SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
Abstract: Recent large vision-LLMs (VLMs) remain fundamentally constrained by a persistent dichotomy: understanding and generation are treated as distinct problems, leading to fragmented architectures, cascaded pipelines, and misaligned representation spaces. We argue that this divide is not merely an engineering artifact, but a structural limitation that hinders the emergence of native multimodal intelligence. Hence, we introduce SenseNova-U1, a native unified multimodal paradigm built upon NEO-unify, in which understanding and generation evolve as synergistic views of a single underlying process. We launch two native unified variants, SenseNova-U1-8B-MoT and SenseNova-U1-A3B-MoT, built on dense (8B) and mixture-of-experts (30B-A3B) understanding baselines, respectively. Designed from first principles, they rival top-tier understanding-only VLMs across text understanding, vision-language perception, knowledge reasoning, agentic decision-making, and spatial intelligence. Meanwhile, they deliver strong semantic consistency and visual fidelity, excelling in conventional or knowledge-intensive any-to-image (X2I) synthesis, complex text-rich infographic generation, and interleaved vision-language generation, with or without think patterns. Beyond performance, we show detailed model design, data preprocessing, pre-/post-training, and inference strategies to support community research. Last but not least, preliminary evidence demonstrates that our models extend beyond perception and generation, performing strongly in vision-language-action (VLA) and world model (WM) scenarios. This points toward a broader roadmap where models do not translate between modalities, but think and act across them in a native manner. Multimodal AI is no longer about connecting separate systems, but about building a unified one and trusting the necessary capabilities to emerge from within.
First 10 authors:





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SenseNova-U1, a single artificial intelligence model that can both understand and create across different types of information, like text and images. Instead of building separate systems (one for “reading” images and text, and another for “drawing” or generating them), the authors design one unified model that learns to see, think, and make things in the same “language” inside the model. Think of it like teaching one student to both read and write in multiple subjects, rather than splitting the work between two different students.
What questions did the researchers ask?
The paper focuses on a few simple but big questions:
- Can one model natively learn to both understand (read/interpret) and generate (write/draw) across text and images without using separate parts glued together?
- Can we avoid heavy compression tricks that lose detail in images, and still get high-quality, sharp results?
- Can a unified design make the model better at complex tasks that mix text and images, like creating posters with readable text, editing images using instructions, or making comics and slides with both words and pictures?
How did they build and train the model?
To make this understandable, imagine the model as a single brain trained to handle both words and pixels together, rather than having two different brains that translate between each other.
Here are the main ideas, with simple analogies:
- Near-lossless visual interface: Instead of squishing an image into a tiny code (which loses details), the model chops the image into small “tiles” (like LEGO bricks, each covering a 32×32 patch). It learns directly from these tiles and from raw words, side by side. This helps keep fine details and clear text in images.
- One shared backbone with two streams: Inside the model, there’s a shared pathway where information mixes, but the “understanding” stream (like reading) and the “generation” stream (like drawing) each have their own specialized sub-parts. They talk to each other layer by layer but don’t step on each other’s toes. You can picture this like a classroom where readers and artists work in the same room and can glance at each other’s work, but each still practices their own skill.
- Mixture-of-Transformers (MoT): For bigger versions, the model uses teams of “expert” sub-models. A smart router picks a few experts for each piece of the task, so the model scales up without wasting effort. It’s like calling in the right specialists—some are better at understanding tricky text, others at drawing realistic images.
- Generation by “cleaning noise”: To create images, the model starts from noisy pixels (like static on a TV) and learns to clean them step by step until a clear image appears. The researchers adjust the amount of noise based on the image size, so making a small picture or a big poster feels equally “fair” to the model.
- Training in stages (like school levels):
- Warmup for understanding: Start by making the “reading” ability strong.
- Pre-training for generation: Teach the model to draw images from text at different resolutions.
- Unified training: Now train both together so they cooperate smoothly.
- Fine-tuning: Polish instruction-following and mixed tasks (answering visual questions, making posters, editing images).
- Reward-based tuning: Give the model feedback (rewards) for specific goals, like drawing readable text in images, matching styles, and making images people prefer.
- Distillation: Teach the model to generate high-quality images with fewer steps, so it’s much faster at runtime.
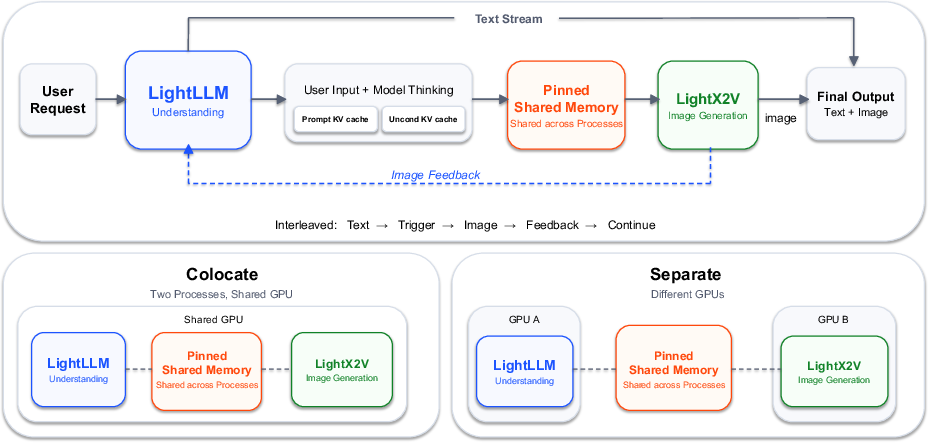
- Practical serving (how it runs): They use two engines that work together—one handles the understanding and conversation flow; the other specializes in fast image generation. They share information quickly under the hood so users feel it’s one seamless model.
What did they find, and why is it important?
The model performs strongly in both reading/understanding and creating/generation—at the same time:
- Understanding power: It competes with top models at reading text, analyzing images, answering questions about pictures, reasoning with knowledge, making decisions like an agent, and understanding spatial layouts.
- Generation quality: It makes high-fidelity images that match the text, including tricky, text-heavy layouts like posters, infographics, resumes, and comics. The images stay sharp and semantically accurate, and the model keeps the written text readable inside images.
- Interleaved content: It can produce mixed sequences that include both sentences and images in order (like illustrated stories or slide decks) while keeping the content consistent across the whole piece.
- Beyond seeing and drawing: Early tests show it can also connect vision, language, and action (VLA) and even model aspects of the world over time (world modeling), hinting that the unified approach helps with “think-and-act” tasks.
- Efficiency and simplicity: By avoiding giant, separate vision encoders or heavy decoders, the system is simpler and trains end-to-end. Distillation makes it fast at generation with far fewer steps, which is crucial for real apps.
Why it matters: Previous systems often stitched together different parts that didn’t fully “think in the same way.” This paper shows that one native, unified model can be good at both understanding and generation without relying on lossy shortcuts. That’s a big step toward AI that naturally sees, thinks, and creates in a single flow.
What could this change?
- More capable assistants: The same model could read a document, understand a chart, answer questions, then design a clean infographic—all in one go.
- Better consistency: Because understanding and generation live in the same brain, the pictures it draws should better match the text it reads and writes, reducing errors or mismatches.
- Rich creative tools: It could help make presentations, posters, comics, and tutorials that mix accurate text with well-laid-out visuals, including complex, text-dense graphics.
- Toward unified intelligence: The results suggest that you don’t need to glue specialized systems together. Instead, you can trust a single, well-designed model to grow the skills needed across vision, language, and even action.
In short, SenseNova-U1 is a promising step toward AI that doesn’t just translate between separate parts, but truly thinks across words and pixels as one.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or left unexplored in the paper, framed to be concrete and actionable for future research.
- Quantitative validation of “near-lossless” visual interface: no measurements (e.g., PSNR/SSIM, LPIPS) showing fidelity preservation under token compression with patches, nor comparisons to VAE/VQ-VAE latents at similar compute.
- Patch-head limitations and grid artifacts: the decoder MLP predicts independent patches, acknowledged to cause grid artifacts; no implemented cross-patch continuity mechanism (e.g., PixelShuffle + conv, sub-patch overlap, or cross-attention between adjacent patches) or ablation on patch size vs. artifact severity.
- Effect of patch size and strides: no experimental study of how stride choices (16 then 2) and patch size affect semantic consistency, OCR, fine detail rendering, memory footprint, and throughput across resolutions.
- Lack of ablations on noise-scale design: the resolution-adaptive noise is introduced without theoretical analysis or empirical ablations (e.g., alternative scalings, impact on SNR distribution, sensitivity to and ) across varied aspect ratios and sizes.
- Timestep and sampler hyperparameters: choices like logit-normal sampler (), timestep shift (3.0), and Euler solver are not justified or compared against alternatives (e.g., Heun, RK methods) for stability, sample quality, and speed.
- Classifier-free guidance settings: claim that and “consistently yield best performance” lacks quantitative evidence and ablations across tasks (text-rich, style-constrained, editing), and may not generalize.
- Interference and coupling analysis: despite “full parameter decoupling” between understanding and generation streams, there is no study of representational interference, cross-stream synergy, or optimal degrees of parameter sharing (e.g., shared attention vs. separate FFNs) under multi-task optimization.
- Native RoPE details and ablations: the multi-axis “Native RoPE” (temporal/spatial frequency bases) is not specified mathematically nor evaluated via ablation on frequency ranges (rope thetas), normalization choices, and their effects on layout, spatial reasoning, and high-res generation.
- MoT/MoE routing behavior: no transparency into expert specialization patterns, routing stability, load balancing outcomes, or collapse risks; limited analysis of MoE balance loss coefficients ( and ), top-=8 activation, and their trade-offs in accuracy vs. efficiency.
- Joint loss weighting and curriculum: fixed (CE:MSE=0.1:1.0) lacks ablation for optimal weighting or adaptive schedules; no study of catastrophic forgetting or performance drift when alternating Stage 3/4 joint training and Stage 5 RL/post-training.
- Dataset disclosure and reproducibility: major portions of understanding data are internal (SenseNova V6.5); insufficient detail on dataset sources, licensing, demographics, language coverage, and availability for replication or fairness auditing.
- Bias, safety, and hallucination risks: while filtering is mentioned, there is no systematic evaluation of safety (toxic/unsafe outputs), demographic bias in “People” domain, or hallucination rates in visual reasoning and text-rich generation.
- OCR robustness and multilingual coverage: reliance on PaddleOCR and English/Chinese prompts; no analysis for non-Latin scripts, low-resource languages, complex typography, curved text, or dense documents at high resolution.
- Reward modeling biases in RL: VLM judges (closed-source) and HPSv3 are known to have biases (e.g., darker backgrounds favored); no mitigation strategies, calibration, or evidence of avoiding “reward hacking” and unintended aesthetic drifts that degrade OCR or layout fidelity.
- DMD2 distillation quality trade-offs: NFE reduction (100→8) is reported without quantifying the impact on fidelity, text alignment, style adherence, and editing precision across task types; no comparison to other distillation or consistency training strategies.
- Post-training freezing strategy: freezing understanding branch, last 3 layers, and MLP head during RL is a heuristic to mitigate artifacts; no empirical justification or exploration of selective fine-tuning patterns that better balance artifact removal and semantic control.
- Editing and interleaved generation benchmarking: no standardized metrics or datasets for evaluating edit locality, constraint adherence, and interleaved layout accuracy (e.g., DocLayNet, PubLayNet, Chart benchmarks) or comparisons to state-of-the-art editing frameworks.
- VLA and world modeling claims are preliminary: no task definitions, datasets (e.g., CALVIN, Habitat, Procgen), metrics, or baselines demonstrating actionable performance in action-conditioned generation or predictive modeling.
- Inference architecture under load: disaggregated LightLLM/LightX2V system shows per-step latencies but lacks end-to-end throughput analyses under realistic mixed workloads, batching policies, fairness across text/image-heavy traffic, and tail-latency or cold-start behavior.
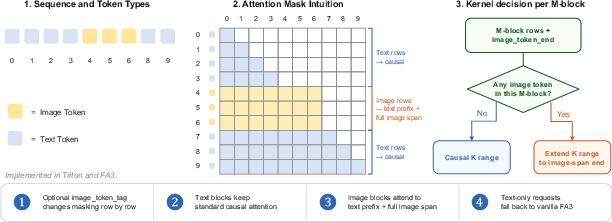
- Hybrid attention masking for multi-image contexts: kernel supports image-span attention expansion, but masking policies for multiple images, interleaved spans, and long-context scenarios (sequence length up to 32,768) are not detailed or benchmarked for correctness and speed.
- High-resolution scalability: generation up to is supported, yet no results on or beyond; memory scaling, KV cache pressure, and quality retention at extreme resolutions remain unexplored.
- Generalization to video and audio: the architecture unifies pixels and words but does not address temporal visual tokens (video) or additional modalities (audio), nor propose extensions of Native RoPE or MoT routing to spatiotemporal streams.
- Comparative evaluation gaps: claims of “top-tier” understanding and strong generation lack comprehensive quantitative benchmarks (e.g., MMMU, DocVQA, ChartQA, GenEval, TIFA, HRS/FID/CLIPScore) and apples-to-apples comparisons with latent diffusion (e.g., SDXL, Flux), discrete unified models, and continuous pixel-space baselines.
- Data pipeline fidelity: VLM-based captioning and CLIP-ratio re-captioning may propagate errors; no audit of caption correctness, semantic coverage, or impact on downstream alignment and hallucination in text-rich scenes.
- Aspect ratio handling: dynamic resolution warmup uses a “difficulty” function but does not formalize or validate its mapping; no study of performance across diverse aspect ratios, especially for document/infographic layouts.
- CFG renormalization: global renormalization is mentioned without details; no ablations on renorm strategies or impact on guidance stability and color shifts in high CFG regimes.
- Editing backward simulation with ground truth: for DMD2, backward simulation uses ground-truth images in editing/interleaved training; unclear how this generalizes to open-ended editing without references, and whether it introduces overfitting to specific edit distributions.
- Token routing explainability: the MoT’s dynamic routing “by token type” is not analyzed for error cases (e.g., misclassification of noise vs. clean tokens) or its sensitivity to mixed content (e.g., partially masked images, overlays).
- Optimization stability: EMA ratios, gradient clipping, and weight decay are specified, but there is no study of training instabilities (e.g., mode collapse in MoE, exploding norms in pixel-space flow) and mitigations (e.g., adaptive loss weighting, orthogonal regularization).
- Compute and cost transparency: no disclosures of training hardware, compute budgets, energy, carbon footprint, or efficiency comparisons with latent-space methods—limits practical reproducibility and sustainability assessment.
- Robustness to distribution shifts: no evaluation under corruptions (noise, blur), adversarial perturbations, or domain shifts (synthetic→natural, documents→photos) for both understanding and generation tasks.
- Layout and structure metrics: for interleaved generation (posters, resumes, infographics), there are no structural metrics (e.g., alignment error, text box detection F1, element overlap rates) to verify layout correctness and consistency.
- Safety in generation (policy compliance): beyond data filtering, no red-teaming or policy audits on prompt adherence and content safety in synthesis/editing (e.g., harmful content, privacy risks).
- Chain-of-thought (“think patterns”) in generation: claims of working “with or without think patterns” are unsubstantiated; no methodology for generating/verifying visual CoT or its impact on creativity, coherence, and factuality.
- Multilingual understanding and generation: beyond English/Chinese, language coverage and performance across scripts, fonts, bidirectionality (RTL), and complex ligatures are not explored.
- Long-context behavior: sequence length up to 32,768 is supported, but no evaluation of degradation, attention sparsity strategies, or retrieval-augmented generation for very long interleaved documents.
Practical Applications
Below is a concise, application-focused synthesis of the paper’s practical implications. It prioritizes concrete use cases, sectors, potential tools/workflows, and feasibility notes.
Immediate Applications
- Unified visual content authoring assistant for marketing, design, and media
- Sectors: media, advertising, design software
- What: Generate and iteratively edit posters, infographics, slides, comics, resumes, and visual stories with accurate text rendering and style following. Supports interleaved image–text generation for end-to-end layouts.
- Tools/workflows: Figma/Canva/PowerPoint plugins; brand-style templates driven by prompts; prompt-to-presentation pipelines.
- Assumptions/dependencies: Requires GPU-backed image generation (distilled to ~8 NFEs for speed); occasional grid artifacts from patch MLP decoding may need mitigation; brand-specific RL or fine-tuning to ensure style consistency.
- Enterprise document AI and infographic understanding
- Sectors: finance, legal, enterprise IT, knowledge management
- What: Parse text-rich documents (reports, forms, statements), extract structure via OCR-like capabilities, summarize or convert into visuals, and round-trip to improved infographics.
- Tools/workflows: Document-to-dashboard pipelines; auto-generated executive summaries with annotated visuals; QA bots that read complex PDFs and produce charts.
- Assumptions/dependencies: Domain adaptation and QA are needed to avoid hallucinations; privacy and compliance controls over input content.
- E-commerce product image pipelines with accurate text overlays
- Sectors: retail, marketplaces
- What: Generate and edit product hero images, lifestyle composites, and promotional banners with legible, on-brand text (sizes, prices, taglines).
- Tools/workflows: Shopify/BigCommerce integrations; batch prompt-to-campaign workflows; A/B tested creative variants.
- Assumptions/dependencies: Style-following RL works best when coupled with brand exemplars; human review for compliance and claims.
- Customer support and how-to content generation
- Sectors: consumer electronics, SaaS, automotive
- What: Create step-by-step illustrated troubleshooting guides and manuals from text prompts; interleaved visuals + instructions for user education.
- Tools/workflows: Help-center content pipelines; Chat-based assistants that output images inline; localization-ready templates.
- Assumptions/dependencies: Accuracy requires domain-curated prompts and review; multilingual performance beyond EN/ZH for text-in-image may require additional tuning.
- UI automation and RPA copilots that “see” screens
- Sectors: enterprise automation, IT operations
- What: Screen-reading and basic decision-making agents that interpret UI screenshots and perform click/keystroke sequences; annotate UI flows.
- Tools/workflows: Screenshot-to-action scripts; visual QA of forms and dashboards; generating annotated SOPs from screen flows.
- Assumptions/dependencies: While VLA is promising, stick to deterministic, well-scoped tasks; tool-use integrations and guardrails needed.
- Newsrooms and data journalism explainers
- Sectors: media, education
- What: Turn articles or briefs into graphics-rich explainers, posters, and social cards with consistent styles and correct labels.
- Tools/workflows: Copy-to-explainer pipelines; editorial approval queues; templated visual narratives for recurring beats.
- Assumptions/dependencies: Fact-checking and editorial review remain essential; reliance on text-to-image guidance settings for alignment.
- Education content authoring
- Sectors: K-12, higher ed, corporate L&D
- What: Generate worksheets, illustrated guides, and slide decks with diagrams and embedded text; create multi-step visual explanations.
- Tools/workflows: LMS integrations; prompt libraries per standard/curriculum; teacher-in-the-loop editing.
- Assumptions/dependencies: Pedagogical validity and accessibility review; multilingual content requires additional training data.
- Brand governance and style enforcement
- Sectors: enterprise marketing, agencies
- What: Enforce brand styles (color, typography, composition) via style-following RL and prompts; produce coherent campaigns across assets.
- Tools/workflows: Brand “style packs” and reward models; approval workflows; asset lineage tracking.
- Assumptions/dependencies: Style judge quality and training data breadth; potential need for custom rewards and fine-tuning.
- Synthetic data generation for training and evaluation
- Sectors: AI/ML R&D, QA/testing
- What: Produce controlled, text-rich synthetic images to stress-test OCR, layout understanding, and VQA pipelines; generate edge cases.
- Tools/workflows: Prompt banks with difficulty controls; dataset balancing by category and attributes; continuous evaluation loops.
- Assumptions/dependencies: Risk of bias amplification; ensure diversity and fairness; use strict deduplication and quality filters (as in paper’s pipeline).
- Systems engineering: disaggregated serving for mixed workloads
- Sectors: cloud platforms, MLOps, inference providers
- What: Adopt separate but coordinated engines for understanding (LightLLM) and generation (LightX2V) to optimize GPU utilization and scale text/image traffic independently.
- Tools/workflows: TP for LLM path; CFG/sequence parallelism for image path; pinned shared memory exchanges; auto-scaling by modality.
- Assumptions/dependencies: Integration effort; GPU orchestration; monitoring across two services; benefits strongest at scale.
- Kernel-level acceleration for multimodal prefill
- Sectors: AI infrastructure, compiler/tooling
- What: Integrate the hybrid attention kernel (Triton or FlashAttention3 variant) to accelerate interleaved text-image prefill while preserving text causal fast paths.
- Tools/workflows: Drop-in backend updates for existing VLM serving stacks; benchmarking and regression testing.
- Assumptions/dependencies: GPU/driver compatibility; careful kernel validation for correctness.
- Research and teaching: reproducible unified modeling
- Sectors: academia, applied research labs
- What: Use the released code/models/training recipes to study pixel-space flow matching, dynamic noise scaling, MoT routing, CFG distillation, and RL reward designs for text-in-image.
- Tools/workflows: Ablation studies; course modules and lab assignments; building lightweight replicas for specialized domains.
- Assumptions/dependencies: Compute budget for high-res training; data licensing; adherence to safety filters.
- Accessibility-oriented visual design
- Sectors: public sector, NGOs, product UX
- What: Generate high-contrast, legible graphics and signage with correct text; transform complex information into accessible visuals.
- Tools/workflows: Templates that meet readability/contrast standards; QA with OCR-based reward checks; localization-ready variants.
- Assumptions/dependencies: Human-in-the-loop accessibility checks; alignment with WCAG and local standards.
Long-Term Applications
- Vision–Language–Action (VLA) agents for robotics and automation
- Sectors: manufacturing, logistics, home robotics
- What: Unified perception, reasoning, and action planning from pixels and language in a single backbone; task execution without modality adapters.
- Tools/workflows: Policy learning over screen/real images; multi-step plans from interleaved instructions; closed-loop control.
- Assumptions/dependencies: Robust action datasets and simulators; latency reductions; safety certification and fail-safes.
- World-model-driven planning and simulation
- Sectors: gaming, autonomous systems, operations research
- What: Learn predictive visual-linguistic world models for imagination-based planning and counterfactual reasoning (e.g., “what if” scenario visuals).
- Tools/workflows: Simulation loops coupled with interleaved generation; policy evaluation in synthetic environments.
- Assumptions/dependencies: Accurate long-horizon modeling; reliable grounding; compute for large-scale training.
- General-purpose multimodal software agents
- Sectors: productivity software, enterprise IT
- What: Agents that read dashboards, generate reports with visuals, and call tools/APIs to act, all within one unified model.
- Tools/workflows: Function-calling interfaces tied to visual context; governance layers for approvals; audit trails.
- Assumptions/dependencies: Tool ecosystem integration; rigorous eval frameworks for safety and utility; continual learning.
- Real-time AR/VR content understanding and generation
- Sectors: XR, retail, entertainment, training
- What: On-device or edge-assisted systems that overlay generated visuals and instructions on live scenes.
- Tools/workflows: Low-latency pipelines; streaming interleaved image–text; device-specific optimizations (further NFE reduction).
- Assumptions/dependencies: Hardware acceleration; power/latency constraints; strong tracking and safety layers.
- Clinical and scientific communication copilots
- Sectors: healthcare, biotech, scientific publishing
- What: Produce accurate, text-rich diagrams (e.g., patient education leaflets, scientific figures) and comprehend dense charts.
- Tools/workflows: Template-driven generation with strict medical/scientific validation; provenance tracking.
- Assumptions/dependencies: Regulatory approval; medical-grade QA; domain-specific training and guardrails.
- Legal and finance analytics with visual explainability
- Sectors: legal tech, investment research, audit
- What: Extract and visualize obligations, risks, or KPIs from contracts and filings; generate annotated, compliant visuals.
- Tools/workflows: Ingestion-to-visual brief pipelines; standardized annotation layers; audit/compliance review.
- Assumptions/dependencies: High accuracy requirements; confidentiality protections; continuous evaluation.
- Personalized education with curriculum-level orchestration
- Sectors: EdTech
- What: Multi-lesson plans with interleaved visual materials, assessments, and adaptive hints; consistent style and readability.
- Tools/workflows: Teacher dashboards with content variants; analytics on learner performance to adapt visuals and text.
- Assumptions/dependencies: Strong pedagogy integration; bias mitigation; diverse language support.
- Secure provenance and watermarking for unified generators
- Sectors: policy, platforms, content authentication
- What: Native provenance signals/watermarks embedded during generation to support platform policies and regulatory compliance.
- Tools/workflows: Standardized watermarks; registry services; detection APIs for platforms and auditors.
- Assumptions/dependencies: Industry standards adoption; robustness to transformations; legal frameworks.
- Multilingual expansion and localization at scale
- Sectors: global marketing, public sector communication
- What: High-quality text-in-image generation across many languages and scripts (beyond EN/ZH), keeping layout and legibility.
- Tools/workflows: Language-specific OCR rewards; script-aware typography models; locale packs for styles.
- Assumptions/dependencies: Training data coverage; font/typography handling; locale QA.
- Safety-first multimodal moderation and guardrails
- Sectors: platforms, enterprise governance
- What: Unified detection and prevention of unsafe content during both understanding and generation; policy-conditional outputs.
- Tools/workflows: Multimodal safety classifiers; RL with safety rewards; incident response and logging.
- Assumptions/dependencies: Continuous policy updates; adversarial robustness; explainability requirements.
Notes on feasibility and dependencies across applications
- Compute and latency: The paper’s DMD2 distillation reduces image generation to ~8 NFEs; reported per-step latency (~0.415 s on 5090 for 2048×2048) implies ~3–4 s/image at high resolution; further optimization may be needed for interactive UX or on-device scenarios.
- Quality factors: Text rendering has been improved via RL but is sensitive to guidance scales and decoding details; patch-level decoding can yield grid artifacts (authors suggest PixelShuffle-based decoding as a future fix).
- Data and safety: Training pipelines apply extensive filtering; downstream adopters should replicate safety filters and perform domain-specific alignment to mitigate hallucinations and bias.
- Integration: The disaggregated serving architecture (LightLLM + LightX2V) offers immediate operational benefits but adds integration complexity; it pays off most at scale or under mixed text/image workloads.
- Legal/compliance: For regulated sectors (health, finance, public sector), human oversight and auditability are essential; additional domain RL/SFT and provenance mechanisms are recommended.
Glossary
- AdamW optimizer: An adaptive weight-decay variant of Adam used for training deep models. "G is optimized with AdamW optimizer at a learning rate of "
- Aesthetic Reward: A learned signal assessing image aesthetic quality and preference alignment. "Aesthetic Reward. For aesthetic and preference alignment, we use Human Preference Score (HPSv3)~\cite{ma2025hpsv3widespectrumhumanpreference} as an aesthetic quality reward."
- Agentic decision-making: The capability of models to make autonomous, goal-directed decisions based on multimodal inputs. "knowledge reasoning, agentic decision-making, and spatial intelligence."
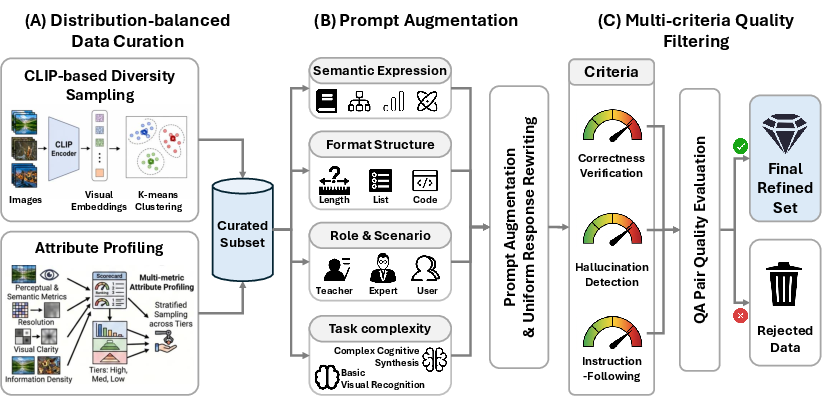
- Attribute profiling: An analysis step that scores samples along perceptual/semantic dimensions for balanced dataset selection. "This is followed by attribute profiling, which evaluates each sample along perceptual and semantic dimensions"
- Autoregressive cross-entropy: The standard next-token prediction objective for language modeling. "jointly couples autoregressive cross-entropy for language with pixel-space flow matching for vision;"
- Bidirectional attention: An attention scheme where tokens can attend to each other in both directions within a block. "Image tokens within the same block attend bidirectionally to one another"
- CFG Parallelism: A serving strategy that parallelizes model runs for different guidance conditions. "diffusion-oriented strategies, e.g., Classifier-Free Guidance Parallelism (CFG Parallelism)"
- CFG renormalization: A normalization strategy applied when using classifier-free guidance to stabilize generation. "Note that we apply a timestep shift of $3.0$ and global CFG renormalization strategies."
- Classifier-Free Guidance: A sampling technique that combines conditional and unconditional predictions to steer generation. "Classifier-Free Guidance."
- CLIP-ratio-balanced re-captioning: Re-captioning data while balancing scores from CLIP to improve alignment distribution. "and CLIP-ratio-balanced re-captioning to ensure balanced alignment across the corpus."
- Convolutional stride: The step size of convolution filters controlling spatial downsampling. "The convolutional strides are set to 16 and 2"
- Cosine learning-rate schedule: A learning rate schedule that follows a cosine decay pattern. "using a cosine learning-rate schedule that decays from to ."
- Cross-entropy (CE): A loss measuring divergence between predicted and target token distributions. "Loss weight (CE : MSE)"
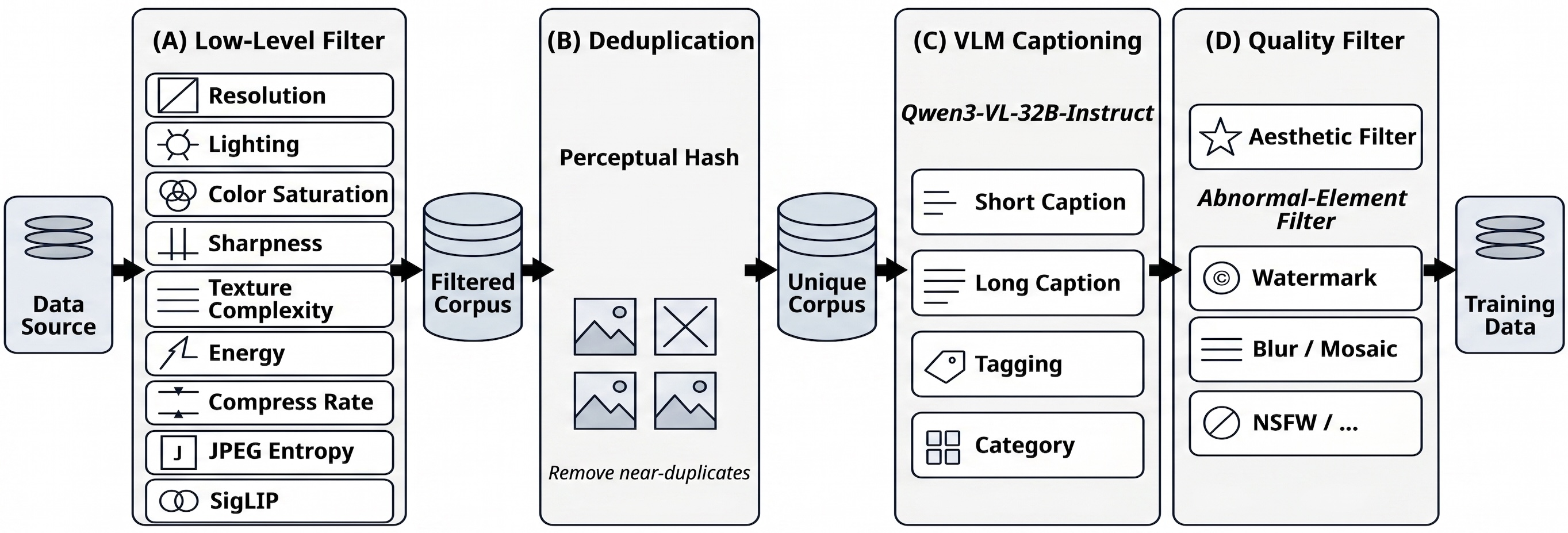
- Deduplication: The process of removing duplicate entries to clean datasets. "cross-source deduplication"
- Denoiser: The network component that predicts clean signal or score from noisy inputs in generative processes. "we explicitly feed it to the denoiser."
- Distribution Matching Distillation (DMD2): A distillation method that aligns a student generator’s distribution with a teacher’s via score matching. "employs Distribution Matching Distillation~\cite{dmd2} to enhance efficiency."
- Distribution-Balanced Sampling: A selection method that enforces balanced coverage across data distributions. "(i) Distribution-Balanced Sampling."
- Euler solver: A numerical ODE integrator used for simulation during generation. "Backward simulation employs an Euler solver"
- Exponential Moving Average (EMA): A running average of parameters used to stabilize training and evaluation. "EMA ratio"
- FlashAttention3: A high-performance attention kernel optimizing memory and throughput. "a modified FlashAttention3 backend."
- Flow matching: A generative training objective aligning model velocity with the true probability flow in data space. "pixel-space flow matching"
- Flow-GRPO: A reinforcement learning method tailored for flow-based generative models. "following Flow-GRPO~\cite{liu2025flow}"
- Function evaluations (NFE): The number of model calls required by a sampler to synthesize an image. "reduce the number of function evaluations (NFE) for image synthesis from 100 to 8"
- GELU: Gaussian Error Linear Unit, a smooth activation function for neural networks. "with GELU activation"
- Guidance scale: The scalar controlling strength of conditional guidance during generation. "with a guidance scale of 4.0"
- Human Preference Score (HPSv3): A learned scorer predicting human preference for image–text pairs. "Human Preference Score (HPSv3)~\cite{ma2025hpsv3widespectrumhumanpreference}"
- Hybrid Attention Kernel: A serving kernel implementing mixed causal/bidirectional attention for multimodal prefill. "Hybrid Attention Kernel. A key systems challenge in unified multimodal prefill is the hybrid attention pattern"
- Intersection-over-Union (IoU): A metric measuring overlap between predicted and ground-truth sets (or regions). "The reward is based on Intersection-over-Union (IoU):"
- K-means: A clustering algorithm used here to diversify sampling across visual embedding clusters. "CLIP-based diversity sampling clusters visual embeddings via -means"
- Key-value cache: Stored past attention keys/values used to speed up autoregressive decoding. "the generation-stage key-value cache is provided by the understanding module"
- KL coefficient: The weight on a Kullback–Leibler divergence term in RL-style optimization. "with a learning rate of and a KL coefficient ."
- Logit-normal t-sampler: A stochastic time-sampling scheme drawing t from a logit-normal distribution. " in the logit-normal -sampler"
- Mixture-of-Experts (MoE): An architecture routing tokens to specialized expert sub-networks. "mixture-of-experts (30B-A3B)"
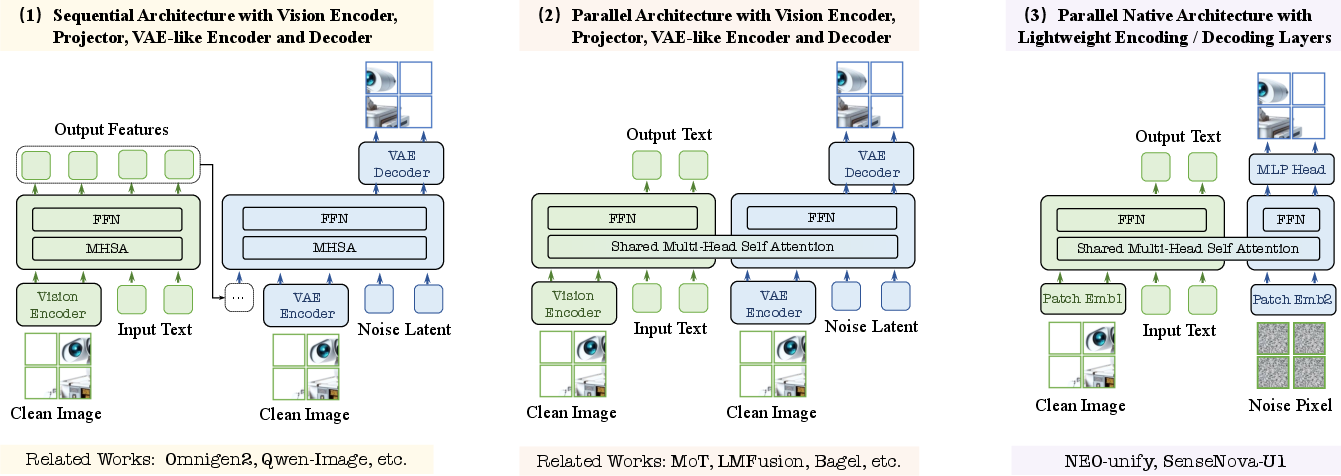
- Mixture-of-Transformers (MoT): A unified architecture with separate understanding/generation transformer streams. "a native Mixture-of-Transformers (MoT) main architecture."
- MoE balance loss: A regularizer encouraging balanced expert utilization in MoE training. "we apply a MoE balance loss coefficient of "
- Native RoPE (Rotary Position Embedding): A position encoding that rotates queries/keys to encode relative positions across time and space. "Its native rotary position embedding (Native RoPE) unifies temporal and spatial encoding"
- Near-lossless visual interface: A visual tokenization strategy that preserves fine pixel details with minimal compression. "Near-Lossless Visual Interface"
- NEO-unify: A native end-to-end multimodal framework that operates directly on pixels and words. "NEO-unify~\cite{sensenova2026neounify}"
- Noise-scale conditioning: Conditioning the denoiser on the resolution-adaptive noise level. "Noise-Scale Conditioning."
- Ordinary Differential Equation (ODE): A continuous-time formulation whose integration corresponds to the generative process. "initializes the flow ordinary differential equation (ODE) at inference."
- PaddleOCR: An OCR toolkit used to compute text-rendering rewards. "we use PaddleOCR~\cite{cui2025paddleocr30technicalreport} to extract text"
- Patch Decoding Layer: The module that maps token representations back to pixel patches for generation. "Patch Decoding Layer."
- Patch Encoding Layer: The module that converts images into visual token sequences. "Patch Encoding Layer."
- Pinned shared memory: Host memory locked for faster GPU–CPU transfer and inter-process communication. "through pinned shared memory"
- Pixel–word primitive: A modeling setup that treats pixels and words as native inputs within a unified sequence. "exploring a native pixel–word primitive"
- PixelShuffle: A sub-pixel upsampling operation to improve patch-wise generation continuity. "replace the MLP head with PixelShuffle modules followed by two convolutional layers"
- Rectified-flow interpolant: A linear path between noise and data used for flow-matching training. "along the rectified-flow interpolant"
- Reinforcement learning (RL): Optimization via reward feedback to improve generation quality. "leverages reinforcement learning (RL) following Flow-GRPO"
- Rotary position embedding (RoPE): A positional encoding method rotating Q/K vectors to encode relative positions. "Its native rotary position embedding (Native RoPE)"
- Sequence Parallelism (SP): A distributed inference/training strategy splitting sequences across devices. "or Sequence Parallelism (SP)"
- Signal-to-noise ratio (SNR): The relative power of signal versus noise affecting denoising difficulty. "ensuring a consistent SNR distribution for flow matching."
- Sinusoidal MLP embedder: An MLP that encodes scalars via sinusoidal features for conditioning. "encode it using a dedicated sinusoidal MLP embedder"
- Sinusoidal positional encoding: A deterministic positional encoding using sinusoids over token indices. "and 2D sinusoidal positional encoding."
- Supervised Fine-Tuning (SFT): Final instruction-following fine-tuning on curated data. "The final SFT corpus is organized along fine-grained, capability-atomic dimensions"
- Tensor Parallelism (TP): A model-parallel strategy that shards tensor operations across GPUs. "the understanding engine uses LLM-oriented Tensor Parallelism (TP)"
- Timestep shift: A constant offset applied to sampling timesteps to improve stability/quality. "We apply a timestep shift of $3.0$"
- Top-k routing: Selecting the top-k experts per token in MoE for computation. "A top- routing strategy activates 8 experts per token"
- Variational Autoencoder (VAE): A latent-variable generative model used for compressed image representations. "variational autoencoders (VAEs)"
- Vision encoder (VE): A separate visual backbone that produces image features for VLMs. "vision encoders (VEs)"
- Vision–language–action (VLA): Tasks or settings requiring perception, reasoning, and action across modalities. "performing strongly in vision–language–action (VLA)"
- World model (WM): A learned model that predicts or simulates aspects of the environment. "and world model (WM) scenarios."
- X2I (any-to-image): Generation tasks that map arbitrary conditions (e.g., text, image) to images. "any-to-image (X2I) synthesis"
- v-loss (velocity loss): The MSE loss on predicted probability-flow velocity used in flow matching. "with -predict and -loss"
Collections
Sign up for free to add this paper to one or more collections.

