- The paper introduces Soft-DPG, leveraging Gaussian smoothing at the Bellman level to eliminate explicit action-gradient dependency for stable policy optimization.
- It formulates Soft-DDPG, which employs Monte Carlo sampling of perturbed actions to robustly update policies, showing significant gains over standard DDPG in discrete reward environments.
- Empirical results on MuJoCo and Gym benchmarks confirm that Soft-DPG enhances stability and improves final returns, particularly under non-smooth and sparse reward conditions.
Soft Deterministic Policy Gradient with Gaussian Smoothing: A Technical Essay
Motivation and Theoretical Foundations
Deterministic Policy Gradient (DPG) algorithms have dominated continuous control in RL due to their efficient, low-variance gradient estimation. However, the key assumption underlying DPG—the differentiability of the critic with respect to action—fails in practical scenarios involving sparse or discretized rewards, which often produce irregular, non-smooth action-value surfaces. This induces instability and ill-defined gradients during actor updates. The paper introduces Soft Deterministic Policy Gradient (Soft-DPG), leveraging Gaussian Smoothing (GS) at the Bellman operator level to establish a robust policy gradient formulation that eliminates explicit dependency on critic action-gradients.
The central theoretical contribution is the introduction of a σ-smoothed Bellman equation. This constructs an action-value function, Qσπ, directly as the fixed point of a smoothed Bellman expectation operator. Qσπ is constructed to ensure well-behaved, stable gradients, even when the underlying MDP produces non-smooth Q-functions. Analytical upper bounds are established for the bias between Qπ and Qσπ, with the bias controllable by the smoothing parameter σ and dependent on Lipschitz continuity constants of the reward and transition dynamics.
Algorithmic Instantiation: Soft-DDPG
The theory is instantiated into a practical algorithm, Soft Deep Deterministic Policy Gradient (Soft-DDPG). Unlike standard DDPG—which estimates actor gradients using ∇aQ(s,a)—Soft-DDPG instead generates policy updates via Monte Carlo sampling from Gaussian-perturbed actions, evaluated on the learned Qσπ. Actor updates rely only on the evaluations of Qσπ at perturbed actions, obviating the need for an explicit action-gradient. The critic is trained via targets sampled from the smoothed Bellman operator, ensuring consistency with the theoretical fixed point.
This architecture directly addresses the instability observed when operating in environments with discrete rewards, as demonstrated by visualizations showing the pathologies of critic action-gradients under DDPG. The landscape produced by Soft-DDPG is markedly smoother and yields more informative gradient signals for policy improvement.
Empirical Validation and Numerical Analysis
Extensive empirical evaluations are performed on standard MuJoCo benchmarks and their discretized-reward variants. Results indicate that Soft-DDPG maintains competitive performance in dense-reward settings and consistently outperforms standard DDPG in most environments with discrete or sparse reward surfaces. There is clear evidence that, in discrete-reward tasks such as Ant, HalfCheetah, Hopper, Walker2d, Inverted Pendulum, and Inverted Double Pendulum, Soft-DDPG demonstrates superior stability and final returns. Notably, numerical results indicate absolute improvements in mean scores under discrete reward settings—e.g., in Ant (Discrete) environments, mean scores increase from 190.56±60.23 (DDPG) to Qσπ0 (Soft-DDPG).
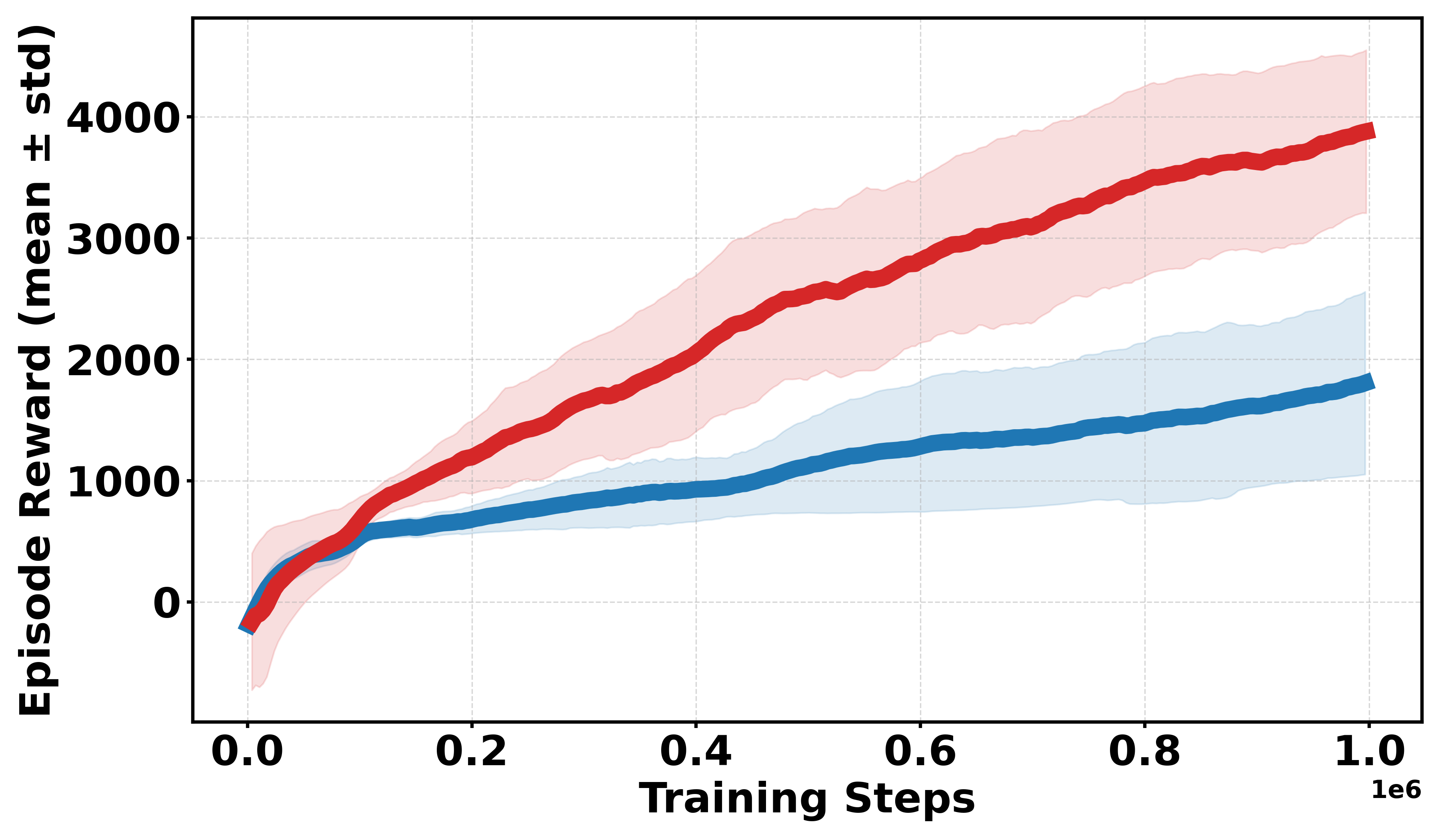
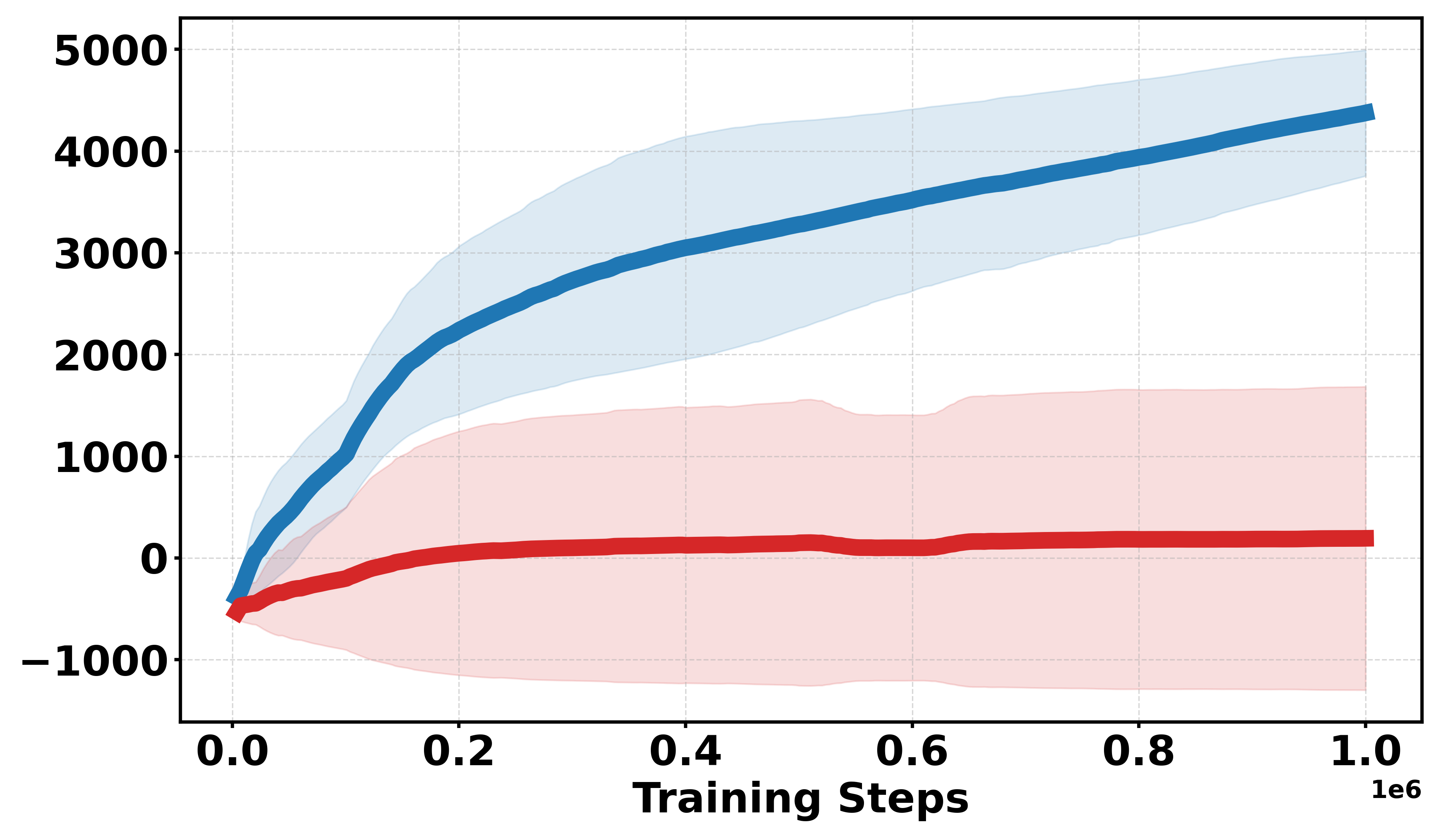
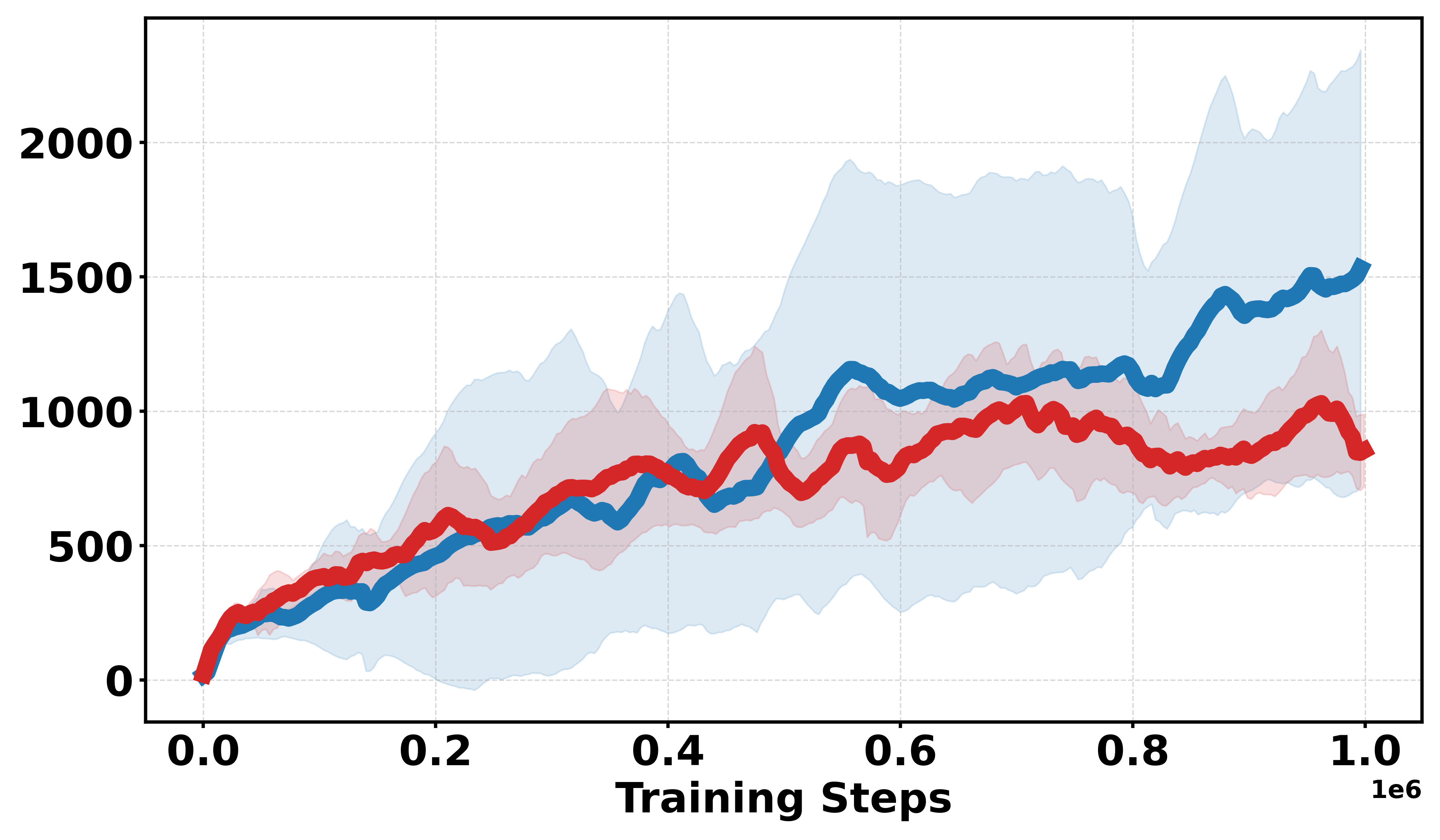
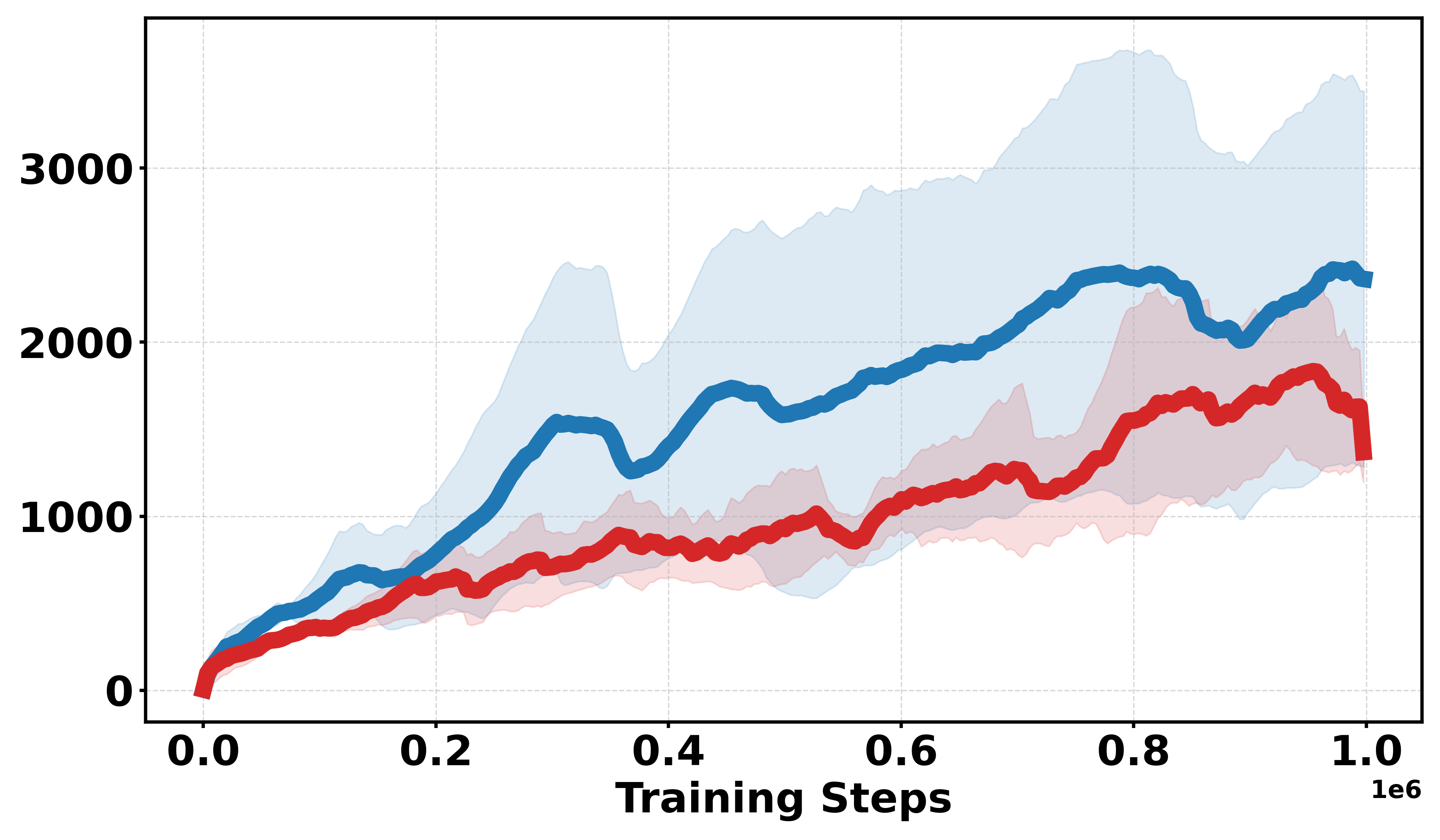
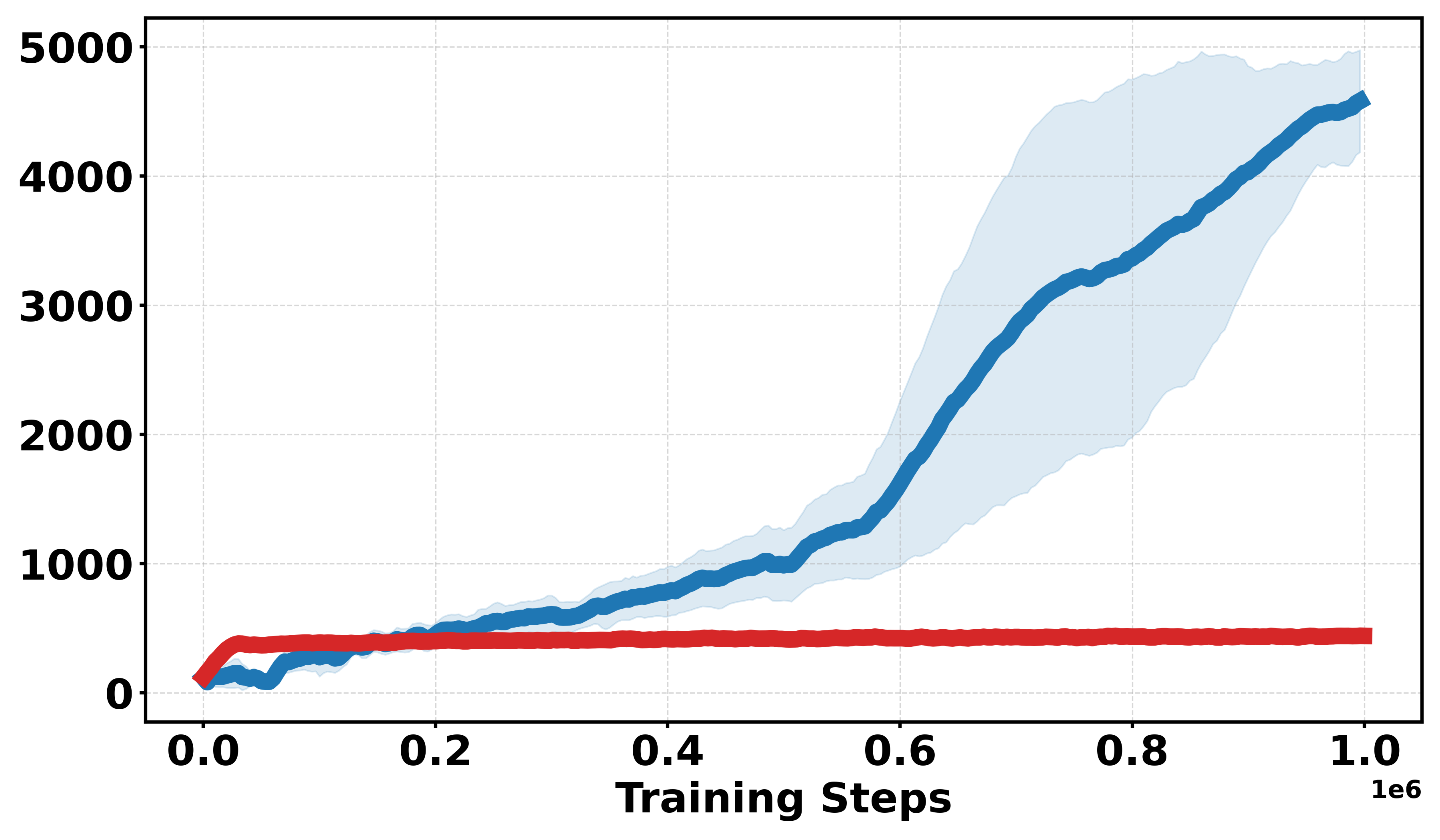
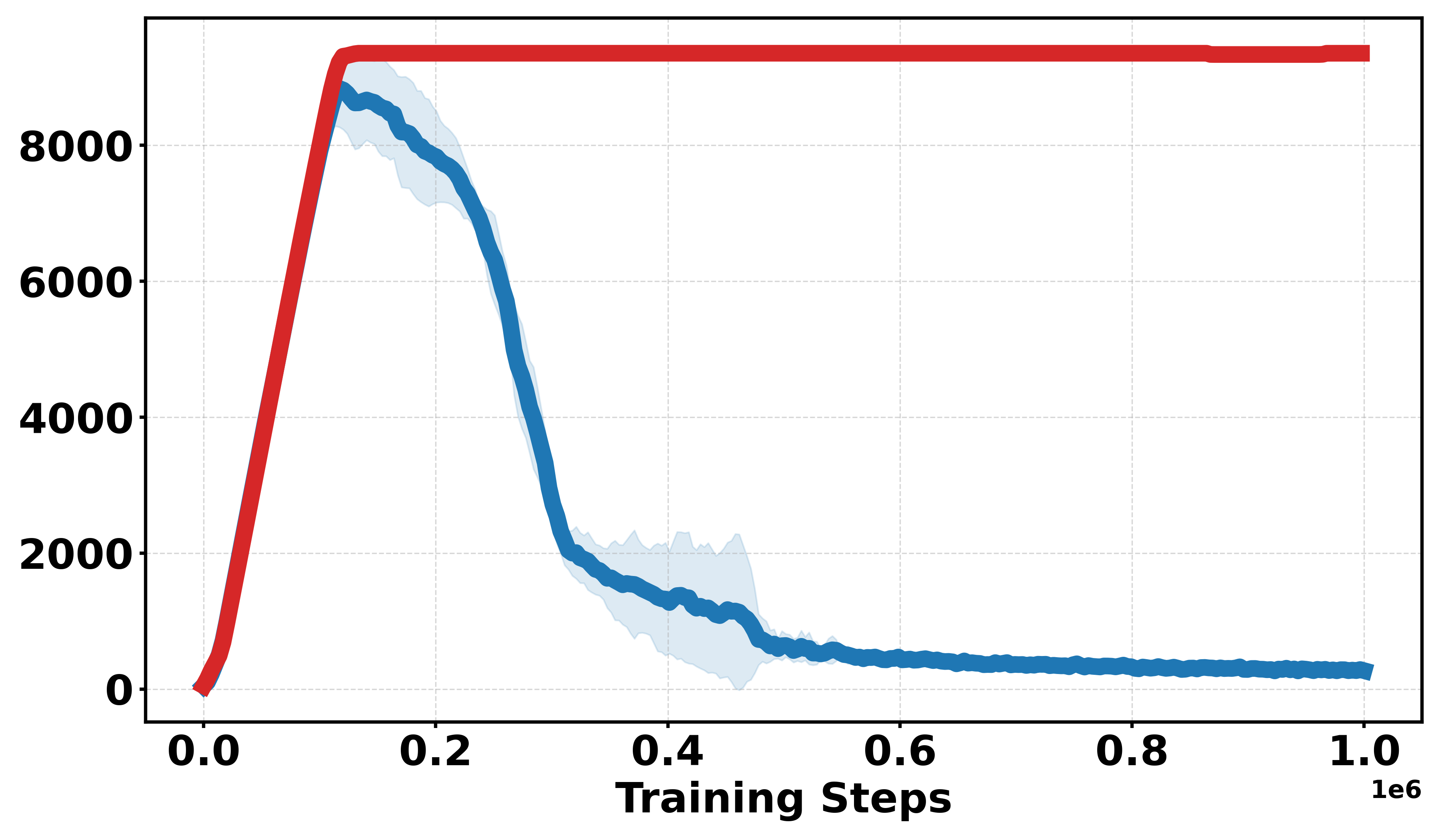
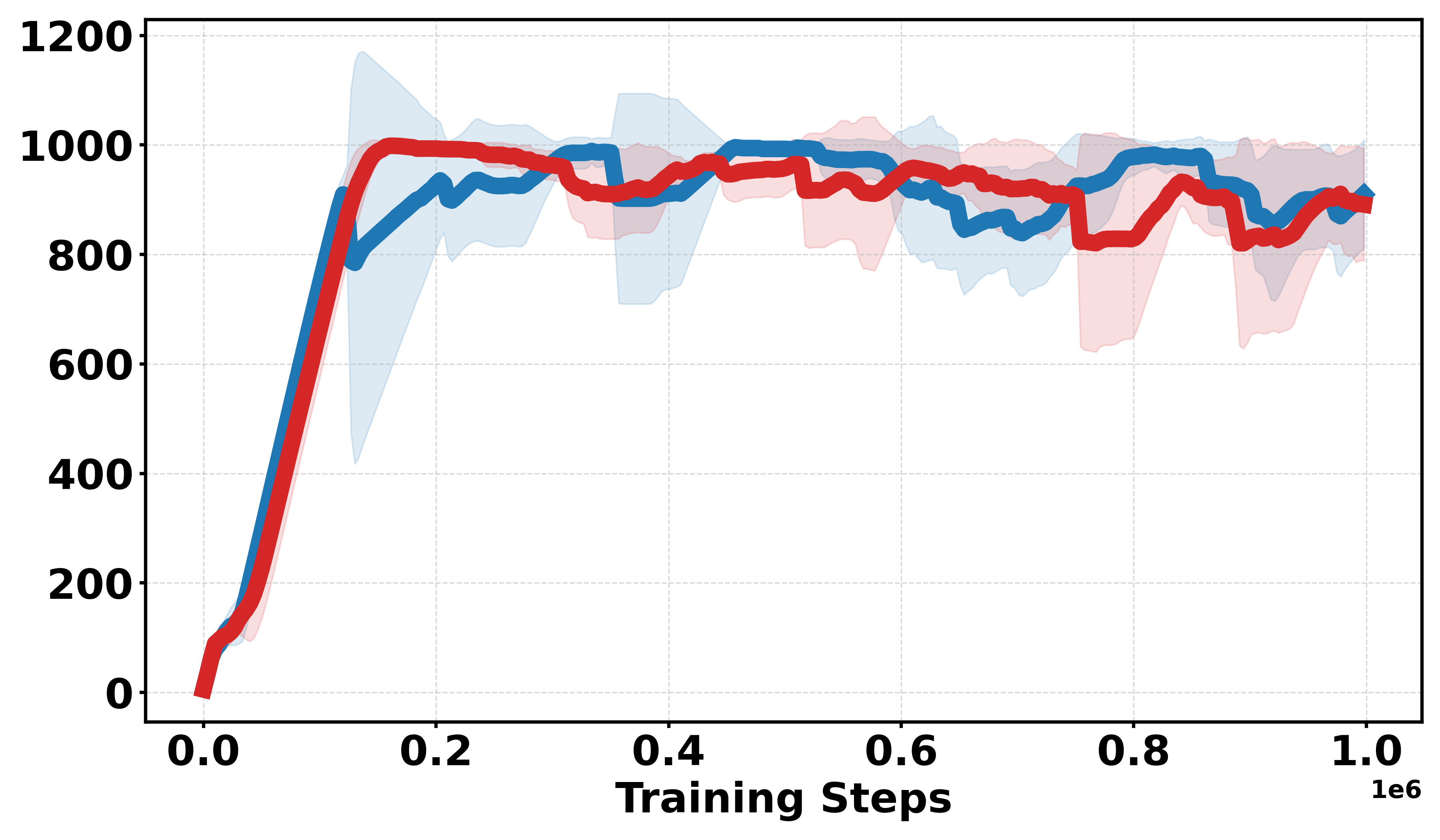
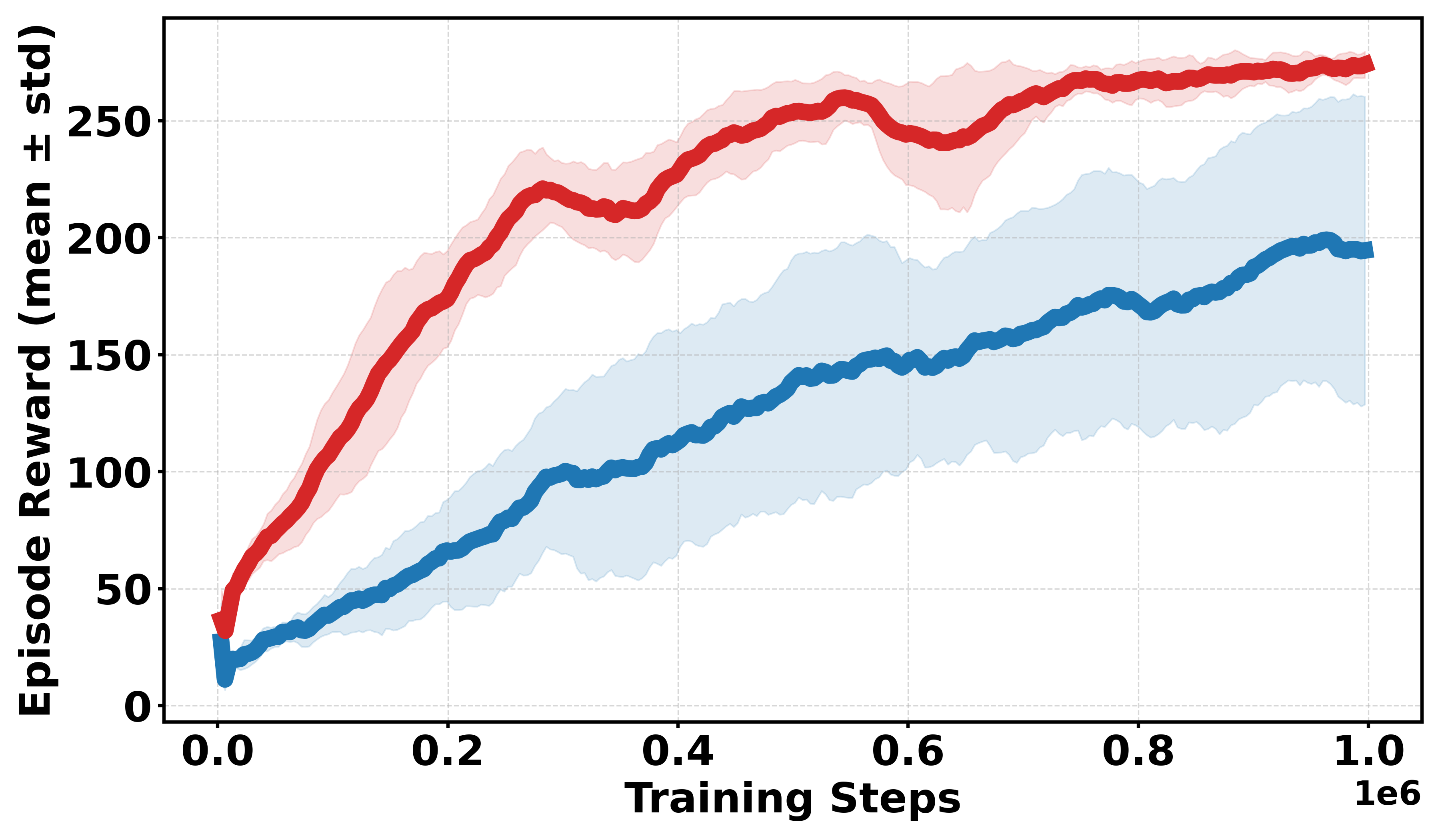
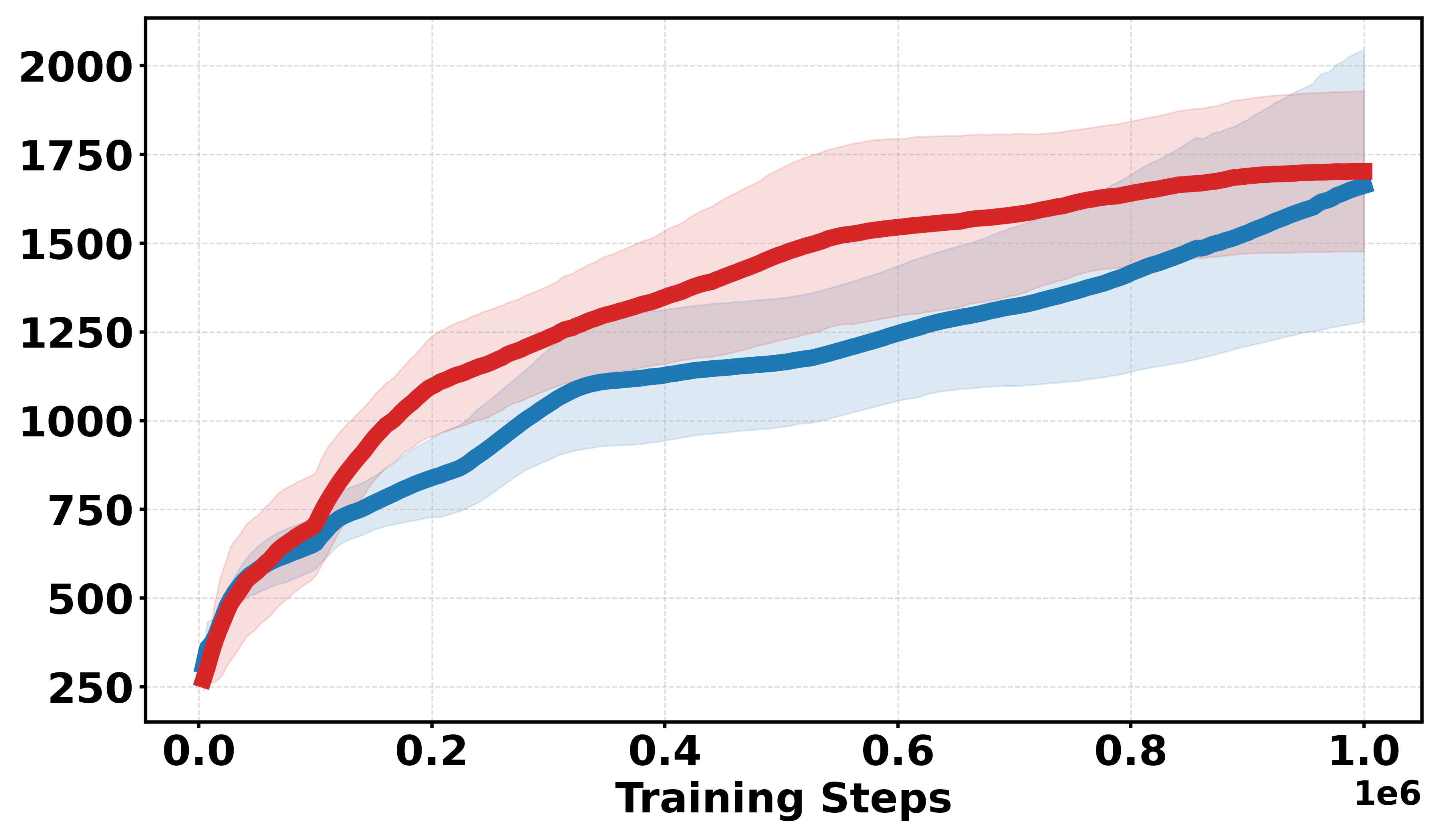
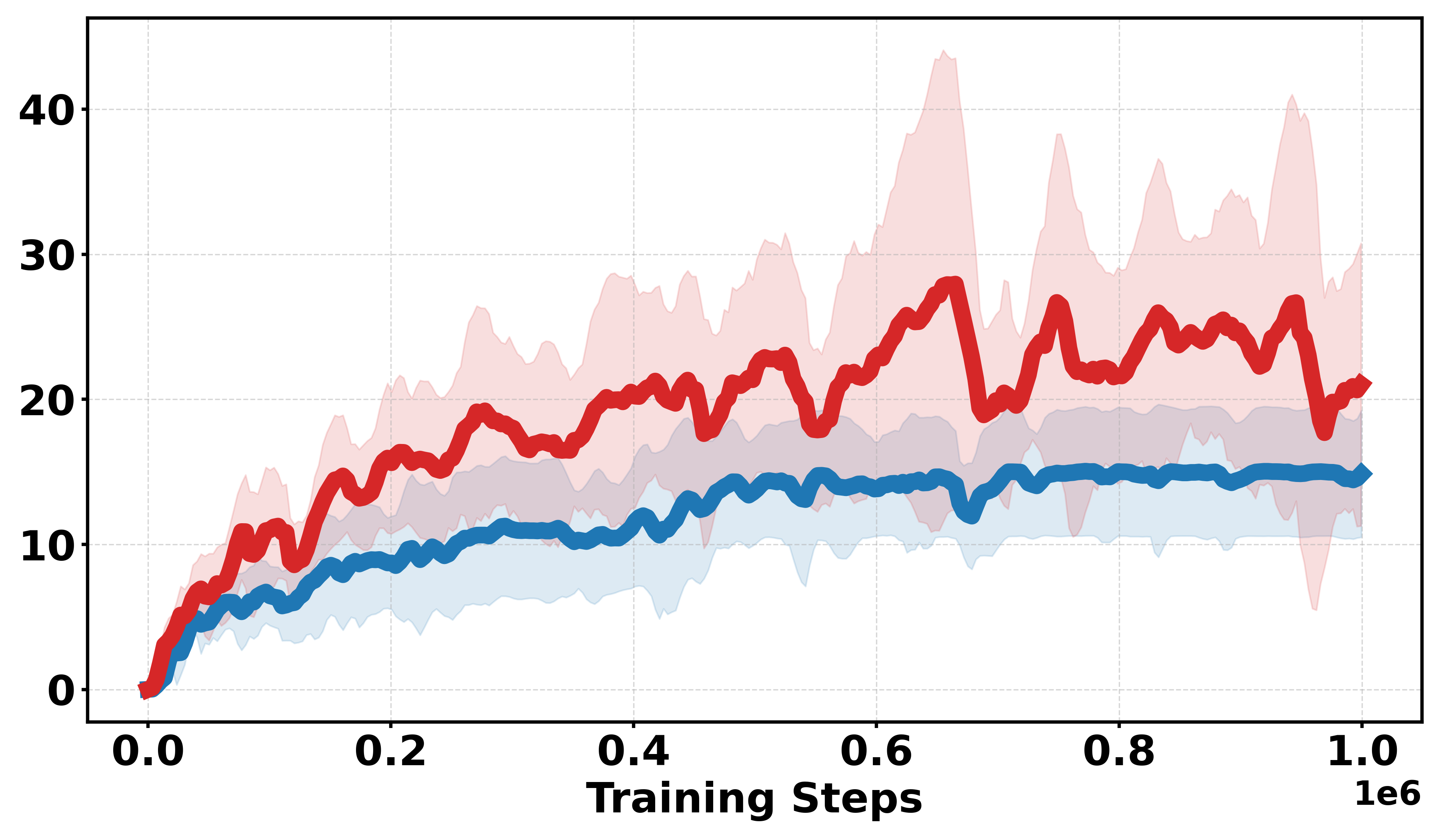
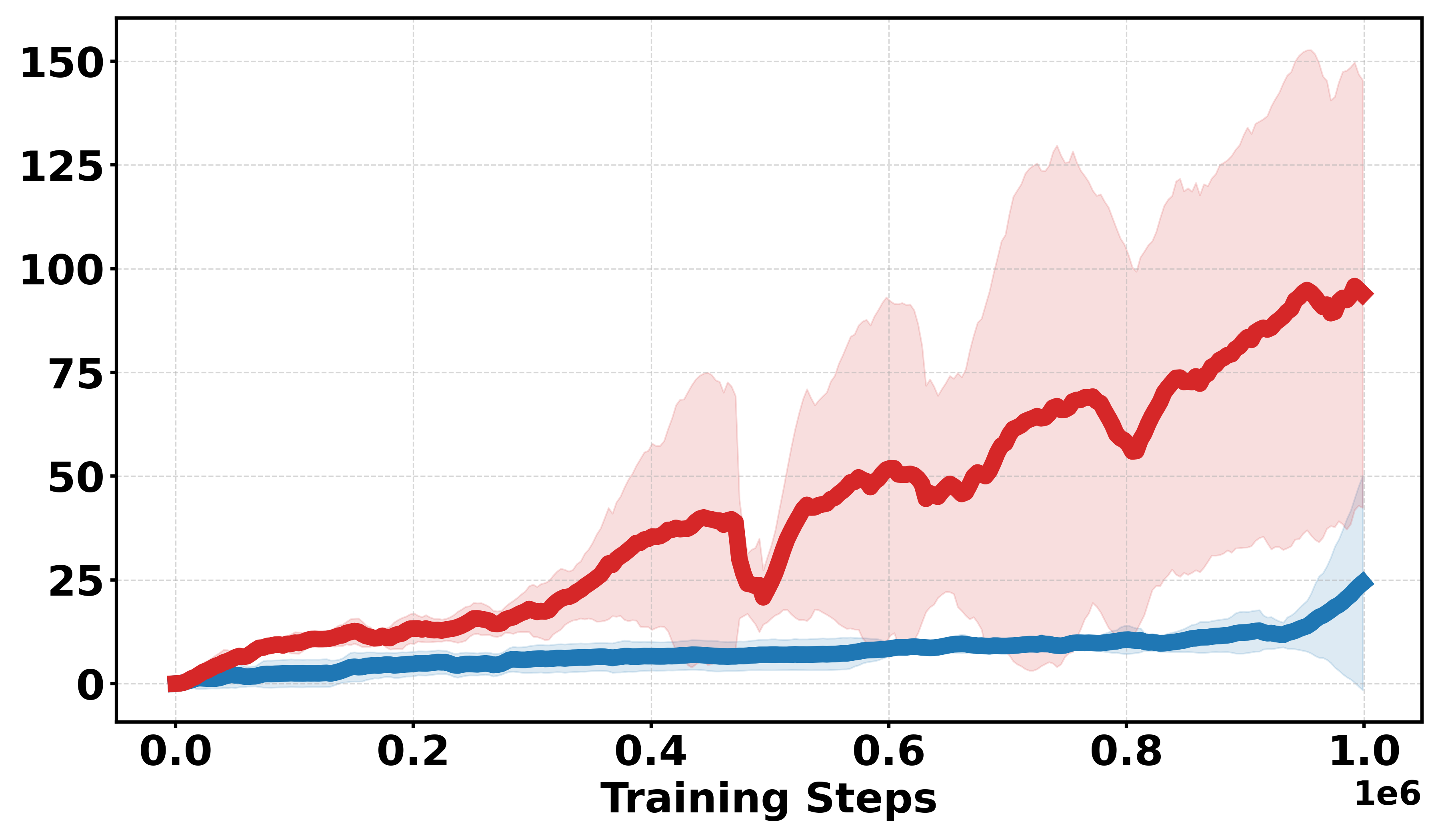
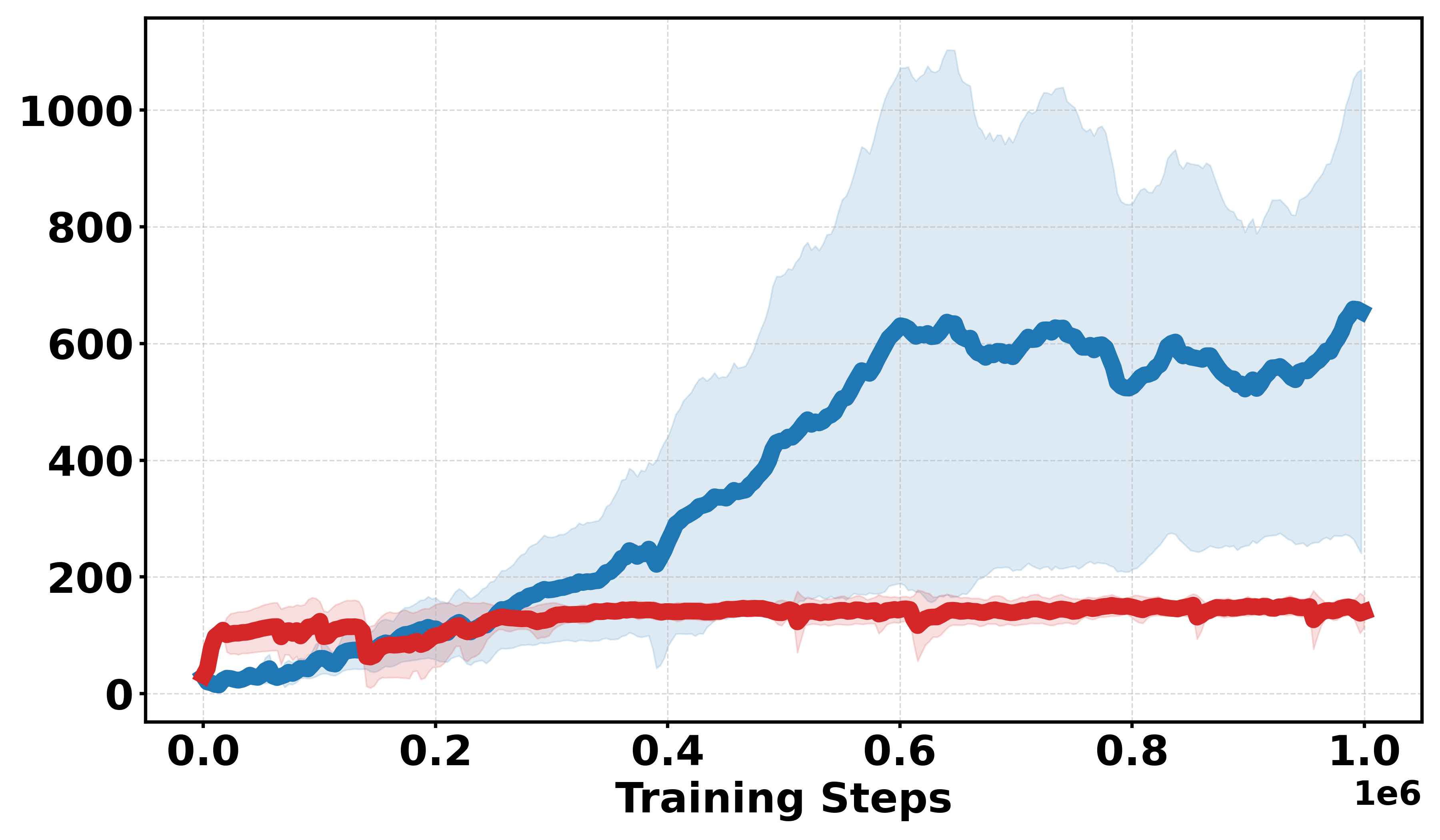
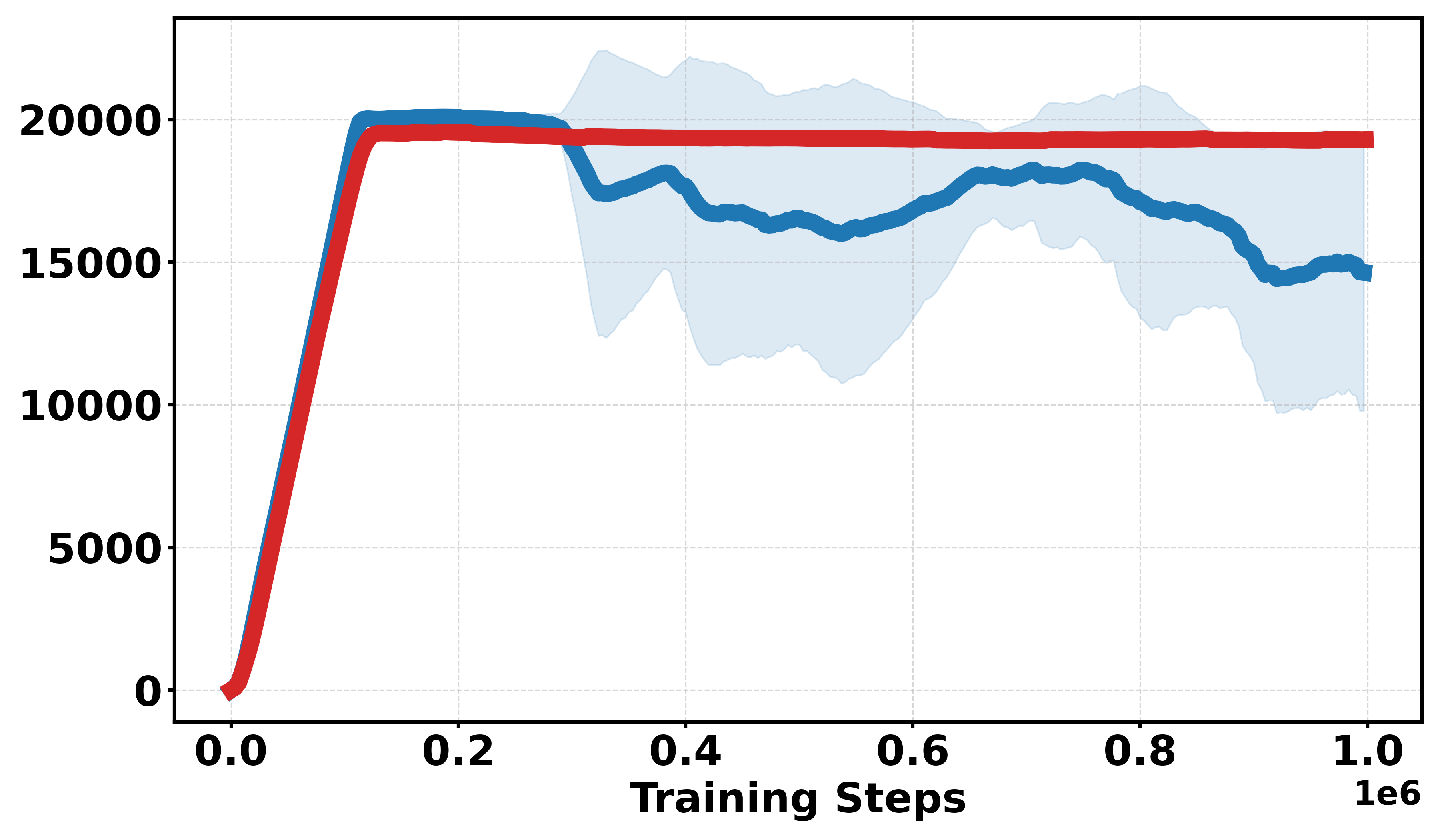
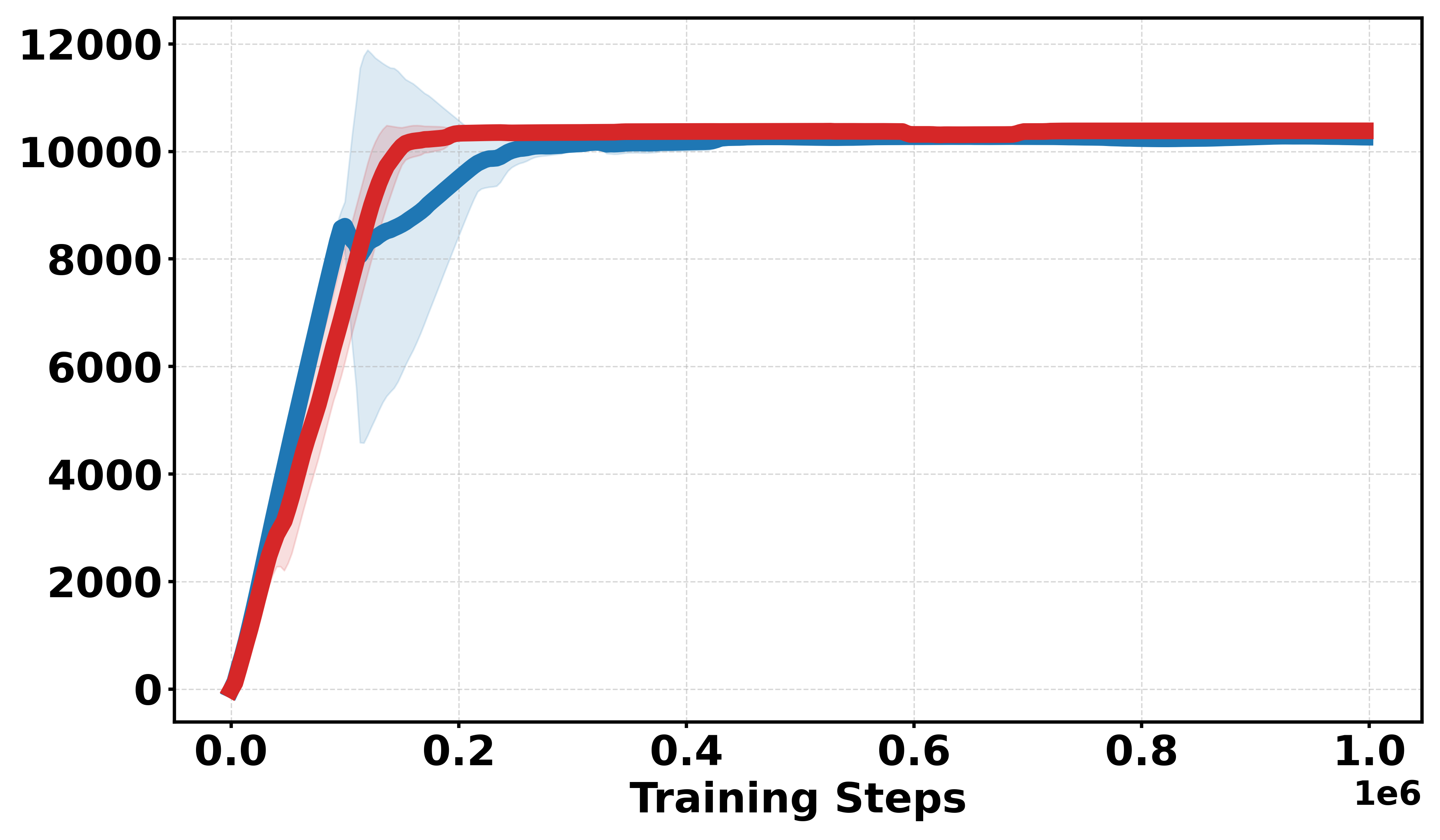

Figure 1: Comparative performance of DDPG and Soft-DDPG across continuous and discrete reward variants, showing robust gains in non-smooth environments.
Sensitivity analysis shows optimal performance when Qσπ1 Monte Carlo samples and Qσπ2 for Gaussian smoothing. Both parameters are critical; too small Qσπ3 reintroduces instability, while too large Qσπ4 causes excessive smoothing bias.
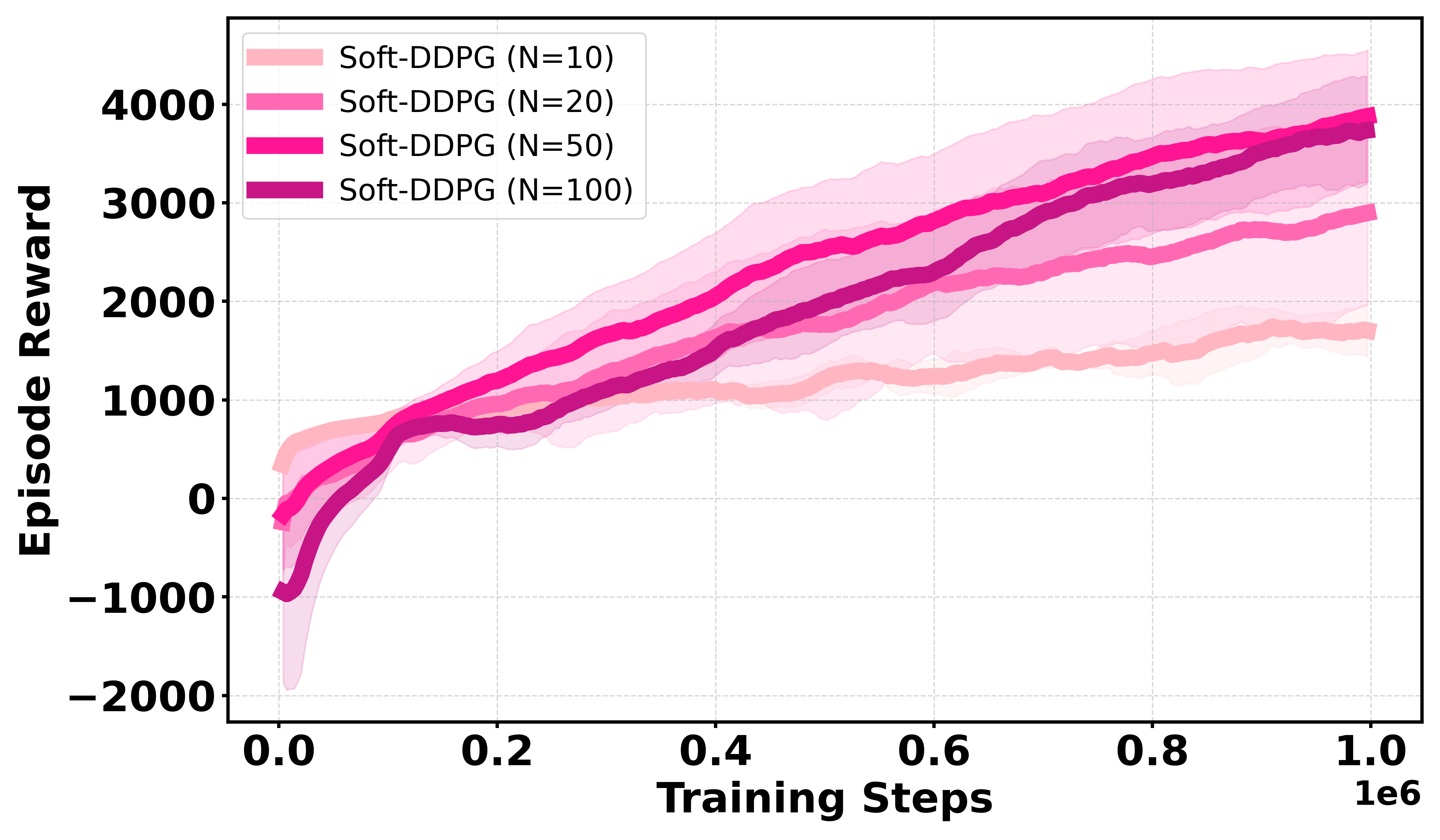
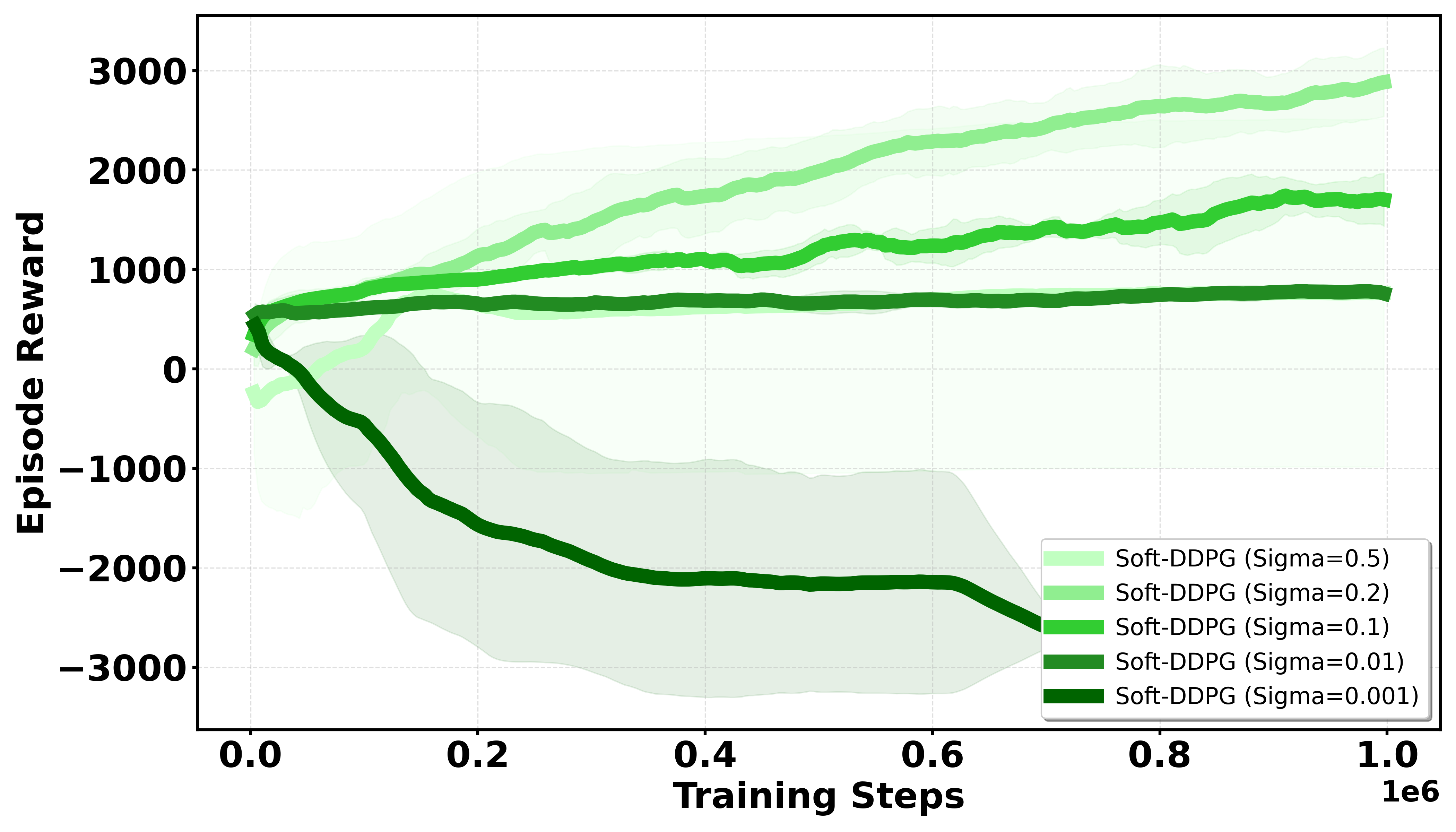
Figure 2: Sensitivity to the number of samples Qσπ5 (Qσπ6); optimal trade-off occurs at Qσπ7, eliminating excessive variance.
Additional discrete reward experiments across Gym environments (BipedalWalker, LunarLander, Pendulum, MountainCar) confirm the robustness of Soft-DDPG, consistently outperforming DDPG under challenging reward structures. In continuous reward settings, standard DDPG generally yields better performance, as expected due to introduced bias from smoothing.
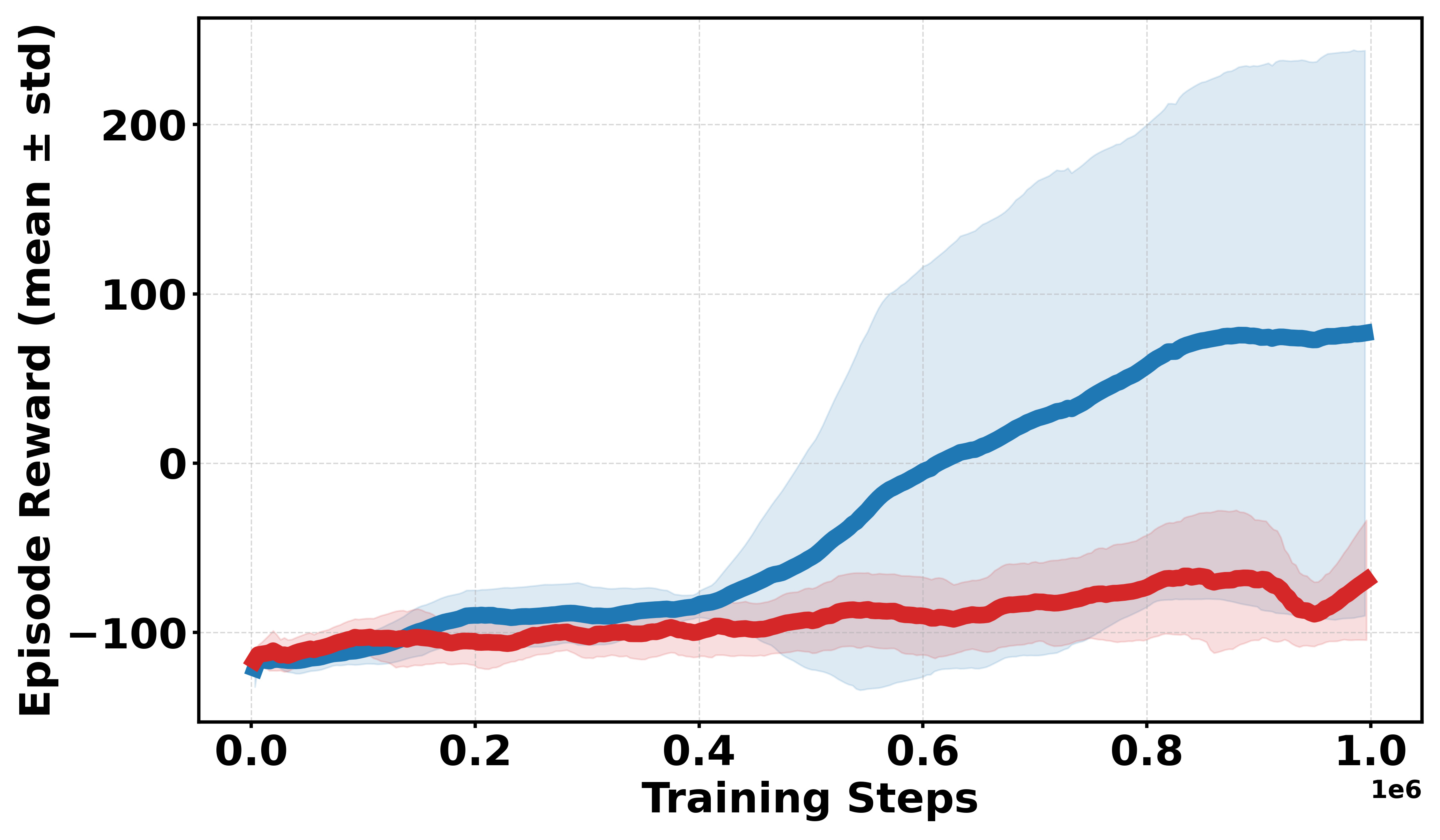
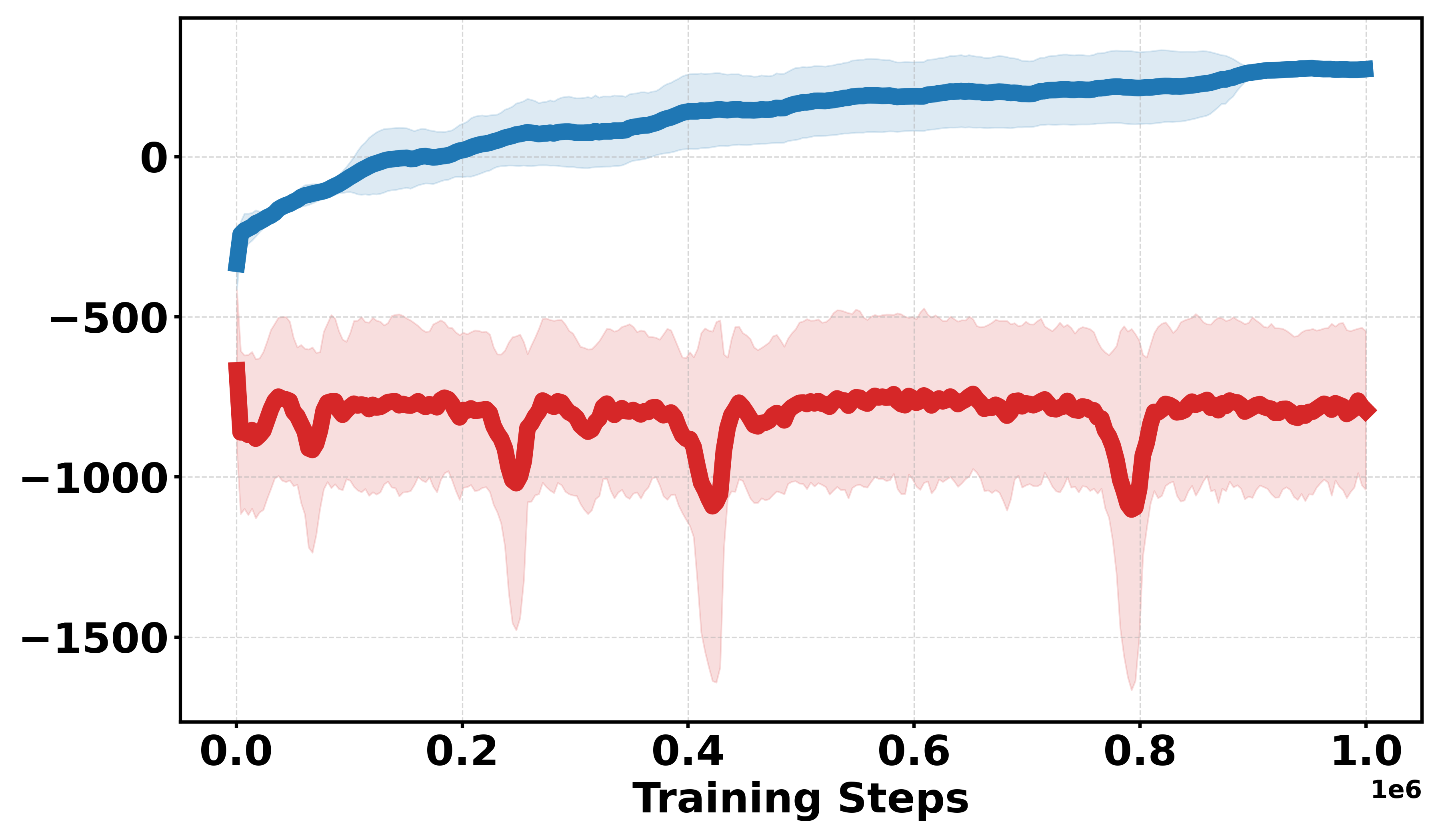
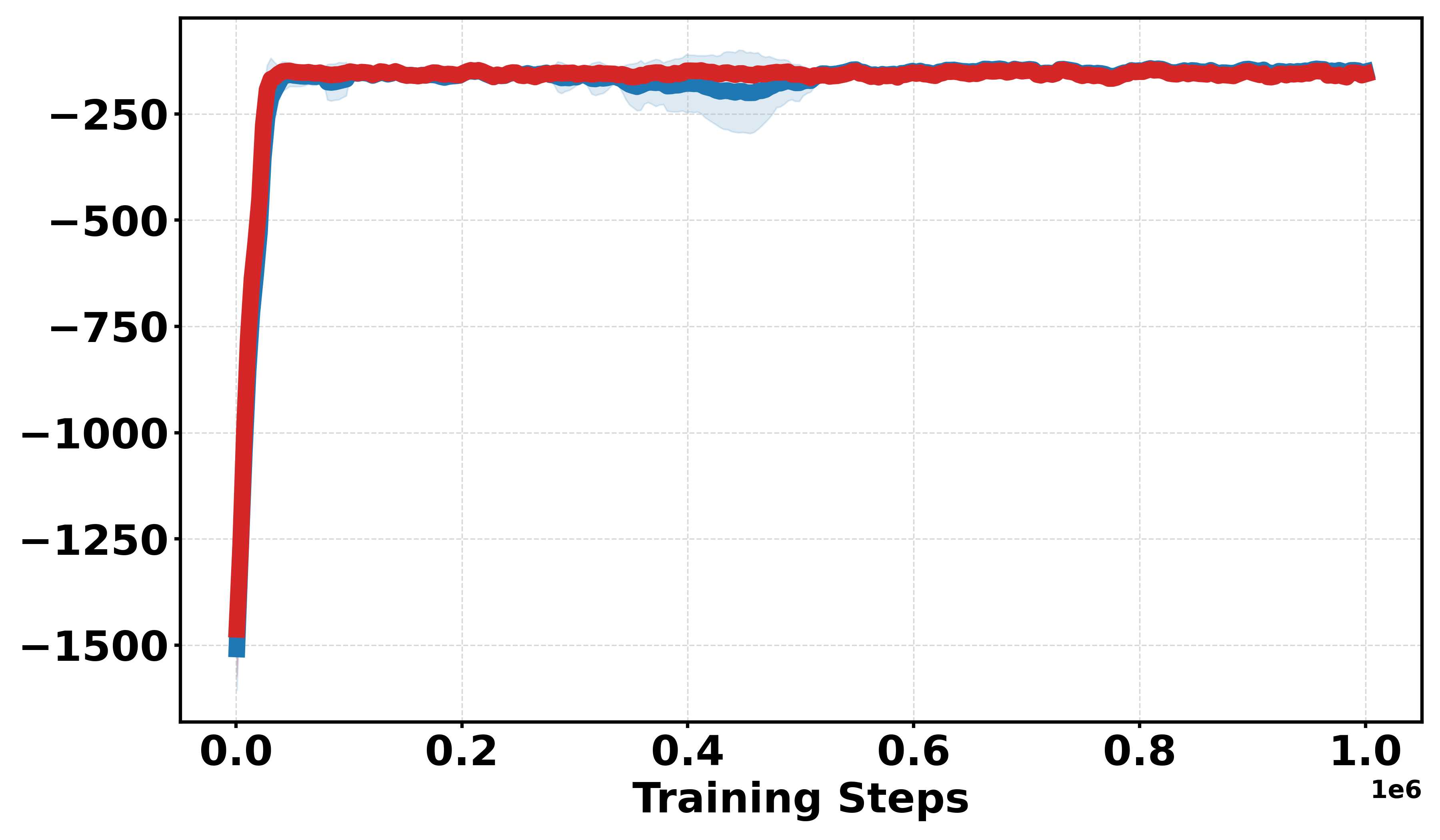
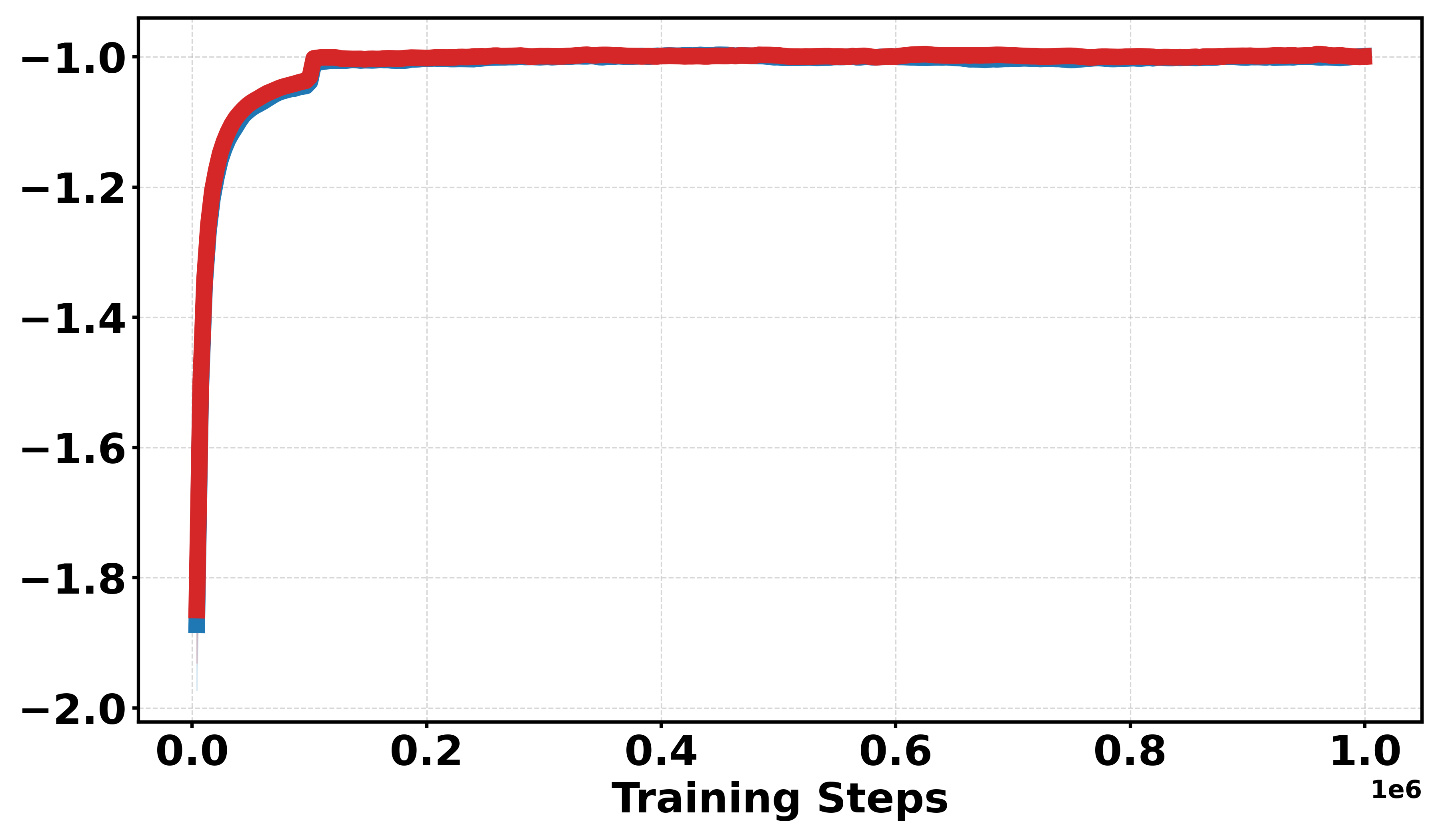
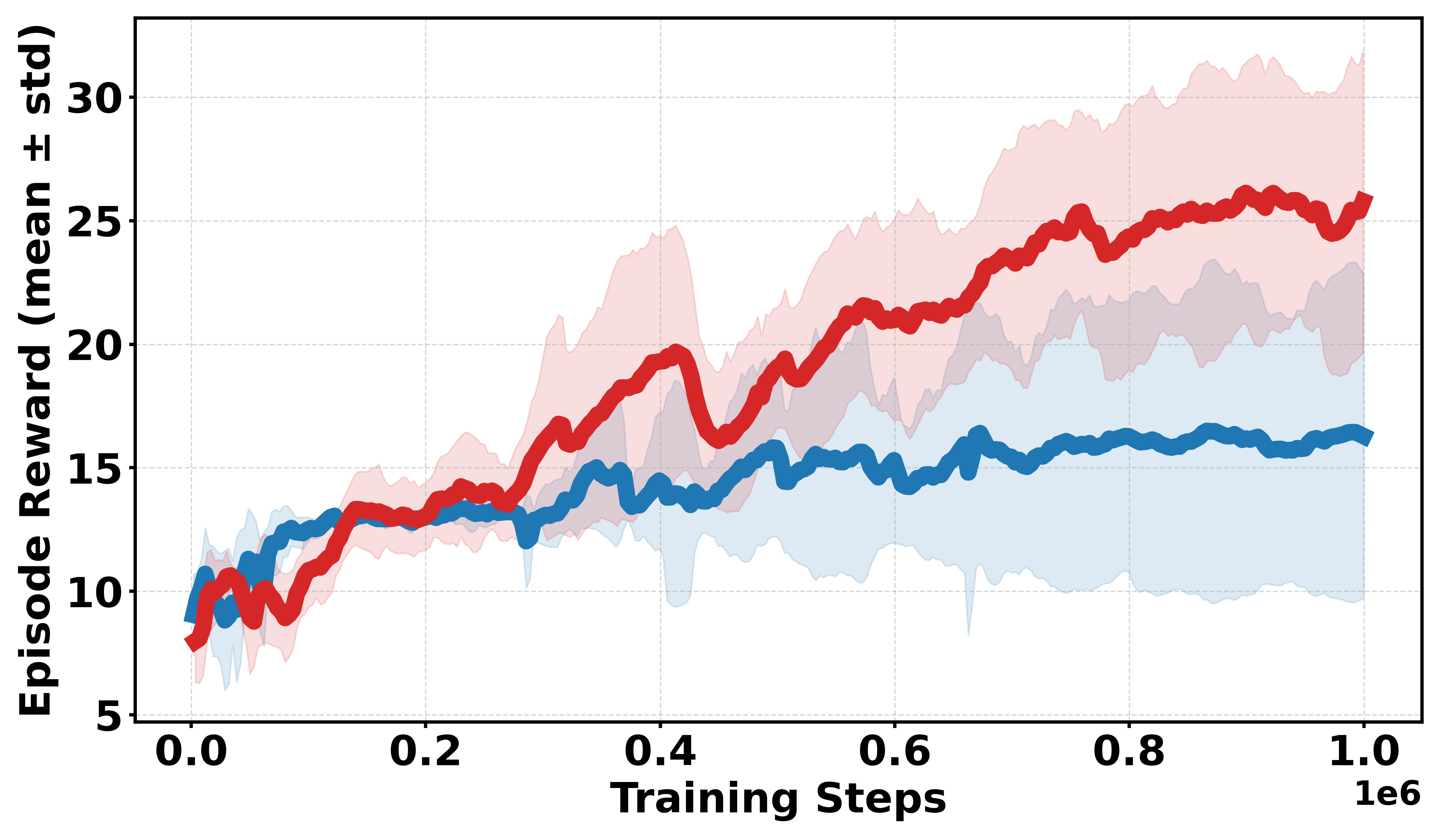
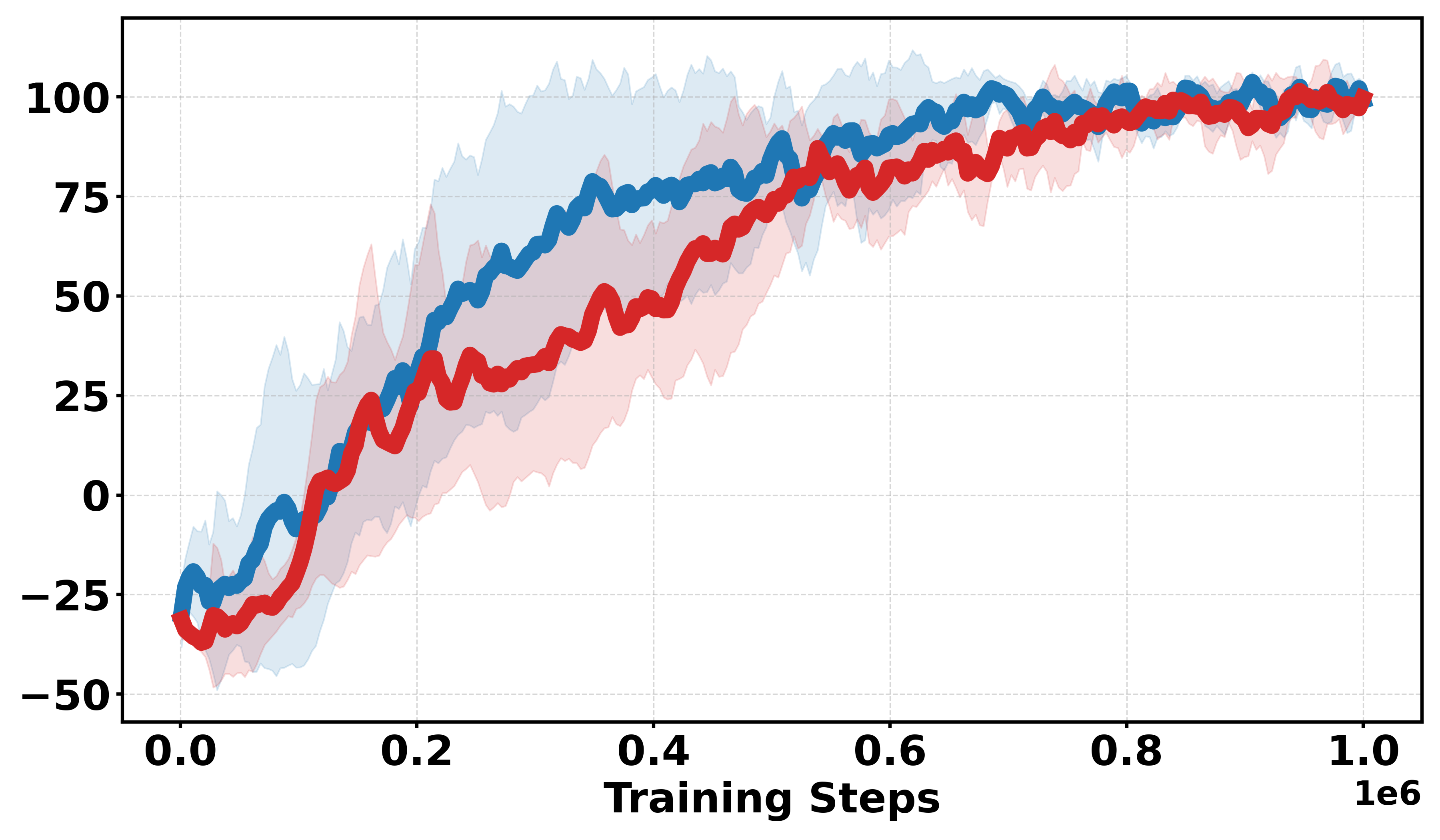
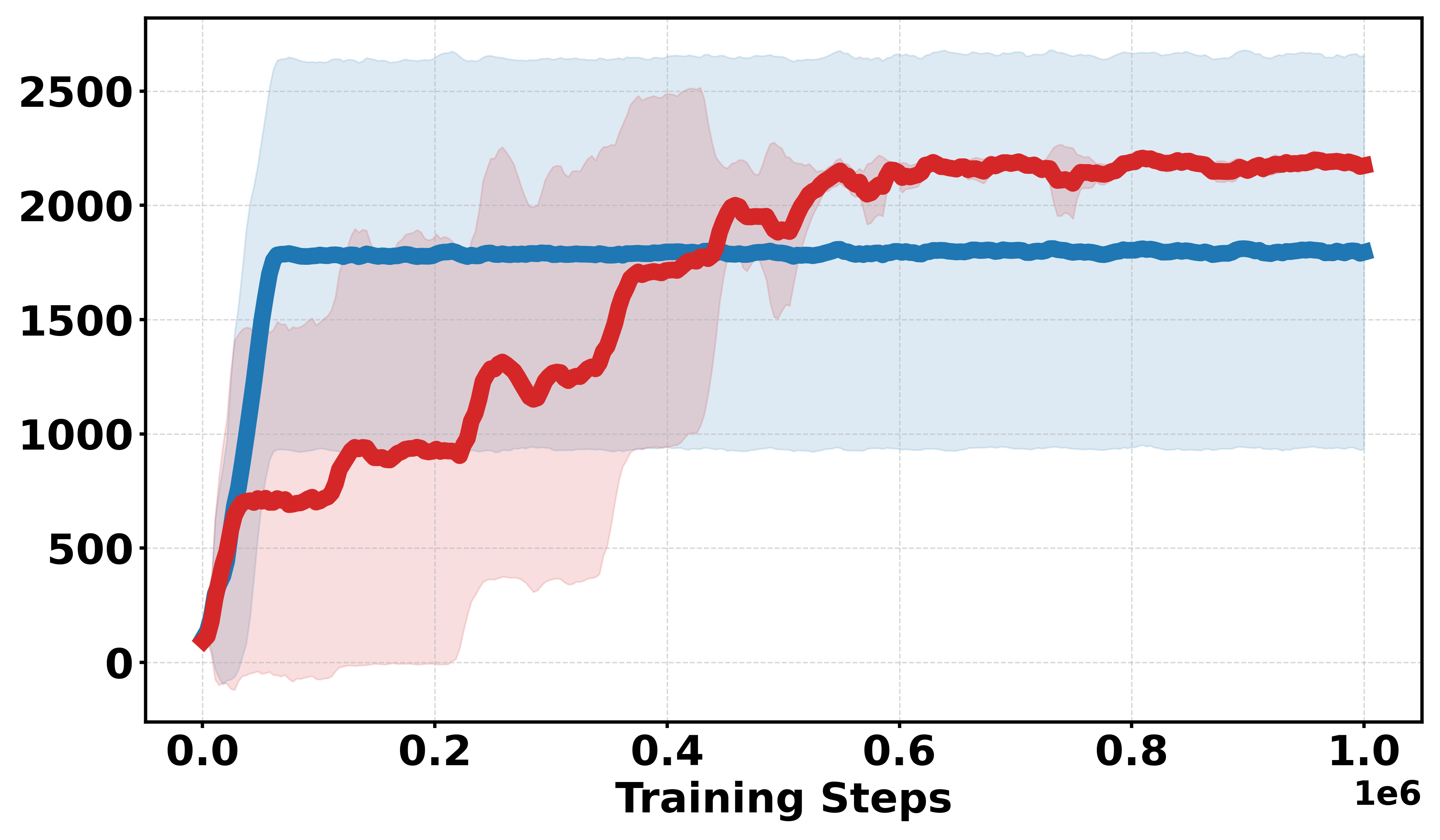
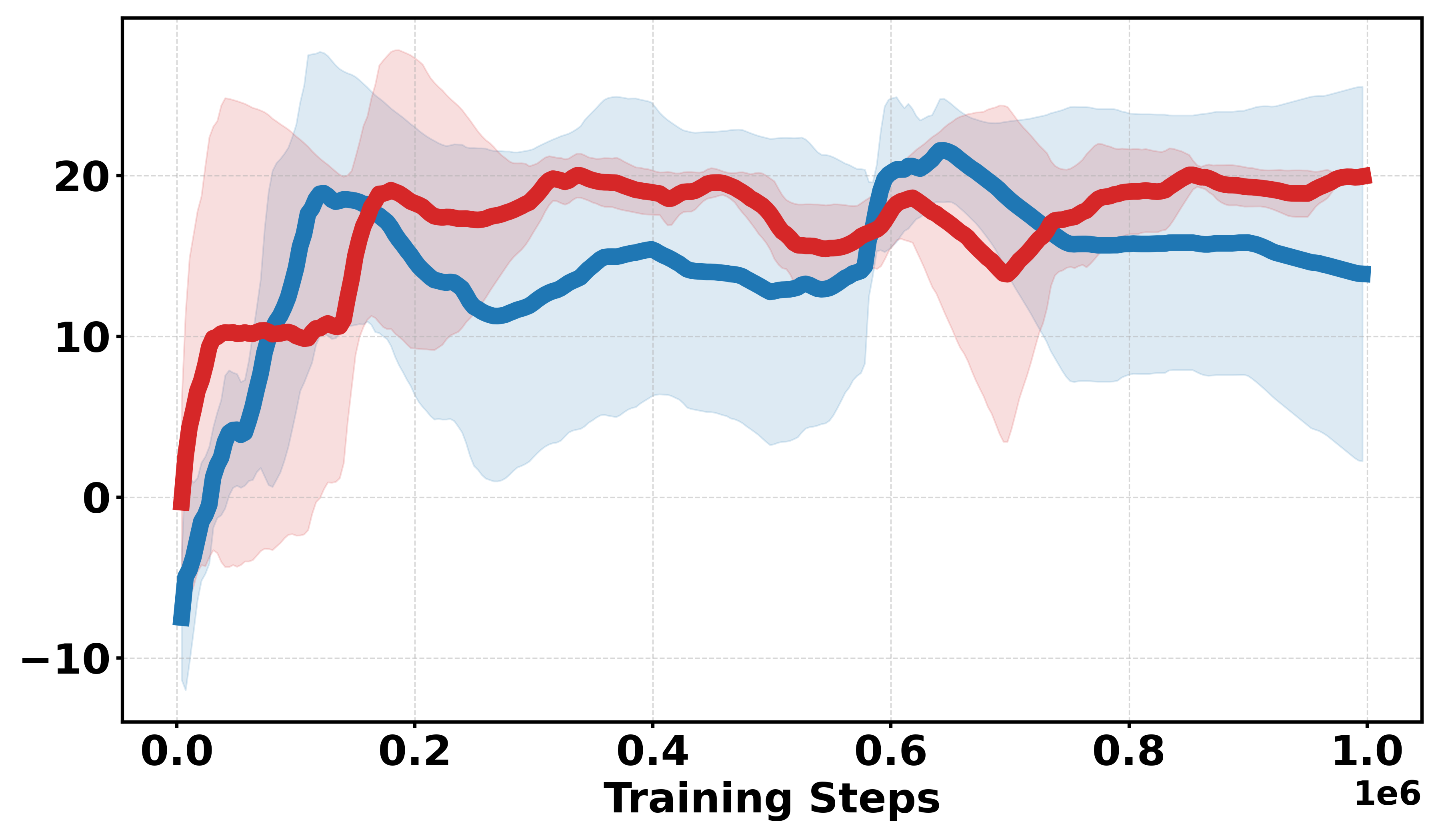
Figure 3: Learning curves across Gym continuous and discrete benchmarks; Soft-DDPG achieves improved sample efficiency and stability in discrete cases.
Practical and Theoretical Implications
The primary theoretical implication is that GS at the Bellman operator level produces a Bellman-consistent surrogate Q-function, which is provably Lipschitz and approximates the original Q-function within an explicit bias bound. Practically, Soft-DDPG offers a principled solution for actor-critic RL in settings where reward surfaces are non-smooth, discrete, or sparse—a regime where standard DPG and its deep variants fail. The algorithm is applicable in robotics, autonomous driving, and industrial control, where such reward structures are prevalent and the critic landscape is typically problematic.
The smoothing parameter Qσπ8 introduces a bias-variance trade-off. With proper tuning, Soft-DDPG remains competitive in dense reward environments but is clearly advantageous in discrete/sparse reward settings. However, excessive smoothing can degrade performance and its selection is environment-dependent.
Limitations and Future Directions
While Soft-DDPG addresses the deficiencies of DPG under non-smooth rewards, it inherits the typical limitations of deep actor-critic methods, including sensitivity to hyperparameters and lack of convergence guarantees. Tuning Qσπ9 and the number of smoothing samples requires environment-specific exploration and is non-trivial. Further, while GS provides theoretical smoothness, it may introduce optimization bias in inherently smooth reward landscapes.
Future work could extend the smoothing paradigm to alternative RL formulations (e.g., stochastic policy gradients, multi-agent RL), investigate adaptive smoothing schedules, and integrate smoothing with other regularization techniques for improved sample efficiency.
Conclusion
Soft-DPG, instantiated via Soft-DDPG, rigorously leverages Gaussian smoothing at the Bellman operator level to produce stable, well-defined policy gradients in actor-critic RL, especially under non-smooth reward landscapes. The approach eliminates explicit action-gradient dependence, leading to robust empirical performance in challenging discrete and sparse reward environments. Analytical error bounds guarantee that the smoothing-induced bias remains controllable. Soft-DDPG is a theoretically grounded and practically validated variant that broadens the applicability and reliability of deterministic policy gradient RL in real-world control tasks (2605.06228).