- The paper presents a novel RL training paradigm (BAPO) that integrates group-based reward assignment and dual-level adaptive modulation to enhance boundary recognition.
- Experimental results demonstrate up to a +15.8 point increase in reliability and proper alignment of IDK responses with unsolvable queries.
- The study shows that BAPO effectively prevents reward hacking and maintains accuracy with limited RL samples, offering safer deployment in high-risk applications.
Boundary-Aware Policy Optimization for Reliable Agentic Search: A Technical Analysis
Introduction
LLMs augmented with external search modules—referred to as agentic search models—have demonstrated remarkable gains in complex question answering (QA) by integrating multi-step reasoning, external retrieval, and autonomous planning. However, standard RL-based training in these frameworks is predominantly oriented toward maximizing correctness and accuracy, leading to a significant reduction in their ability to recognize and admit when an answer is beyond their knowledge or reasoning boundary. This limitation results in models often fabricating plausible but spurious answers, introducing reliability deficits in production use. The "BAPO: Boundary-Aware Policy Optimization for Reliable Agentic Search" (2601.11037) paper addresses this critical issue by proposing a novel RL training paradigm explicitly designed to endow LLM-based agentic search frameworks with boundary awareness, achieving a favorable balance between exploration, exploitation, and explicit handling of unanswerable queries.
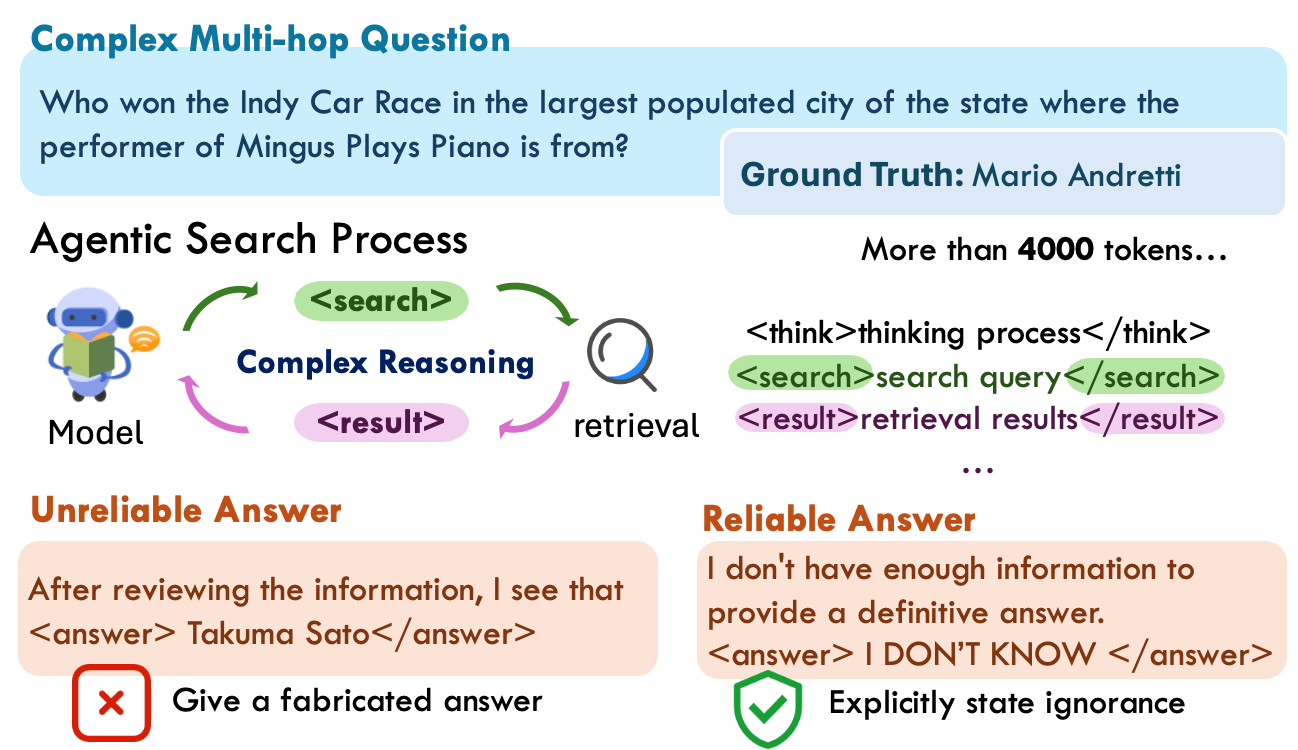
Figure 1: When the agentic search model produces wrong answers, its lengthy and complex reasoning makes it difficult for users to verify. To ensure reliability, the model should explicitly state when information is insufficient and that no answer is available.
Motivation and Empirical Observations
Empirical evidence establishes that RL-finetuned agentic search models (eg. ReSearch, Search-R1) exhibit sharply diminished "IDK" (I DON'T KNOW) response rates post RL. Precision and accuracy converge, with IDK response rates collapsing (e.g., a drop from ~19% pre-RL to ~4% post-RL; see Figure 2). Prompting for explicit admission of ignorance mitigates but does not solve this issue. Naively adding positive rewards for IDK introduces "reward hacking," where the model over-utilizes IDK to avoid errors, resulting in degraded accuracy and shallow exploration.
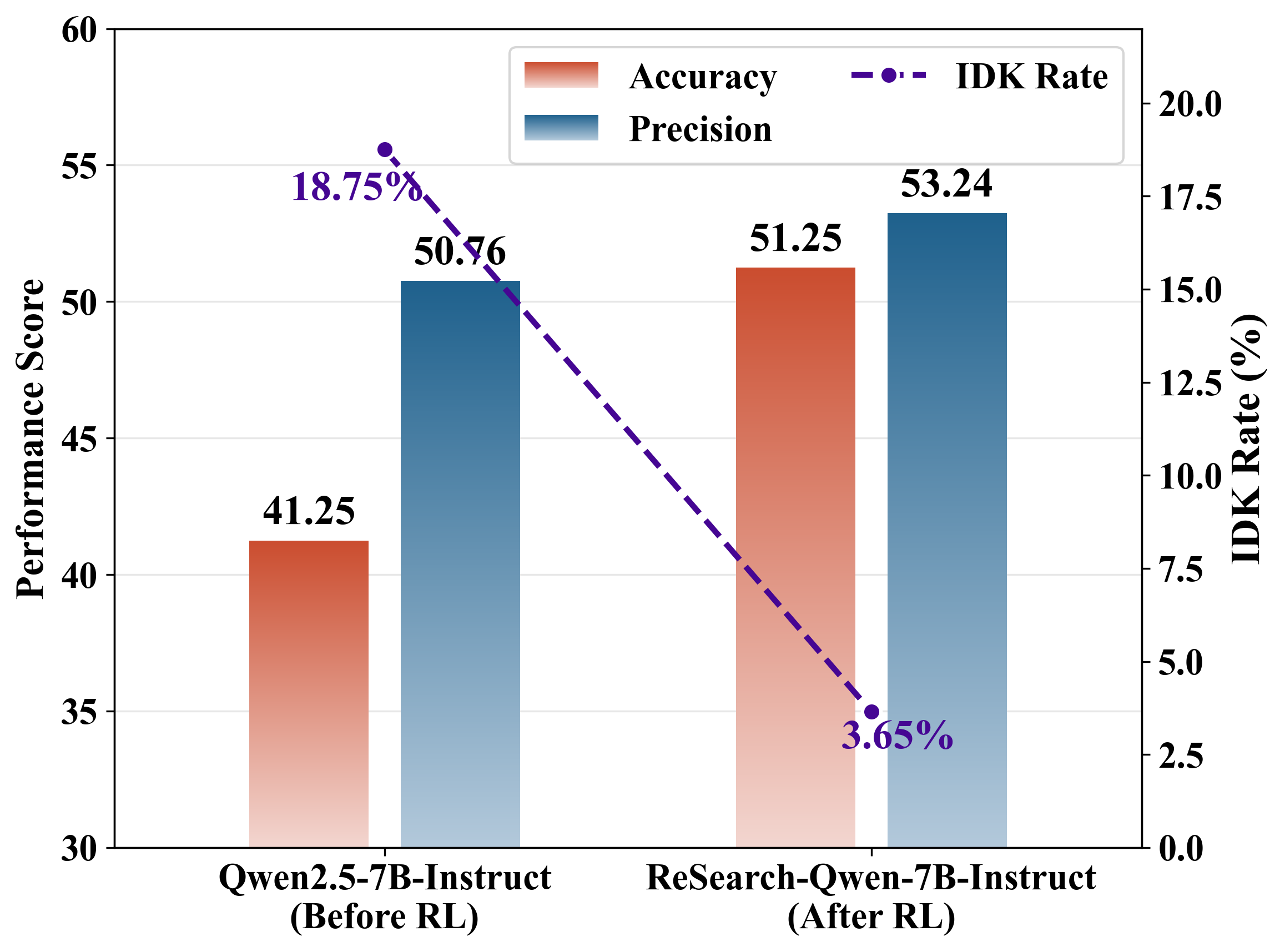
Figure 2: Evaluation results of accuracy, precision, and IDK rate (ρIDK)—sharp post-RL drop in ρIDK indicates weakened boundary awareness.
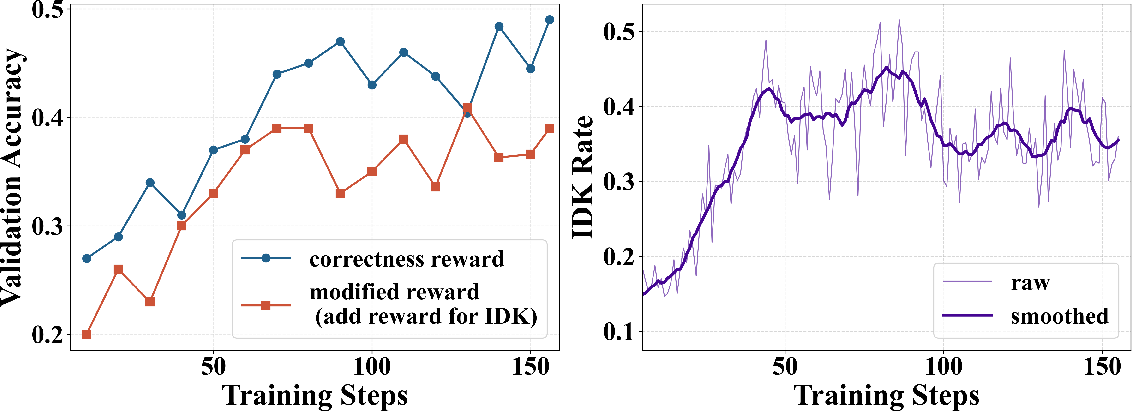
Figure 3: Left: Validation accuracy under different reward settings during RL training. Right: IDK rate (ρIDK) illustrating reward hacking.
BAPO: Boundary-Aware Policy Optimization
The BAPO framework introduces an RL training regime that addresses the boundary-awareness–accuracy tradeoff through two core innovations: (1) a group-based, context-sensitive boundary-aware reward assignment, and (2) a dual-level adaptive reward modulation mechanism.
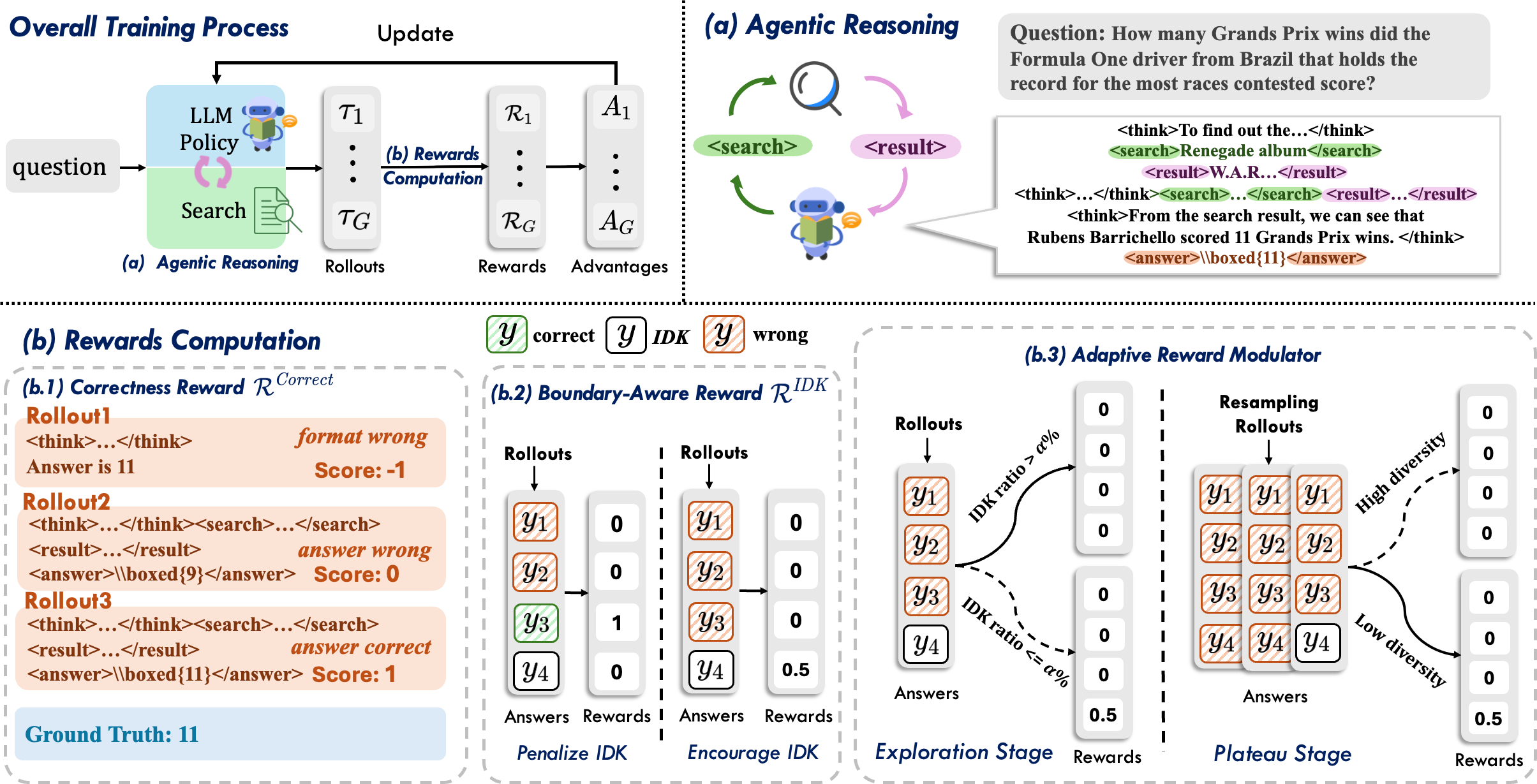
Figure 4: The BAPO training pipeline: (a) Agentic rollouts, (b) reward computation (correctness + adaptive boundary-aware), (c) modulator.
Group-Based Boundary-Aware Reward
BAPO formalizes reasoning boundary as the absence of any correct trajectory within a sampled group of rollouts for a query. If none of the group contains a correct answer, a moderated positive reward is assigned to those rollouts producing an explicit IDK response. This reward is strictly contingent—IDK is rewarded only when correctness is unattainable by search and reasoning, discouraging premature or lazy refusal.
Adaptive Reward Modulator
To avoid reward exploitation, BAPO controls the activation of the boundary-aware reward with two mechanisms:
- Stage-level modulation: During early RL stages, when accuracy is volatile and exploration is prioritized, the IDK reward is mostly deactivated. Only after accuracy plateaus is it activated, shifting training objectives to reliability.
- Sample-level modulation: For queries where the model’s output set is highly diverse (indicative of ongoing exploration), the IDK reward is suppressed. For those with low diversity (training-converged cases), the reward is issued.
This modulator ensures strong gradient signals for both answer discovery and calibrated refusal, preventing the model from early convergence to IDK or excessive "blind guessing."
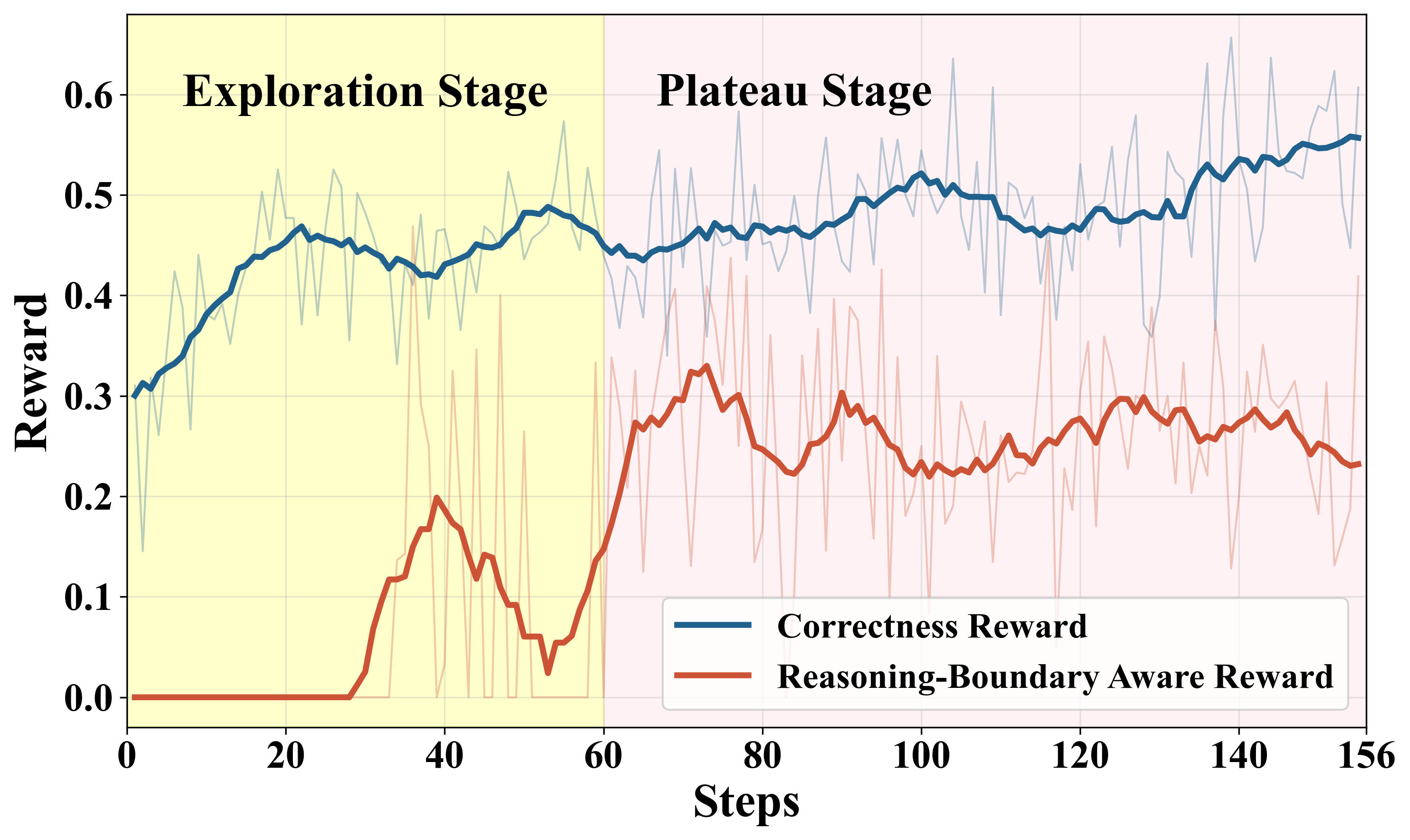
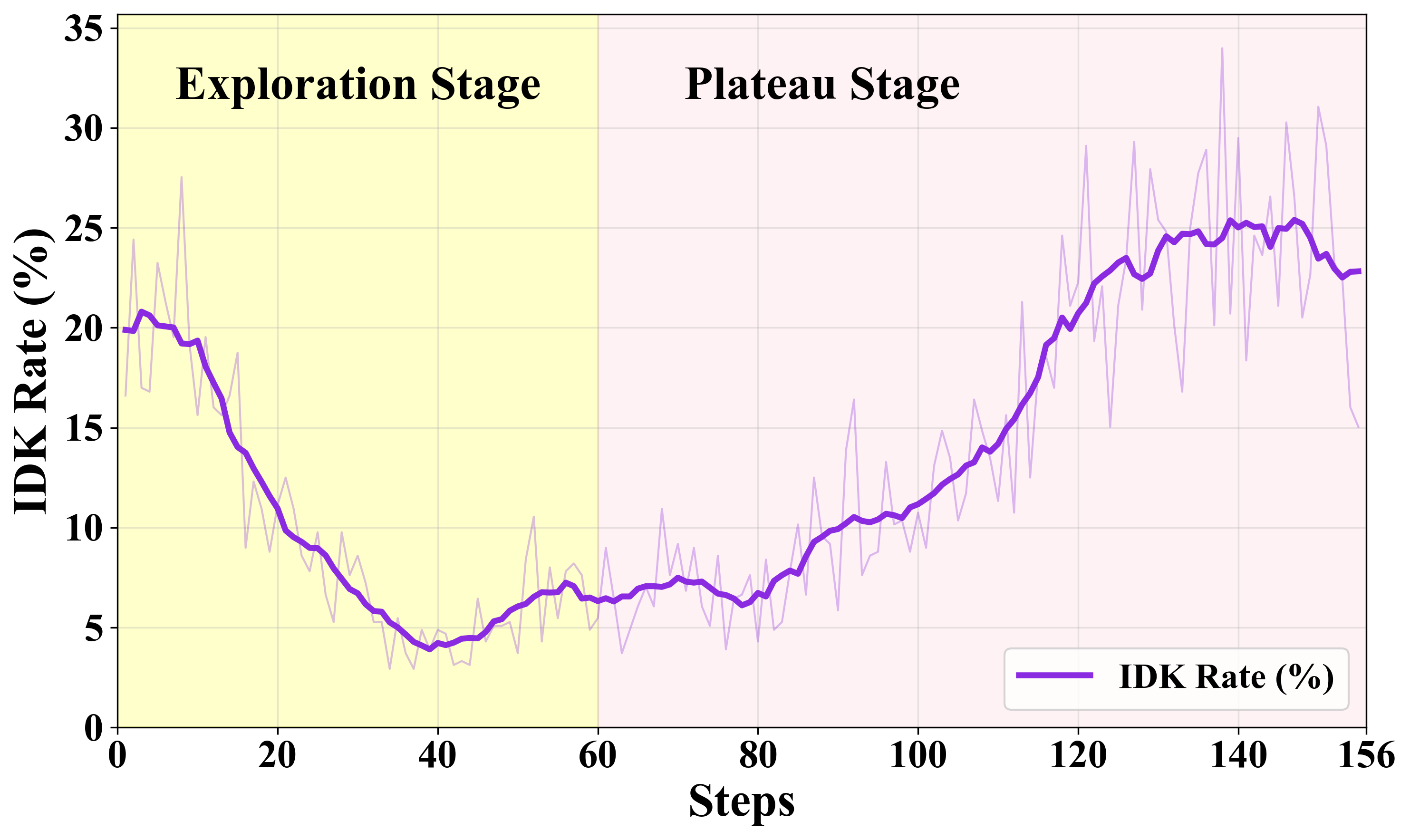
Figure 5: Upper: Temporal evolution of correctness and IDK rewards. Lower: IDK rate increases as boundary-awareness reward is engaged.
Experimental Results
BAPO demonstrates robust improvements on multi-hop QA benchmarks (HotpotQA, MuSiQue, 2WikiMultiHopQA, Bamboogle) across model scales (3B, 7B, 14B). Reliability, operationalized as a function of accuracy, precision, and IDK-rate, increases by up to +15.8 points relative to established RL and instruction-tuned baselines, and by +10% over GRPO, while only slightly reducing accuracy.
Key observations:
- BAPO-trained models achieve IDK rates aligned with true unsolvability (rejection success rate ~75%), and do not refuse solvable queries.
- Existing uncertainty calibration or test-time filtering methods (internal confidence, explicit expressions, self-reflection) substantially degrade accuracy or yield only minor reliability gains due to decoupling between internal uncertainty proxies and external information quality. BAPO circumvents this by explicitly modeling the interplay between retrieved context reachability and reasoning capacity.
- BAPO achieves comparable or superior reliability using only 5k RL training samples vs. the >90k in comparator models, highlighting efficiency.
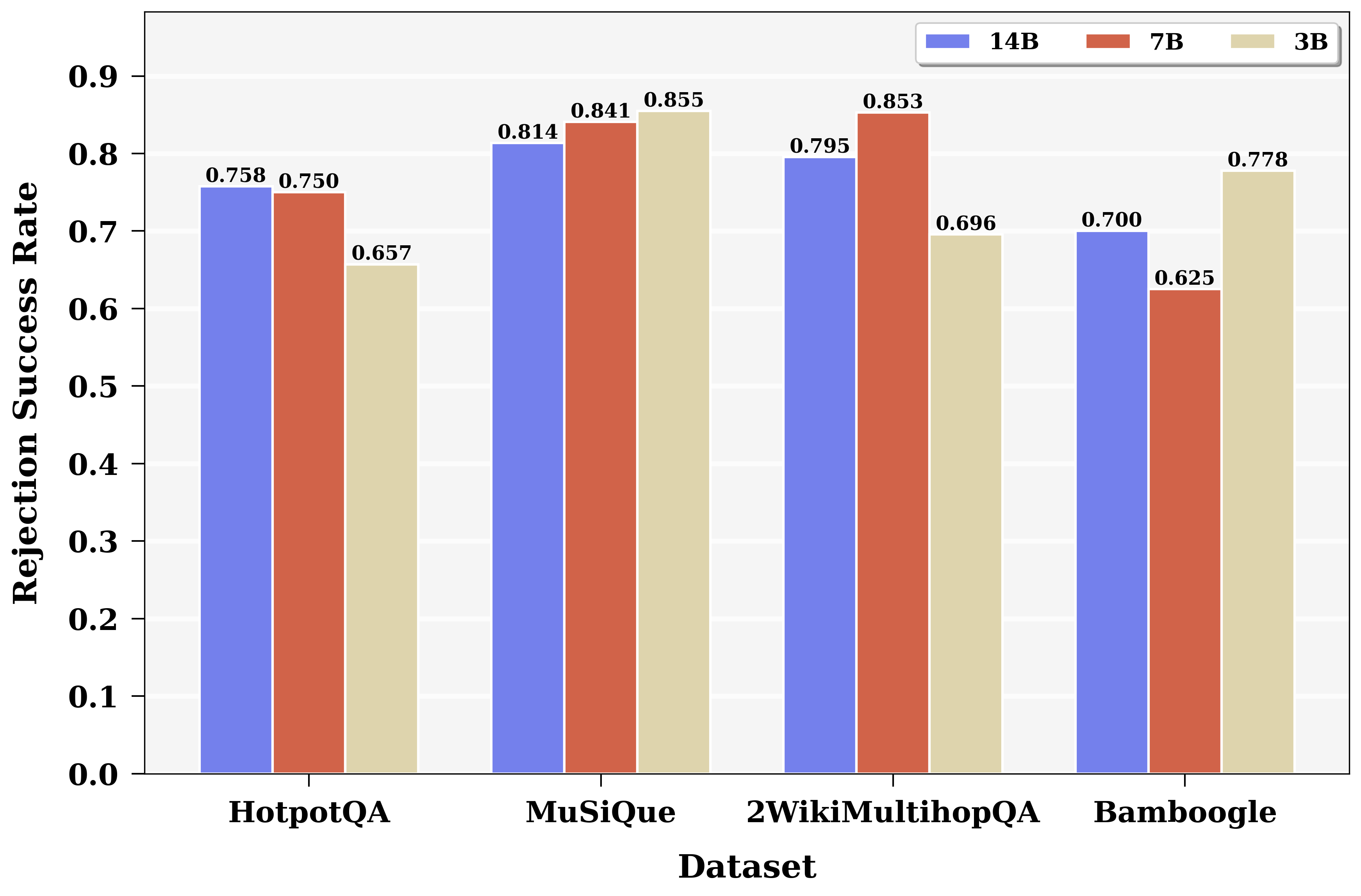
Figure 6: Rejection success rates for BAPO-trained models (3B, 7B, 14B), consistently above 74%.
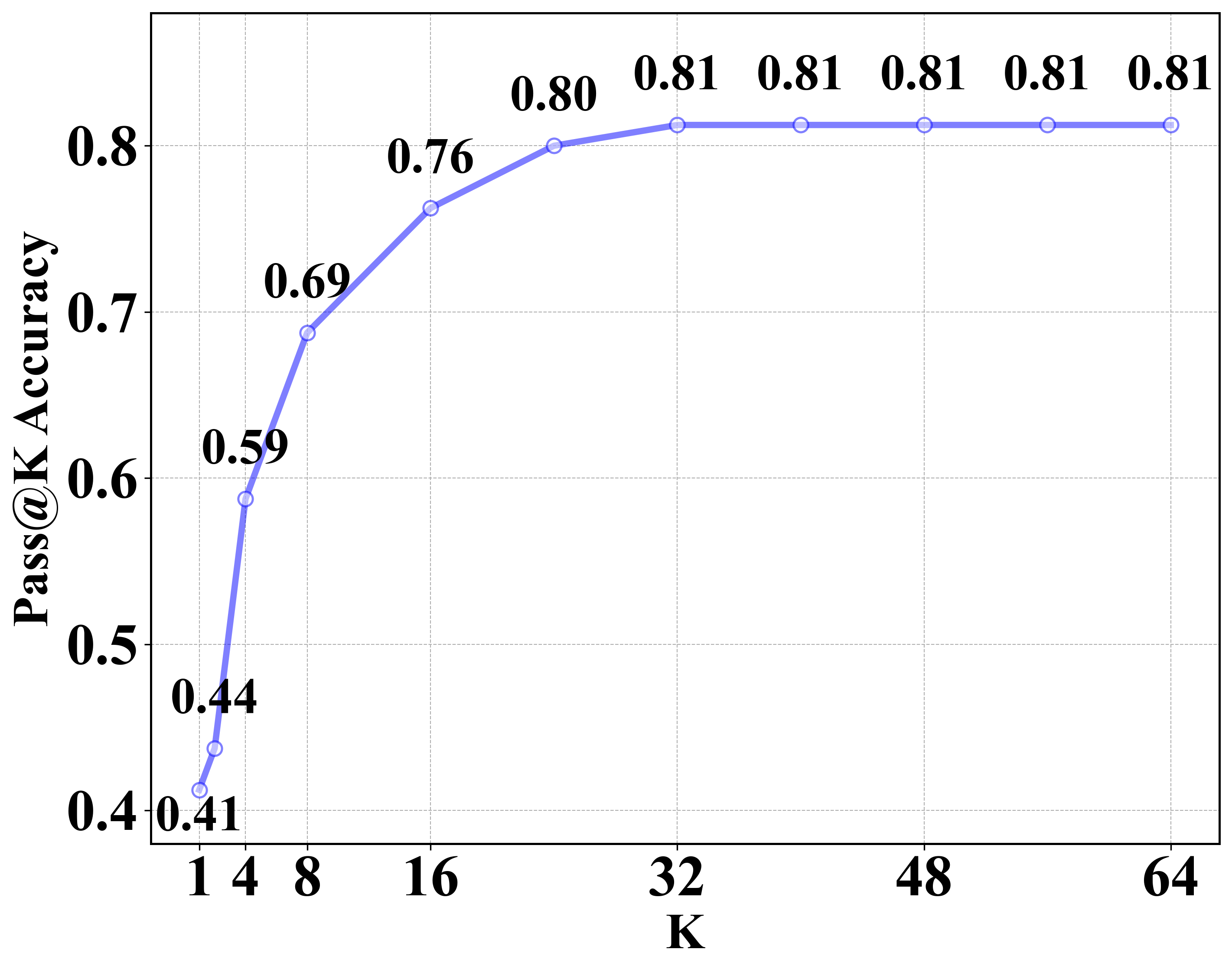
Figure 7: Effect of increased rollout (Pass@K) on accuracy. Performance plateaus after K=32, justifying dynamic resampling for boundary estimation.
Ablation and Analysis
Ablative evaluation confirms that the group-based reward and both modulation components are necessary. Removal/naive replacement—eg., static IDK reward—leads to reward hacking, high refusal rates, and substantial accuracy collapses. The dual modulator is essential to maintain the exploration–exploitation–boundary-awareness balance.

Figure 8: Confident and uncertain expressions lexicon used for uncertainty analysis.
Theoretical and Practical Implications
The BAPO framework clarifies that boundary-awareness cannot be trivially solved by post-hoc filtering, token-level calibration, or static reward engineering. Explicit reward design, tailored to the group-level structure and dynamically modulated through training phases and per-sample diversity, is essential to reliably induce "knowing-what-is-not-known" in agentic open-book QA agents.
Practically, models trained with BAPO are substantially safer in deployment, as they avoid undetected hallucinations and reliably surface unanswerable queries for escalation or alternate handling. Theoretical implications extend to other RL-finetuned agent frameworks, including tool-use and code/logic generation, where boundary-awareness is critical.
Limitations and Future Directions
BAPO’s evaluation is limited to knowledge-intensive QA and local RAG setups; its generalizability to creative tasks, dynamic web-retrieval scenarios, and very large model regimes (>14B) remains unproven. Future extensions could investigate more fine-grained reward stratification, synergy with advanced retrieval modules, or integration with model-internal uncertainty quantification.
Conclusion
BAPO provides a technically grounded solution to the problem of agentic search model unreliability and hallucination. By synergizing group-based, context-triggered rewards and adaptive modulation strategies, it aligns agentic search behavior with both accuracy and honest self-assessment of reasoning boundaries. The framework establishes practicable routes to high-reliability systems suited for real-world, high-risk deployment.