Leveraging Verifier-Based Reinforcement Learning in Image Editing
Abstract: While Reinforcement Learning from Human Feedback (RLHF) has become a pivotal paradigm for text-to-image generation, its application to image editing remains largely unexplored. A key bottleneck is the lack of a robust general reward model for all editing tasks. Existing edit reward models usually give overall scores without detailed checks, ignoring different instruction requirements and causing biased rewards. To address this, we argue that the key is to move from a simple scorer to a reasoning verifier. We introduce Edit-R1, a framework that builds a chain-of-thought (CoT) verifier-based reasoning reward model (RRM) and then leverages it for downstream image editing. The Edit-RRM breaks instructions into distinct principles, evaluates the edited image against each principle, and aggregates these checks into an interpretable, fine-grained reward. To build such an RRM, we first apply supervised fine-tuning (SFT) as a ``cold-start'' to generate CoT reward trajectories. Then, we introduce Group Contrastive Preference Optimization (GCPO), a reinforcement learning algorithm that leverages human pairwise preference data to reinforce our pointwise RRM. After building the RRM, we use GRPO to train editing models with this non-differentiable yet powerful reward model. Extensive experiments demonstrate that our Edit-RRM surpasses powerful VLMs such as Seed-1.5-VL and Seed-1.6-VL as an editing-specific reward model, and we observe a clear scaling trend, with performance consistently improving from 3B to 7B parameters. Moreover, Edit-R1 delivers gains to editing models like FLUX.1-kontext, highlighting its effectiveness in enhancing image editing.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making computer tools better at editing photos the way people want. The authors build a smart “judge” that doesn’t just give a single score to an edited image, but first thinks through a checklist of what the edit should do, explains its reasoning, and then gives a fair, detailed score. They use this judge to teach image-editing models to follow instructions more accurately and keep images looking good.
What questions did the researchers ask?
They focused on two simple questions:
- How can we create a fair and reliable judge for image edits that checks exactly what the instructions ask for?
- How can we use that judge to train image-editing models so they follow instructions better without messing up parts of the image that should stay the same?
How did they do it?
The team’s key idea is to turn a “scorer” into a “verifier” — a judge that thinks step by step and checks specific rules.
Turning a judge into a verifier
Instead of asking “Is this edit good? Yes/No,” the verifier breaks the instruction into clear principles:
- Keep: what should stay the same in the image (for example, “don’t change the background”).
- Follow: what should be changed (for example, “make the shirt blue”).
- Quality: make sure the picture still looks natural and clean (no weird artifacts).
This is like a teacher grading a project with a checklist instead of just one overall grade. The verifier also “shows its work” (called Chain-of-Thought), explaining why each principle passes or fails before giving the final score.
Building the verifier in two stages
The researchers trained their verifier in two steps. Here’s a simple description:
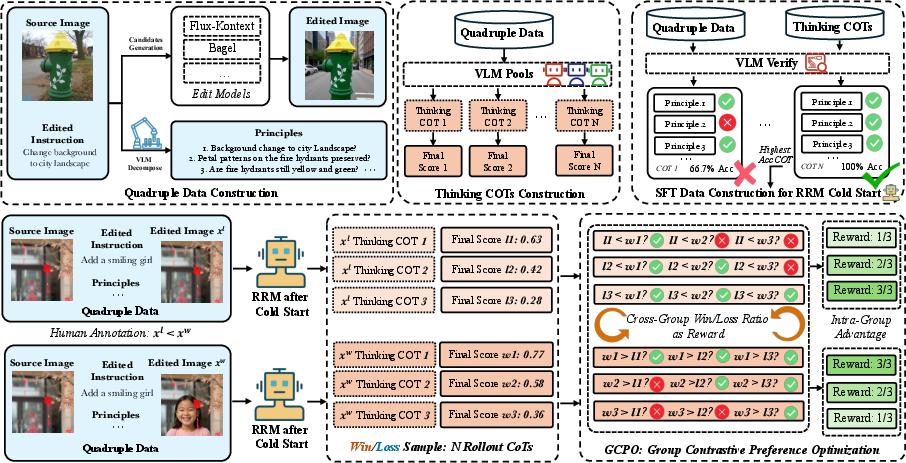
- Step 1: Cold Start with Supervised Learning
- They collected many examples of edited images, their original images, and the instruction used.
- Big vision-LLMs (like smart AIs that read and look) wrote down step-by-step thoughts and gave a score for each example.
- Another strong AI double-checked these thoughts to pick the most accurate ones. This created clean training data to teach the verifier to think and score well.
- Step 2: Improve with Preference-Based Reinforcement Learning (their new method called GCPO)
- Humans compared pairs of edited images and picked which one was better.
- For each pair (winner vs. loser), the verifier generated several different “think-and-score” attempts for both images.
- GCPO (Group Contrastive Preference Optimization) rewarded the verifier when its scores consistently put the winner above the loser across many comparisons. Think of it like a mini tournament: every “winner attempt” competes against every “loser attempt,” and the verifier learns to rank them correctly more often.
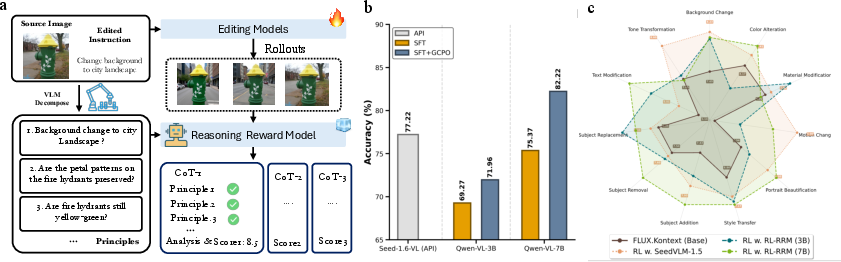
Teaching editing models with the verifier
Once the verifier was strong, they used it to train actual image-editing models. They used a training style called GRPO (a group-based reinforcement learning method):
- The editor makes several edited versions of the image.
- The verifier scores them using the checklist and reasoning.
- The editor learns to move toward the higher-scored edits next time.
This is like a coach (the verifier) giving consistent, detailed feedback so the player (the editor) improves.
What did they find, and why is it important?
They tested their approach in two ways: how good the verifier is at judging, and how much it helps real editors improve.
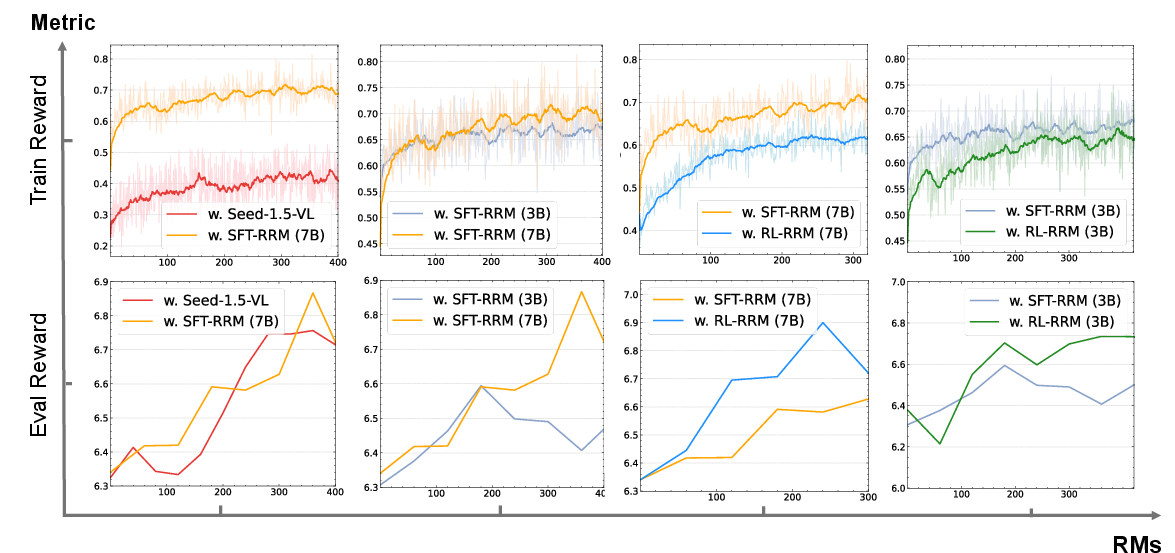
- The verifier became very accurate:
- Their best verifier (a 7B-parameter model, meaning a larger, stronger model) correctly matched human preferences about 82% of the time, beating other strong systems used as judges.
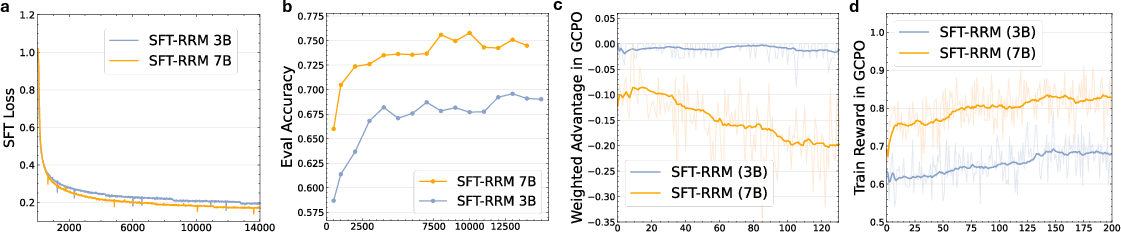
- It improved as it got bigger (from 3B to 7B), showing a clear scaling benefit.
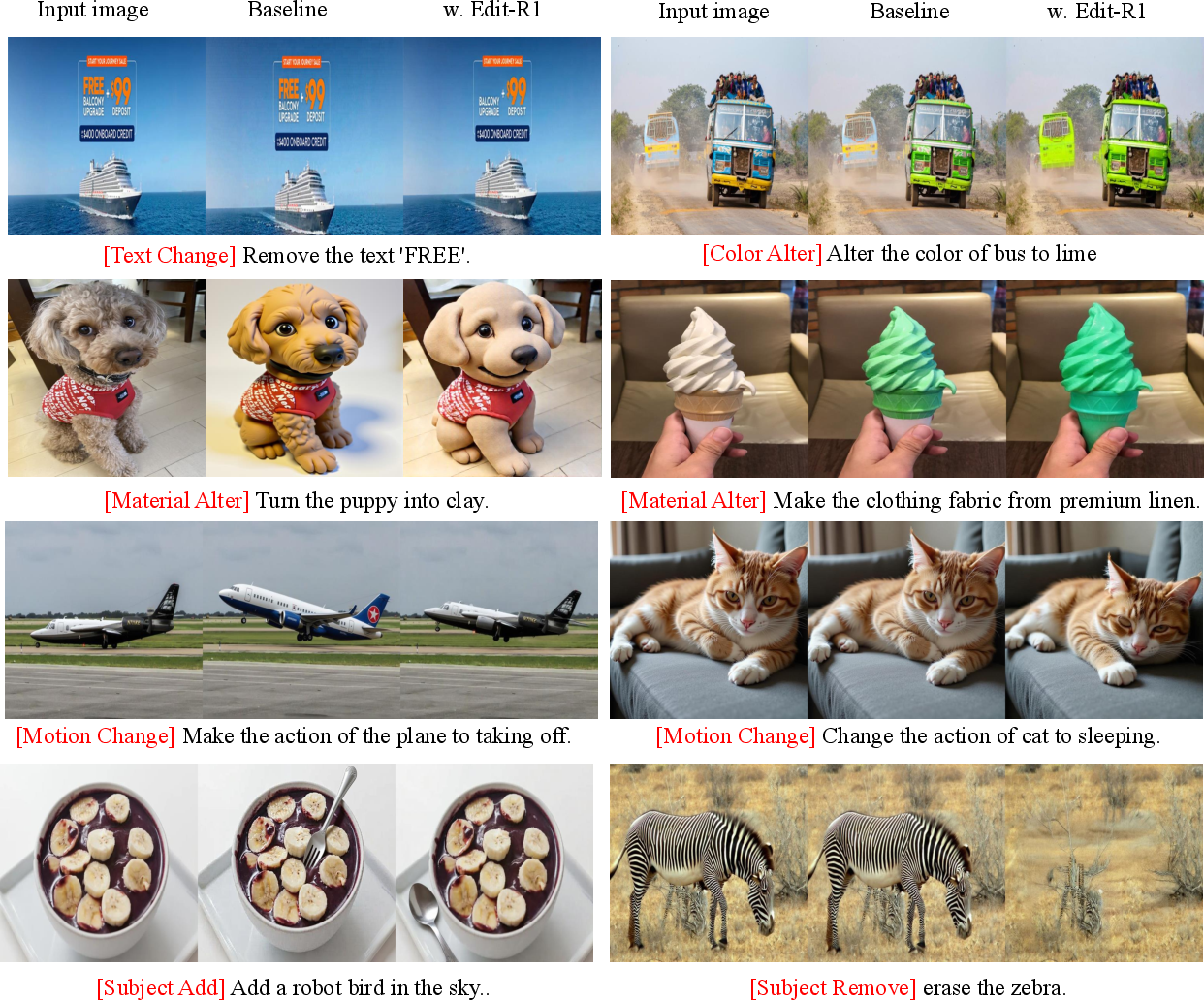
- It made editors better at following instructions:
- When used to train editors like FLUX.Kontext and Qwen-Image-Edit, the editors did a better job on:
- Following the requested change (semantic consistency),
- Keeping the rest of the image intact,
- Overall image quality.
- In tricky categories like “motion change,” one editor improved by about 15% relative to its original score—showing the verifier’s feedback helped most where edits are hardest.
Why this matters:
- Many older judges gave one overall score and could be biased or confused by complicated instructions.
- By using a checklist and showing its reasoning, this verifier gives clearer, fairer feedback. That makes training more stable and reduces the chance of “reward hacking” (where a model learns to trick the judge instead of truly improving).
What’s the bigger impact?
This work shows a better way to align AI image editors with what people actually want:
- Clearer feedback: Breaking instructions into Keep/Follow/Quality helps models improve the right things and avoid ruining unedited parts.
- Trust and transparency: The verifier explains its reasoning, so its scores are easier to understand and debug.
- Stronger training: The new GCPO method lets a reasoning judge learn from simple human preferences, and the GRPO setup uses that judge to make editors reliably better.
In short, this paper moves AI image editing closer to how a careful human would work: read the instructions, use a checklist, explain the decisions, and steadily improve with feedback. This can lead to smarter, more dependable photo-editing tools for creative work, design, and everyday image fixes.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- External-judge bias in SFT data curation: the “quality-control” step relies on Seed-1.5-VL; the extent to which this induces judge-specific biases or circularity (e.g., overfitting to Seed-VLM preferences) is not quantified. Evaluate multiple, diverse judges and report cross-judge stability.
- Principle generation dependency: it is unclear whether principles are always generated by the RRM at inference or require an external principle generator. Clarify and compare end-to-end (self-decompose) vs. externally provided principles at training and deployment.
- Fixed principle taxonomy: the Keep/Follow/Quality triplet may not cover important axes (e.g., identity preservation, safety, geometry/physics plausibility, lighting/photometric consistency, region-protection). Study expanded or adaptive principle sets and their impact.
- Principle weighting scheme: the “weighted aggregate” of principle checks is not fully specified or validated. Learn task-adaptive weights, report ablations on weighting strategies, and analyze trade-offs (e.g., fidelity vs. preservation).
- Prompt and CoT sensitivity: robustness to prompt phrasing, temperature, and CoT length is not analyzed. Measure sensitivity, standardize prompts, and regularize CoT length to avoid verbosity-induced scoring drift.
- Score parsing fragility: reliance on rule-based parsing of <score> … </score> can be brittle. Quantify failure modes and add formatting-robust extraction or constrained decoding.
- GCPO theoretical guarantees: convergence properties, bias/variance of the estimator, and robustness to noisy preferences are unaddressed. Provide theory, diagnostics, and comparisons to DPO/IPO/GRPO variants and listwise methods.
- Missing KL control in GCPO: the objective omits a KL term; implications for stability, overfitting to preferences, and distributional drift are not measured. Add KL regularization ablations and report stability metrics.
- Use of ties: “same” pairs are discarded both for training and evaluation. Develop tie-aware training (e.g., margin-based neutrality) and report calibration when preferences are ambiguous.
- Sample efficiency of GCPO: benefits are attributed to “better alignment” using ~10k pairs, but the dose–response curve (benefit vs. number/quality of pairs) is not studied. Provide scaling curves and active preference collection strategies.
- Reward hacking analysis: while RRMs are positioned as robust, no adversarial stress tests (e.g., exploiting known VLM blind spots, spurious textures, over-saturation) are reported. Add adversarial and distribution-shift evaluations.
- Generalization across editors: SFT data uses outputs from FLUX.Kontext, BAGEL, and SeedEdit; evaluation focuses on those families plus Qwen-Edit. Test generalization to unseen editing models and editing paradigms (e.g., mask-based, instruction-only).
- Distributional coverage: data and benchmarks are English-centric; multilingual instructions, domain-specific imagery (medical, diagrams, artworks), and low-resource domains are not evaluated. Extend to multilingual and domain-specific settings.
- Real-user edits and multi-turn sessions: the framework addresses single-turn edits. Assess performance on iterative, conversational edits with history, contradictions, or evolving constraints.
- Localization fidelity: verification of “unaltered regions” is handled via VLM reasoning, not pixel-level checks. Combine VLM judgments with perceptual/structural metrics and/or segmentation-based invariance tests.
- Motion/geometry magnitude assessment: the paper notes failures on small-magnitude edits; no principled metric for spatial displacement or geometric compliance is integrated. Add geometric verifiers (e.g., keypoint/pose/optical-flow surrogates).
- Safety and content policy: the RRM does not consider safety, fairness, or misuse (e.g., deceptive edits). Integrate safety principles and evaluate on safety-critical edits and fairness-sensitive content.
- Compute and latency: CoT verification per sample adds overhead; end-to-end training and inference costs are not reported. Quantify throughput, latency, and cost, and explore distillation or early-exit for practical deployment.
- Multi-objective balancing: downstream RL improves semantic consistency (SC) but can reduce perceptual quality (PQ) in places. Formulate multi-objective/granular rewards and report Pareto frontiers across SC, PQ, and preservation.
- Hyperparameter sensitivity: GRPO settings (group size G=24, β=0.04) and GCPO rollout counts (N) lack sensitivity analyses. Provide robustness sweeps and recommendations.
- Scaling limits: results stop at 7B; scaling laws or diminishing returns for larger RRMs are unknown. Report scaling trends (data, parameters, compute) and cost–performance trade-offs.
- Cross-benchmark robustness: internal benchmarks exclude “same” pairs; public results focus on EditRewardBench. Add broader, standardized editing benchmarks and report inter-annotator agreement and judge-identity effects.
- Principle correctness audits: generated principles may be infeasible or misaligned with the input image/instruction. Measure principle validity rates and introduce self-consistency or cross-checkers to filter invalid principles.
- Joint training dynamics: the RRM is fixed during policy optimization; co-training the editor and RRM (with safeguards) is unexplored. Investigate alternating or co-evolution schemes and their stability.
- Confidence calibration: the RRM emits a single score without uncertainty. Add calibrated confidence or interval estimates and use them in RL (e.g., risk-sensitive advantages).
- Robustness to image text and overlays: test whether textual overlays or watermarks spuriously influence the VLM-based verifier, and harden the RRM against such artifacts.
- Reproducibility details: exact datasets, data filtering thresholds, code for parsing/verification, and compute budgets are insufficiently specified. Release detailed protocols, prompts, judges, and seeds for reproducibility.
- Extension to video editing: the approach targets images; extending the verifier to temporal coherence, motion, and frame-level preservation is open. Design temporal principles and video-aware GCPO/GRPO.
- Category-specific gaps: despite gains in Motion Change, some categories show modest or inconsistent improvements. Perform per-category diagnostics and tailor principle sets/reward weights accordingly.
Practical Applications
Below are practical applications derived from the paper’s verifier-based reasoning reward model (Edit-RRM), the GCPO optimization algorithm, and the Edit-R1 training framework. Each item notes sectors, possible tools/workflows, and feasibility dependencies.
Immediate Applications
- Production-grade QA for image editing pipelines
- Sectors: software, creative/media, e-commerce, advertising
- What: Use the 7B Edit-RRM as an automated verifier to check instruction fidelity, preservation of unedited regions, and visual quality for every edit before delivery or publishing.
- Tools/workflows: “Edit-RRM API” microservice; CI/CD gate that rejects edits below a threshold; per-principle JSON pass/fail reports; dashboard for QC teams.
- Assumptions/dependencies: Access to the trained RRM; acceptable inference latency/cost; domain similarity to training data to maintain accuracy.
- RLHF post-training to upgrade existing editors
- Sectors: software, creative/media
- What: Apply GRPO with the Edit-RRM as a non-differentiable reward to fine-tune deployed editors (e.g., FLUX.Kontext, Qwen-Image-Edit) for higher semantic consistency and fewer artifacts.
- Tools/workflows: GRPO training plug-in; scheduled offline policy updates; evaluation harness with EditRewardBench and internal preference sets.
- Assumptions/dependencies: Sufficient GPU budget for group rollouts; safeguards against reward hacking; KL regularization to preserve style/brand identity.
- Interactive “principle checklist” guidance for creators
- Sectors: creative tools, education
- What: Surface the RRM’s principle decomposition (“Keep/Follow/Quality”) to guide users during editing; highlight unmet principles with concrete suggestions.
- Tools/workflows: Editor-side panel that renders per-principle verifications and localized comments; assistive prompts to fix failures.
- Assumptions/dependencies: UI integration; users comfortable with structured feedback; stable per-instruction principle extraction.
- Bulk e-commerce catalog edits with automatic verification
- Sectors: e-commerce, retail
- What: Automate background replacement, colorway changes, lighting/shadow adjustments at scale, and gate outputs with the RRM to ensure consistency and brand compliance.
- Tools/workflows: Batch edit service + RRM gating; deviation heatmaps; exception queues for human review.
- Assumptions/dependencies: SKU/domain adaptation if product categories differ from RRM’s training distribution; service-level latency constraints.
- Brand and legal compliance checks for visual content
- Sectors: advertising, policy/compliance, enterprise
- What: Use per-principle verification to confirm that logos, disclaimers, and protected regions are preserved while requested changes are applied; document audit trails.
- Tools/workflows: Compliance policy templates mapped to “Keep” principles; signed verification reports stored with the asset.
- Assumptions/dependencies: Accurate detection and principled parsing for brand elements; governance around thresholds and overrides.
- Privacy and redaction verification (PHI/PII removal)
- Sectors: healthcare (data ops), legal, public sector
- What: Validate that instructions like “blur faces,” “remove badge names,” or “mask license plates” have been fully executed without collateral edits.
- Tools/workflows: Redaction pipelines with RRM final gate; principle sets tuned to privacy rules; audit logs for compliance.
- Assumptions/dependencies: Domain shift (medical or surveillance imagery) may require light finetuning; failsafe human review for critical content.
- Standardized evaluation and benchmarking for academia/industry
- Sectors: academia, software
- What: Adopt Edit-RRM as a consistent, interpretable metric for model comparisons; use principle-wise scores to diagnose failure modes.
- Tools/workflows: Benchmark kits; leaderboards with per-principle breakdowns; ablation protocols.
- Assumptions/dependencies: Community agreement on metric thresholds; periodic revalidation with human studies.
- Preference data collection and curation accelerator
- Sectors: academia, ML platforms
- What: Use the paper’s “Think + Verify” pipeline and external VLM judges to auto-filter noisy CoT traces and steadily improve SFT data quality.
- Tools/workflows: Data curation tool that generates multiple CoTs per case and auto-selects the most verifiable trace; schema for quadruples (ref image, instruction, principles, edit).
- Assumptions/dependencies: Access to strong VLMs for initial filtering; storage/compliance for reasoning traces.
- In-product A/B testing and ranking of edited outputs
- Sectors: consumer apps, creative platforms
- What: Rank candidates from Best-of-N sampling using Edit-RRM as a per-image metric; ship higher-fidelity edits by default.
- Tools/workflows: Reranking service; “win rate” dashboards; tie-breakers with human-in-the-loop.
- Assumptions/dependencies: RRM generalizes to app’s content; careful monitoring to avoid regressions in style or diversity.
- Safety/guardrail enforcement for editing systems
- Sectors: software, policy/compliance
- What: Encode disallowed transformations (e.g., altering specific regions) as “Keep” principles and reject edits that violate them; curb destructive or misleading manipulations.
- Tools/workflows: Policy-to-principle compiler; override workflow with justification logging.
- Assumptions/dependencies: Clear policy definitions; precision in principle grounding; monitoring for false positives.
- Method transfer to other static visual tasks (immediate scope)
- Sectors: software, design
- What: Apply GCPO and pointwise verifier RMs to text-guided style transfer, inpainting/outpainting, or document layout edits.
- Tools/workflows: Minimal adaptation of principle schemas; GRPO training loops.
- Assumptions/dependencies: Similar supervision signals exist; modest domain-specific finetuning.
Long-Term Applications
- Video editing with verifier-based rewards
- Sectors: media/entertainment, advertising
- What: Extend Edit-RRM to video with temporal principles (temporal consistency, motion continuity, identity preservation) and reward editors with GRPO.
- Tools/workflows: Video-RRM with sequence-level CoT; clip-level QC dashboards; temporal anomaly alerts.
- Assumptions/dependencies: Scalable training data and compute; new benchmarks for temporal fidelity; efficient multi-frame inference.
- Generalist multimodal reward models for visual generation
- Sectors: software, research
- What: Unify reward modeling across T2I, editing, video, and 3D using principle-based CoT and GCPO to align with human preferences at scale.
- Tools/workflows: Cross-task principle ontologies; shared preference pools; unified evaluation suites.
- Assumptions/dependencies: Robust transfer across modalities; principled aggregation of heterogeneous criteria.
- Online preference learning (GCPO-in-the-loop) in products
- Sectors: consumer apps, creative platforms
- What: Continuously update the verifier using implicit user feedback (accept/reject, dwell time) and small curated preference pairs to stay aligned with tastes/brands.
- Tools/workflows: Live GCPO training jobs; drift detection; safety throttles for updates.
- Assumptions/dependencies: Consentful telemetry; bias and privacy controls; stable online learning practices.
- Assistive, voice-driven editing with verifiable guidance
- Sectors: accessibility, education, creative tools
- What: Build assistants that decompose natural-language commands into principles, propose concrete edit steps, and verify results live.
- Tools/workflows: Speech-to-principles module; corrective suggestions; “teach me why” explanations from CoT.
- Assumptions/dependencies: Fast, on-device or low-latency inference; robust speech grounding; UX research.
- Regulatory auditability for synthetic media pipelines
- Sectors: policy, public sector, enterprise compliance
- What: Provide machine-verifiable edit logs with per-principle verification to support disclosure, provenance, and risk assessments under regulatory frameworks.
- Tools/workflows: Immutable audit trails; provenance metadata (e.g., C2PA) coupled with RRM verdicts; third-party certification.
- Assumptions/dependencies: Standards adoption; legal acceptance of model-based verification as evidence.
- Safety and misuse detection
- Sectors: platforms, policy
- What: Combine principle checks with content classifiers to identify deceptive/manipulative edits (e.g., deepfake-like modifications to sensitive regions).
- Tools/workflows: Hybrid risk scores; human escalation queues; incident reporting.
- Assumptions/dependencies: Expanded “safety principle” ontologies; adversarial robustness testing.
- Domain-specialized RRMs (medical, remote sensing, industrial inspection)
- Sectors: healthcare (non-diagnostic data ops), geospatial, manufacturing
- What: Tailor principles to domain semantics (e.g., “preserve lesion region” overlays, “do not alter geospatial features,” “maintain defect masks”) to verify non-destructive edits.
- Tools/workflows: Expert-in-the-loop principle design; domain-specific preference sets; validation studies.
- Assumptions/dependencies: Careful scoping to non-diagnostic/non-deceptive use; regulatory review for critical domains.
- 3D content and NeRF/editing reward models
- Sectors: gaming, AR/VR, digital twins
- What: Extend principle-based verification to 3D scene edits (material swaps, geometry tweaks) with multi-view consistency checks.
- Tools/workflows: Multi-view RRM scoring; scene graph–aware principles; simulator-in-the-loop verification.
- Assumptions/dependencies: New datasets and render-time budgets; geometric reasoning extensions.
- Automated dataset synthesis and curation via verifier feedback
- Sectors: ML platforms, academia
- What: Use the RRM to grade and filter synthetic edits for training future editors, boosting data quality without heavy human labeling.
- Tools/workflows: Data flywheel with RRM-based acceptance; coverage analysis per principle/category; active-learning loops.
- Assumptions/dependencies: Avoid reinforcing RRM biases; periodic human audits.
- Enterprise-grade “EditOps” stacks
- Sectors: enterprise software, MLOps
- What: Full-stack orchestration for edit requests, model selection, RRM verification, human review, and release—analogous to DevOps for visual content.
- Tools/workflows: Policy-to-principle compilers; SLA monitors; cost/latency optimizers; versioned reward/model registries.
- Assumptions/dependencies: Organizational buy-in; integration with DAM/CMS systems; governance models.
- Research extensions: verifiable metrics standards and robust RM design
- Sectors: academia, standards bodies
- What: Formalize per-principle visual metrics, adversarial testing for reward hacking, and reproducible CoT verification schemes.
- Tools/workflows: Open testbeds; red-teaming protocols; shared “principle bank” datasets across institutions.
- Assumptions/dependencies: Community coordination; funding for long-horizon benchmarking.
Notes on cross-cutting feasibility
- Scaling and cost: CoT-based verification increases inference tokens; careful batching and caching help. Group rollouts for GRPO/GCPO impose compute requirements.
- Data alignment: For new domains, small preference sets (~10k pairs) can substantially improve alignment, but coverage and bias must be monitored.
- Robustness: Guard against reward hacking by mixing evaluators, adding human spot checks, and regularly revalidating with blind human studies.
- Governance: Store and secure reasoning traces; comply with privacy and IP policies; set clear acceptance thresholds and escalation paths.
Glossary
- Advantage: A normalized measure of how much better or worse a sample’s reward is relative to others in the same group, used to weight policy updates. "The advantage is computed within each preferred or non-preferred group."
- Best-of-N scaling: An inference strategy that selects the best result from multiple generated candidates to boost quality without changing training. "the baseline model already benefits from Best-of-N scaling"
- Chain-of-Thought (CoT): An explicit step-by-step reasoning process generated by a model before producing an answer or score. "builds a chain-of-thought (CoT) verifier-based reasoning reward model (RRM)"
- Clipped surrogate losses: PPO-style objective terms that clip policy update ratios to stabilize training and prevent overly large updates. "The objective function is the sum of the two groups' clipped surrogate losses, omitting the KL divergence term"
- Cold-start: An initial training phase using supervised data to bootstrap a model before reinforcement learning. "we first apply supervised fine-tuning (SFT) as a ``cold-start'' to generate CoT reward trajectories."
- Diffusion-based editors: Image editing systems built on diffusion generative models that iteratively denoise latent variables to produce edits. "to modern diffusion-based editors."
- Direct Preference Optimization (DPO): A preference-learning method that directly optimizes a model to prefer human-chosen outputs based on pairwise comparisons. "adopts Direct Preference Optimization (DPO) as their optimization method."
- Flow-based editing model: An image editor based on flow-based generative modeling, which transforms noise to images via invertible flows or learned ODEs. "the flow-based editing model"
- Flow-based generative models: Generative models that map simple distributions to complex data distributions through continuous or invertible flows. "diffusion and flow-based generative models"
- Flow-GRPO: A GRPO variant tailored to flow-based generative models for stable reinforcement learning in image generation/editing. "We adopt Flow-GRPO"
- Geometric mean: A multiplicative average used to combine metrics, emphasizing balanced performance across them. "overall score (O), computed as the geometric mean of SC and PQ."
- Group Contrastive Preference Optimization (GCPO): A reinforcement learning algorithm that contrasts groups of rollouts from preferred vs. non-preferred samples to optimize a pointwise reasoning model using pairwise data. "we introduce Group Contrastive Preference Optimization (GCPO), a reinforcement learning algorithm"
- Group Relative Policy Optimization (GRPO): A PPO-style reinforcement learning approach that normalizes rewards within groups of samples to compute advantages for stable updates. "We employ the GRPO algorithm"
- Hallucinated feedback: Incorrect or fabricated judgments produced by a model when evaluating outputs, leading to misleading signals. "leading to biased or hallucinated feedback"
- Holistic scorer: A reward model that outputs a single overall score without decomposing tasks into verifiable subcomponents. "treat the RM as a holistic scorer"
- Inference scaling: Improving performance by increasing compute at inference time (e.g., sampling more candidates) rather than changing training. "with inference scaling."
- Instruction fidelity: The degree to which an edited image adheres to the specified editing instruction. "assessing aspects like instruction fidelity, preservation of unedited regions, and overall quality."
- KL-divergence penalty term: A regularizer that constrains the learned policy to stay close to a reference policy by penalizing divergence. "and a KL-divergence penalty term to regularize the policy"
- Non-differentiable: A process that cannot be directly optimized via gradient backpropagation, often requiring black-box or RL methods. "non-differentiable yet powerful reward model."
- Pairwise preference data: Human annotations indicating which of two outputs is better, used to align models with human judgments. "leverages human pairwise preference data"
- Policy exploration: The process by which a learning algorithm tries diverse actions or outputs to discover better solutions. "restricts policy exploration"
- Pointwise: An evaluation or scoring scheme that assesses each candidate independently rather than via comparisons. "optimize a pointwise reasoning model with pairwise data"
- Preference pairs: Paired outputs labeled by humans as “winner” and “loser” for training preference-aware models. "human-annotated preference pairs"
- Principle decomposition: Breaking an instruction into smaller, verifiable principles (e.g., Keep, Follow, Quality) to structure evaluation. "enabled by principle decomposition and CoT"
- Reasoning Reward Model (RRM): A reward model that generates an explicit reasoning trace (e.g., CoT) before producing a final score. "Verifier-based Reasoning Reward Model (RRM)."
- Regression-based: A modeling paradigm where a network directly predicts scalar scores via a regression head. "regression-based"
- Reinforcement Learning from Human Feedback (RLHF): Training models using reward signals derived from human evaluations to better align with human preferences. "Reinforcement Learning from Human Feedback (RLHF) has become a core post-training step"
- REFL: A reinforcement learning method for diffusion models that optimizes policies against reward models, typically requiring differentiability. "utilize REFL for preference alignment"
- Reward hacking: Exploiting weaknesses in a reward model to attain high scores without genuinely improving the desired behavior. "REFL is often prone to severe reward hacking"
- Reward model (RM): A model that evaluates outputs (e.g., images) and assigns scores reflecting human preferences or task objectives. "lack of a robust general reward model"
- Semantic Consistency (SC): A metric assessing how well an edited image semantically follows the instruction. "semantic consistency (SC)"
- Supervised Fine-Tuning (SFT): Training a model on labeled data to improve its task performance before applying RL or other methods. "apply supervised fine-tuning (SFT)"
- Verifiable rewards: Rewards grounded in explicit, checkable criteria that reduce opportunities for reward hacking. "with verifiable rewards"
- Verifier: A model that checks adherence to decomposed principles and aggregates them into an interpretable reward. "Verifier as a reasoning reward model."
- Vision-LLM (VLM): A multimodal model that processes and reasons over both images and text. "using a general-purpose Vision LLM (VLM) to output a single, direct score"
- Win/loss ratio rewards: Rewards computed by comparing scores across groups (preferred vs. non-preferred) and measuring how often one group’s samples outrank the other’s. "We employ pairwise win/loss ratio rewards derived from cross-group preference comparisons."
- Weighted advantage: An advantage measure that accounts for factors like reasoning length when analyzing training dynamics. "The weighted advantage is defined as"
Collections
Sign up for free to add this paper to one or more collections.

