours, a throughput improvement by approximately 3,000× compared to direct high-fidelity simulator training. Policy inference latency remains below 2 ms, satisfying real-time control demands.
Closed-Loop Policy Behavior and Dynamics Model Evaluation
The paper demonstrates that open-loop predictive accuracy does not directly translate to downstream policy robustness. The expressive Transformer dynamics model achieves superior multi-step displacement errors under open-loop rollout, but its corresponding policies exhibit increased collision and off-road rates in closed-loop RL evaluation, suggesting exploitation of model artifacts not representative of real-world or high-fidelity dynamics.
Conversely, physically grounded models (DDM/residual hybrids) induce more conservative policy behavior and smooth control, yielding improved tracking and transferability upon deployment in high-fidelity simulation. Policy performance is critically modulated by observation design: deprived of lateral velocity and yaw rate, policies severely degrade in tracking and robustness, regardless of dynamics backend.
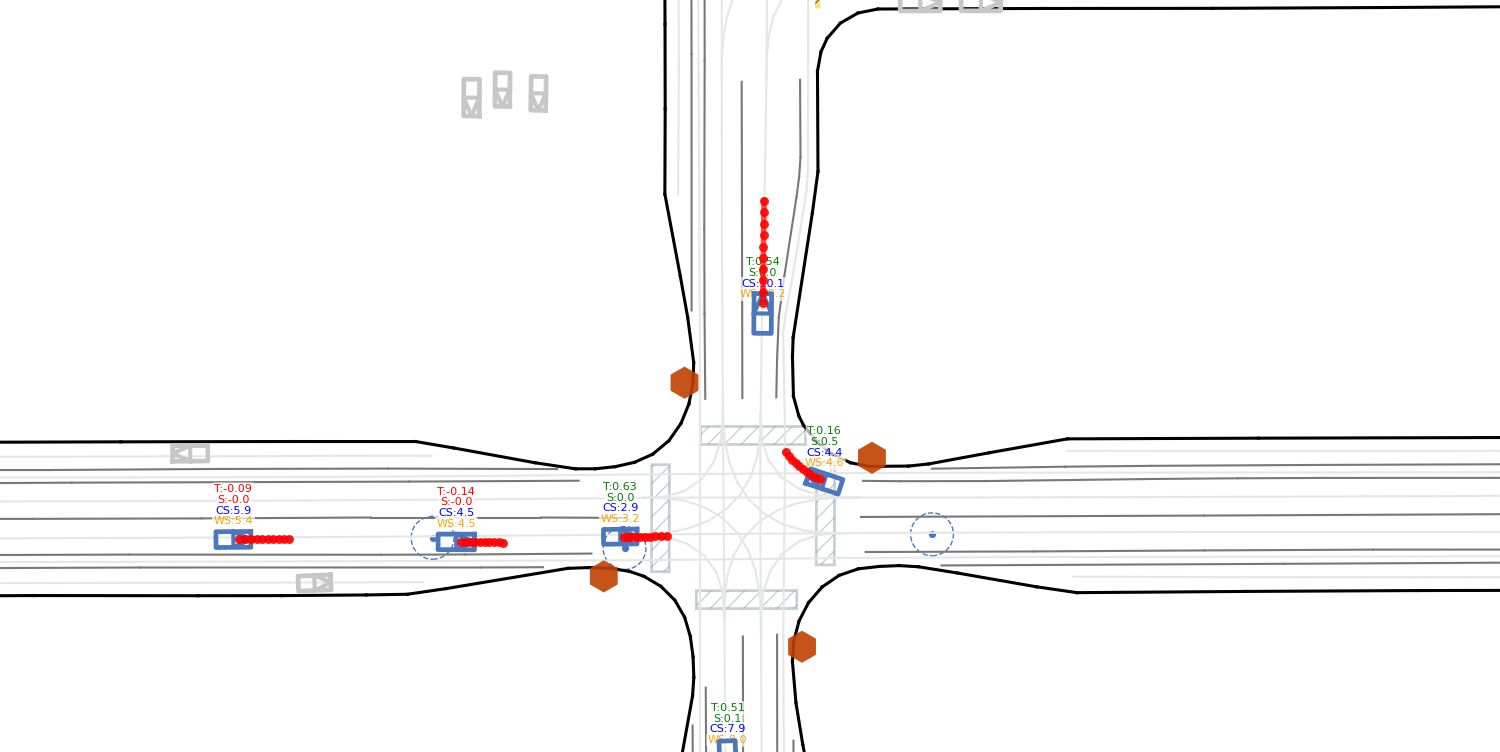
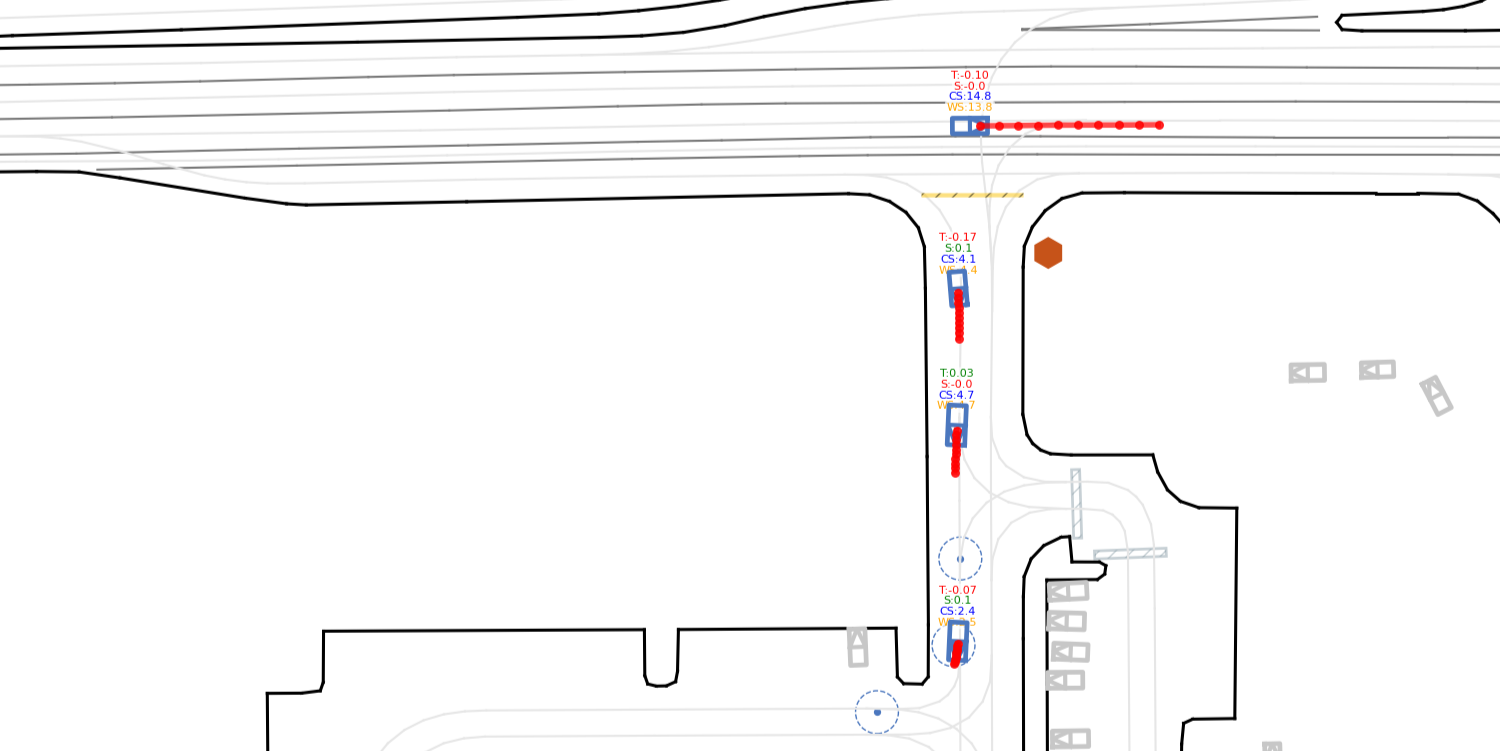
Figure 2: Policy generalization is encouraged by the diversity of driving scenarios, agent interactions, and trajectory complexity in WOMD validation splits.
Transfer and Robustness under Abrupt Dynamics Shifts
Zero-shot transfer is evaluated on the Putnam Park Road Course in BeamNG under nominal and friction-varying conditions. Policies trained in GPUDrive using DDM-based dynamics demonstrate successful completion and superior tracking error under nominal conditions. When ice patches are introduced, only policies exposed to friction variability during training achieve reliable performance, with distance traveled before loss of control increasing by more than 50%—for DDM + residual conditioning, policy completion rises from 40.4% to 83.4% of track length, and heading error drops.
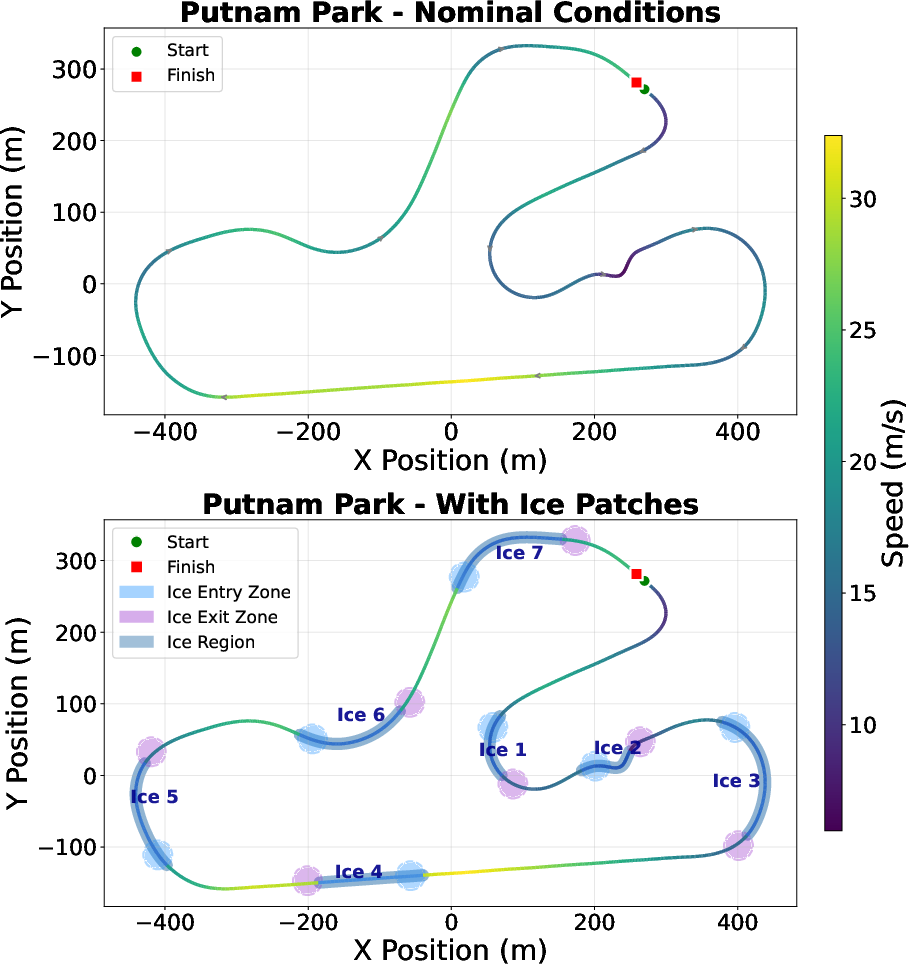
Figure 3: Evaluation tracks with manually introduced ice patches assess policy robustness to sudden surface transitions in BeamNG.
Surface conditioning during training further modulates robustness, but explicit surface labels in policy observation can decrease transfer reliability: label-independent policies outperform label-conditioned ones under friction shift, demonstrating that reliance on physical feedback yields more stable policy generalization when dynamics models are imperfect.
Implications and Theoretical Insights
The Sim2Sim2Sim methodology formalizes dynamics distillation as a paradigm for reconciling scalable RL training with faithful physical replication. The paper empirically supports two nuanced claims:
- Open-loop prediction error alone is insufficient for characterizing the suitability of a learned dynamics model as an RL environment.
- Structural inductive bias and rich training diversity jointly determine robustness, whereas explicit context conditioning or history-encoded adaptation is non-essential given sufficient exposure to out-of-distribution conditions.
These findings suggest that future AI systems for control should focus not merely on predictive performance, but on the interplay between dynamics model capacity, policy learning incentives, and environment diversity. Research directions include more generalizable world model architectures [Li2025RWM], iterative aggregation strategies for reducing model exploitation, and cross-modality integration to accommodate sensor-rich autonomy stacks.
Conclusion
Sim2Sim2Sim establishes dynamics distillation as a practical bridge between high-fidelity vehicle simulation and scalable reinforcement learning policy optimization. The framework enables efficient training and reliable policy transfer to realistic environments, robustly handling abrupt dynamics variations without fine-tuning. Theoretical and empirical analyses uncover the limitations of predictive accuracy as a sole metric for dynamics models, underscoring the necessity of combined structural priors and distributional exposure. The approach informs future developments in robust, scalable RL for safety-critical autonomous systems and paves the way for integrated world modeling advancements in AI control research.