Emu3.5: Native Multimodal Models are World Learners
Abstract: We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
First 10 authors:









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Emu3.5, a very large AI model that can understand and create both pictures and text together, like telling a story with images and words. The big idea is to train one model to predict “what comes next” across time for both language and visuals—like guessing the next word in a sentence and the next frame in a video—so it can learn how the world changes and how to describe it.
What questions were the researchers trying to answer?
- Can one model learn from long videos (not just short clips) that mix images and speech/text, and then generate new, consistent picture-and-text stories over time?
- Can such a model act as a “world model,” meaning it can imagine and keep track of people, places, and objects as they move and change?
- Can it also edit or create images on demand (like turning a rough idea or multiple input images into a new picture) while staying fast and high-quality?
- Can we make this kind of model run much faster without losing quality?
How did they build and train Emu3.5?
Think of Emu3.5 as a very big “sequence guesser.” A sequence is just a long line of small pieces called tokens. Tokens can be words or tiny chunks of an image. The model learns to predict the next token—like finishing a sentence or completing the next piece of a picture.
Here’s the approach in everyday terms:
- Learning from long videos and text: The team trained the model on a huge amount of internet videos and their transcripts (speech turned into text). Instead of random single images, they used sequences of frames plus the words people spoke. This helps the model learn how scenes and stories flow over time.
- One unified goal: The model always does the same simple task—predict the next token—whether the token is a word or part of an image. This “one rule for everything” keeps training simple while covering many skills.
- Turning images into tokens: Images are broken into small, discrete “visual tokens” (like LEGO bricks). This lets the model treat pictures and text in a similar way.
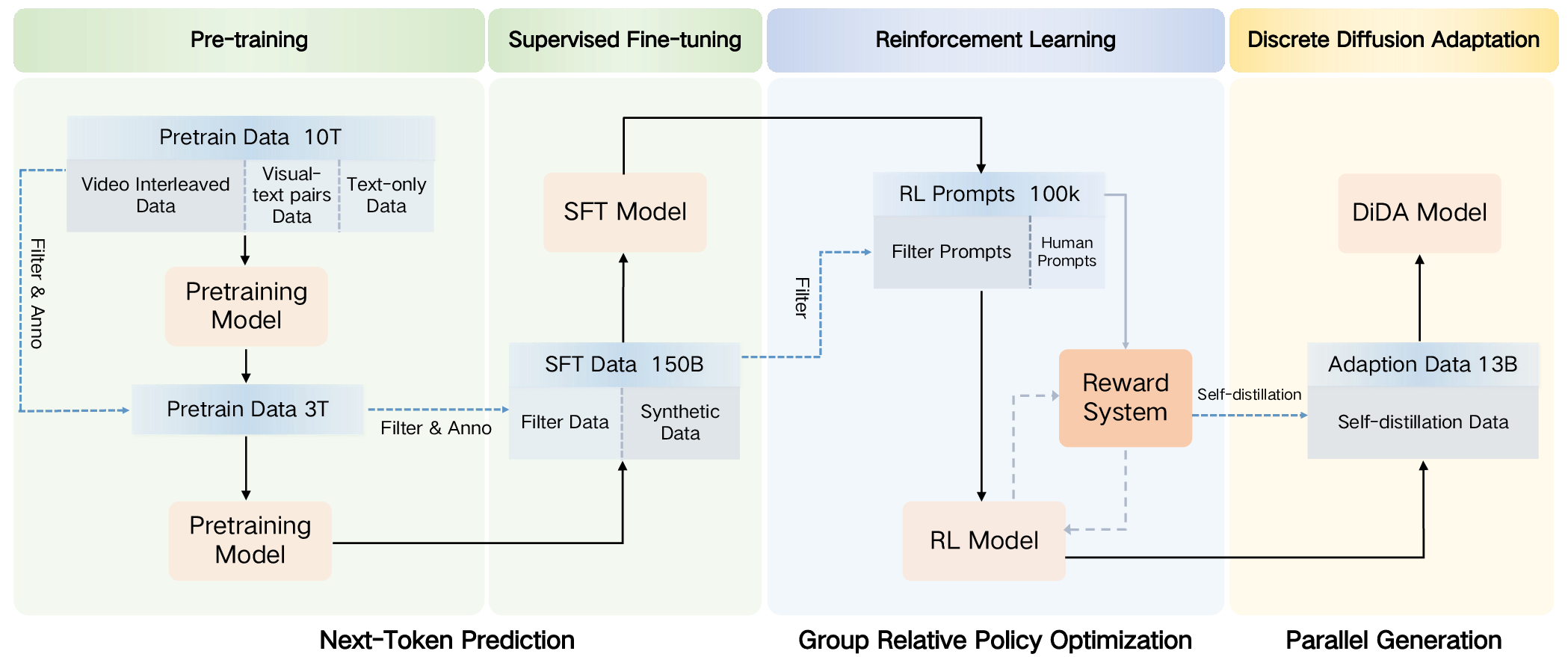
- Two big training phases:
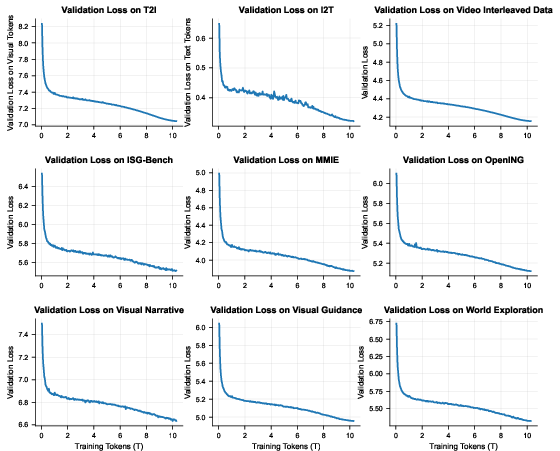
- Pre-training: The model read about 10–13 trillion tokens of mixed video frames and text (plus extra image–text pairs and text-only data). This is like a massive warm-up where it learns general patterns.
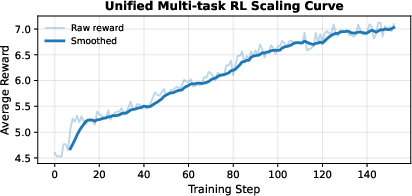
- Post-training: First, supervised fine-tuning (learning from curated examples of the tasks they want). Then reinforcement learning, which is like practicing with a score—good outputs get rewarded so the model learns what people prefer.
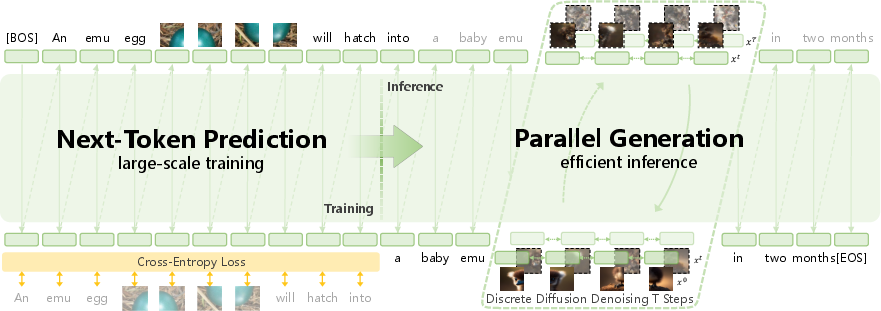
- Speed-up trick (DiDA): Normal text models generate one token at a time, which is slow for images because there are many visual tokens. The team introduced Discrete Diffusion Adaptation (DiDA), which lets the model predict many visual tokens in parallel, from both directions, like filling in a puzzle faster. This makes per-image generation about 20× faster without losing quality.
Helpful analogies for key terms:
- “Next-token prediction”: Like texting with autocomplete—guessing the next word, but also the next piece of a picture.
- “World model”: Like a smart game engine in the model’s head that keeps track of characters, objects, and scenes over time.
- “Reinforcement learning”: Practicing with feedback—do better next time to get a higher score.
- “Discrete diffusion (DiDA)”: Instead of placing one puzzle piece at a time, you rapidly refine the whole picture in parallel.
What did they find, and why does it matter?
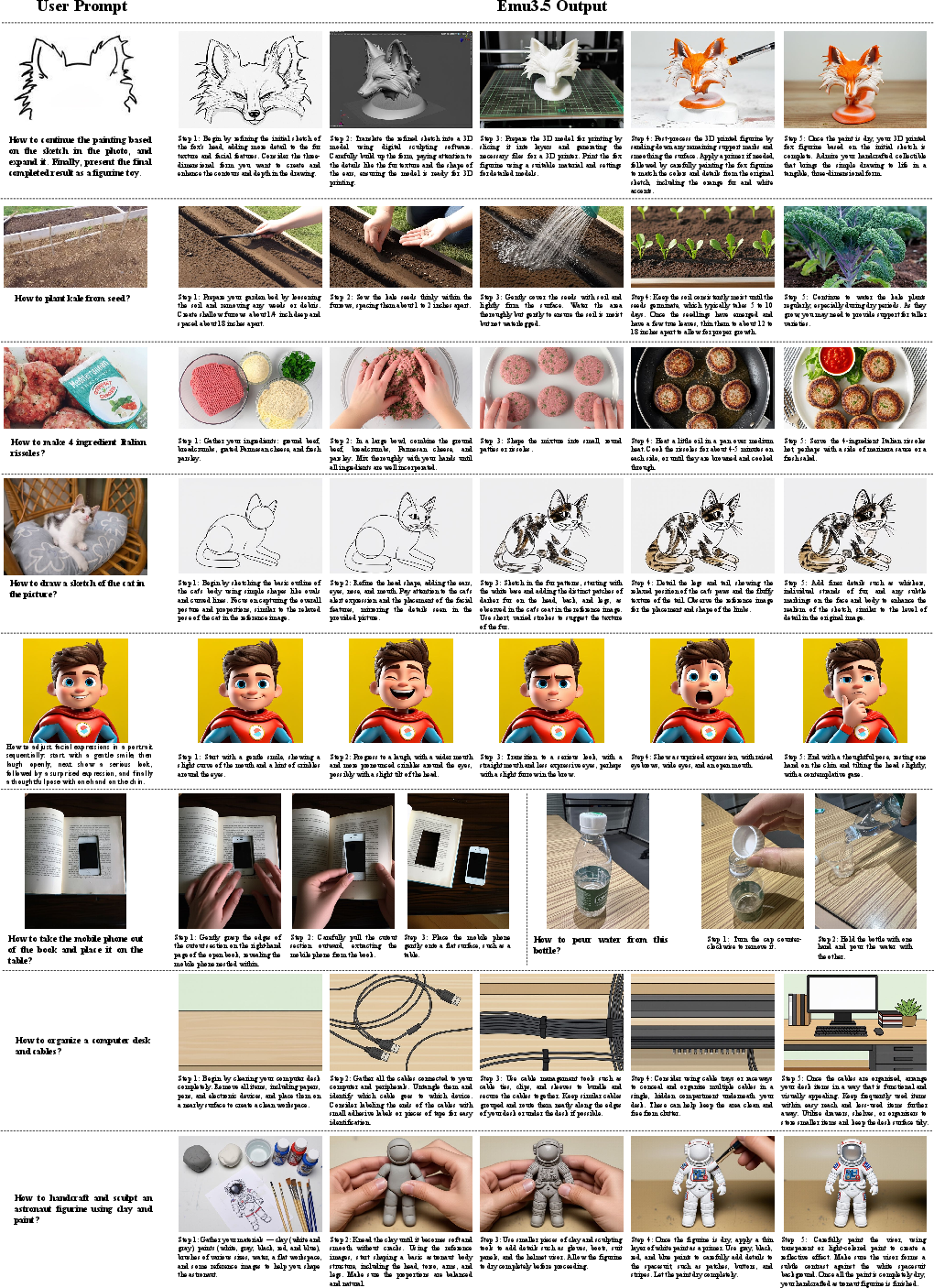
Emu3.5 shows strong abilities that matter in real use:
- Long, mixed stories: It can generate long, consistent sequences that interleave text and images—good for visual storytelling, step-by-step guides, and explanations that unfold over time.
- Any-to-image (X2I) editing and creation: It can take different kinds of inputs (text, images, or both) and produce a new, edited image with fine control (e.g., keep a character’s look consistent, adjust scenes, add readable text).
- Text-rich images: It renders text inside images accurately (like signs, labels, posters), which is usually hard.
- World modeling: It can keep track of space and time, supporting:
- World exploration: Build and “walk through” imagined or real-like environments while describing them.
- Embodied manipulation: Sketch out step-by-step plans and key frames for tasks like cooking or assembling—capturing the important moments rather than every tiny motion.
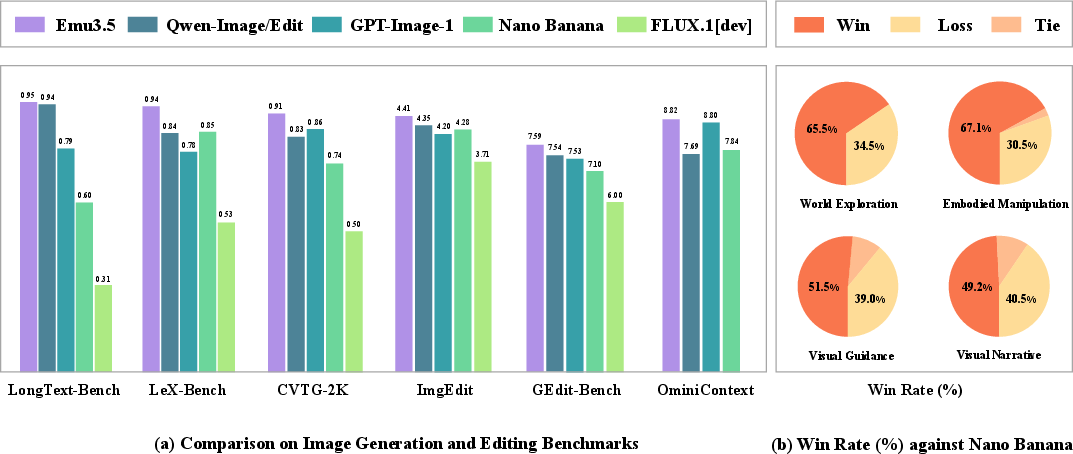
- Competitive performance: On image generation and editing, Emu3.5 performs similarly to a strong closed model (Gemini 2.5 Flash Image), and it does even better on complex “interleaved” generation tasks that mix images and text over time.
- Much faster inference: With DiDA, image generation gets around 20× faster without losing quality—important for real apps.
Why this matters:
- Learning from long video-text sequences teaches the model not just “what things look like” but “how things change,” making it better at planning, narrating, and staying consistent.
- A single, unified model that can read, see, and create both images and text is more flexible and can transfer skills across tasks (for example, improvements in image editing help its storytelling ability).
What could this change in the future?
- Education and guides: Clear, step-by-step visual explanations for how to do things (science labs, repairs, recipes), with both pictures and text generated on the fly.
- Creative tools: Faster, controllable image creation and editing for comics, design, posters, and storyboards, with consistent characters and styles across many scenes.
- Robotics and simulation: Better “mental rehearsal” via keyframe plans and consistent scene understanding could help robots plan tasks more safely and reliably.
- Interactive worlds: Explore imagined or reconstructed environments through natural conversation, getting visuals and narration together.
- Open research: The model is open-sourced, so the community can build new multimodal apps, test safety, reduce bias, and push the science forward.
As with any large AI trained on internet-scale data, there are limits: it can reflect biases in the data, it doesn’t truly “understand” physics like a human, and very long or unusual scenarios can still be challenging. But Emu3.5 is a meaningful step toward AI systems that can learn, imagine, and explain the world across both words and visuals.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved in the paper and can guide future research:
- Data provenance and licensing: Specify exact sources, licenses, and consent policies for the 63M internet videos and third‑party content; clarify how copyrighted, PII‑containing, and restricted materials were handled beyond “talking‑head” filtering.
- Benchmark contamination controls: Detail de‑duplication against evaluation sets (including interleaved generation tasks), near‑duplicate detection, and leakage audits, with quantitative contamination reports.
- ASR–frame alignment quality: Quantify timestamp/alignment error rates of Whisper transcripts to frames, multi‑language ASR accuracy, and the downstream impact of ASR noise on interleaved learning and generation.
- Silent and multilingual videos: Provide the actual language distribution post‑filtering, strategies for balancing silent segments, and empirical effects on cross‑lingual multimodal learning.
- Long‑horizon limits vs 32k context: Report the practical maximum number of images/frames per interleaved sequence (given up to 4k visual tokens per image), memory/latency trade‑offs, and strategies for streaming, chunking, or recurrence for hour‑scale sequences.
- RL post‑training specifics: Disclose the optimization algorithm (e.g., PPO/DPO/RLAIF), reward functions for images and interleaved sequences, reward model training data and bias controls, scale of RL steps, and stability/variance analyses.
- RL vs SFT ablations: Provide controlled comparisons isolating the contributions of RL (and each reward component) over SFT‑only on all claimed capabilities (narrative, guidance, X2I, world exploration, manipulation).
- Interleaved reward design: Clarify how multimodal rewards are assigned at mixed text+image time steps, how credit assignment is handled across long horizons, and whether rewards encourage temporal consistency explicitly.
- DiDA methodology transparency: Precisely define training objectives, schedule, conditioning, and initialization for Discrete Diffusion Adaptation; analyze convergence behavior and compatibility with the NTP base model.
- DiDA failure modes: Systematically evaluate cases where bidirectional parallel visual prediction harms global layout, spatial dependencies, or fine text rendering; quantify diversity trade‑offs (mode collapse risks) vs autoregressive decoding.
- Consistency across frames with DiDA: Test whether parallel per‑image decoding erodes inter‑frame temporal coherence in long interleaved sequences; propose/measure constraints to maintain cross‑image consistency.
- Visual–text loss weighting: Justify the fixed 0.5 weight on visual tokens; provide ablations across weights/curricula and report impacts on multimodal balance, text fidelity, and visual quality.
- Visual tokenizer scalability: Analyze codebook utilization, collapse risks, and OOD generalization for the 131,072‑codebook IBQ with f=16; ablate codebook size, downsampling factor, and SigLIP distillation effects on reconstruction, text rendering, and editing fidelity.
- Diffusion image decoder trade‑offs: Report objective details, training data, and quantitative metrics before/after LoRA distillation (50→4 steps); specify when to prefer diffusion vs vanilla decoder (quality vs speed).
- Video decoder details: Provide training scale (clips, fps, durations), conditioning regimes, mask usage statistics, and quantitative video metrics (e.g., FVD, LPIPS‑T, CLIP‑FID); compare against state‑of‑the‑art video generators on standardized benchmarks.
- Any‑to‑Image (X2I) dataset governance: Disclose the real/semi‑synthetic/synthetic proportions, human representation policies, bias auditing, and quality control criteria; quantify the contribution of each source to final performance.
- Synthetic T2I data risks: Assess imitation/copying of training images, stylistic IP concerns, and whether training on generated content reduces novelty/diversity; propose safeguards and measurement protocols.
- Evaluation completeness and reproducibility: List all benchmarks and metrics used for each task (image quality, text fidelity, temporal consistency, controllability), release prompts and scoring scripts, and detail automated preference evaluation protocols against Gemini (raters, pairings, significance tests).
- Multilingual capability coverage: Beyond English/Chinese, assess text rendering and OCR fidelity for non‑Latin scripts (Arabic, Devanagari, CJK variants), bidirectional text, and low‑resource languages; release multilingual OCR/reading benchmarks and results.
- World modeling metrics: Define and report quantitative measures for spatial consistency, causal continuity, and long‑horizon coherence in Visual Narrative, Visual Guidance, and World Exploration (e.g., identity persistence, pose continuity, map consistency).
- Closed‑loop embodied evaluation: Move from keyframe “plans” to executable control in simulators/real robots; report task success rates, robustness to perturbations, sim‑to‑real transfer, and safety constraints for Embodied Manipulation.
- From keyframes to motion: Specify how keyframe sequences are converted into continuous trajectories (planning/control module, physics constraints), and evaluate feasibility under physical laws and object affordances.
- Robustness and safety under adversarial use: Test adversarial prompts, distribution shifts (low‑light, occlusions, compression), jailbreak attempts, harmful content generation, and refusal behaviors; disclose safety alignment methods and filters.
- Long‑sequence forgetting: Quantify and mitigate drift/forgetting in very long interleaved generations (visual identity and narrative consistency); evaluate memory mechanisms or external retrieval for maintaining story/world state.
- Compute, energy, and hardware footprint: Report training/inference FLOPs, wall‑clock time, accelerator types/counts, DiDA speedups at scale, memory footprints for 2K images, and carbon estimates.
- Scaling laws and stage contributions: Provide compute‑optimal scaling analyses across 10T→13T tokens, stage‑2 benefits (higher resolution/annotations), and the marginal utility of each data family (video‑interleaved, X2I, text‑only).
- Model variants and deployment: Explore smaller distilled variants, quantization, and throughput/latency for interactive applications; report quality‑vs‑cost trade‑offs and memory footprints.
- Audio modality gap: The model uses ASR text but not raw audio; investigate native audio tokenization, audio‑conditioned generation, and audio‑visual synchronization within the interleaved framework.
- Failure case taxonomy: Provide systematic qualitative and quantitative analyses of known weaknesses (e.g., small text rendering, hands, fine geometry, fast motion, multi‑step causality), with targeted data or training remedies.
- Data release limitations: If training data cannot be released, offer detailed recipes, sampling code, or large synthetic substitutes to enable reproducibility and ablation by the community.
- Legal/ethical review of third‑party partnerships: Clarify data governance, retention policies, user consent, and jurisdictional compliance for videos accessed via partnerships; document IRB/ethics oversight where applicable.
Practical Applications
Immediate Applications
Below are applications that can be deployed now or with modest integration and engineering, directly leveraging Emu3.5’s native multimodal generation, any-to-image (X2I) editing, interleaved vision–language reasoning, and DiDA-based fast visual inference.
- Industry — Design, Advertising, and Media: Generate and edit brand-consistent creatives, storyboards, and campaign assets with accurate multilingual text rendering and multi-image conditioning.
- Tools/products/workflows: “Emu3.5 X2I Creative Studio” plugins for Figma/Photoshop; “Storyboard Co‑Pilot” for previsualization that interleaves scripts and frames; batch ad variant generator for A/B testing.
- Assumptions/dependencies: Content rights and governance; GPU/accelerator availability; style control and prompt hygiene; human review for brand safety.
- Industry — E‑commerce and Retail: Rapidly produce product imagery variants (colorways, backgrounds, seasonal themes) and overlay localized text that remains photorealistic at 2K resolution.
- Tools/products/workflows: PIM/CMS integration for auto‑population; background replacement pipeline; language‑localized promo image generator.
- Assumptions/dependencies: QC pipelines to prevent misrepresentation; SKU metadata alignment; font and localization standards.
- Industry/Academia — Technical Documentation and Customer Support: Produce step‑wise illustrated manuals and visual “how‑to” guides from raw text specifications or ticket logs using interleaved image+text sequences (Visual Guidance).
- Tools/products/workflows: “GuideBuilder” for hardware/software onboarding docs; CRM plugin that converts support resolutions into visual procedures.
- Assumptions/dependencies: Accuracy validation; domain‑specific terminology; confidentiality controls for internal content.
- Education — Lesson and Course Content: Create visual narratives that teach history, science concepts, or procedures with interleaved frames and explanatory text; multilingual image text rendering simplifies localization.
- Tools/products/workflows: LMS plugins for “Visual Narrative Lessons”; auto‑generated lab prep sheets with images; curriculum alignment dashboards.
- Assumptions/dependencies: Pedagogical review; age-appropriate content filters; alignment to learning objectives.
- Software — Developer Experience and Training: Generate visual tutorials for software features from log files or screenshots; interleave step descriptions and annotated images.
- Tools/products/workflows: “DevDocs Visual” assistant that ingests screenshots and outputs guided tutorials; API docs with image-heavy examples.
- Assumptions/dependencies: Screenshot ingestion reliability; versioning and context management; security policies for internal UIs.
- Accessibility and Globalization: Accurate text rendering in images supports rapid localization of signage, infographics, and training materials across languages.
- Tools/products/workflows: “Localized Image Renderer” for gov/NGO communications; accessible pictorial instructions with translated overlays.
- Assumptions/dependencies: Font availability and typographic conventions; cultural review; reading order and layout accessibility guidelines.
- Edge/On‑device Prototypes: DiDA’s ~20× per‑image speedup enables interactive image editing and generation on the edge (kiosk, embedded device, mobile prototypes).
- Tools/products/workflows: Mobile AR image-editing demos; kiosk-based visual product configurators; low-latency image renderers for retail.
- Assumptions/dependencies: Memory constraints (32k context), device accelerators (GPU/NPU), efficient decoders, battery budgets.
- Synthetic Data Generation for CV/ML: Produce interleaved sequences for training perception and VLM tasks (dense captions, procedure steps, long-horizon contexts).
- Tools/products/workflows: “Interleaved Data Forge” to synthesize paired image-text and video-keyframe corpora; domain-specific augmentation.
- Assumptions/dependencies: Distribution alignment; label fidelity; controls to avoid reinforcing biases; licensing of synthetic assets.
- Game and Interactive Entertainment: Rapid concept art and level pitches with interleaved narrative+frames; iterate worlds using World Exploration in user-driven mode.
- Tools/products/workflows: Narrative scene generator for game pitches; episodic storyboard drafts; virtual environments for playtesting.
- Assumptions/dependencies: IP constraints; style consistency; team pipelines for art direction and QA.
- Research — Multimodal Benchmarks and Methods: Use the open-source repo to study long-horizon interleaving, bidirectional visual prediction (DiDA), multimodal RL reward design, and scaling behavior.
- Tools/products/workflows: Emu3.5 fine-tuning for new tasks; benchmark suites for Visual Narrative/Guidance; tokenizer/decoder ablations.
- Assumptions/dependencies: Compute budgets; data governance; reproducibility and evaluation rigor.
Long-Term Applications
Below are applications that are feasible but require further research, scaling, safety, domain adaptation, or regulatory compliance, especially where physical actuation or mission-critical correctness is essential.
- Robotics — Embodied Manipulation and Keyframe Planning: Generate subtask sequences (language + keyframes) for complex manipulation (grasping, pouring, folding), then couple with low-level controllers.
- Tools/products/workflows: “Keyframe Planner” that outputs interleaved plans for robotic execution; curriculum generator for long-horizon skills.
- Assumptions/dependencies: Sim-to-real transfer; closed-loop perception; safety guarantees; standardized robot APIs; multimodal reward shaping.
- Digital Twins and Simulation for Training: Use World Exploration to synthesize coherent environments and trajectories for training agents, stress-testing policies across diverse scenarios.
- Tools/products/workflows: “Generative Twin Engine” for factories/cities/campuses; mixed real-synthetic simulation with interleaved narratives.
- Assumptions/dependencies: Physics fidelity; integration with simulators (Unreal/Unity/Omniverse); data validation to avoid unrealistic artefacts.
- Healthcare — Patient Education and Procedural Training: Visual narrative and guidance for surgical steps, imaging workflows, or rehabilitation exercises.
- Tools/products/workflows: “OR Visual Guide” and “Patient‑Prep Explainer” that interleave visuals and instructions; multilingual health education assets.
- Assumptions/dependencies: Clinical validation; regulatory approvals (e.g., FDA/CE), privacy (HIPAA/GDPR), liability frameworks; domain-specific fine-tuning.
- Autonomous Systems — Exploration and Navigation Planning: Interleaved scene synthesis for route planning and what‑if analysis; procedural steps visualized for teleoperation or training.
- Tools/products/workflows: “Exploration Agent” that drafts visual plans with text; simulation‑based pretraining pipelines for autonomy stacks.
- Assumptions/dependencies: Sensor fusion integration; real-time constraints; environment fidelity; safety case documentation.
- Education — Fully Interactive Textbooks and Labs: AI-generated, step-by-step visual+text curricula, labs, and assessments that adapt to learner progress.
- Tools/products/workflows: “Visual Curriculum Builder” and “Adaptive Lab Assistant”; long-horizon multimodal reasoning to scaffold learning.
- Assumptions/dependencies: Pedagogical efficacy studies; content alignment to standards; bias mitigation; teacher-in-the-loop review.
- Smart Home and Personal Assistants: Household task planning (repairs, cooking, crafts) with interleaved visuals that show progress and next steps; AR overlays.
- Tools/products/workflows: “Household Visual Planner” with AR guidance; appliance troubleshooting assistant.
- Assumptions/dependencies: Privacy policies; device integration; failure recovery strategies; safe operations around humans.
- Film/Series Preproduction and Virtual Production: Automated episodic narrative generation, maintaining character/style consistency across long arcs; integration with VP pipelines.
- Tools/products/workflows: “Series Generator” linking scripts to visual beats; continuity trackers; asset versioning across episodes.
- Assumptions/dependencies: Rights/IP management; human direction and union considerations; cultural sensitivity and safety filters.
- Energy and Industrial Maintenance: Visual guidance for inspections and repairs (turbines, substations, pipelines), including long-horizon procedural plans and scene consistency under AR.
- Tools/products/workflows: “Plant Visual Guide” for field technicians; long-horizon checklists with visual confirmations; drone inspection planning.
- Assumptions/dependencies: Domain adaptation; integration with CMMS/EAM systems; safety certification; harsh environment robustness.
- Finance and Enterprise Reporting: Multimodal narrative reports combining charts, diagrams, and explanatory text; visual “playbooks” for compliance audits.
- Tools/products/workflows: “Narrative Report Generator” that creates interleaved visuals/text; compliance workflow tooling.
- Assumptions/dependencies: Data privacy and governance; factuality guarantees; audit trails and provenance.
- Policy and Governance — Multimodal Data Use and Safety: Frameworks for responsible training on web-scale video; standards for multimodal evaluation, synthetic data provenance, and content authenticity.
- Tools/products/workflows: “Multimodal Dataset Auditor” for licensing and quality; watermarking/provenance systems; bias/safety auditing suites.
- Assumptions/dependencies: Legal clarity on data use; cross-jurisdiction compliance; community standards for world-model evaluation.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient update to improve training stability and generalization. "Throughout all stages, the AdamW optimizer is employed with , and ."
- Any-to-Any (X2X): A generalized generative paradigm where any input modality sequence can be transformed into any output modality sequence. "the model's progression towards a more universal Any-to-Any (X2X) generation paradigm"
- Any-to-Image (X2I): A general-purpose image generation/editing setting where arbitrary interleaved image–text inputs produce a single edited or generated image. "Any-to-Image (X2I) generation, i.e, general-purpose image editing, is of critical importance."
- ASR (Automatic Speech Recognition): Technology that converts spoken audio into text. "For the audio track, we adopt the Whisper-large-v2 model~\cite{whisper} to perform automatic speech recognition (ASR)"
- Autoregressive model: A model that generates outputs sequentially, conditioning each token on previously generated tokens. "Notably, it is also the first autoregressive model to rival closed-source diffusion models in both inference speed and generation quality."
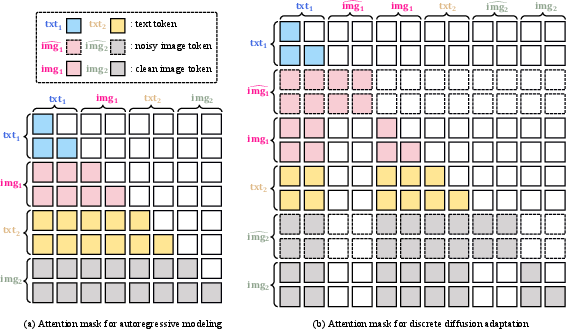
- Bidirectional parallel prediction: A decoding strategy that predicts tokens in parallel from both directions instead of strictly left-to-right. "which converts token-by-token decoding into bidirectional parallel prediction"
- Chain-of-Thought (CoT): An approach that elicits intermediate reasoning steps to improve complex reasoning. "including questions(user prompts), global chain-of-thought (CoT), and image-level CoTs."
- Context length: The maximum number of tokens the model can process in a single sequence. "The model supports a context length of up to 32,768 tokens"
- Context parallelism (CP): A distributed training strategy that splits long sequences across devices to handle large context lengths. "Both training stages adopt tensor parallelism (TP) = 8 and context parallelism (CP) = 2."
- Cross-entropy loss: A standard loss function for classification or next-token prediction that measures the difference between predicted and true distributions. "the model is trained using a standard next-token prediction objective based on the cross-entropy loss."
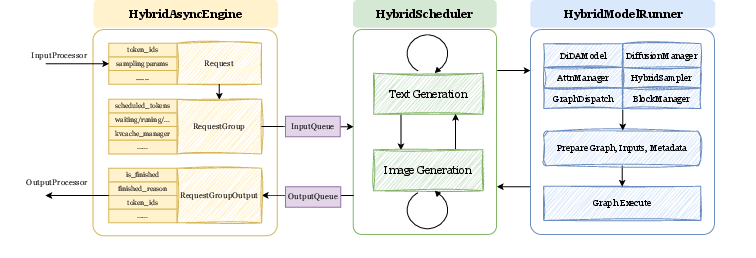
- Decoder-only transformer: A transformer architecture that uses only the decoder stack for autoregressive generation. "follows a standard decoder-only transformer architecture for large-scale multimodal pre-training, supervised fine-tuning, and reinforcement learning."
- DeQA: A learned perceptual image quality assessment model used to filter low-quality frames. "The DeQA model is employed to evaluate perceptual clarity and retain visually high-quality frames."
- DeQA-Score: A score derived from DeQA used for data filtering. "we begin by applying the DeQA-Score filtering scheme~\citep{DEQA} to remove low-quality or visually degraded video clips"
- DiDA (Discrete Diffusion Adaptation): A method that adapts discrete token decoding to diffusion-style parallel prediction to accelerate inference. "we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction"
- Diffusion-based image decoder: A generative image decoder that reconstructs images via denoising diffusion processes from discrete tokens. "The diffusion-based image decoder takes the same quantized tokens as input but generates images at twice the resolution of the vanilla decoder."
- Diffusion-based video decoder: A video generator that synthesizes continuous frames using diffusion conditioned on keyframe tokens. "We extend Emu3.5 to generate continuous videos with a diffusion-based video decoder conditioned on the generated keyframe tokens."
- DiT: A diffusion transformer architecture used for diffusion-based generation. "Our video decoder is built upon the mainstream DiT~\citep{Peebles2022DiT} architecture."
- DINO: A self-supervised vision model used here for feature extraction and redundancy filtering. "DINO and FG-CLIP features are extracted from all keyframes to compute cross-frame similarity"
- Embodied Manipulation: A robotics task involving multi-step, physically grounded object interactions toward a goal. "Embodied Manipulation is a fundamental challenge in robotics, requiring an agent to execute a sequence of dexterous, physical interactions with objects in an environment to achieve a long-term goal."
- FG-CLIP: A variant or extension of CLIP used for extracting visual features, especially for redundancy and alignment tasks. "DINO and FG-CLIP features are extracted from all keyframes to compute cross-frame similarity"
- FlagScale: A framework for large-scale distributed training with multiple parallelism strategies. "The training and inference infrastructure is built upon the FlagScale~\cite{flagscale2025} framework"
- Grouped Query Attention (GQA): An attention variant that groups queries to reduce memory and compute costs. "adopting Grouped Query Attention (GQA)~\cite{ainslie2023gqa} to improve efficiency."
- IBQ: A vector-quantization-based framework for visual tokenization. "We primarily adopt the IBQ~\cite{VQ:IBQ} framework for visual tokenization"
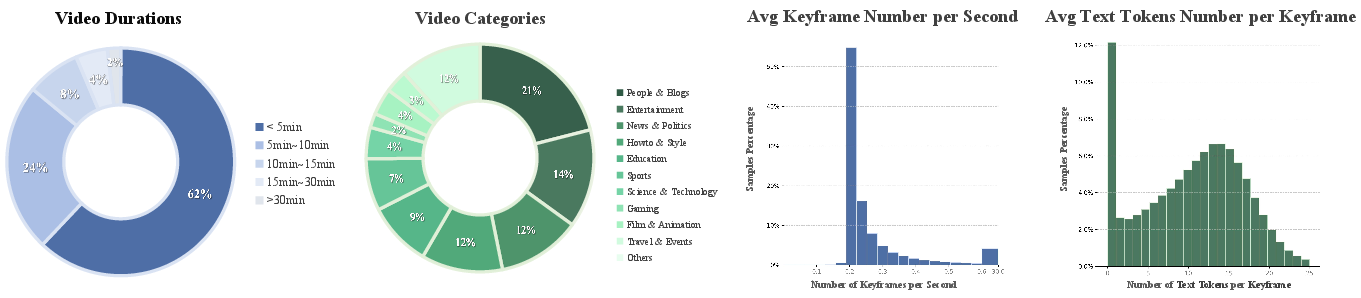
- Keyframe: A representative frame in a video sequence used to summarize or condition generation. "We computed the average number of ASR text tokens per keyframe for each video"
- Key-value heads: Attention heads dedicated to key–value projections, often fewer than total heads for efficiency. "The attention mechanism employs 64 heads with 8 dedicated key-value heads"
- LoRA-based distillation: A technique that uses Low-Rank Adaptation to distill and accelerate diffusion decoders. "we perform the LoRA-based distillation method to accelerate the decoding by about 10, i.e, from $50$ denoised steps to $4$, without sacrificing performance."
- Next-token prediction (NTP): An autoregressive objective where the model predicts the next discrete token in a sequence. "During training, the model performs unified next-token prediction (NTP)"
- Pre-normalization: Applying normalization before the main sub-layer operations in transformers to stabilize training. "RMSNorm~\cite{zhang2019root} with pre-normalization is used to stabilize training."
- QK-Norm: A normalization technique applied to query and key projections to stabilize attention. "We introduce QK-Norm~\cite{dehghani2023scaling} to the query and key projections to enhance attention stability."
- Quantized embeddings: Discrete embeddings obtained via vector quantization, used as compact visual representations. "We utilize quantized embeddings from the VQ quantizer to provide fine-grained visual details"
- Reinforcement learning: A learning paradigm where models are optimized via feedback signals (rewards) rather than direct supervision. "Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation."
- RoPE (rotary positional embeddings): A positional encoding method that rotates queries and keys to encode relative positions. "rotary positional embeddings (RoPE)~\cite{su2024roformer} are employed."
- RMSNorm: A normalization technique that scales activations based on their root mean square. "RMSNorm~\cite{zhang2019root} with pre-normalization is used to stabilize training."
- Self-distillation: A training approach where a model learns from its own outputs or a previous version to improve efficiency or performance. "The model is then rapidly adapted for high-efficiency inference with DiDA, using only a few billions tokens from SFT and self-distillation data."
- SigLIP: A vision–LLM whose features are used to distill semantics into the visual tokenizer. "we also integrate feature distillation from SigLIP~\cite{SigLIP} into the intermediate outputs of the tokenizer decoder during training"
- Spatiotemporally consistent: Maintaining coherent structure and dynamics across both space and time. "enabling spatiotemporally consistent world exploration"
- Supervised fine-tuning (SFT): Post-training on labeled data to align the model with desired tasks and formats. "Emu3.5 undergoes supervised fine-tuning (SFT) with 150 billion samples"
- SwiGLU: An activation function variant that improves transformer training and performance. "SwiGLU~\cite{shazeer2020glu} is used as the activation function"
- Tensor parallelism (TP): A distributed training technique that splits model tensors across devices. "Both training stages adopt tensor parallelism (TP) = 8 and context parallelism (CP) = 2."
- Visual Guidance: A task focused on multi-step, interleaved vision–language generation that grounds procedural actions in visual context. "Visual Guidance is a multimodal learning task designed to enable models to understand and generate procedural actions through visual information"
- Visual Narrative: Interleaved generation of images and text to tell coherent, temporally consistent stories. "Visual Narrative, characterized by generating consecutive storylines with narrative texts and vivid images in an interleaved manner"
- Visual tokens: Discrete token representations of images used within a unified text–vision token space. "To maintain balanced optimization between modalities and prevent visual tokens from overwhelming the training dynamics"
- Visual tokenization: The process of converting images into discrete tokens via a learned codebook. "We primarily adopt the IBQ~\cite{VQ:IBQ} framework for visual tokenization"
- VQ quantizer: A vector-quantization module that maps continuous features to discrete codebook entries. "We utilize quantized embeddings from the VQ quantizer to provide fine-grained visual details"
- World Exploration: A task where models generate and navigate coherent visual environments based on prompts, maintaining spatial and causal consistency. "World Exploration is designed to enable models to immerse themselves in user-defined virtual worlds and perform interactive exploration based on textual or multimodal prompts."
- World model: A model trained to predict and simulate future multimodal states of an environment. "We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language."
Collections
Sign up for free to add this paper to one or more collections.