- The paper introduces an entropy-guided multi-layer fusion framework combining DINOv3 and SigLIP2, capturing complementary spatial and semantic features.
- It employs orthogonality-regularized linear transformations and RoPE-based cross-attention to enhance geometric alignment and reduce redundant feature signals.
- Empirical results demonstrate state-of-the-art improvements in tasks like RefCOCO detection and fine-grained reasoning, achieving gains up to 5.4%.
CoME-VL: A Complementary Multi-Encoder Approach for Vision-Language Learning
Motivation and Preliminary Analysis
CoME-VL is introduced in response to significant limitations in single-encoder Vision-LLMs (VLMs), particularly those using CLIP-style contrastive pretraining, which are optimized for global image-text alignment but underperform in dense semantic recognition and grounding tasks. An extensive qualitative and quantitative analysis demonstrates that contrastively trained encoders (e.g., SigLIP2) primarily capture high-level semantic representations aligned with textual information, but sacrifice spatial precision. In contrast, self-supervised encoders (e.g., DINOv3) have a strong bias toward geometric and localized spatial features, leading to enhanced robustness in fine-grained visual reasoning and grounding.

Figure 1: Semantic feature analysis comparing spatial attention mechanisms across layers for DINOv3 and SigLIP2, highlighting their orthogonal behaviors in semantic and spatial encoding.
Layer-wise inspection of attention maps reveals that DINOv3 exhibits spatially coherent, object-centric attention patterns from early layers, thereby facilitating object boundary and part-level geometry awareness, while SigLIP2's attention is more fragmented and morphs gradually into semantically discriminative regions in deeper layers. These orthogonal properties motivate dual-encoder integration.
Architecture and Methodology
CoME-VL proposes a structured, modular fusion framework combining the complementary strengths of a self-supervised DINOv3 encoder with a contrastive SigLIP2 encoder. Each image is processed by both encoders, extracting hierarchical feature grids from strategically selected layers based on spatial entropy analysis, which identifies the most informative layers and reduces unnecessary feature redundancy.
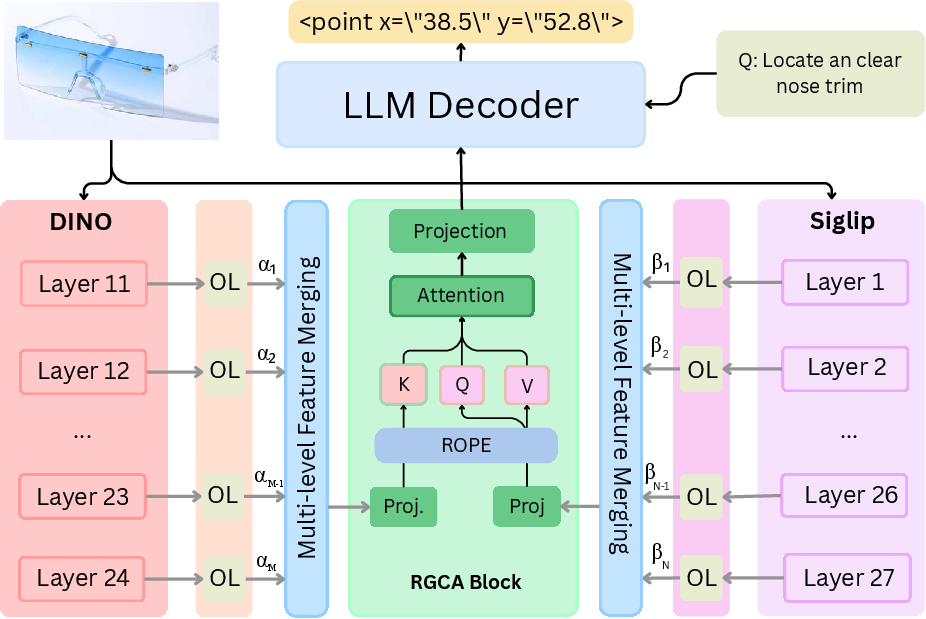
Figure 2: Schematic overview of CoME-VL, showing the dual-encoder, multi-layer fusion, orthogonality-regularized mixing, RoPE-based spatial alignment, and decoder-only LLM integration.
A key innovation is entropy-guided multi-layer aggregation, which informs layer selection not by arbitrary depth, but by quantifying distributional sparsity and information density at each stage, leading to selective retention of diverse semantic (SigLIP2) and robust spatial (DINOv3) features. To further minimize redundancy, each retained layer output is projected through an orthogonality-regularized linear transformation, which encourages representational decorrelation and maximizes complementary signal utilization.
Spatial alignment during fusion is conducted via RoPE (Rotary Position Embedding)-enhanced cross-attention, which enforces geometry-aware token composition without exploding the number of visual tokens processed by the decoder-only LLM. This architecture enables succinct and efficient vision-language feature integration, streamlining both computation and memory costs relative to naive concatenation schemes.
Empirical Results and Analysis
CoME-VL is evaluated on a suite of vision-language and grounding benchmarks, revealing consistent improvements over both contrastive and self-supervised single-encoder baselines. In terms of quantitative gains, CoME-VL achieves an average improvement of 4.9% on visual understanding tasks and 5.4% on grounding tasks. On the challenging RefCOCO benchmark for detection, CoME-VL establishes new state-of-the-art performance, surpassing both single-encoder baselines and recent multi-encoder feature-merging approaches.
Qualitative results illustrate more precise coordinate-level grounding for fine-grained pointing and region-localization queries.

Figure 3: Qualitative results on PixMo pointing, with CoME-VL delivering accurate coordinate-level responses for fine-grained visual queries.
Furthermore, CoME-VL uniquely demonstrates robust performance on localization, chart understanding, document-table reasoning, pointing, and counting—tasks representative of multi-faceted multimodal reasoning.

Figure 4: Qualitative task breadth: CoME-VL supports chart understanding, table reasoning, object localization, pointing, and counting, unifying visual understanding and grounding.
Ablation experiments show that both the entropy-guided multi-layer fusion and orthogonality-regularized mixing are indispensable for achieving these results, with component-wise analyses confirming additive performance benefits. RoPE-based cross-attention further improves spatial alignment, particularly for localization accuracy beyond naive fusion.
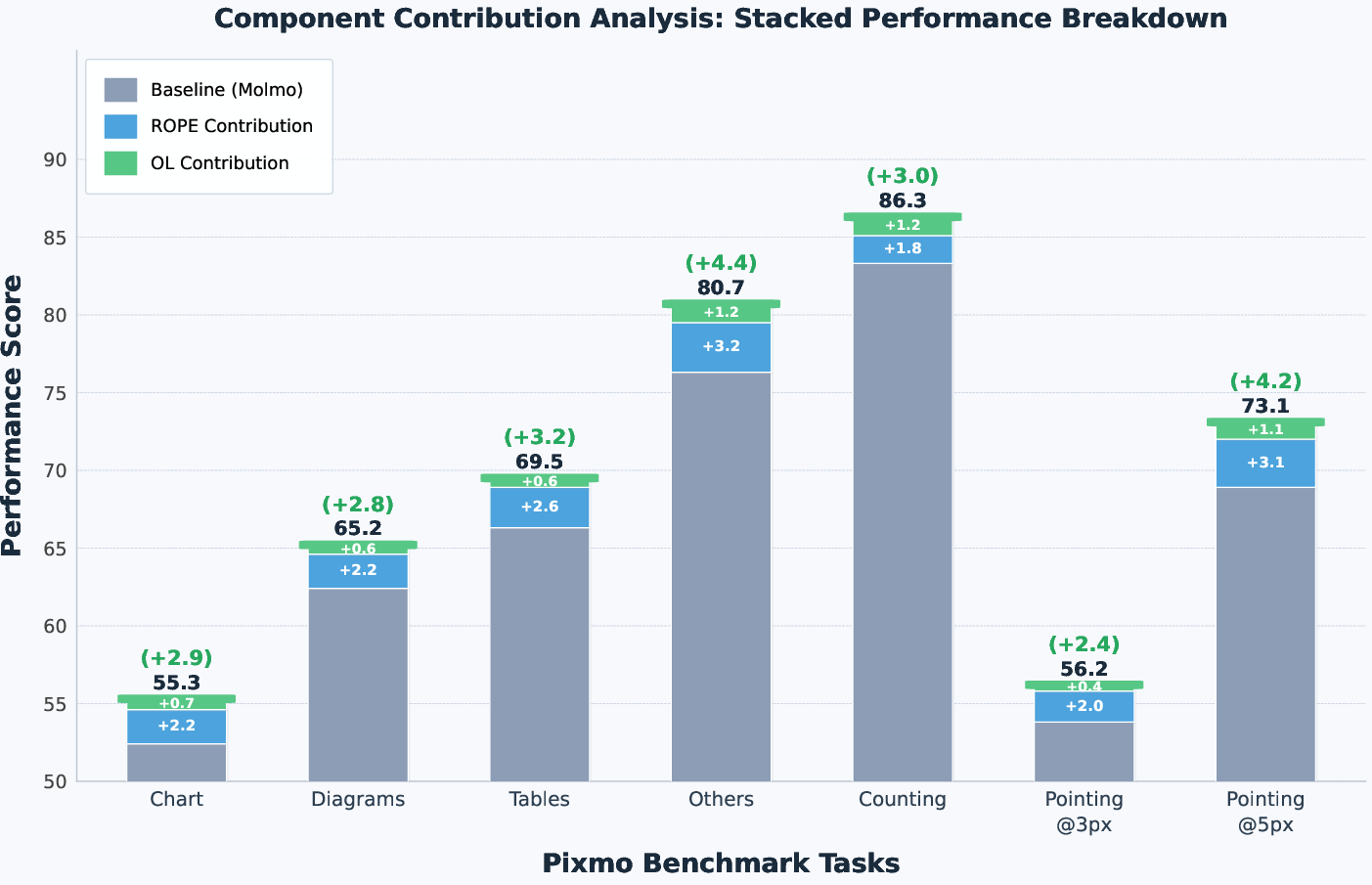
Figure 5: Component-wise impact of RoPE-based alignment and orthogonality-regularized mixing, demonstrating cumulative performance enhancement over the Molmo baseline.
Attention rollout visualizations confirm that DINOv3 and SigLIP2 retain their complementary focus across depth, with DINOv3 providing strong spatial coherence and SigLIP2 delivering semantic specialization.
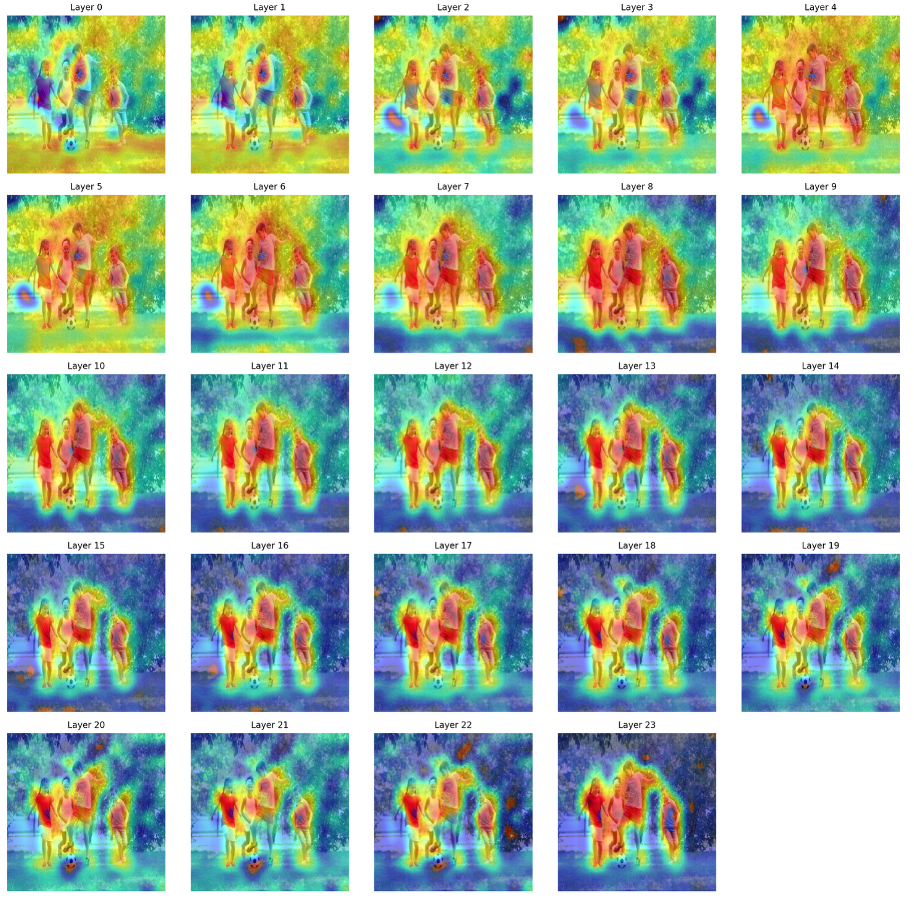
Figure 6: Deeper-layer attention rollout for DINOv3, visualizing the emergence of discriminative region sensitivity from spatially coherent object focus.
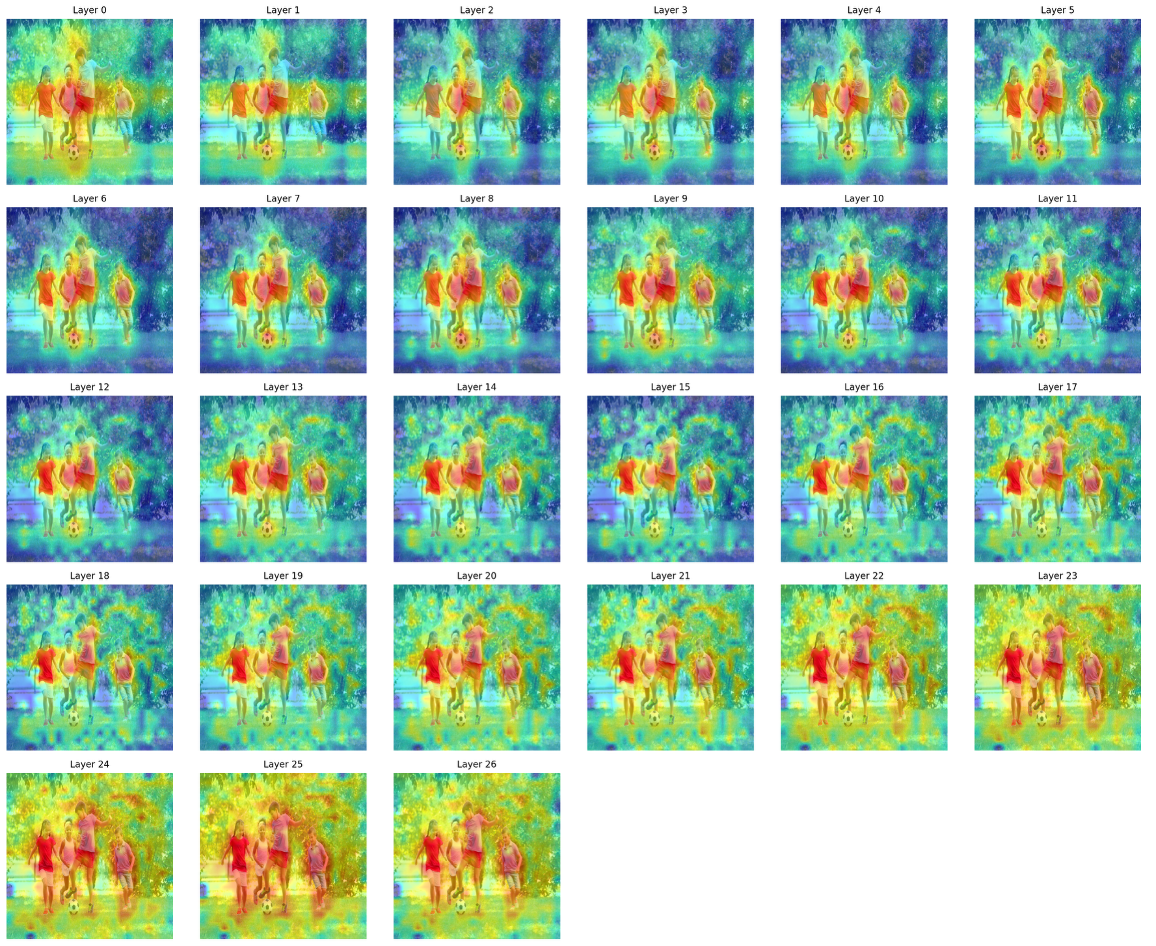
Figure 7: Deeper-layer attention rollout for SigLIP2, marking the transition from diffuse early-layer attention to semantically-focused discrimination.
Implications and Future Outlook
CoME-VL demonstrates that principled, entropy-guided multi-encoder fusion—leveraging orthogonality regularization and geometry-aware cross-attention—can overcome representational bottlenecks inherent in contrastive- or self-supervised single-encoder designs. This exposes the criticality of multi-scale, multi-source visual features for supporting high-precision grounding and compositional reasoning in VLMs, challenging dominant architectural paradigms built around single global representations.
Practically, CoME-VL's framework is extensible to multi-vision-encoder approaches, offering a path toward further scaling and robustness as LLMs grow in capacity. The modular fusion and efficient integration protocol can be adapted to other encoders (e.g., SAM, MAE, ConvNEXT) and to tasks requiring complex visual grounding, such as robotics, autonomous navigation, and medical imaging analysis.
Orthogonality-regularized fusion and entropy-based layer selection may become standard in the construction of scalable, interpretable multimodal representation pipelines.
Conclusion
CoME-VL introduces a robust, scalable vision-language architecture that capitalizes on the complementary nature of contrastive and self-supervised visual encoders, incorporating entropy-guided layer selection, orthogonality-regularized fusion, and RoPE-based cross-attention for efficient, accurate multimodal integration. Strong empirical results, both qualitative and quantitative, support the approach's validity. This architecture provides a unifying template for future research in visual grounding and multimodal reasoning, suggesting that further innovation in multi-encoder fusion will be central to progress in vision-LLMs (2604.03231).

