- The paper introduces RLDF for efficient reinforcement learning in diffusion language models by sampling denoising steps based on token-level uncertainty.
- RLDF employs a structured pipeline with weighted timestep sampling, clipped clean state prediction, and token-level normalization to stabilize training.
- Empirical results show that RLDF outperforms baselines on math reasoning and code generation tasks, enhancing in-domain and out-of-domain generalization.
Reinforcement Learning from Denoising Feedback in Diffusion LLMs
Introduction
Diffusion LLMs (DLMs) have recently emerged as powerful alternatives to autoregressive LLMs, leveraging bidirectional attention and iterative denoising for generative tasks. However, standard reinforcement learning (RL) algorithms—responsible for equipping autoregressive LLMs with advanced reasoning—cannot be directly transferred to DLMs due to fundamental differences in attention mechanics and sequence generation protocols. The paper "Reinforcement Learning from Denoising Feedback" (2605.25638) introduces RLDF, an efficient RL training paradigm tailored to DLMs, addressing challenges in policy loss estimation. The method strives for computationally tractable yet context-consistent policy gradient estimation, enabling stable and scalable RL training in DLMs.
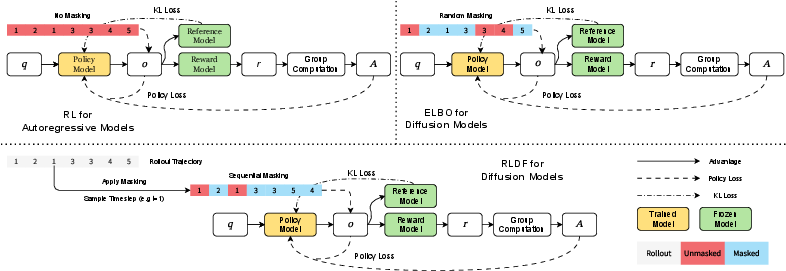
Figure 1: Comparison of RL for autoregressive models, ELBO-based RL for diffusion models, and RLDF sampling a timestep and applying sequential masks, estimating policy loss using πθ(x0∣xt).
Policy Loss Estimation in Diffusion LLMs
Policy loss estimation in DLMs is fundamentally hampered by the bidirectional attention and non-causal sequence generation. Unlike single-pass log-likelihood in autoregressive LLMs, DLMs require iterative denoising from fully masked input to clean sequence, inducing variable contextualization at every timestep. Prior loss estimation schemes (no-masking, random-masking, ELBO) invariably suffer from a mismatch between training and inference context, negatively impacting gradient fidelity and model generalization.
RLDF addresses this challenge by estimating policy loss specifically at those denoising steps with high predictive uncertainty, using both rollout and training feedback to select informative positions for update. Crucially, RLDF employs weighted sampling over denoising steps with sampling weight derived from token-level uncertainty (entropy), thus concentrating computational resources where they yield maximum impact.
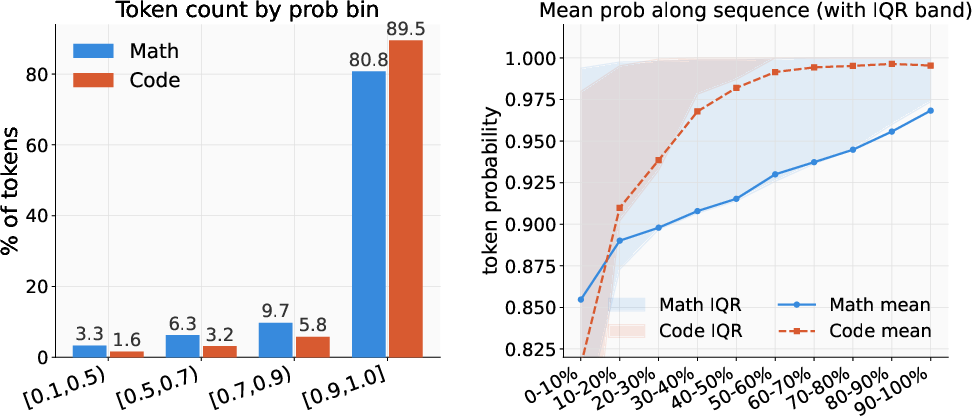
Figure 2: Token probability distributions across Math and Code tasks. Tokens unmasked at later steps exhibit higher confidence and lower variance. Over 80% of tokens are unmasked with high probability (p≥0.9).
RLDF Training Pipeline
The RLDF pipeline consists of four stages:
- Rollout and Denoising Trajectory Recording: Model responses are generated via the sequential denoising process, recording token probabilities and denoising trajectories.
- Weighted Timestep Sampling: A subset of denoising timesteps is selected based on token-level uncertainty; steps with lower average confidence receive greater sampling weight.
- Clipped Clean State Loss Estimation: Loss is computed by conditioning on intermediate noisy state and predicting clipped clean tokens at sampled timesteps. Tokens below a probability threshold are discarded to improve signal-to-noise ratio.
- Policy and KL Regularization Aggregation: PPO clipping and unbiased KL-divergence estimator are used to penalize deviation from a reference model and stabilize optimization.
This structured pipeline yields loss estimates faithful to inference context, avoids computational explosion, and improves policy gradient estimation precision.
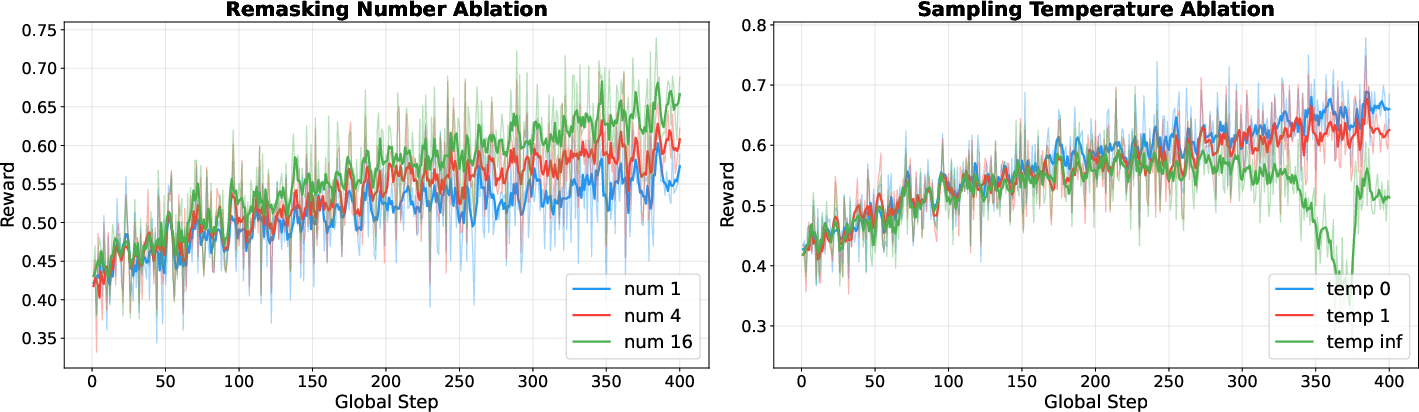
Figure 3: Ablation on sequential remasking strategy. Increasing remasking counts and reducing sampling temperature boost mean rollout reward.
Empirical Evaluation
RLDF is evaluated on mathematical reasoning and code generation benchmarks (MATH500, GSM8K, AMC23, MBPP, HumanEval) using LLaDA-8B-Instruct and Dream-7B-Instruct as backbone DLMs. Models are trained using only RLDF, starting from pretrained diffusion weights. Cross-dataset evaluation and robustness testing (varying generation length, static vs. dynamic unmasking) verify generalizability.
Key findings:
- RLDF consistently outperforms baselines (d1, ESPO, TraceRL, Coupled-GRPO) in task accuracy on both code and math reasoning, under both dynamic and static unmasking strategies.
- The Dream model exhibits particularly rapid convergence with RLDF, attributed to latent capabilities reactivated from AR-to-diffusion adaptation.
- RLDF demonstrates superior out-of-domain generalization, notably bridging MBPP-HumanEval distribution shift.
Design Choices and Ablation Studies
Sampling Strategy and Temperature
Higher sampling counts accelerate convergence but increase iteration time. Lower sampling temperatures stabilize training by focusing updates on high-uncertainty steps, mitigating noise-dominated gradients.
Clean State vs. Next State Estimation
Loss estimation using the clean state (x0) is theoretically and empirically superior to next state (xt−1) estimation. Clean state prediction leverages a larger proportion of tokens per sample, yielding richer training signals and stable KL regularization dynamics, as loss spikes are avoided.
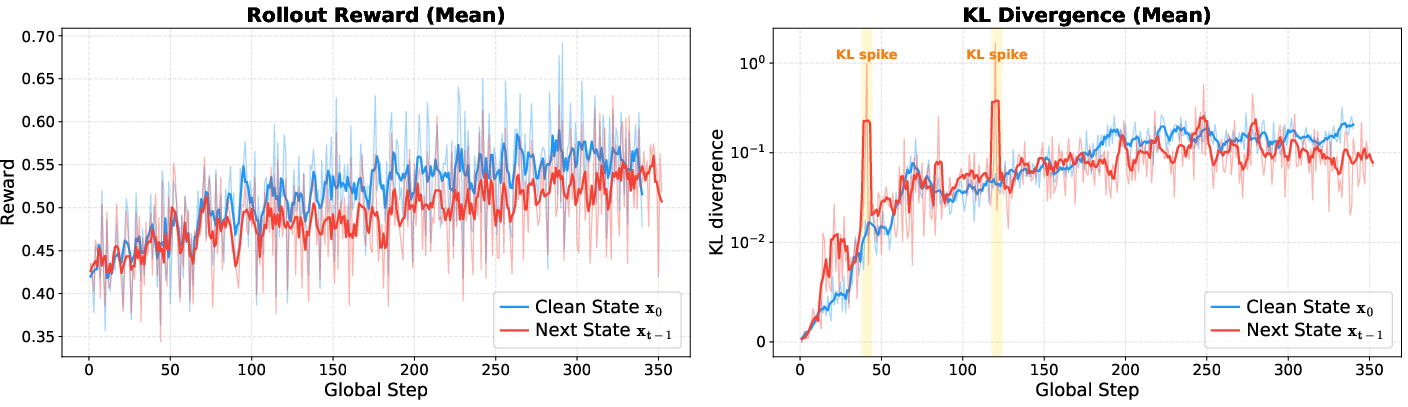
Figure 4: Clean state estimation yields more stable training than next state estimation, evidenced by improved rollout reward and smoother KL loss.
Loss Normalization
Token-level normalization produces more stable convergence than sample-level normalization, reducing loss spikes and improving the utilization of gradient signal.
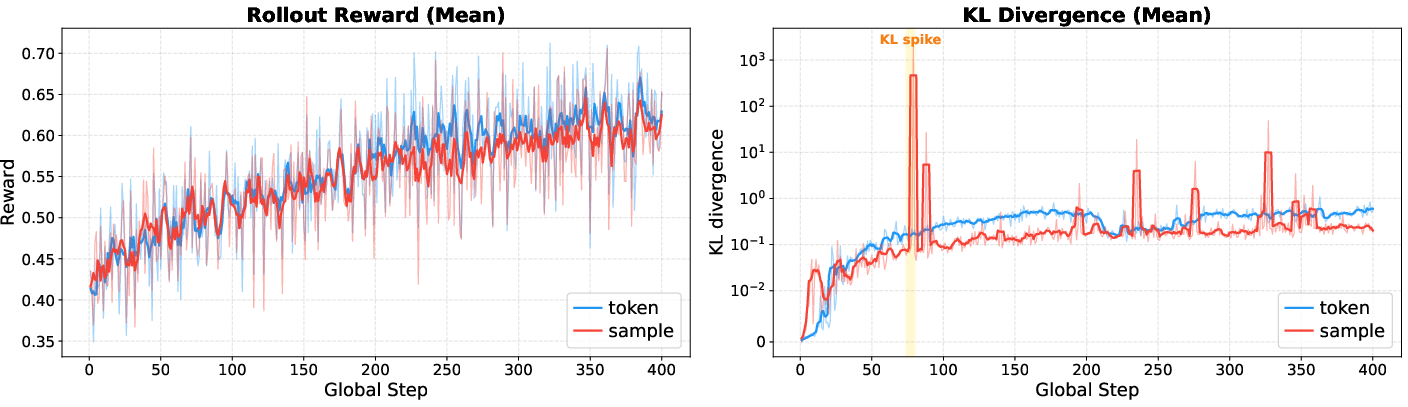
Figure 5: Token-level normalization leads to a more stable training process, with fewer loss spikes and faster convergence.
Token Clipping
Tokens with low prediction confidence are clipped during loss computation, effectively rejecting unreliable signals and preventing divergence in gradient norm and loss. Clipping is essential for maintaining stable RL training in diffusion models.
Practical and Theoretical Implications
RLDF demonstrates that scalable RL for DLMs is achievable via selective stepwise loss estimation and context-aligned objectives, unlocking the reasoning potential of models like Dream and LLaDA. Empirical gains span both in-distribution and out-of-distribution domains. The methodological contributions—weighted timestep sampling, clipped clean state prediction, and token-level loss normalization—provide a principled foundation for future RL algorithms targeting DLMs.
Practically, RLDF enables DLMs to approach or exceed autoregressive LLMs on complex reasoning and code tasks, maintaining efficiency and scalability. Theoretically, RLDF regularizes the inherent train-inference mismatch in DLM pipelines, laying groundwork for new RL objectives and efficient model architectures.
Future Directions
Potential directions include:
- Extending RLDF to multimodal DLMs.
- Investigating diffusion-native reward shaping for complex tasks.
- Scaling RLDF to increasingly larger DLMs and broader benchmarks.
- Hybridizing AR and DLM mechanisms for further efficiency gains.
Conclusion
RLDF provides a robust RL framework for diffusion LLMs, resolving policy loss estimation bottlenecks and enabling competitive reasoning and code generation capabilities. Its principled sampling and loss computation strategies support generalizability and efficiency. The community-centric Drift framework operationalizes these advancements for broader research adoption. RLDF is poised to inform future RL algorithms and architectures in the diffusion modeling landscape.