- The paper introduces a codec-aligned tokenization that utilizes motion-residual and bit-cost cues to concentrate tokens on event-relevant video regions.
- It employs a unified 3D spatiotemporal embedding and OneVision-Encoder to efficiently process sampled frames, codec-stream data, and static images.
- Experimental results demonstrate significant gains, including a +9.7 boost over frame sampling and 74.9 mAP on JumpScore for temporal localization.
LLaVA-OneVision-2: Codec-Aligned Paradigm for Long-Video Perceptual Intelligence
Introduction and Motivation
LLaVA-OneVision-2 (LLaVA-OV-2) advances the multimodal LLM paradigm by rethinking video input representations, shifting from legacy uniform frame sampling to a codec-aligned tokenization regime that prioritizes perceptual evidence allocation. The principal motivation is to exploit the predictive structure inherent in compressed video bitstreams, particularly temporal bit-cost and motion-residual cues, to concentrate token budgets on event-relevant regions and improve spatiotemporal grounding across long-form video tasks.
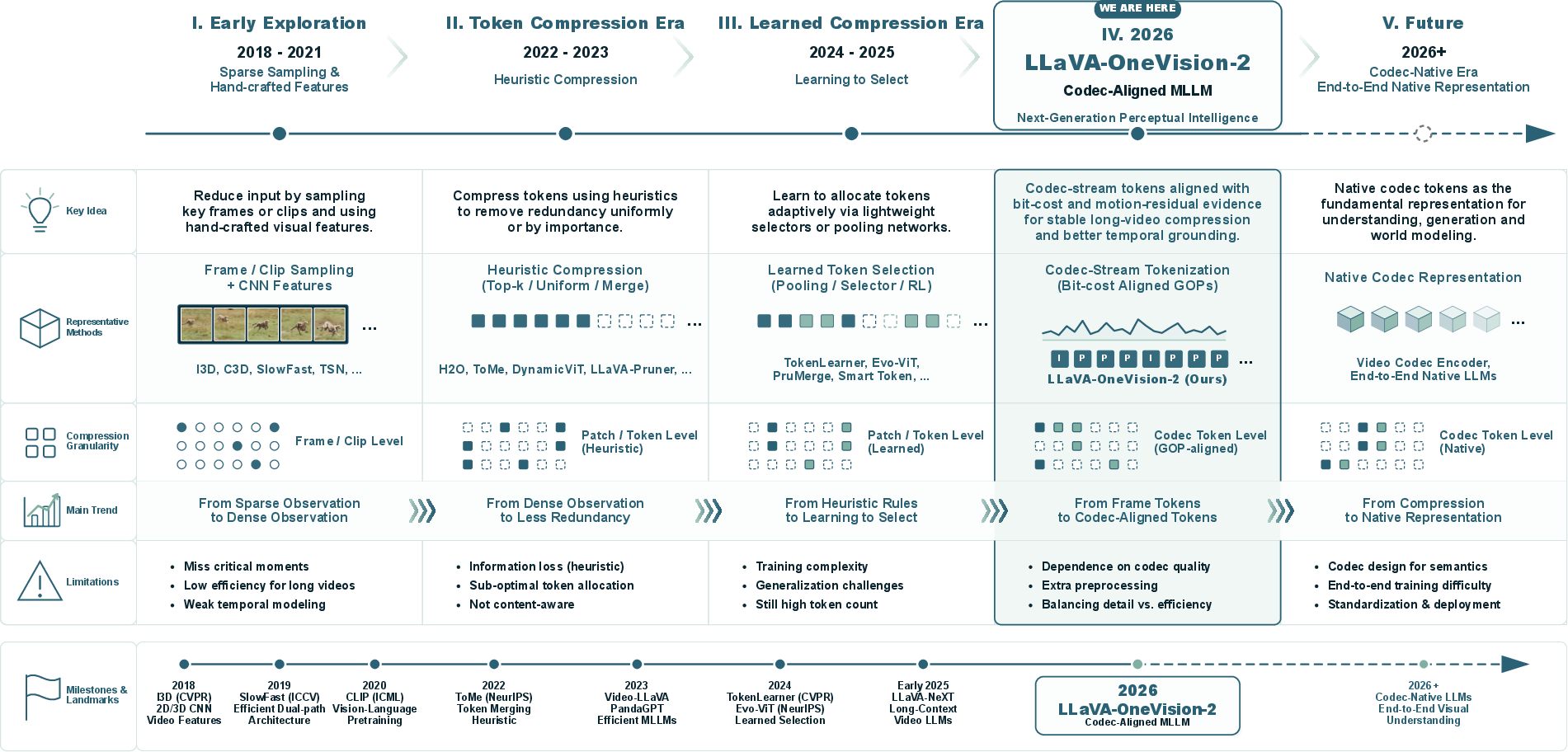
Figure 1: Roadmap of video understanding from token compression to codec-aligned perceptual intelligence. The roadmap traces the evolution from early frame/clip sampling and hand-crafted visual features, to heuristic token compression, learned token selection, and the 2026 codec-aligned paradigm represented by LLaVA-OneVision-2.
Standard LVLMs under-represent continuous spatial and motion dynamics by reducing videos to uniformly sampled frames, discarding the majority of predictive stream signals. In contrast, LLaVA-OV-2 treats compressed video as a continuous bit-cost stream, adaptively grouping tokens according to codec dynamics and explicitly incorporating motion-residual evidence. This allocation strategy is coupled with a unified spatiotemporal embedding via shared 3D RoPE, enabling joint representation of codec, sampled, and static image inputs.
Architectural Innovations
LLaVA-OV-2 employs the OneVision-Encoder as the backbone, supporting sampled frames, codec-patchified videos, and static images. The encoder maps all modalities to a unified visual-token interface—patch embeddings, 3D coordinates, and adaptive group visibility masks. Spatial windowed attention preserves native-resolution computation efficiency, crucial for scaling to long-form inputs.
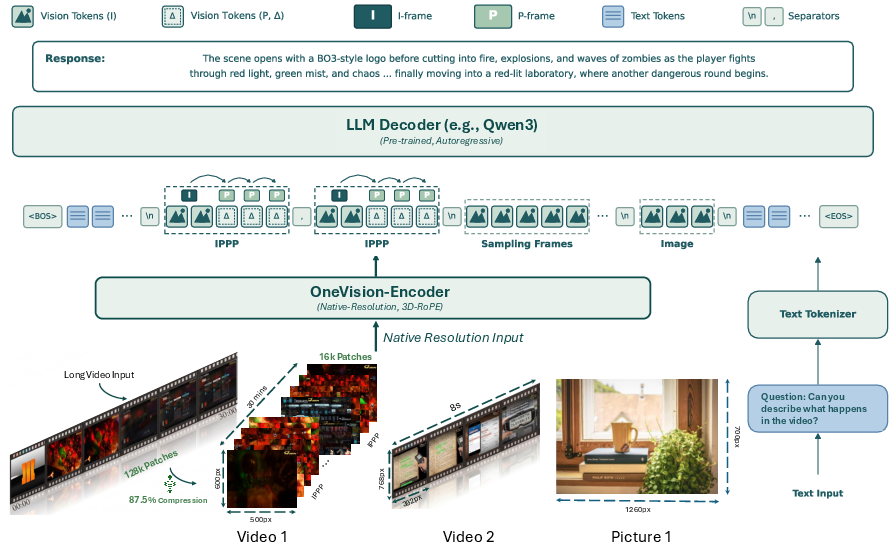
Figure 2: LLaVA-OneVision-2 architecture. The model unifies codec-stream videos, sampled-frame videos, and native-resolution images under a shared visual-token interface, maintaining modality invariance throughout the stack.
The vision-language connector is a lightweight MLP projecting visual tokens into the language-model embedding space, and a pre-trained Qwen3-8B decoder processes the combined visual and textual streams under the next-token objective.
Codec-stream tokenization, the headline contribution, segments the bitstream using adaptive Groups of Pictures (GOPs) determined by packet-level bit-cost dynamics. Within each group, spatial saliency is scored jointly via motion vectors and luma residuals, normalized by robust statistics, and patches are selected in block-wise granularity to align with encoder-side merges.

Figure 3: Codec-stream tokenization partitions the video adaptively; motion and residual signals score spatial saliency, yielding compact, merge-aligned I/P visual canvases.
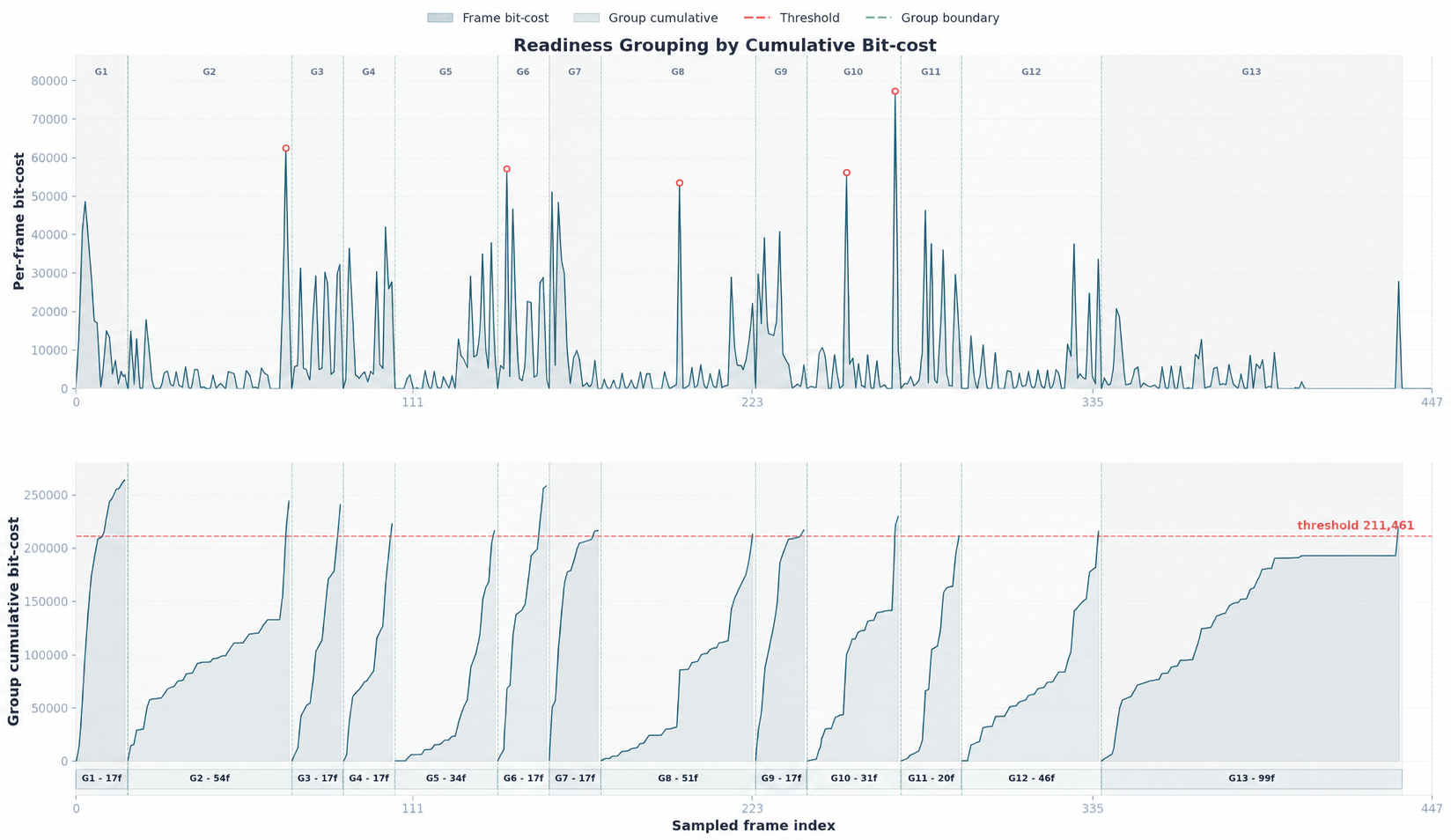
Figure 4: Codec-stream grouping by cumulative bit-cost. Sharp bit-cost peaks correspond to rapid motion or abrupt visual transitions, and adaptive grouping densifies token allocation around these regions.
This design induces sparse, event-centric token distributions—essential for stable compression over extended temporal horizons—without introducing downstream architectural complexity. All input modalities are processed within the same encoder, maintaining architectural parity while shifting evidence selection toward event transitions.
Training Stack and Data Strategy
A progressive four-stage training recipe is employed, scaling supervision from images to long videos and spatial reasoning:
- Stage 1 bootstraps from image pretraining, mixing short 30s video captions.
- Stage 2 extends to 30–60s clips with multimodal instruction data.
- Stage 3 incorporates long-form (10–15min) video captions and instruction data.
- Stage 4 introduces codec-stream tokenization and spatial supervision (Molmo2-VideoTrack, LLaVA-OneVision-2-Spatial-4M), densifying token budgets to up to 768 frames.
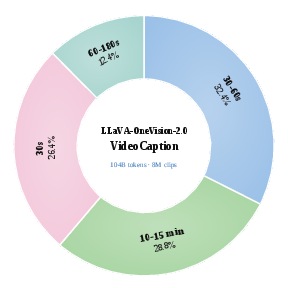
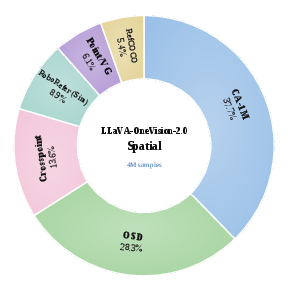
Figure 5: Video-Caption Data Mixture: Training is stratified by clip duration and token volume, ensuring models acquire both semantic perception and temporal continuity.
Mixed-batch training interleaves codec-stream, uniform-frame, and image inputs. This ensures robust generalization across event coverage and spatial resolution.
JumpScore Benchmark and Temporal Grounding
The JumpScore benchmark, designed to probe fine-grained sub-second temporal localization in densely repeated motion sequences, exposes the failure regime of uniform sampling. With decimal-second annotations for each jump-rope cycle start, the task requires precise boundary localization amid visual redundancy.

Figure 6: Representative cycles from JumpScore. Discriminative evidence exists only at cycle boundaries, challenging conventional frame-sampled models.
LLaVA-OV-2 achieves 74.9 mAP on JumpScore, a +44.8 improvement over Qwen3-VL-8B, and codec-stream inputs yield a +9.7 boost over matched frame sampling. The model maintains parity or improves performance on standard QA and grounding benchmarks under increasing token budgets.
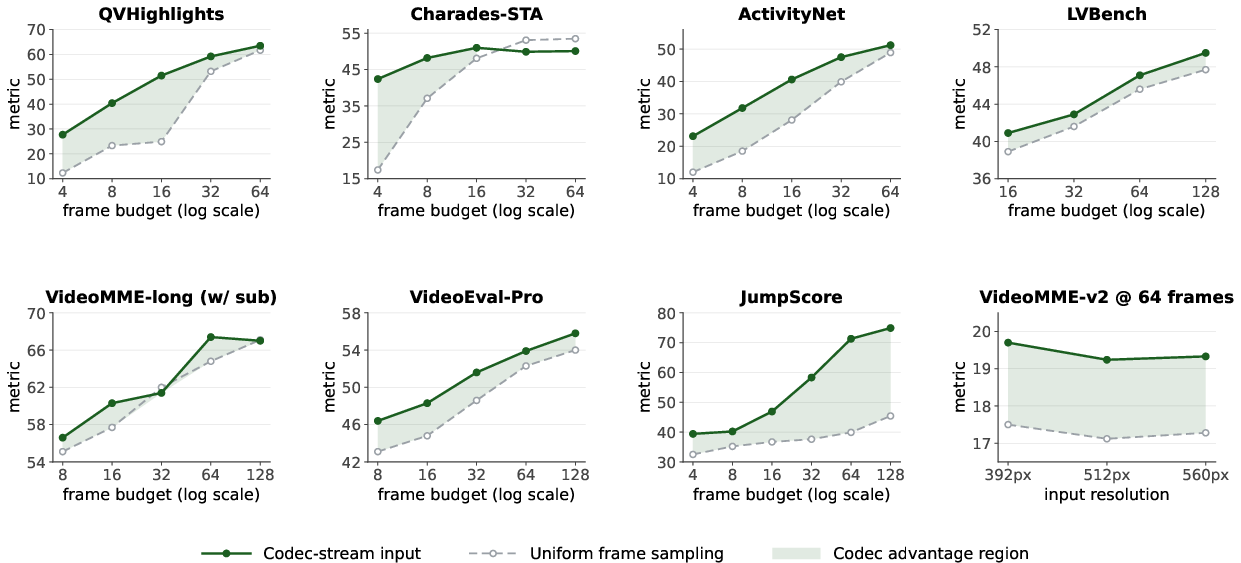
Figure 7: Codec-stream inputs versus frame sampling. Stream tokenization yields substantial gains in event-level temporal grounding by allocating tokens to high-bit-cost, high-residual regions instead of uniform slots.
Comprehensive Benchmarking and Ablation
Across 18 video, 11 spatial, and 11 image/document benchmarks, LLaVA-OV-2 demonstrates consistent performance gains:
- Video suite: average +4.3 points over Qwen3-VL-8B, with outsized improvements on temporal grounding (Charades-STA, ActivityNet, QVHighlights), spatial reasoning (VSI-Bench, ReVSI), and JumpScore.
- Spatial reasoning: +5.3 average, with dramatic outperformance on CrossPoint (+35.0) and TraceSpatial-3D (4× next-best score).
- Tracking: +15.6 J{content}F average, indicating superior mask overlap in referring segmentation tasks.
Ablation studies show codec-stream tokenization is most effective for event-centric tasks, and frame sampling remains preferable for detail-sensitive, static, or trajectory-reliant queries.
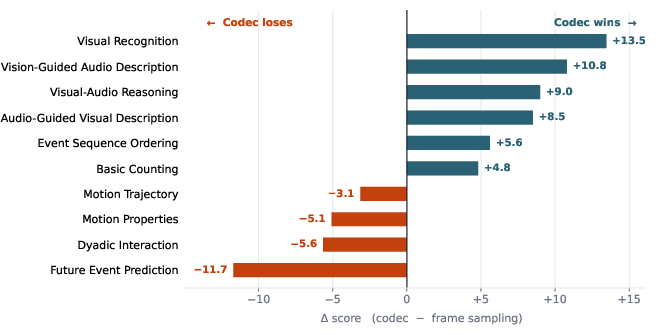
Figure 8: Per-skill ablation on VideoMME-v2: Codec-stream inputs dominate on event-ordering and recognition; frame sampling is superior for trajectory continuity and motion prediction.
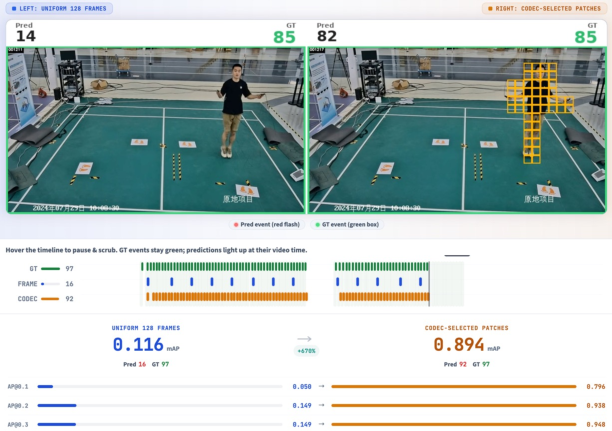
Figure 9: JumpScore validation: At matched visual-token budgets, codec-stream sampling attributes nearly all cycle starts, while uniform sampling fails on dense motion boundaries.
Practical and Theoretical Implications
LLaVA-OV-2’s codec-aligned paradigm marks a shift from uniform observation toward stream-aware evidence allocation, directly leveraging bitstream dynamics for token efficiency. Practically, this enables scaling to longer temporal horizons by compressing irrelevant intervals and densifying transitions, making it highly suitable for streaming perception, robotics, and any event-driven multimodal applications.
Theoretically, unified spatiotemporal token interfaces, adaptive grouping, and shared RoPE embeddings offer a path toward generalized perception modules. The explicit separation of evidence allocation from downstream language processing facilitates plug-and-play architecture transferability across MLLM stacks.
Future extensions will likely combine codec-aligned tokenization with memory mechanisms (e.g., visual KV-cache) and reinforcement-fine-tuning for deeper temporal grounding, scaling visual context to hours-long videos and enabling agentic behavior in embodied environments.






Figure 10: Real-world trajectory predictions: Online spatial reasoning and per-frame trajectory generation enable robotic manipulation in dynamic scenarios.
Conclusions
LLaVA-OneVision-2 presents a codec-aligned, stream-aware approach to video tokenization, yielding significant improvements in temporal grounding, spatial reasoning, and tracking under constrained token budgets. The model’s design and training scheme provide empirical evidence that perceptual intelligence benefits from allocating visual tokens according to predictive stream dynamics, not uniform observation, and set the stage for scalable, streaming multimodal intelligence in long-horizon video tasks (2605.25979).

