Self-Rewarding Vision-Language Model via Reasoning Decomposition
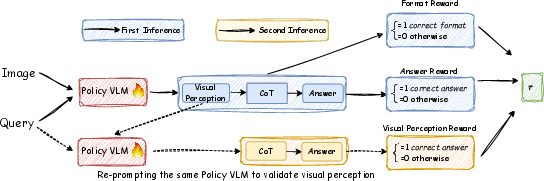
Abstract: Vision-LLMs (VLMs) often suffer from visual hallucinations, saying things that are not actually in the image, and language shortcuts, where they skip the visual part and just rely on text priors. These issues arise because most post-training methods for VLMs rely on simple verifiable answer matching and supervise only final outputs, leaving intermediate visual reasoning without explicit guidance. As a result, VLMs receive sparse visual signals and often learn to prioritize language-based reasoning over visual perception. To mitigate this, some existing methods add visual supervision using human annotations or distilled labels from external large models. However, human annotations are labor-intensive and costly, and because external signals cannot adapt to the evolving policy, they cause distributional shifts that can lead to reward hacking. In this paper, we introduce Vision-SR1, a self-rewarding method that improves visual reasoning without relying on external visual supervisions via reinforcement learning. Vision-SR1 decomposes VLM reasoning into two stages: visual perception and language reasoning. The model is first prompted to produce self-contained visual perceptions that are sufficient to answer the question without referring back the input image. To validate this self-containment, the same VLM model is then re-prompted to perform language reasoning using only the generated perception as input to compute reward. This self-reward is combined with supervision on final outputs, providing a balanced training signal that strengthens both visual perception and language reasoning. Our experiments demonstrate that Vision-SR1 improves visual reasoning, mitigates visual hallucinations, and reduces reliance on language shortcuts across diverse vision-language tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Below is a concise list of concrete knowledge gaps, limitations, and open questions that remain unresolved and can guide future research.
- Reliability of self-reward verification: The second-pass “caption-only” answer check is performed by the same policy model, risking circular validation, confirmation bias, and reward hacking. Quantify how often successes arise from language priors rather than faithful visual grounding via human audits and counterfactual tests (e.g., image perturbations, occlusions).
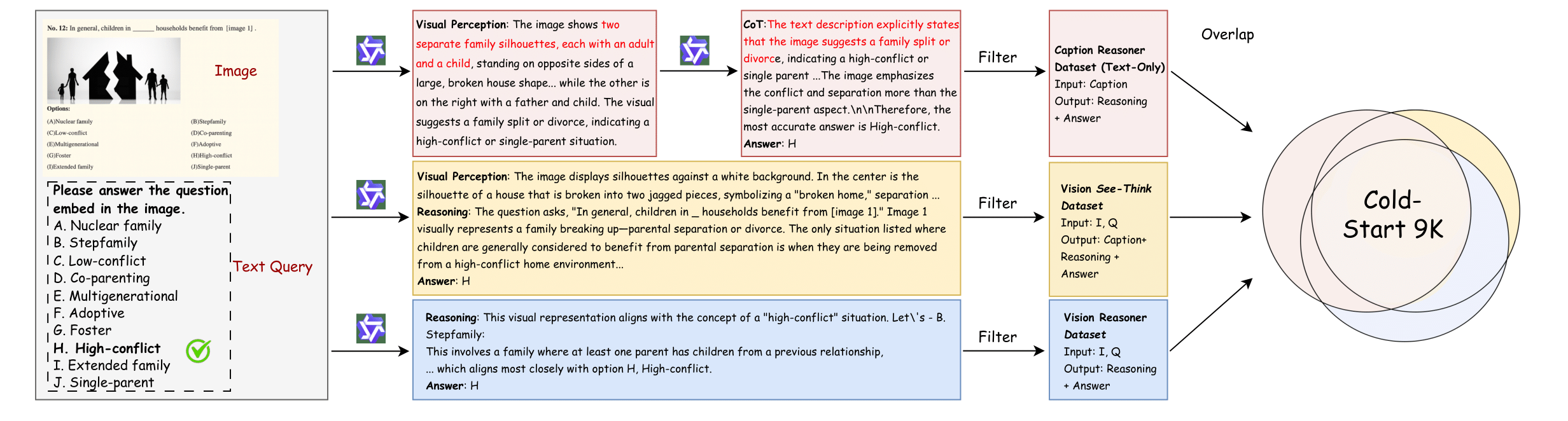
- Caption leakage and content constraints: The method does not prevent the “visual perception” from embedding computed answers, non-visual inferences, or shortcut hints. Develop automatic detectors and constrained-generation policies to ensure captions contain only visually observable facts (e.g., restricted vocabularies, regex checks, entailment filters).
- Sparse, binary visual reward: r_visual is a 0/1 signal tied to final correctness, offering no graded fidelity or partial credit. Explore denser rewards (entailment consistency, multi-QA probing of the same caption, cross-checks against region-wise evidence) to shape perception quality.
- Self-reward circularity mitigation: Using the same policy to score its own outputs can entrench biases. Test cross-model evaluators, ensembles, or adversarial judges; quantify calibration and robustness of self-reward under policy drift.
- Continued dependence on labeled answers: Despite “self-rewarding,” the pipeline requires ground-truth answers to compute both answer and visual rewards. Investigate weakly/unsupervised alternatives (e.g., multi-view consistency, cycle-consistency, synthetic counterfactuals, consensus across unlabeled variants).
- Evaluator and dataset bias: SFT data are generated/filtered by Qwen-2.5-VL; correctness for open-ended tasks is judged by Gemini-2.5-flash. Measure evaluator-induced variance, transfer bias, and reliability via human evaluation and multiple independent judges; report agreement and sensitivity.
- Generality across backbones/encoders: Results are limited to Qwen2.5-VL-3B/7B. Replicate on diverse VLM families (e.g., LLaVA, InternVL, MiniCPM, Flamingo) to assess portability and dependence on architecture/encoder choices.
- Missing training details and variance: Key RL settings (group size K, KL β, seeds, compute budget, rollout lengths) and variance across seeds are not reported. Provide sensitivity analyses, confidence intervals, and stability metrics to ensure reproducibility and robustness claims.
- Compute and scalability costs: The two-pass rollout increases training/inference cost; no profiling or sample-efficiency analysis is provided. Quantify overhead, throughput, memory footprint, and trade-offs vs. single-pass baselines.
- Task coverage gaps: Evaluation omits video, multi-image reasoning, localization/referring expressions, dense captioning, segmentation/box pointing, and grounding-heavy tasks. Extend to spatially grounded benchmarks to test true perception alignment.
- Limited hallucination assessment: Hallucination evaluation relies primarily on HallusionBench. Incorporate object-level and broader hallucination suites (e.g., POPE, Object HalBench), and measure groundedness (pointing/localization success) beyond binary QA.
- LSR metric validation: The proposed Language Shortcut Rate depends on Gemini judgments without human verification or cross-evaluator reliability studies. Formalize decision criteria, test consistency across judges, and correlate LSR with human ratings of shortcutting.
- Unquantified information loss: Converting images to text captions likely loses fine-grained spatial/texture/color cues. Quantify loss and compare text-only perception against embedding-level, scene-graph, or region-grounded representations on tasks requiring precise visual detail.
- Prompt/format sensitivity: The method relies on a tagged output structure, but there is no ablation on prompt wording, tag schema, caption length limits, or decoding strategies. Study how formatting choices impact reward accuracy and downstream performance.
- Out-of-distribution robustness: No tests on OOD settings (adversarial images, OCR noise, typography-heavy documents, diagrams with unusual styles, non-English text). Build OOD suites to stress perception robustness.
- Penalizing “correct answer, wrong perception”: Currently, incorrect perceptions leading to correct answers receive 0 visual reward but no explicit penalty. Evaluate adding negative rewards or margin penalties to actively discourage shortcutting.
- Theoretical guarantees: The mutual-information argument is qualitative. Provide formal analyses (e.g., bounds on I(A;I), convergence under decomposed rewards, bias under self-judging) and characterize failure modes of self-reward in multimodal RL.
- Baseline comparability: Perception-R1 and Visionary-R1 are not retrained on the same 47K dataset; results may be incomparable. Run matched-data baselines and report apples-to-apples comparisons.
- Train–test contamination auditing: The 47K RL corpus aggregates many public datasets; there is no formal audit of overlap with evaluation sets. Publish de-duplication scripts and hashes; verify zero leakage.
- Multilingual generalization: Experiments appear English-centric. Evaluate multilingual datasets (questions and embedded text) to test caption sufficiency and visual grounding across languages/scripts.
- Safety and privacy: Encouraging detailed perception captions may increase PII leakage or sensitive content exposure. Incorporate safety filters and measure PII leakage rates under the proposed training.
- Reward balancing and schedules: The weighting of format, answer, and visual rewards (α) is tuned empirically without schedule analysis. Study annealing strategies and balancing to prevent language-dominant optimization and maintain perception fidelity.
- Step-wise reasoning supervision: The approach does not reward intermediate reasoning steps t beyond the final correctness. Investigate step-level visual-grounded checks (e.g., verifying each step’s claims against the caption/image) to improve faithfulness.
- Spatial grounding verification: The current visual reward never checks that caption statements correspond to actual image regions. Add region-level pointing/selection tasks and image-conditioned verifiers for groundedness.
- Cross-modal consistency checks: No constraints ensure alignment between caption tokens and visual evidence. Explore attention-based or retrieval-based corroboration (e.g., CLIPScore with masked regions, contrastive checks) to substantiate claims.
- Continual-learning stability: Self-reward may drift as the policy evolves, causing instability or forgetting. Monitor stability over longer training, propose regularization (e.g., EMA teachers, replay buffers), and report long-horizon behavior.
- Public reproducibility artifacts: The code link lacks detailed configs, prompts, evaluator templates, and data curation scripts. Release these artifacts to enable exact replication and fair benchmarking.
Collections
Sign up for free to add this paper to one or more collections.

