Qwen-Image-Layered: Towards Inherent Editability via Layer Decomposition (2512.15603v1)
Abstract: Recent visual generative models often struggle with consistency during image editing due to the entangled nature of raster images, where all visual content is fused into a single canvas. In contrast, professional design tools employ layered representations, allowing isolated edits while preserving consistency. Motivated by this, we propose \textbf{Qwen-Image-Layered}, an end-to-end diffusion model that decomposes a single RGB image into multiple semantically disentangled RGBA layers, enabling \textbf{inherent editability}, where each RGBA layer can be independently manipulated without affecting other content. To support variable-length decomposition, we introduce three key components: (1) an RGBA-VAE to unify the latent representations of RGB and RGBA images; (2) a VLD-MMDiT (Variable Layers Decomposition MMDiT) architecture capable of decomposing a variable number of image layers; and (3) a Multi-stage Training strategy to adapt a pretrained image generation model into a multilayer image decomposer. Furthermore, to address the scarcity of high-quality multilayer training images, we build a pipeline to extract and annotate multilayer images from Photoshop documents (PSD). Experiments demonstrate that our method significantly surpasses existing approaches in decomposition quality and establishes a new paradigm for consistent image editing. Our code and models are released on \href{https://github.com/QwenLM/Qwen-Image-Layered}{https://github.com/QwenLM/Qwen-Image-Layered}
Sponsor





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is the paper about?
This paper introduces a new AI model called Qwen-Image-Layered that can split a single picture into several separate “layers,” like how professional designers use layers in Photoshop. Each layer holds one piece of the picture (like a person, text, or an object) along with its transparency. Because the content is separated, you can edit one layer (resize it, move it, recolor it, replace it) without accidentally changing everything else. The goal is to make image editing more precise, consistent, and easy.
What questions did the researchers ask?
The researchers wanted to solve a common problem: when you edit a normal (flat) image, changing one thing often messes up other parts. They asked:
- Can we turn a regular image into multiple clean, meaningful layers (with transparency) so edits don’t spill over to other areas?
- Can the model handle a variable number of layers (not just “foreground/background”)?
- Can we train a system that’s both good at generating images and at breaking them into layers?
- How can we get enough high-quality training data with layered images?
How did they do it?
They built an end-to-end “diffusion” model (a popular method for image generation) that takes a normal RGB image and outputs several RGBA layers. Here’s the approach, explained with simple ideas and analogies:
Key idea: Layers like stickers on a window
- Think of an image as a stack of transparent stickers placed on top of each other. Each sticker shows one part of the scene (a character, background, text). The “A” in RGBA means “alpha,” which is the transparency of the sticker.
- If you edit one sticker, the others don’t change. This prevents unintended shifts in color, shape, or position elsewhere.
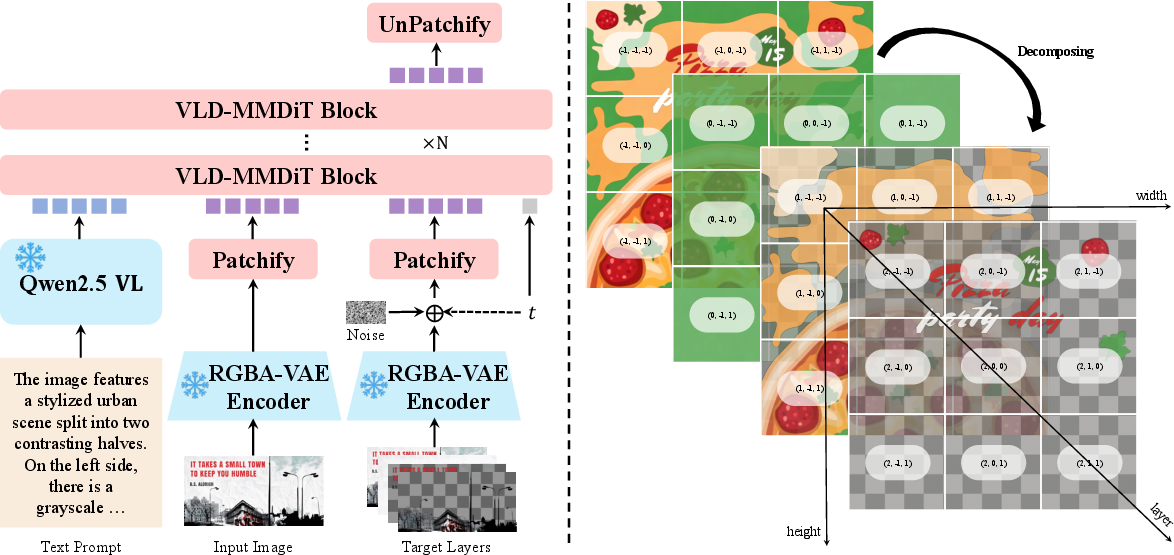
RGBA-VAE: A shared “compressor/decompressor” for images
- A VAE (Variational Autoencoder) is like a smart compressor/decompressor for images. It turns images into a smaller, learnable form (latent space) and back.
- They built an RGBA-VAE that works for both regular RGB images and transparent RGBA layers. Using a single shared space makes it easier for the model to connect the original picture to its future layers and reduces mismatches between inputs and outputs.
VLD-MMDiT: An architecture that handles multiple, variable layers
- The model looks at the input image and the layers it’s trying to create “side by side,” so it can learn how parts relate to each other. This uses attention (a way for the model to focus on relationships), similar to how LLMs read words in a sentence.
- “Variable Layers Decomposition” means the system isn’t stuck with only two layers. It can produce as many as needed.
- Layer3D RoPE: This is a way to mark the position of patches not only in height and width but also which layer they belong to. Think of it as giving each sticker an ID and order so the model doesn’t mix them up.
Multi-stage training: Learning step by step
They trained the model in three stages, starting simple and increasing difficulty, like leveling up in a game:
- Text-to-RGB and Text-to-RGBA: Learn to generate normal images and images with transparency from text prompts.
- Text-to-Multi-RGBA: Learn to create multiple layers from text, including both the final combined image and its separate layers.
- Image-to-Multi-RGBA: Learn to take an existing image and break it into multiple RGBA layers.
Training data: Real layered files from Photoshop
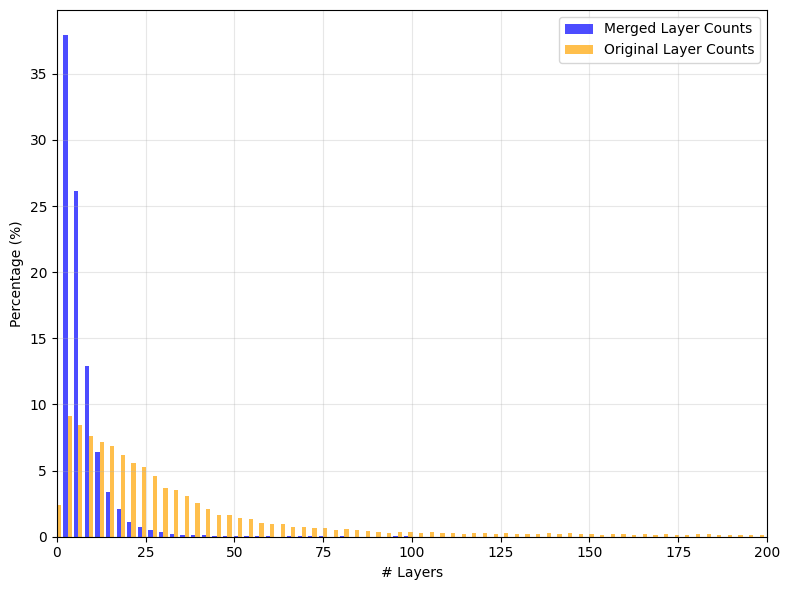
- Good layered data is rare. So they collected real PSD (Photoshop) files, extracted layers, filtered out low-quality parts, merged non-overlapping layers to keep things simpler, and used an AI captioner to describe the images.
- This gave them a strong dataset to teach the model how real layered designs are built.
What did they find?
The model consistently produced better layers than previous methods and made editing more reliable. In simple terms: cleaner layers, better transparency, fewer artifacts, and edits that don’t break other parts of the image. Highlights include:
- Higher-quality layer decomposition: Compared to strong baselines (like LayerD), Qwen-Image-Layered generated layers with more accurate transparency (alpha) and fewer errors. Quantitative scores showed lower color errors and higher overlap with ground-truth transparency.
- Better RGBA reconstruction: Their RGBA-VAE reconstructed transparent images more faithfully than prior systems (better PSNR/SSIM and lower perceptual error).
- Consistent editing: After decomposition, basic edits like resizing, repositioning, and recoloring were easy and precise. Edits stayed local to the chosen layer, avoiding the “semantic drift” (like a person’s face changing) and misalignment problems common in traditional edits.
- Multilayer generation from text: The model could generate layered images directly from prompts, and also from a two-step pipeline where it first makes a raster image and then decomposes it. This improved both how well the image matched the prompt and how nice it looked.
Why does this matter?
Editing a flat image is risky: change one part and others can shift or blur. By making layered pictures the default, this research:
- Gives creators and designers safer, more precise control: Move an object, change its color, or update text—without touching anything else.
- Improves reliability in photo edits and creative workflows: Identities, backgrounds, and layouts stay consistent during edits.
- Helps future AI systems build complex scenes: Games, AR/VR, and graphic design can benefit from layered, composable content.
- Opens a new path for generative models: Instead of generating a single flat image, models can produce structured, editable layers from the start.
In short, Qwen-Image-Layered turns images into neat, transparent layers that make editing simpler and more dependable—much closer to how professionals want to work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper that future work could address:
- Automatic determination of the number of layers (N): The method supports variable N but does not describe how N is predicted or selected at inference; criteria or a termination mechanism for “enough” layers is absent.
- Layer ordering and depth semantics: It is unclear whether the produced layer order is consistent with scene depth/occlusion or stable across runs; no constraints or evaluation of order consistency are provided.
- Completeness of hidden content (background inpainting): The paper claims complete, editable layers, but provides no quantitative evaluation that occluded regions are plausibly reconstructed after foreground removal (especially on natural photos).
- Alpha validity and compositing fidelity: There is no explicit constraint or analysis ensuring alphas are in [0,1], free from fringing/color bleed, or that the composite of predicted layers exactly reconstructs the input (reconstruction error for I2L is not reported).
- Handling non-normal blend modes and effects: The approach assumes standard alpha compositing, yet real PSDs commonly use multiply/screen/overlay, masks, and effects (e.g., drop shadows, glows). How to model, decompose, and re-compose such cases remains open.
- Semi-transparency and fine structures: Robustness and quantitative quality of alphas for hair, smoke, motion blur, glass, and soft edges on natural images are not evaluated (only Crello-like graphics and AIM-500 reconstruction are measured).
- Editing consistency when changing layout: When moving/resizing objects, inter-layer lighting/shadows/reflections and occlusion updates are not handled; methods to maintain physical plausibility after edits are not discussed.
- Scalability with number of layers and resolution: Attention concatenation grows with N and spatial tokens; runtime/memory scaling, maximum feasible layers beyond 20, and performance at high resolutions are not analyzed.
- Runtime and resource footprint: Inference speed, GPU memory requirements, and practical deployment considerations (e.g., batched processing, latency) are not reported.
- Generalization to diverse domains: Robustness to natural photographs with clutter, varied lighting, textured backgrounds, or heavy compression artifacts is not quantitatively assessed; evaluation relies on Crello and curated PSD-derived data.
- Dataset transparency and coverage: The PSD-derived dataset’s availability, licensing, and representativeness (e.g., coverage of blend modes/effects, real semi-transparent content) are unclear; the impact of merging non-overlapping layers on semantics is not studied.
- Caption dependence: The model uses auto-generated captions for conditioning, but the sensitivity of decomposition quality to noisy or erroneous captions is untested; performance without text is not compared.
- Semantic disentanglement measurement: Claims of “semantically disentangled” layers lack objective metrics (e.g., object-level overlap with segmentation, category purity, cross-layer redundancy) and human perceptual studies.
- Robustness and failure modes: No systematic analysis of typical errors (e.g., layer fragmentation, duplicate objects across layers, alpha leakage, background holes) or conditions that cause them.
- Comparison breadth: Quantitative comparisons exclude several recent layered decomposition/generation baselines (e.g., methods cited like DiffDecompose, PrismLayers/PSDiffusion variants), limiting the strength of empirical claims.
- Choice of latent shared space: While RGBA-VAE unifies input/output latents, it may encode redundant information across layers; approaches to factor shared structure (e.g., background bases, low-rank shared components) are not explored.
- Guarantees for edit safety: There is no metric showing that edits confined to a single layer leave other layers pixel-identical after re-composition; a formal “no unintended drift” measure is missing.
- Control granularity: Mechanisms for explicit user control over grouping, layer semantics (objects vs. materials vs. text), or re-layering after decomposition are not provided.
- Out-of-distribution behavior: How the model handles images with hundreds of layers, vector graphics, or artworks with unusual compositing pipelines is unclear; extrapolation beyond the training regime is not tested.
- Extension to video: Temporal consistency for layered video decomposition/editing is not addressed; maintaining stable layer identities and alphas across frames remains open.
- Physical/geometry priors: The method does not incorporate depth, illumination, or material priors; integrating 3D/relighting constraints to improve edit realism is an open direction.
- Evaluation of edit tasks: The paper shows qualitative edits but lacks quantitative “editing consistency” metrics (e.g., identity preservation, SSIM/LPIPS in unedited regions, flicker/stability under repeated edits).
- Post-processing and file interoperability: Export to PSD/AE with accurate layer properties, color management, premultiplied vs. straight alpha handling, and round-trip integrity are not discussed.
- Training portability: It is unclear how easily the multi-stage scheme and Layer3D RoPE transfer to other base models or VAEs; ablations on portability and initialization sensitivity are missing.
- Safety, privacy, and ethics: The PSD data pipeline may include sensitive content; dataset filtering, consent, and watermark/copyright considerations are not detailed.
Glossary
- AIM-500 dataset: A benchmark dataset used to evaluate image reconstruction quality. "Quantitative comparison of RGBA image reconstruction on the AIM-500 dataset~\cite{li2021deep}."
- Alpha blending: A compositing process that combines layers using their alpha (transparency) values to produce a final image. "The original image can be reconstructed by sequential alpha blending as follows:"
- Alpha channel: The transparency component of an RGBA image that controls how opaque each pixel is. "For RGB images, the alpha channel is set to 1."
- Alpha matte: A per-pixel transparency mask (typically in [0,1]) specifying how much of a layer is visible at each pixel. "each layer comprises a color component and an alpha matte "
- Dynamic Time Warping (DTW): A sequence alignment technique that finds an optimal match between two sequences, allowing for non-linear alignment; used here to align layer sequences. "This protocol aligns layer sequences of varying lengths using order-aware Dynamic Time Warping"
- Flow Matching: A training objective for generative models that learns continuous flows from noise to data by predicting velocities along a path. "Following Qwen-Image, we adopt the Flow Matching training objective."
- Image inpainting: Filling in missing or occluded regions in an image to plausibly reconstruct content. "followed by image inpainting~\cite{yu2023inpaint} to reconstruct the background."
- Inter-layer and intra-layer attention mechanisms: Attention designs that model relationships across different layers (inter-layer) and within a single layer (intra-layer) to maintain semantic consistency. "Through carefully designed inter-layer and intra-layer attention mechanisms, LayerDiff~\cite{huang2024layerdiff} is able to synthesize semantically consistent multilayer images."
- Latent transparency: An approach that models transparency directly in the latent space of an autoencoder or diffusion framework. "LayerDiffusion~\cite{zhang2024transparent} introduces latent transparency into VAE"
- Layer3D RoPE: A rotary positional embedding variant extended with a layer dimension to support variable numbers of layers. "we propose a Layer3D RoPE within each VLD-MMDiT block to enable the decomposition of a variable number of layers"
- Logit-normal distribution: A continuous distribution obtained by applying the logistic function to a normal variable; used to sample timesteps in flow-based training. "a timestep from a logit-normal distribution."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique that adds low-rank adapters to existing layers. "introduces latent transparency into VAE and employs two different LoRA~\cite{hu2022lora} with shared attention"
- LPIPS (Learned Perceptual Image Patch Similarity): A perceptual metric that measures visual similarity using deep features. "LPIPS"
- Matting: Estimating foreground opacity (alpha matte) to separate foreground from background, especially around fine structures like hair. "or matting~\cite{li2024matting} to extract foreground objects"
- MLLM (Multimodal LLM): A large model that processes and reasons over multiple modalities (e.g., text and images) to provide conditioning signals. "the text prompt is encoded into text condition with MLLM."
- MMDiT (Multi-Modal Diffusion Transformer): A transformer-based diffusion architecture that processes multimodal inputs for image synthesis or decomposition. "adapting MMDiT to the latent space of RGBA VAE."
- Multi-Modal attention: An attention mechanism that integrates multiple modalities (e.g., text and images) within a unified transformer block. "we employ a Multi-Modal attention~\cite{esser2024scaling} to directly model these relationships"
- Multi-stage Training: A curriculum-style training strategy that progressively introduces tasks and components to stabilize learning and improve performance. "a Multi-stage Training strategy to adapt a pretrained image generation model into a multilayer image decomposer."
- Patchification: Splitting an image (or latent feature map) into non-overlapping patches to be processed as token sequences by a transformer. "we apply patchification to the noise-free input image and the intermediate state "
- Photoshop Document (PSD): Adobe Photoshop’s native layered image file format used here as a source of multilayer training data. "Photoshop documents (PSD)."
- PSNR (Peak Signal-to-Noise Ratio): A reconstruction quality metric that measures the fidelity of a reconstructed image relative to a reference. "PSNR"
- Rectified Flow: A framework that defines straight-line paths in data space for learning transport from noise to data within flow-based generative models. "According to Rectified Flow~\cite{liu2022flow}"
- RGBA: A four-channel image color model containing red, green, blue, and alpha (transparency) channels. "decomposes a single RGB image into multiple semantically disentangled RGBA layers"
- RGBA-VAE: A variational autoencoder designed to encode/decode four-channel RGBA images, enabling a shared latent space for RGB and RGBA. "we propose an RGBA-VAE to unify the latent representations of RGB and RGBA images"
- rFID (Reconstruction Fréchet Inception Distance): A variant of FID used to assess the distributional quality of reconstructed images by comparing feature statistics. "rFID"
- Segmentation: Partitioning an image into meaningful regions (e.g., objects), often used as a pre-processing step for decomposition. "leverages segmentation~\cite{ravi2024sam} or matting~\cite{li2024matting} to extract foreground objects"
- Semantic drift: Unintended changes to high-level semantics (e.g., identity or attributes) when editing or generating images. "This issue typically appears as semantic drift (\eg unintended changes to a person's identity)"
- Soft IoU: A differentiable or continuous version of Intersection over Union used to evaluate overlap between predicted and ground-truth masks/alphas. "Alpha soft IoU"
- SSIM (Structural Similarity Index Measure): A perceptual metric that evaluates structural similarity between images. "SSIM"
- Variational Autoencoder (VAE): A generative model that learns a latent distribution to encode and reconstruct images via a stochastic encoder-decoder. "Variational Autoencoders (VAEs)~\cite{kingma2013auto} are commonly employed in diffusion models"
- VLD-MMDiT (Variable Layers Decomposition MMDiT): An extension of MMDiT that supports decomposing images into a variable number of layers. "we propose a VLD-MMDiT (Variable Layers Decomposition MMDiT), which supports decomposition into a variable number of layers"
- Vision-LLMs (VLMs): Models that jointly process visual and textual inputs to perform tasks like captioning or guidance for decomposition. "Vision-LLMs~\cite{liu2023visual} to guide this decomposition process."
Practical Applications
Below are practical, real-world applications derived from the paper’s findings, methods, and innovations (RGBA-VAE, VLD-MMDiT, Layer3D RoPE, multi-stage training, and the PSD data pipeline). Each item includes the primary sectors, potential tools/workflows, and assumptions that may impact feasibility.
Immediate Applications
- Layer-preserving photo editing for consumers
- Sectors: healthcare (PII redaction in public-facing materials), social media, photography
- What: Convert a single photo into disentangled RGBA layers to resize, recolor, reposition, or remove objects without affecting the rest of the image (reduces identity drift and pixel shifts).
- Tools/workflows: Mobile/desktop photo editors with “Decompose to layers” and layer-specific transforms; API/SDK for app integration.
- Assumptions/dependencies: GPU/edge inference; decomposition quality can vary on complex occlusions; privacy and consent for uploaded photos.
- Graphic design asset salvage and non-destructive editing
- Sectors: advertising, publishing, marketing, software (creative tools)
- What: Turn flattened raster assets into editable, semantically separated layers (akin to PSD), enabling late-stage changes without rebuilding designs.
- Tools/workflows: Photoshop/Figma plugins (“QIL Decompose”) and batch converters for asset libraries; CMS integration to store layered assets.
- Assumptions/dependencies: Performance depends on domain coverage; licensing/usage rights for existing assets.
- E-commerce product imagery pipeline
- Sectors: retail/e-commerce
- What: Isolate product vs. background/props into layers; bulk recoloring, background swaps, shadow tweaks; marketplace-specific variants while preserving product fidelity.
- Tools/workflows: “Product Layer Studio” batch pipeline; SKU-level layer metadata; auto-caption to drive T2L (Text-to-Multi-RGBA) variants.
- Assumptions/dependencies: Need SKU consistency; fine-tuning on domain imagery for accuracy; marketplace compliance (e.g., background color rules).
- Dynamic creative optimization (DCO) for marketing
- Sectors: advertising, martech
- What: A/B test creatives by swapping text, CTA buttons, or props in isolated layers; run rapid iterations while keeping background and subject intact.
- Tools/workflows: Ad platform plugin or API with layer catalog; automated caption prompts to generate variants via T2L.
- Assumptions/dependencies: Brand guidelines; review/approval workflows; attribution and data governance.
- Text-only edits, localization, and accessibility in posters and UIs
- Sectors: media, localization, education, software (UI/UX)
- What: Accurate layer separation of text elements for multi-language replacement or accessibility (font size, contrast) without layout drift.
- Tools/workflows: Localization pipeline that uses “Text layer isolator” + translation memory; automated reflow tests.
- Assumptions/dependencies: Robust text decomposition across fonts and stylings; language-specific typography constraints.
- Content moderation and compliance (selective redaction)
- Sectors: policy/compliance, media platforms
- What: Remove or blur sensitive content (faces, license plates, logos) as isolated layers; preserve rest of the image exactly unchanged to meet regulatory requirements.
- Tools/workflows: Moderation dashboard with “Sensitive Layer Finder”; audit logs of which layers were edited.
- Assumptions/dependencies: Reliable detection of sensitive elements; audit trails; consent and governance for edits.
- VFX/motion graphics prep for stills
- Sectors: film/animation, media production
- What: Decompose reference frames or still assets into RGBA layers to simplify compositing, color grading, and element motion without re-sculpting masks.
- Tools/workflows: Compositor handoff as layered assets; Nuke/After Effects bridge.
- Assumptions/dependencies: Semi-transparent elements and soft boundaries handled; artist QA remains necessary.
- Synthetic dataset creation for segmentation/matting research
- Sectors: academia, CV/ML research
- What: Generate layered datasets from raster images to bootstrap matting/segmentation training; use T2L to synthesize diverse layered scenes with ground-truth alphas.
- Tools/workflows: Data pipeline using RGBA-VAE + I2L/T2L; auto-caption augmentation with Qwen2.5-VL.
- Assumptions/dependencies: Domain shift to targeted tasks; annotation quality checks; licensing for source images.
- Layer-aware T2I prototyping for design ideation
- Sectors: software (creative tools), gaming, AR filters
- What: Text-to-multi-RGBA (T2L) generation to produce scene drafts where art directors can toggle, reorder, or restyle layers for fast iteration.
- Tools/workflows: “Layered Prompt Studio” with layer bins (subject, background, text, effects).
- Assumptions/dependencies: Prompt quality; semantic alignment with brand/storyboards.
- PSD mining for enterprise asset governance
- Sectors: enterprise creative operations, DAM/CMS
- What: Use the PSD extraction pipeline to standardize, filter, annotate, and merge layers from archival PSDs; normalize assets for downstream AI editing.
- Tools/workflows: DAM ingest service with “Layer normalizer”; automated captioning and metadata tagging.
- Assumptions/dependencies: PSD licensing and IP; data cleaning needs (e.g., removing non-contributing layers as described in the paper).
Long-Term Applications
- Temporally consistent video layer decomposition and editing
- Sectors: film/animation, social media, sports broadcasting
- What: Extend I2L to videos with stable layers across frames to reposition subjects, recolor outfits, or replace ads while preserving identity and geometry.
- Tools/workflows: “Video Layered Editor” with trackable layer IDs; cross-frame consistency checks.
- Assumptions/dependencies: New training for temporal consistency; higher compute; occlusion and motion handling.
- AR/VR interactive layer-aware scenes
- Sectors: AR/VR, robotics, gaming
- What: Layered assets enable occlusion-aware placement and interactive manipulation of scene elements; object-level transparency for spatial understanding.
- Tools/workflows: Real-time engines integrating RGBA-VAE; runtime layer toggling.
- Assumptions/dependencies: Real-time inference and acceleration; depth/geometry integration; HMD platform constraints.
- Domain-specialized decomposition (medical/CAD/remote sensing)
- Sectors: healthcare, manufacturing, geospatial
- What: Adapt layered decomposition for domain-specific semantics (e.g., isolating organs in scans, parts in CAD renders, land cover in satellite images).
- Tools/workflows: Domain fine-tuning + expert-in-the-loop review; regulatory-grade audit.
- Assumptions/dependencies: Extensive domain data; safety/accuracy standards; specialized evaluation metrics.
- Layer-level provenance, watermarking, and rights management
- Sectors: policy/compliance, media licensing
- What: Encode provenance per layer (creator, license, edit history); enforce permissions (e.g., text layer editable, subject layer locked).
- Tools/workflows: “Layer Rights Registry” integrated with DAM; per-layer watermarks and cryptographic signatures.
- Assumptions/dependencies: Standards and legal frameworks; interoperability across tools; resistance to tampering.
- Design version control and collaborative editing at layer granularity
- Sectors: enterprise creative ops, software tooling
- What: Git-like diffs and merges on layers; conflict-free multi-user edits; audit trails of layer changes.
- Tools/workflows: Layer-aware VCS plugins; approval workflows and rollback.
- Assumptions/dependencies: Consistent layer IDs; cross-tool interoperability; access control and governance.
- 3D/depth-aware layered representations
- Sectors: gaming, XR, digital twins
- What: Extend from 2D layers to depth-aware or semi-3D layers for parallax and spatial edits; improved compositing realism.
- Tools/workflows: Hybrid 2D/3D pipeline; depth map + RGBA layers; parallax-aware editor.
- Assumptions/dependencies: New model architectures; multi-view or depth supervision; increased training complexity.
- On-device, real-time decomposition
- Sectors: mobile, consumer apps
- What: Run I2L on-device for instant layer edits in camera apps (e.g., live removal of objects, live caption layer control).
- Tools/workflows: Distilled/quantized models; GPU/NPUs; offline mode.
- Assumptions/dependencies: Hardware acceleration; power/battery constraints; model compression and privacy-safe design.
- Synthetic worlds and simulators built from layered assets
- Sectors: robotics, autonomy, simulation
- What: Compose synthetic training scenes by programmatically swapping layers to vary layout, occlusion, and appearance for robust CV training.
- Tools/workflows: Scenario generator using T2L; curriculum schedules that adjust layer complexity.
- Assumptions/dependencies: Transfer to real-world performance; domain randomization; integration with downstream CV tasks.
- API marketplaces for “raster-to-layer” services
- Sectors: software/SaaS, creative ecosystems
- What: Offer scalable decomposition and T2L generation APIs with SLAs for agencies, platforms, and app developers.
- Tools/workflows: Managed inference, batch pipelines, usage analytics; enterprise agreements.
- Assumptions/dependencies: Cost-effective inference; demand aggregation; security/compliance for customer data.
- Standards and best practices for responsible layered editing
- Sectors: policy, industry consortia
- What: Establish guidelines for non-destructive, transparent edits; clear labeling when content has been layer-edited; per-layer audit logs.
- Tools/workflows: Compliance checkers; certification programs; public disclosures.
- Assumptions/dependencies: Multi-stakeholder consensus; alignment with content authenticity initiatives (e.g., C2PA).
Notes on technical dependencies across applications:
- Core components: RGBA-VAE (shared latent space), VLD-MMDiT + Layer3D RoPE (variable-length, layer-aware attention), multi-stage training (task adaptation), PSD pipeline (real-world multilayer data).
- Performance is sensitive to domain coverage and training data (e.g., semi-transparent layers, complex occlusions, natural photos vs. graphic designs).
- Captioning quality affects T2L; the paper relies on Qwen2.5-VL for auto-generated descriptions.
- Compute and latency constraints will govern deployment (cloud vs. edge); privacy and licensing must be accounted for in real-world pipelines.
Collections
Sign up for free to add this paper to one or more collections.