See Once, Then Act: Vision-Language-Action Model with Task Learning from One-Shot Video Demonstrations
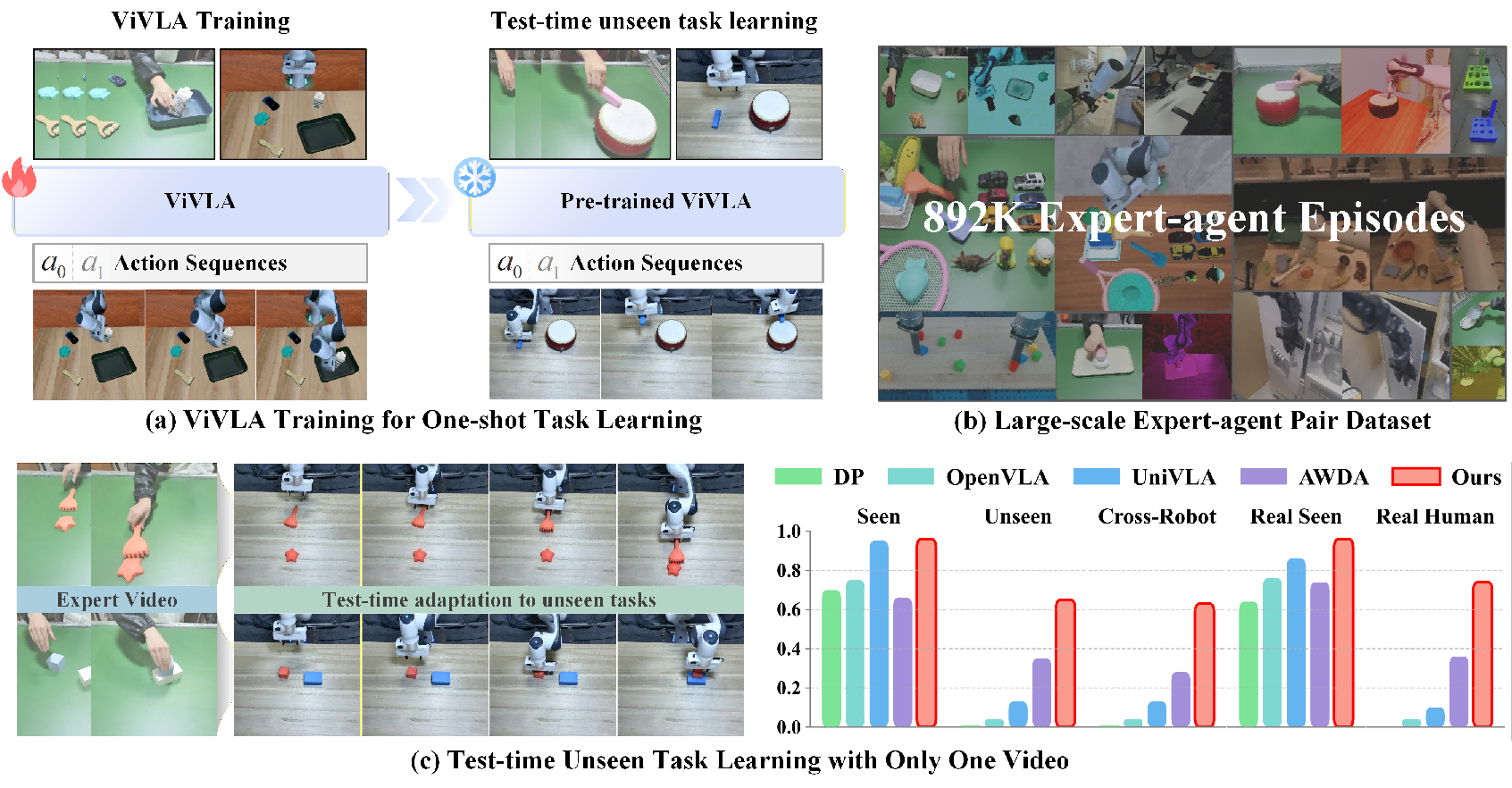
Abstract: Developing robust and general-purpose manipulation policies represents a fundamental objective in robotics research. While Vision-Language-Action (VLA) models have demonstrated promising capabilities for end-to-end robot control, existing approaches still exhibit limited generalization to tasks beyond their training distributions. In contrast, humans possess remarkable proficiency in acquiring novel skills by simply observing others performing them once. Inspired by this capability, we propose ViVLA, a generalist robotic manipulation policy that achieves efficient task learning from a single expert demonstration video at test time. Our approach jointly processes an expert demonstration video alongside the robot's visual observations to predict both the demonstrated action sequences and subsequent robot actions, effectively distilling fine-grained manipulation knowledge from expert behavior and transferring it seamlessly to the agent. To enhance the performance of ViVLA, we develop a scalable expert-agent pair data generation pipeline capable of synthesizing paired trajectories from easily accessible human videos, further augmented by curated pairs from publicly available datasets. This pipeline produces a total of 892,911 expert-agent samples for training ViVLA. Experimental results demonstrate that our ViVLA is able to acquire novel manipulation skills from only a single expert demonstration video at test time. Our approach achieves over 30% improvement on unseen LIBERO tasks and maintains above 35% gains with cross-embodiment videos. Real-world experiments demonstrate effective learning from human videos, yielding more than 38% improvement on unseen tasks.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces ViVLA, a robot learning system that can watch a single short video of an expert doing a task and then figure out how to do that task itself. Think of it like a robot that learns new skills the way many people do: by watching a “how‑to” clip once and then trying it. ViVLA combines vision (seeing), language (understanding instructions), and action (moving) in one model, so it can take in an expert video plus a simple text instruction and output the robot’s next moves.
Key Questions the Paper Tries to Answer
- Can a robot learn a brand‑new task by watching just one demonstration video, without extra training?
- How can we help robots understand the tiny, precise motions in videos (not just the big picture)?
- Can we make a common “action language” that works for both human videos and different kinds of robots?
- How do we train such a robot model efficiently and quickly?
- Where do we get enough good training data that connects human videos to robot actions?
How ViVLA Works (Methods Explained Simply)
To make ViVLA learn from a single video, the authors built several key pieces that fit together:
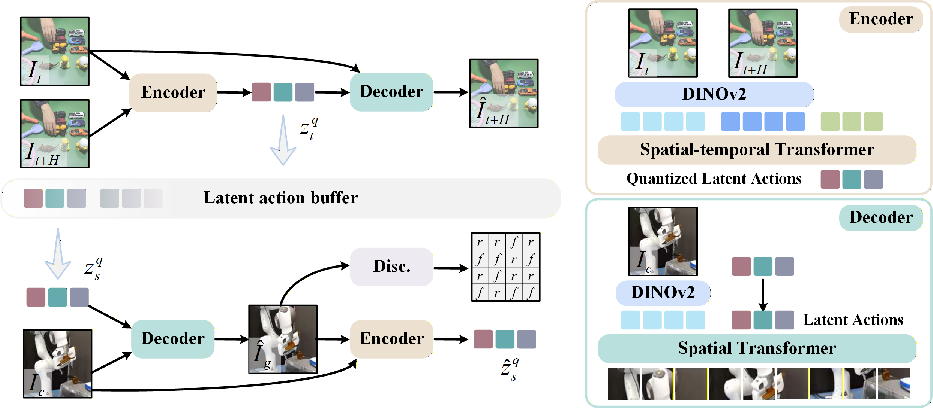
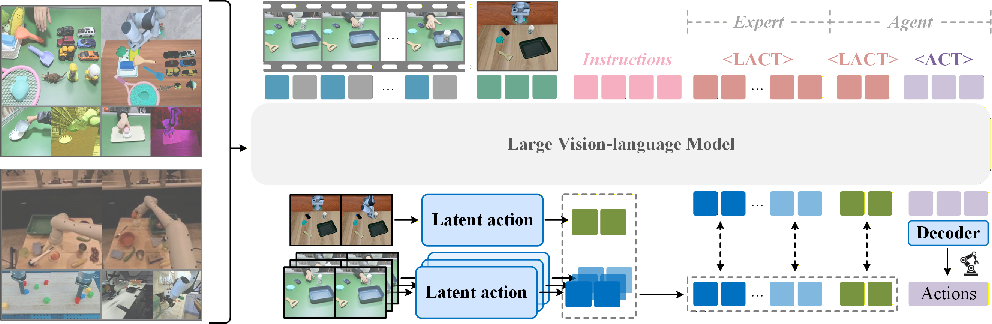
1) Learning “hidden action codes” from videos
Robots don’t have action labels for most videos, especially human ones. So the team teaches the model to invent a compact “alphabet” of action tokens—a kind of secret code that represents how things move from one moment to the next.
- Analogy: Imagine describing a dance using a small set of symbols for steps. Instead of writing every tiny motion, you pick a small set of tokens that cover most steps well.
- The model learns these tokens by trying to predict a future frame from a current frame and a set of action tokens. If the tokens capture the right motion, it can reconstruct what the scene looks like a bit later.
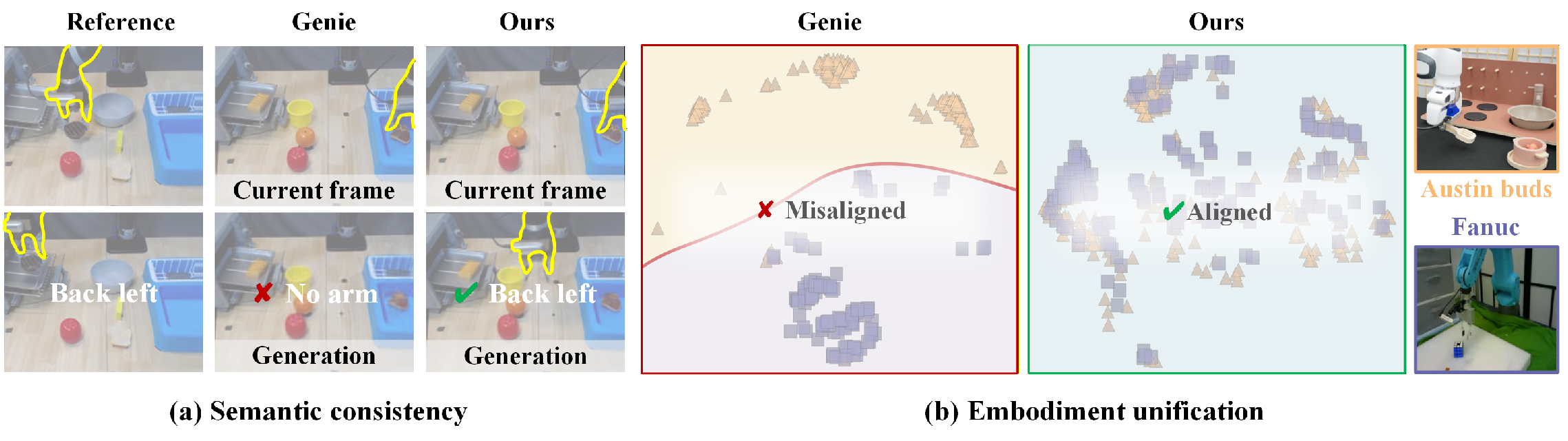
To make the tokens consistent and useful across humans and robots, they add an “action‑centric cycle consistency” check:
- Analogy: Translate a sentence into a secret code, use that code to create a future scene, then decode the scene back into the same code. If the code matches, the “alphabet” is stable and meaningful.
- This encourages a single, unified action space across different bodies (human hands, robot arms) so the robot can learn from human demonstrations.
2) Parallel decoding instead of step‑by‑step guessing
Many models predict actions one token at a time, which can lead to “shortcut learning” (cheating by relying too much on previous answers) and slow inference.
- ViVLA predicts all the action tokens for a sequence in one go (parallel), using special “START” tokens to say how many to generate.
- This forces the model to base its actions on understanding the video and the current robot observation—not just the last token—and makes it faster.
3) Masked video understanding to reduce redundancy
Videos have lots of repeated information. Processing every frame and every pixel is heavy.
- ViVLA randomly hides (masks) parts of the video across time and space, then asks the model to still figure out the actions.
- Analogy: Like studying with some pieces of a puzzle covered—you have to understand the whole scene better to fill in the blanks.
- This both speeds up training and improves the model’s ability to understand the important parts of the demonstration.
4) Building a huge expert‑agent dataset from human videos
Robots need pairs of data: an expert demonstration and a corresponding robot trajectory. Those are rare.
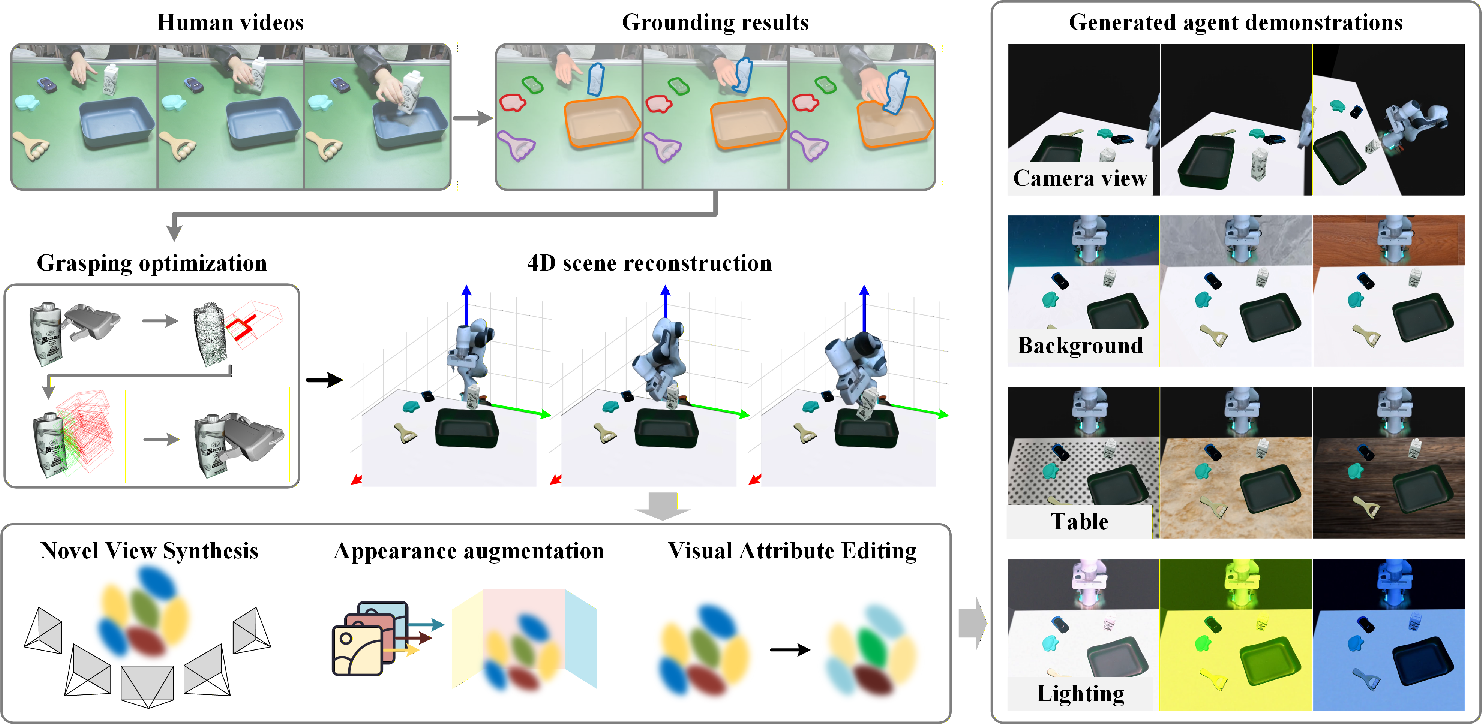
- The authors created a pipeline that takes human videos and reconstructs the scene in 3D using “Gaussian splatting” (a method to build a 3D scene from 2D images).
- They detect hand poses and object positions, then render a robot performing the same task in the reconstructed scene, producing the robot’s observation and action data.
- They gathered 7,421 human videos across 100+ tasks and combined them with public datasets to build 892,911 expert‑agent pairs for training.
Main Results and Why They Matter
Here’s how ViVLA performed:
- On unseen tasks in the LIBERO benchmark (a collection of robot manipulation tasks), ViVLA improves success by over 30%.
- Using videos from different embodiments (e.g., from humans or other robots) still gives above 35% gains.
- In real‑world tests with human videos, ViVLA achieves more than 38% improvement on unseen tasks.
Why this is important:
- The robot learns from a single expert video at test time—no extra fine‑tuning needed—bringing it closer to how humans learn by watching.
- The unified action tokens let knowledge transfer across different bodies, so robots can learn from human videos more effectively.
- Parallel decoding makes the system faster and reduces the chance of “cheating” in training.
What This Could Mean for the Future
- Easier robot training: Instead of collecting huge robot datasets for every new task, people could show a short demonstration video and let the robot learn on the spot.
- Better human‑robot teaching: Regular human how‑to videos become useful training material for robots, even when humans and robots move differently.
- Faster deployment: The model’s speed and generalization mean robots could adapt to new environments and tasks more quickly.
- Foundation for general‑purpose robots: This approach brings robots closer to being versatile helpers that can handle many tasks without heavy retraining.
In short, ViVLA is a step toward robots that can learn new skills by watching, just like you might learn to fold a shirt or fix a bike by watching a single online tutorial.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide future work:
- Quantitative ablation gaps: The paper does not report ablations isolating the contribution of each major component (latent action tokenizer, action-centric cycle consistency, parallel decoding, temporal-spatial masking, discriminator, post-training on target robot), making it unclear which parts drive the reported gains.
- Latent action design sensitivity: There is no analysis of how codebook size K, token length l_z, and temporal window H affect semantic fidelity, cross-embodiment alignment, throughput, and downstream control performance.
- Interpretability of latent actions: The semantic meaning of learned latent action tokens is not evaluated (e.g., do clusters correspond to manipulation primitives/verbs?), limiting diagnosticability and controllability.
- Cycle consistency robustness: The action-centric cycle consistency objective lacks theoretical guarantees and empirical stress-testing (e.g., risk of representational collapse, degenerate solutions, or over-regularization).
- Cross-embodiment alignment metrics: The claim of “unified latent action space” is not supported by quantitative alignment metrics across embodiments (e.g., retrieval/transfer accuracy, mutual information, or probing tasks), leaving the extent of alignment uncertain.
- Adversarial training stability: The local-global discriminator introduces GAN-style objectives, but training stability, convergence behavior, and sensitivity to hyperparameters are not studied.
- Information leakage checks: The paper argues the discriminator prevents latent information leakage via generated frames, but does not empirically verify leakage (e.g., via probing or causal interventions).
- Parallel decoding coherence: It remains unclear how parallel decoding maintains temporal coherence and closed-loop consistency for long action sequences compared to autoregressive decoding, especially under partial observability.
- Masking strategy calibration: The temporal-spatial masking ratio and policy (which tokens/time steps are masked) are not explored, leaving unclear trade-offs between efficiency and fine-grained action understanding.
- Long-horizon task generalization: The method’s effectiveness on long-horizon, multi-stage tasks with branching subgoals and delayed rewards is not evaluated.
- Robustness to viewpoint and pace mismatch: The model’s sensitivity to camera viewpoint differences, motion speed/tempo mismatches, temporal warping, and frame rate differences between human videos and robot execution is unquantified.
- Handling low-quality demonstrations: There is no analysis of robustness to noisy, occluded, edited, or incomplete expert videos, nor automatic quality filtering of demonstrations.
- Closed-loop vs open-loop execution: The paper does not clarify whether actions are predicted in open-loop sequences or consistently updated in a closed loop with fresh observations; implications for error recovery and safety remain open.
- Post-training dependence: Although one-shot skill acquisition is claimed at test time, the method requires embodiment-specific post-training (action decoder full fine-tuning and LoRA on the backbone); the extent of zero-shot transfer to entirely novel robots without any post-training is unknown.
- Action decoder generality: The design and generalization of the action decoder across different action spaces (e.g., torque, velocity, waypoint) and control frequencies are not assessed.
- Multimodal sensing: The approach relies primarily on vision; performance on contact-rich tasks that require force/torque or tactile signals is not studied.
- Instruction use and alignment: The role of language instructions during test-time learning from video (e.g., necessity, ambiguity resolution, alignment with video content) is not quantified; learning from video-only without language is not evaluated.
- Dataset construction validity: The pairing of human videos with synthesized robot demonstrations “for the same task” risks label leakage or misalignment; procedures for task matching, validation, and error rates are not reported.
- 3D reconstruction requirements: The pipeline uses TRELLIS and 3D Gaussian splatting; feasibility for single-view videos, minimal camera calibration, and scenes with limited viewpoints is not addressed.
- Physical plausibility of generated demonstrations: The realism of robot-with-objects interactions (contact dynamics, collision avoidance, grasp feasibility) in the synthesized 4D scenes is not validated against physics or real executions.
- Pose estimation errors: Error rates of HaMeR, ICP alignment, and FoundationPose in cluttered scenes, with motion blur or occlusions, and their impact on downstream policy learning are not quantified.
- Segmentation into subtasks: The video parsing via contact onset/offset thresholds lacks sensitivity analysis (choice of ε, noisy point clouds), and does not cover interactions without clear contacts (e.g., tool use, non-prehensile actions).
- Data diversity and coverage: While 100+ manipulation tasks are reported, coverage of deformable objects, liquids, tool use, and complex assembly remains unclear; how task diversity correlates with generalization is unstudied.
- Potential dataset contamination: Constructing pairs from public datasets with “similar tasks” risks train-test leakage; rigorous split protocols and leakage checks are not documented.
- Compute and efficiency: The training cost, memory footprint, and latency for large video-token sequences, as well as the actual inference speedup from parallel decoding in real robotic loops, are not reported.
- Safety and failure recovery: Safety constraints, failure detection, and recovery strategies when the learned actions deviate from the demonstration intent are not addressed.
- Evaluation transparency: Reported percentage improvements lack absolute success rates, task-wise breakdowns, and statistical significance; real-world evaluation details (task definitions, sample sizes, hardware, camera setups) are limited.
- Generalization to drastically different embodiments: Performance on robots with substantially different kinematics (e.g., mobile manipulators, dual-arm systems, soft robots) and sensor suites remains an open question.
- Temporal alignment strategies: Methods for aligning demonstration timelines to robot execution (dynamic time warping, pace normalization) are not explored.
- Uncertainty estimation: The model does not provide calibrated confidence or uncertainty measures to support risk-aware control and human oversight.
- Human-in-the-loop refinement: Mechanisms for interactive corrections, iterative refinement, or few-shot aggregation of multiple demonstrations are not studied.
- Ethical and data rights: The use of public human videos for training raises privacy and licensing considerations that are not discussed.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases and workflows that leverage the paper’s methods and findings today, grouped by sector. Each item includes dependencies and assumptions that affect feasibility.
- One-shot commissioning for pick-and-place and simple assembly (Robotics, Logistics, Manufacturing)
- What: Teach a robot a new SKU packing routine or small fixture assembly by showing a single expert video; ViVLA infers latent actions and generates robot actions without retraining the whole model.
- Tools/Workflow: ViVLA backbone + action decoder post-training via LoRA; camera(s) for expert-video capture; ROS integration for execution; safety geofencing.
- Assumptions/Dependencies: Task must be within the manipulation repertoire similar to LIBERO-style tasks; adequate visual coverage; reliable grasp planning and collision avoidance; supervisor oversight during first deployments; GPU/edge compute for video inference.
- Rapid task reconfiguration for production changeovers (Robotics, Manufacturing)
- What: When a product variant changes (new parts tray layout, slight object differences), operators record a short demonstration; ViVLA adapts to the new configuration on-the-fly.
- Tools/Workflow: “Video-to-Skill” pipeline: record demo → ViVLA latent actions → parallel-decoded action sequence → validate → deploy.
- Assumptions/Dependencies: Stable lighting/background; correct calibration of robot-camera extrinsics; gripper compatible with the object geometry; minimal occlusions.
- Cross-embodiment skill transfer inside robot fleets (Robotics, Software)
- What: Move the same skill from a 6-DoF arm to another brand/model using the unified latent action space and action decoder fine-tuning.
- Tools/Workflow: Latent Action Tokenizer (A3C) + per-robot action decoder; fleet orchestration (e.g., ROS2, gRPC); shared skill library with LACT tokens.
- Assumptions/Dependencies: Basic kinematic compatibility; adequate post-training on the target robot; consistent camera perspectives; shared perception stack standardized across embodiments.
- Human-to-robot teaching from mobile phone videos (Robotics, Daily life, Education)
- What: Record a single phone video of a task (e.g., tidying a specific shelf, loading a dishwasher rack); ViVLA learns and executes the routine.
- Tools/Workflow: ViVLA app to capture demo + instruction; upload; on-device or edge inference; execution with safety interlocks.
- Assumptions/Dependencies: Non-safety-critical tasks; robust viewpoint handling; sufficient scene visibility; household robot form factor and gripper capable of the task.
- Lab automation task onboarding (Robotics, Academia/Industry R&D)
- What: One-shot onboarding of pipetting-like motions, reagent bottle handling, opening/closing lids in non-critical settings under supervision.
- Tools/Workflow: Video capture of a single demo; ViVLA latent actions; per-lab robot action decoder; run-time checklist for safety and contamination control.
- Assumptions/Dependencies: Not for regulated or sterile-critical steps without validation; proper end-effector selection; reliable detection of containers and lids; clean-room compatibility may require additional sensing beyond vision.
- Dataset augmentation at scale using the video-driven expert–agent pipeline (Software, Robotics, Academia)
- What: Convert readily available human videos into robot trajectories to expand training sets and reduce data collection costs.
- Tools/Workflow: Pose estimation (HaMeR for hands, FoundationPose for objects, TRELLIS for meshes), 3D Gaussian splatting to render 4D robot scenes; pair with human videos; feed into model training.
- Assumptions/Dependencies: Availability of object meshes or reconstruction; accurate hand/object pose estimation; computational capacity for 3D reconstruction; licensing of source videos.
- Skill authoring and sharing inside organizations (Software, Robotics)
- What: Maintain a “Skill Card” registry: short video demo + language instruction + deployment metadata. Colleagues can reuse and adapt skills across sites and embodiments.
- Tools/Workflow: Skill repository with latent-action tokens (LACT) as the canonical representation; CI pipeline for validation; versioning and rollback.
- Assumptions/Dependencies: Organizational standards for safety and data governance; identity and access control; consistent perception stack.
- Faster inference for real-time manipulation via parallel decoding (Robotics, Software)
- What: Replace autoregressive action generation with parallel decoding to cut latency and avoid shortcut learning, improving responsiveness in closed-loop control.
- Tools/Workflow: ViVLA’s START_LACT_n and START_ACT_n tokens; action query tokens injected into the LM; real-time controller with low-latency IO.
- Assumptions/Dependencies: Deterministic scheduling; compute resources sized for parallel decoding; tested bounds on action burst lengths.
- Classroom and research use for one-shot imitation learning (Academia, Education)
- What: Hands-on teaching of transformers for control, latent action spaces, cycle-consistency; students record a single demo and deploy on EDU robots.
- Tools/Workflow: ViVLA open-source recipes; small robot arms; curated datasets from the paper; assignments on cross-embodiment transfer and masking strategies.
- Assumptions/Dependencies: Access to GPUs; faculty expertise in multimodal LMs; safe lab setup.
- Policy and compliance checklists for using public videos to train robots (Policy, Legal, Compliance)
- What: Immediate adoption of documentation templates to record provenance, consent, licensing, and risk controls when ingesting human videos into the expert–agent pipeline.
- Tools/Workflow: Data governance schema (provenance, consent flags, retention); content filtering; bias audits; opt-out mechanisms.
- Assumptions/Dependencies: Organizational willingness to enforce data governance; access to legal counsel; alignment with privacy regulations (e.g., GDPR/CCPA).
Long-Term Applications
These use cases are compelling but require further research, scaling, validation in safety-critical contexts, and potential standardization.
- Household generalist robots learning from online videos (Robotics, Daily life)
- What: Robots learn complex chores (multi-step cooking prep, laundry folding variations, child-safe tidying) by watching public tutorial videos.
- Tools/Workflow: Robust video parsing, temporal localization, broader object taxonomies, multimodal feedback (tactile, force).
- Assumptions/Dependencies: Stronger generalization far beyond training distribution; reliable on-device safety; robust handling of clutter and deformables; legal frameworks for content use.
- Cross-vendor interoperability via a standardized latent action token protocol (Robotics, Software, Policy)
- What: LACT (latent action tokens) become an industry-wide “MIDI for manipulation,” enabling skills to port across different robot brands.
- Tools/Workflow: Standards body (e.g., IEEE/ISO) defines token semantics; vendor SDKs implement decoding; neutral test suites.
- Assumptions/Dependencies: Broad industry adoption; detailed formalization of latent action semantics; certification processes.
- Skill marketplaces for “video-to-robot” tasks (Software, Robotics, Platform Economy)
- What: Enterprises and creators share monetizable skill videos with instructions; robots subscribe and execute tasks on demand.
- Tools/Workflow: Marketplace platform; validation and safety gating; telemetry for success/failure and auto-adaptation.
- Assumptions/Dependencies: Content licensing; incentives for high-quality demos; governance for liability and misuse.
- Adaptive industrial cells that self-learn new tasks from a single on-the-line demo (Robotics, Manufacturing)
- What: When a new product or fixture arrives, operators demonstrate once; the cell adapts without engineering change orders.
- Tools/Workflow: Robust pose estimation with multi-sensor fusion; integrated planning and compliance checking; digital twins for validation before execution.
- Assumptions/Dependencies: High reliability guarantees; integration with MES/ERP; safety certifications; formal verification of learned policies.
- Human-robot collaboration with shared latent action space (Robotics, Healthcare, Construction, Energy)
- What: Humans demonstrate subtasks; robots assist by inferring and continuing actions seamlessly (e.g., holding, positioning, attaching).
- Tools/Workflow: Co-manipulation frameworks; intent inference; safety envelopes; standardized human-robot skill interfaces.
- Assumptions/Dependencies: Rich sensing (force/torque, tactile); advanced intent modeling; rigorous safety; task-specific regulatory approvals (especially in healthcare/energy).
- Autonomous skill acquisition from enterprise video archives (Robotics, Software, Policy)
- What: Robots mine internal CCTV or training videos to build task repertoires, then request human validation for deployment.
- Tools/Workflow: Video retrieval and parsing; weak-to-strong supervision pipelines; human-in-the-loop approval; audit trails.
- Assumptions/Dependencies: Privacy compliance; secure data storage; robust filtering of irrelevant or unsafe content; scalable training infrastructure.
- Advanced lab and pharma workflows (Robotics, Healthcare)
- What: Precision multistep tasks (e.g., pipette serial dilutions, delicate sample handling) learned from one or few demonstrations, with closed-loop sensory correction.
- Tools/Workflow: Vision+tactile fusion; calibration with microfluidic constraints; error recovery models; GMP-compliant validation.
- Assumptions/Dependencies: High accuracy requirements; domain-specific instrumentation; regulatory validation; contamination controls.
- Field robots learning context-specific manipulations (Robotics, Agriculture, Construction, Energy)
- What: Robots learn new gate latches, valve operations, panel interactions from one demo by a technician on-site.
- Tools/Workflow: Ruggedized perception; domain adaptation to outdoor lighting/weather; policy gating based on risk assessments.
- Assumptions/Dependencies: Environmental robustness; reliable localization; compliance with site safety protocols; integration with maintenance systems.
- Universal generalist VLA foundation models for manipulation (Academia, Robotics)
- What: Large-scale VLA models with unified latent action spaces trained on millions of expert–agent pairs across thousands of tasks; near-human adaptability.
- Tools/Workflow: Continual learning; scalable data generation (e.g., improved Gaussian splatting, simulation-to-real bridges); comprehensive benchmarks.
- Assumptions/Dependencies: Massive compute and data; mitigation of catastrophic forgetting; fairness and bias considerations; open benchmarks and reproducibility.
- Policy frameworks for on-the-fly robot learning (Policy, Standards)
- What: Safety and compliance standards for robots that modify behavior from single demonstrations; auditability and rollback requirements; liability allocation.
- Tools/Workflow: Certification schemes; incident reporting; standardized telemetry; “safe learning” guidelines.
- Assumptions/Dependencies: Multi-stakeholder consensus; cross-jurisdiction harmonization; evidence-based thresholds for deployment.
Notes on Feasibility and Dependencies Across Applications
- Model and compute: ViVLA relies on a strong VLM backbone (e.g., Qwen2.5-VL) and parallel decoding; edge GPU/TPU resources may be needed for real-time operation.
- Post-training: The action decoder typically requires light fine-tuning (LoRA) per robot embodiment to map latent tokens to continuous controls.
- Data quality: Single demonstration videos must provide sufficient visibility and minimal occlusion; multi-view or high-resolution inputs improve reliability.
- Safety: Early deployments should be supervised; add constraints (virtual fences, speed limits) and formal checks for high-risk environments.
- Perception stack: The video-driven data pipeline depends on hand/object pose estimators (HaMeR, FoundationPose, TRELLIS) and 3D Gaussian splatting; accuracy affects downstream skill quality.
- Legal and ethics: Using human videos requires attention to consent, licensing, privacy (GDPR/CCPA), and potential bias in datasets.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a brief definition and a verbatim usage example.
- 3D Gaussian Splatting: A rendering technique that represents scenes with Gaussian primitives to reconstruct and render 3D/4D views from multi-view observations. "employs 3D Gaussian splatting to render realistic 4D scenes depicting an agent robot executing the demonstrated tasks"
- A3C (Action-Centric Cycle-Consistency): The proposed training framework that enforces cycle-consistency on latent actions to unify semantics across expert videos and agent demonstrations. "Latent Action Learning with Action-Centric Cycle-Consistency (A3C)."
- Action-centric cycle consistency: A constraint that requires latent actions decoded into future frames to be recoverable from those frames, promoting semantic consistency and cross-embodiment alignment. "We concurrently enforce action-centric cycle consistency"
- Action discretization: Converting continuous action values into discrete bins to align with token-based modeling in LLMs. "OpenVLA~\cite{openvla} adopts a similar action discretization approach while training vision-LLMs"
- Adversarial losses (GAN): Losses used to train a generator and discriminator in opposition, aligning generated samples with the real data distribution. "Based on these local and global logits, we define the adversarial losses for both the decoder and discriminator "
- Autoregressive action modeling: A sequential prediction paradigm where each action token is predicted conditioned on previously observed (often ground-truth) tokens. "Autoregressive action modeling strategy results in shortcut learning and increased inference latency."
- Codebook: A finite set of discrete vectors used to quantize latent embeddings in VQ-VAE-style models. "represented using tokens selected from a codebook vocabulary of size ."
- DINOv2: A self-supervised vision foundation model used to extract robust image embeddings. "using DINOv2~\cite{oquab2023dinov2}."
- Discriminator (local-global): A model component that evaluates generated images at both patch-level (local) and pooled feature-level (global) to enforce realistic reconstructions. "we introduce a local-global discriminator that aligns the distribution of generated frames with dataset images across both local details and global style."
- FoundationPose: A pose estimation method that predicts 6D object poses over time from visual input. "FoundationPose \citep{wen2023foundationpose} estimates temporal object poses"
- Flow matching: A continuous trajectory-generation technique that trains models to match transport flows between distributions, enabling precise action generation. "generates continuous actions via flow matching"
- Flow representations: Visual representations encoding future point trajectories in images or point clouds, useful for cross-embodiment learning. "Flow representations, which capture future trajectories of query points in images or point clouds, have been explored for cross-embodiment learning"
- HaMeR: A method for reconstructing hand shape and pose from video, producing mesh and kinematic parameters. "we first apply HaMeR \citep{pavlakos2024reconstructing} to predict hand shape and pose parameters"
- Human2Robot dataset: A constructed dataset of paired human videos and synthesized robot executions for the same tasks. "construct the Human2Robot dataset containing 89,736 human-robot paired training samples through this pipeline."
- Iterative Closest Point (ICP): An algorithm for aligning 3D shapes or point clouds by iteratively minimizing point-to-point distances. "The Iterative Closest Point (ICP) \citep{besl1992method, rusinkiewicz2001efficient} is further implemented to align the hand mesh with the segmented hand point cloud"
- LLMs: Transformer-based models trained on massive text corpora, exhibiting broad generalization and reasoning abilities. "Inspired by the remarkable success of LLMs"
- Latent action tokenizer: A learned module that encodes visual transitions into discrete latent action tokens suitable for language-model prediction. "we propose training a latent action tokenizer that derives action representations directly from visual observations."
- LIBERO benchmark: A standardized evaluation suite for robot manipulation tasks used to measure generalization and performance. "over 30\% improvement on unseen tasks in the LIBERO benchmark"
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning technique that injects low-rank updates into pre-trained model weights. "fine-tuned using Low-Rank Adaptation (LoRA) \cite{hu2022lora}"
- Model-Agnostic Meta-Learning (MAML): A meta-learning algorithm that optimizes for rapid adaptation to new tasks with minimal updates. "Finn et al. \cite{finn2017one} extended model-agnostic meta-learning (MAML) to visual imitation learning"
- Open X-Embodiment (OXE) dataset: A large-scale, multi-embodiment robot dataset aggregating data across institutions. "Open X-Embodiment (OXE) dataset~\cite{o2024open}"
- OpenVLA: A vision-language-action model trained on large-scale robot datasets using action discretization. "OpenVLA~\cite{openvla} adopts a similar action discretization approach"
- PaliGemma: A vision-LLM architecture adapted in robotics pipelines for action generation. "~\cite{pi_0} adapts the PaliGemma VLM by integrating a specialized action expert module"
- Parallel decoding: A generation strategy that predicts multiple action tokens simultaneously to prevent shortcut learning and reduce latency. "we adopt a parallel decoding strategy where the model receives empty action embeddings as input and generates all action tokens concurrently in a single forward pass."
- Qwen2.5-VL: A multi-modal vision-LLM backbone used for video and image understanding in the proposed system. "Our framework builds upon the Qwen2.5-VL \cite{bai2025qwen2} vision-LLM"
- RT-2: A VLA approach that discretizes actions to co-train web-scale LMs with robot trajectory data. "A pioneering work, RT-2~\cite{RT-2}, introduced a discretization strategy that uniformly quantizes continuous action values into 256 bins per dimension."
- Spatial transformer: A transformer architecture focused on spatial attention across image patches for reconstruction or discrimination tasks. "The decoder , implemented as a spatial transformer containing spatial blocks with spatial attention layers"
- Spatial-temporal (ST) transformer: A transformer with interleaved spatial and temporal attention designed to model visual dynamics across frames. "a spatial-temporal (ST) transformer, which consists of spatiotemporal blocks"
- Temporal localization: An auxiliary task where the model identifies the position of inserted observation images within a video timeline to enhance cross-modal exchange. "we incorporate a temporal localization task that inserts the agent's observation images into the demonstration video sequence"
- Temporal-spatial masking strategy: A training-time video token masking approach across time and space to reduce redundancy and improve understanding. "we introduce a temporal-spatial masking strategy that stochastically masks video tokens across both temporal and spatial dimensions."
- Vector Quantized Variational Autoencoder (VQ-VAE): A generative model that quantizes latent embeddings into discrete codebook entries for stable training and discrete representations. "optimized using the VQ-VAE~\cite{van2017neural} objective."
- Vision Transformer (ViT): A transformer architecture that processes images as sequences of patch tokens, often with windowed attention for efficiency. "consists of a Vision Transformer (ViT) with window attention for efficient processing at native resolutions"
- Vision-Language-Action (VLA) models: Multi-modal models that perceive visual inputs and instructions to output robot actions end-to-end. "Vision-Language-Action models (VLAs) ~\cite{RT-2, openvla, qu2025spatialvla, pi_0, bjorck2025gr00t, pertsch2025fast, bu2025univla} have emerged as a promising approach for processing multimodal inputs to generate robotic actions."
- Vision-LLMs (VLMs): Models that jointly understand visual and textual inputs, serving as foundations for action-conditioned control. "vision-LLMs (VLMs) \cite{bai2025qwen2, team2025kimi, team2024chameleon, liu2023visual, xiong2025bluelm}"
Collections
Sign up for free to add this paper to one or more collections.

