Laguna M.1/XS.2 Technical Report
Abstract: We present Laguna M.1 and Laguna XS.2, two Mixture-of-Experts foundation models built for long-horizon, agentic coding: M.1 has $225.8$B total parameters ($23.4$B activated per token) and XS.2 has $33.4$B total ($3$B activated). Both models were trained from scratch end-to-end inside the same internal system that we refer to as our Model Factory: a tightly-integrated stack of versioned data, training, evaluation, and inference components that turn model development into an industrial process. We describe the principles and design choices of the Model Factory and also detail the end-to-end training process of our models, throughout pre-training data and architecture, post-training stages, evaluation, and quantization. On agentic software engineering and terminal benchmarks (SWE-bench Verified, SWE-bench Multilingual, SWE-Bench Pro, and Terminal-Bench 2.0) M.1 and XS.2 are competitive with state-of-the-art open models in their respective weight classes. Laguna XS.2 weights are released under Apache~2.0 at https://huggingface.co/collections/poolside/laguna-xs2.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces two new AI coding models, called Laguna M.1 and Laguna XS.2. They’re built to handle long, complicated coding tasks step by step, like fixing real software bugs or using a computer terminal to complete multi-step instructions. The authors also explain how they built these models so quickly and reliably using an “AI Model Factory” — a streamlined, engineering-first process that turns model-building into an organized assembly line rather than a one-off craft project.
- Laguna M.1: a very large “Mixture-of-Experts” model (225.8 billion total parameters; about 23.4 billion active per input token).
- Laguna XS.2: a smaller, faster version (33.4 billion total; about 3 billion active per token), with weights released openly under the Apache 2.0 license.
Both models aim to be strong “agentic coders” — meaning they can plan, reason, take actions, and write or run code over many steps, not just answer short questions.
The big questions the paper asks
- How can we build AI models that are especially good at long, multi-step coding tasks?
- Can a “Model Factory” (a carefully engineered, reusable pipeline) make model-building faster, safer, and more reliable?
- What training recipe, data mix, and model design choices help these models learn better and stay stable during training?
- Can the resulting models compete with other state-of-the-art models on tough, real-world coding and terminal benchmarks?
- Can we make a smaller open model (XS.2) that still performs strongly and runs on limited hardware?
How they built the models (in everyday language)
Think of the model as a school with many specialist teachers:
- Mixture-of-Experts (MoE): Instead of one giant teacher handling everything, the model has many “experts” trained on different patterns. For each word or token, a “router” decides which few experts should handle it. This keeps the model smart but efficient — only a small part of the whole wakes up for each token.
- Long memory for long tasks: Coding often needs looking back far into earlier instructions. These models are trained to handle very long contexts (eventually up to 256,000 tokens), like remembering a huge conversation history or looking through many files at once.
- Attention as reading strategy:
- Global attention: occasionally taking a “bird’s-eye view” across the whole text.
- Sliding window attention: focusing on a moving window, like reading a book with a magnifying glass that slides along the page.
- They mix these to balance speed and understanding.
- Training recipe: They use a “warm up — cruise — cool down” learning rate schedule (Warmup-Stable-Decay). It’s like learning to drive: start gentle, drive steadily, then slow down carefully so you don’t spin out.
- Massive data, but carefully curated: Over 30 trillion tokens from:
- Web pages (after smart quality ranking to keep useful variety without keeping junk)
- Code repositories
- Educational and academic text
- Synthetic data (AI-generated rephrasings and structured examples), which helps reduce repetition and fill gaps
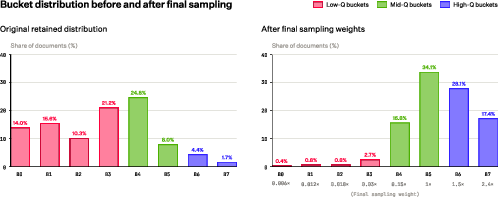
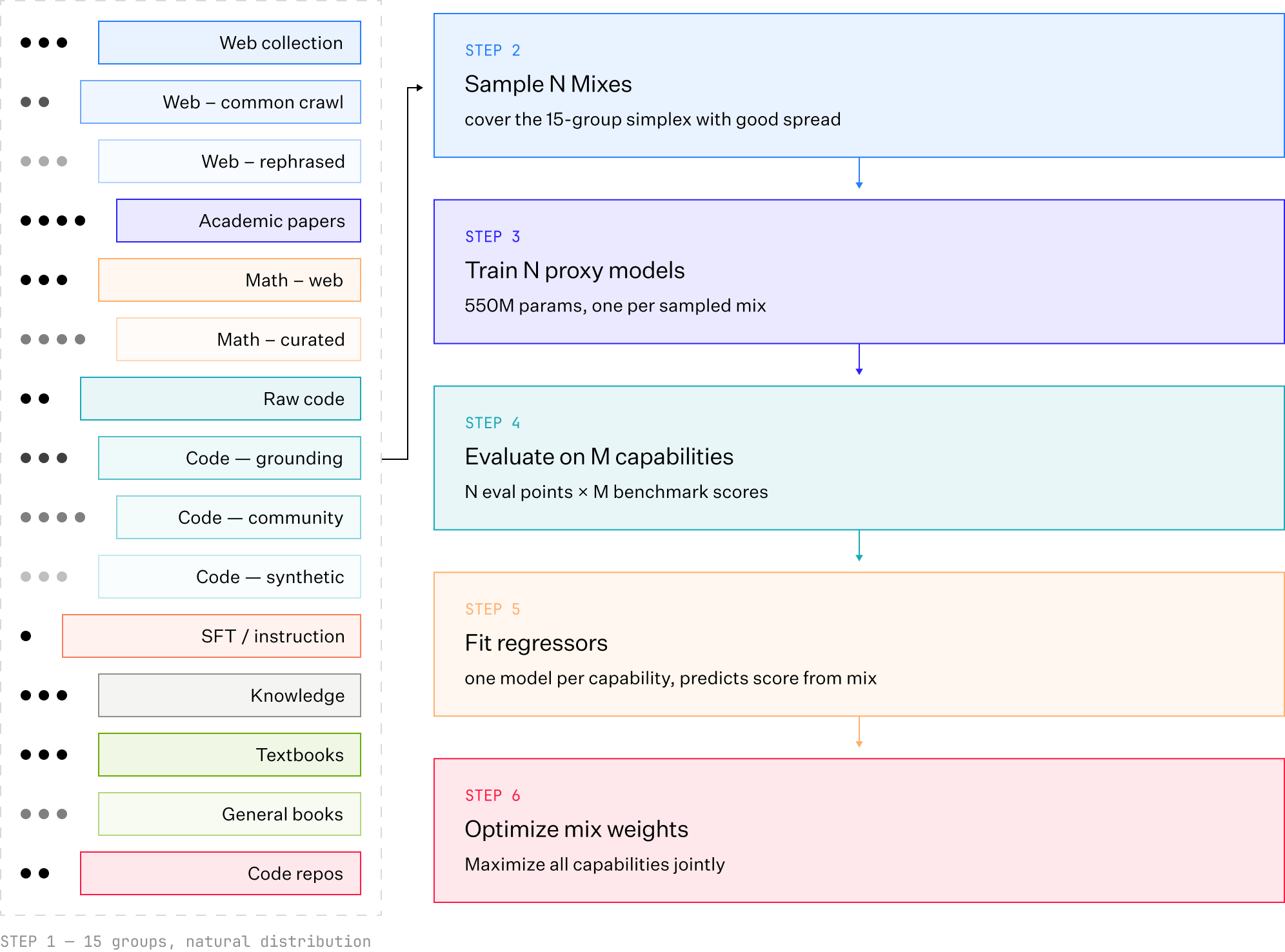
- Ranking over filtering: Instead of throwing away huge amounts of imperfect web data, they score documents along multiple dimensions (like “how useful,” “how informative”) and rank them. This keeps valuable diversity while still removing obvious noise.
- AutoMixer: Like a chef auto-tuning a recipe, this tool adjusts the data mixture so the model gets the most useful “diet” for long training.
- Model Factory: Imagine building models on an assembly line where:
- Every experiment is written as code and versioned.
- Every input, run, and result is tracked, so you can trace exactly how a model was made.
- A custom job scheduler launches training quickly without disrupting other jobs.
- Automatic checks catch silent hardware errors by comparing “fingerprints” of model copies.
- This setup let them train and release the smaller XS.2 model only five weeks after M.1 finished pre-training.
- Making it run on smaller machines: They “quantize” the model — storing and computing with fewer bits like FP8 or INT4 where possible — so the XS.2 model can run on devices with less memory, while keeping quality high.
- Stability lessons learned:
- They fixed an issue where some experts “collapsed” (got overloaded) by tuning the optimizer and routing.
- They raised the math precision in one delicate spot to prevent instability as numbers grew.
- They prevented “padding” (blank tokens) from messing with the expert router.
What they found and why it matters
The authors tested M.1 and XS.2 on tough, realistic benchmarks where the model must plan and write code or operate a terminal:
- SWE-bench Verified, SWE-bench Multilingual, SWE-bench Pro: Tests where models fix real software issues across different projects and languages.
- Terminal-Bench 2.0: Tests where models complete tasks in a command-line environment.
Main takeaways:
- Both models are competitive with the best open models of similar size on these agentic coding tasks.
- The Model Factory approach works: XS.2 was trained and released fast, reusing lessons and tooling from M.1.
- The long-context strategy, improved attention, and data “recipe” made the models better at multi-step, real-world coding tasks.
- XS.2 is open-weight under Apache 2.0, making it useful for the community and easier to deploy widely.
- Quantization recipes let XS.2 run on lower-VRAM hardware without a big quality drop.
Why it matters:
- Strong agentic coding models can help developers fix bugs faster, understand large codebases, and automate repetitive tasks.
- An industrialized, traceable build process reduces mistakes, speeds up research, and makes results more reliable.
- Open release of XS.2 encourages collaboration and practical adoption.
What this could mean going forward
- Better coding assistants: These models can act more like reliable teammates that plan, write, run, and check code over many steps, not just produce a snippet and stop.
- General problem solving: The authors see coding as a gateway to broader reasoning, because code lets you clearly express steps and verify if an answer works. Improving agentic coding could push forward many kinds of knowledge work.
- Faster progress with fewer surprises: The Model Factory’s “experiment-as-code,” automatic tracking, tough reliability checks, and fast scheduling can help teams scale research safely and quickly.
- Wider access: Open weights plus quantization mean more developers, startups, and researchers can experiment, customize, and deploy agentic coding models on their own hardware.
- Better data practices: Ranking instead of over-filtering keeps the long-tail variety that large models need for long training and broad skills, while still removing obvious junk and harmful content.
In short: The paper shows how to build strong, long-context coding models efficiently and reliably, and it shares a repeatable process that others can adopt. The open XS.2 release makes these ideas immediately useful to the community.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or left unexplored in the paper, stated concretely so that future work can address them.
- Reproducibility of M.1: Model weights, exact training configs, and seeds for Laguna M.1 are not released, preventing independent replication of its results and stability claims.
- Closed Model Factory components: Critical infrastructure (scheduler, Titan, Blender, Hive, evaluation harness) is proprietary; no open implementations or APIs are provided to reproduce training, data mixing, or evaluations.
- Pre-training mixture transparency: Exact per-source proportions (web/code/synthetic), per-stage curricula, and how >30T tokens were allocated over time are omitted, hindering controlled re-training.
- AutoMixer specifics: The automated data-mixture mechanism lacks a formal description (objective, optimization method, feedback signals from evals, update cadence, convergence criteria, guardrails against overfitting to benchmarks).
- Web-data quality scoring: The composite scoring recipe (feature set, weights, PCA details, bucket boundaries, calibration data) and model checkpoints (e.g., Propella versions) are not released, limiting reproducibility and external validation.
- Data sources and licenses: Concrete datasets, domain coverage, and licensing/compliance status (copyright, terms of use, consent) are not specified; unclear if any sources impose downstream restrictions.
- Multilingual capability vs English filtering: Web data is filtered to English, yet results are reported on multilingual SWE-bench; the non-English training signal sources and their proportions are not explained.
- Contamination checks: No analysis of pre-training/eval overlap (SWE-bench, Terminal-Bench, or coding repositories), dedup scope (document-level, repo-level, function-level), or benchmark-taint mitigation is provided.
- Memorization and privacy: No memorization audits (e.g., canary exposure, membership inference), PII filtering efficacy, or privacy safeguards are described for high-recall web data.
- Synthetic data provenance: Teacher models (names/versions), prompts, sampling parameters (T, top-p), and per-pipeline token contributions are not reported, nor are safeguards against feedback loops or teacher/model leakage.
- Synthetic validation and decontamination: Criteria and tooling for correctness checks, adversarial filtering, and benchmark decontamination of synthetic corpora are unspecified.
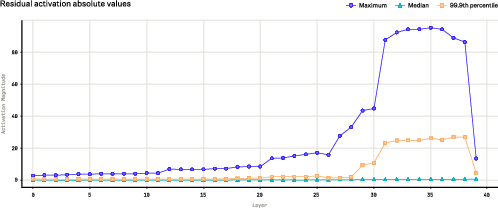
- Stability remedies generality: FP32 LM-head input-gradient all-reduce fixed M.1 instabilities, but it’s unclear whether similar precision fixes are needed elsewhere, how robust this is across architectures, or how it compares to z-loss/mean-centering.
- Muon optimizer hyperparameters: Key settings (momentum/decay coefficients, beta schedules, Newton–Schulz iteration counts, damping) and ablations vs AdamW are missing; benefits vs costs across scales and interconnects are not quantified.
- Expert-routing choices: The rationale and sensitivity for “8 of 256 experts + shared expert with 2.5× modulation,” capacity/overflow behavior, token dropping, and impact on specialization and load balancing are not analyzed.
- Router design alternatives: No ablations comparing sigmoid vs softmax gates, score-normalization strategies, or auxiliary loss configurations (weights, temperature), nor evidence on router-induced instability.
- Padding and special tokens: Skipping padding tokens in routing improved stability, but the quantitative impact on utilization, latency, and balance (and handling of BOS/SEP/CLS-like tokens) is not reported.
- Long-context efficacy: While contexts are extended to 128K (and 256K via RoPE scaling without training), no long-context benchmark results (e.g., RULER, LONG-BENCH), distance-wise degradation, or stability diagnostics are provided.
- RoPE/YaRN design choices: Applying YaRN only to global-attention layers and doubling RoPE for 256K lacks justification or ablation; the impact on retrieval at different depths and on SWA/GA interplay remains unquantified.
- Quantization trade-offs: XS.2 INT4/FP8/NVFP4 recipes lack accuracy-vs-latency/throughput curves, calibration-set details, per-layer bit allocation strategies, and task-wise degradation—especially for agentic coding; nothing is reported for M.1 quantization.
- Compute and footprint: Training FLOPs, wall-clock time, GPU-hours, utilization, energy consumption, and carbon footprint are not reported; scaling efficiency of MoE kernels (with and without communication overlap) is not quantified.
- Systems portability: NVLink/NVFP4-optimized kernels and fused all-to-all/GEMM methods are not evaluated on different hardware/fabrics; generality to A100/H100 or non-NVIDIA setups is unknown.
- Scheduler external validity: The custom scheduler’s performance (queueing latency, fairness, preemption overhead) isn’t benchmarked or released; applicability and reliability on other clusters are unclear.
- Evaluation rigor: Full evaluation protocol details (prompts, toolchain configs, environment versions, attempt budgets, search strategies, seed variance, statistical significance) are missing, limiting replicability and result comparability.
- Benchmark breadth: Results focus on agentic coding/terminal tasks; standard capability benchmarks (e.g., MMLU, GPQA, MATH, HumanEval/MBPP, reasoning suites) and general instruction-following quality are unreported.
- Post-training specifics: The imitation-learning and RL stages are referenced but lack concrete datasets, reward definitions, safety constraints, and ablations quantifying SFT vs RL gains and stability.
- Safety and misuse: No toxicity, bias, jailbreak, privacy, or insecure-code generation evaluations are reported; safety fine-tuning, red-teaming methods, and deployment safeguards are not described.
- Tokenizer training: The corpus, languages, and heuristics used to train the 100,352-BPE tokenizer—and their effect on code, non-English text, and bytes—are not documented.
- Data dedup strategy: Dedup granularity (fuzzy vs exact, across snapshots/repos/functions), thresholds, and measured repetition rates after all synthesis/rephrasing are not quantified.
- Expert specialization analysis: There is no interpretability on expert roles, domain specialization, routing stability over training, or correlation with data mixture shifts.
- Factory-to-user pipeline: How rapidly AutoMixer or agents adapt mixes from live evaluations, safeguards against overfitting/drift, and human-in-the-loop oversight are unspecified.
- Claims of competitiveness: The paper asserts competitiveness but does not report absolute scores in-text, confidence intervals, or compute-normalized comparisons to dense baselines with matched active parameters.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that draw directly from the paper’s released model (Laguna XS.2, Apache 2.0) and its engineering methods. Each item includes likely sectors, example tools/workflows, and feasibility notes.
- Bold, private-by-default coding copilot for enterprises (Software, Security)
- What: Deploy quantized Laguna XS.2 as an on‑prem coding assistant that reads entire repositories (long context, 128K–256K) and executes multi-step plans (agentic coding) to fix bugs, refactor, and modernize stacks.
- How: VS Code/JetBrains plugin; GitHub/GitLab app that files PRs; terminal agent to reproduce issues and run tests (SWE‑bench, Terminal‑Bench capabilities).
- Dependencies/assumptions: 1× mid‑range GPU with FP8/INT4/NVFP4 support (24–48 GB VRAM ideal for fast latency); robust sandboxing and CI tests; MoE‑capable inference stack; data privacy policies.
- CI/CD repair, dependency upgrades, and infra as code bots (Software, DevOps)
- What: Agents that diagnose failing builds, update dependencies, adjust Dockerfiles/K8s manifests, and open PRs with fix plans and validation logs.
- How: Integrate with CI (GitHub Actions/GitLab CI); terminal automation harness mirroring Terminal‑Bench; policy gates requiring green tests to merge.
- Dependencies/assumptions: Secure runner/sandbox; repository access controls; deterministic test suites; rollback plans.
- Repository-scale code review and security scanning (Software, Security)
- What: Use long context to perform cross-file audits (e.g., auth flows, secret management), detect insecure patterns, and propose patches.
- How: Pre-commit hooks and nightly scans; attach risk rationales and patch diffs to issues.
- Dependencies/assumptions: Access to large monorepos; secrets redaction; human-in-the-loop security review.
- Offline coding tutors and lab assistants (Education)
- What: Campus/lab-hosted XS.2 instances provide step-by-step code help, project planning, and automated rubric-based feedback without sending data to external services.
- How: LMS integration, IDE plugins, containerized sandboxes for auto‑grading.
- Dependencies/assumptions: Local GPU servers or powerful workstations; academic policies on AI assistance; curated prompts/rubrics.
- Legal/compliance document synthesis and redlining at scale (Policy, Legal, Enterprise Ops)
- What: With long context, summarize, compare, and redline large contracts/policies; generate implementation checklists for standards (e.g., SOC 2, ISO 27001).
- How: Document ingestion pipelines; task templates for gap analysis; export to ticketing systems.
- Dependencies/assumptions: Document access controls; defined policy templates; human legal oversight.
- Data curation via “rank-not-filter” for web and enterprise text (Data, Knowledge Management)
- What: Replace brittle rules with multi‑property quality scoring and bucketed sampling to preserve diversity while reducing noise (as in Propella + composite score).
- How: Run Propella or similar multi-property annotators; define sampling buckets and quotas; monitor mixture drift.
- Dependencies/assumptions: Availability of a multi‑property labeling model (Propella or equivalent); governance for PII/toxic content; storage and Spark‑like compute.
- Synthetic data generation pipelines for domain programs and docs (Software, Support, Education)
- What: Use modular synthesis pipelines (seed rephrasing and compositional distillation) to expand code exam items, support FAQs, or domain‑specific tasks.
- How: Build a “Hive”-style workflow with orchestrators, generators, judges, and validators; enforce quality filters and provenance metadata.
- Dependencies/assumptions: Strong base generators/judges; license‑compliant seeds; evals to detect leakage and bias.
- Training stability and efficiency best‑practices for LLM teams (AI/ML Engineering, Academia)
- What: Adopt concrete recipes to reduce crashes/divergence—FP32 all‑reduce for LM-head input gradients; skip routing for padding tokens; WSD schedule; LR scaling law; Moonlight-style Muon rescaling.
- How: Update training stacks (PyTorch/FSDP/TP/EP) with numerics guards; integrate hash checks for cross‑replica drift detection.
- Dependencies/assumptions: Access to training codebase; cluster/HPC ops buy‑in; reproducibility discipline.
- Reproducible “experiments-as-code” with lineage and automated orchestration (R&D, MLOps, Regulated industries)
- What: Implement a Model Factory‑style control plane using Dagster (assets + DAG lineage) to track data, training, evals, and deployments with unique run IDs.
- How: Single monorepo for configs and pipelines; enforce end‑to‑end asset registration; automated failure recovery and incident routing.
- Dependencies/assumptions: Dagster/Kubernetes/FoundationDB or equivalents; change management culture; shared infra budgets.
- Cluster productivity with per‑job preemption and fast placement (Cloud/HPC, MLOps)
- What: Adopt per‑job eviction, topology mirrors in a scalable KV store (e.g., FoundationDB), and sticky pod respawn to keep caches hot, cutting tail latency in job placement to sub‑minute.
- How: Extend/replace Volcano with a custom batch scheduler; observers to mirror K8s topology; fabric‑aware placement.
- Dependencies/assumptions: K8s expertise; Fabric/NVLink awareness; SRE resourcing; acceptance of scheduler changes.
- Low‑VRAM deployment via mixed‑precision quantization (Edge/On‑prem Software)
- What: Use the provided FP8/INT4/NVFP4 MoE layer quantization and FP8 KV cache to run on smaller GPUs or high‑end workstations.
- How: Integrate quantization-aware runtimes; benchmark latency–quality tradeoffs; deploy profile-based configs.
- Dependencies/assumptions: Hardware with FP8/NVFP4 support; compatible inference kernels for MoE; acceptable quality drop tolerance.
- Audit-ready lineage and integrity checks for model training (Policy, Governance, Safety)
- What: Use cross‑replica hash checks, reproducible asset DAGs, and checkpoint provenance to satisfy emerging audit requirements (e.g., EU AI Act transparency).
- How: Periodic hash verification across DDP replicas; artifact registries with lineage; controlled checkpoint distribution.
- Dependencies/assumptions: Cluster support for deterministic kernels; reliable object storage; compliance processes.
Long-Term Applications
These opportunities will benefit from further research, scaling, or ecosystem development before becoming widely practical.
- Autonomous software engineers for sustained projects (Software, DevOps)
- What: Multi-agent systems that plan and deliver multi‑week features across services—design docs, code, tests, migrations—using the paper’s agentic coding plus reproducible workflows.
- Path: Stronger task decomposition, long‑horizon memory, robust tooling integration, and formal verifiers.
- Dependencies/assumptions: Reliable sandbox orchestration; formal safety/guardrails; expanded evals beyond SWE‑bench.
- Sector-specialized agents that write and maintain operational code
- Healthcare: Generate/maintain HL7/FHIR adapters, ETL, cohort definitions. Dependencies: HIPAA/GDPR compliance, clinical validation, strict PHI handling.
- Finance: Risk/reporting pipeline updates, regulatory report generation, model validation scripts. Dependencies: Model risk governance, audit trails, segregation of duties.
- Energy: Grid simulation setup, optimization runs, telemetry parsers. Dependencies: Simulator APIs, fail‑safe operation, domain test suites.
- Robotics/Manufacturing: ROS nodes, PLC ladder logic/CODESYS modules, calibration procedures. Dependencies: Safety certification, hardware‑in‑the‑loop tests.
- Standardized data governance with compositional contribution scoring (Policy, Data Infrastructure)
- What: Sector/national data utilities that use multi‑property quality models + AutoMixer‑like allocation to ensure diversity, reduce repetition, and document provenance.
- Path: Open benchmarks for contribution scoring, governance frameworks, PII and takedown workflows.
- Dependencies/assumptions: Publicly available annotators; common schemas; legal clarity for web content.
- Generalized MoE training stacks with fused comm‑compute (AI/ML Tooling, Hardware)
- What: Incorporate fine‑grained NVLink dispatch/epilogue fusion into mainstream libraries to cut MoE overheads in training and inference.
- Path: Stable CUTLASS/CUDA kernels, cross‑GPU scheduling APIs, vendor support.
- Dependencies/assumptions: Kernel engineering; portability across GPU generations; upstream adoption.
- Adaptive AutoMixer for continuous data‑mix optimization (AI/ML Engineering)
- What: Automatically tune mixtures by feedback from evals and live‑task performance, reusing WSD‑phase checkpoints for quick cooldown trials.
- Path: Closed‑loop systems linking evals to data mix; causality‑aware controls to avoid overfitting.
- Dependencies/assumptions: Robust eval harnesses; monitoring; compute for frequent small‑scale trials.
- Newton–Schulz‑friendly optimizers as first‑class citizens (AI/ML Tooling, Hardware)
- What: Broad adoption of distributed Muon‑style optimizers with hardware‑aware scheduling and kernel support.
- Path: Framework integration (PyTorch/JAX), determinism controls, and autotuning.
- Dependencies/assumptions: Communication bandwidth, vendor kernel support, community familiarity.
- Policy-aligned provenance from token to source for right‑to‑erasure and audits (Policy, Compliance)
- What: Make token‑level lineage and data bucketing traceable for compliance (e.g., honoring deletion requests, sensitive-source audits).
- Path: Scalable mapping from training tokens to sources; retraining/adapter strategies for removals.
- Dependencies/assumptions: Data store retention; legal frameworks; retraining cost controls.
- On‑device, long‑context agents for consumer and field use (Edge, Mobile, Field Ops)
- What: Agents that run full project histories/logs (≥128K tokens) on laptops/tablets for offline development, diagnostics, or maintenance.
- Path: Further KV compression, memory‑efficient long‑attention, better quantization for MoE routing.
- Dependencies/assumptions: Hardware acceleration for FP8/NVFP4; efficient KV cache management; battery/perf constraints.
- Agentic research loops (“AI researchers that run the factory”) (Academia, Industrial R&D)
- What: Agents that design ablations, launch runs, analyze results, and update configs within a guarded Model Factory.
- Path: Stronger tooling APIs, policy engines for guardrails, reproducibility enforcement.
- Dependencies/assumptions: Secure control planes; rigorous approval workflows; automated anomaly detection.
- Cross‑org scheduler standards for fast, fair, gang‑scheduled AI clusters (Cloud/HPC)
- What: Industry adoption of per‑job preemption, topology mirrors, and sticky respawn to raise effective cluster utilization.
- Path: Open scheduler APIs, integration with K8s, proofs of fairness and stability at scale.
- Dependencies/assumptions: Vendor engagement; ops expertise; interoperability with existing SLAs.
Notes on feasibility and risk
- Safety and compliance: Agentic coding must be sandboxed and test‑gated to avoid introducing vulnerabilities or misconfigurations; regulated sectors require strict governance.
- Hardware support: Some benefits (FP8/NVFP4 quantization, fused MoE comm‑compute) depend on modern GPUs and specialized kernels.
- Long‑context tradeoffs: Quality beyond the trained 128K context can degrade; FP8 KV caches help but memory/latency remain constraints.
- Data rights: Web and synthetic data usage must respect licenses, PII policies, and takedown mechanisms.
- Organizational change: Adopting experiments‑as‑code and lineage-driven workflows requires cultural and process shifts, not just tooling.
Glossary
- AdamW: An optimization algorithm that adds decoupled weight decay to Adam. "non-matrix parameters (updated by AdamW~\citep{loshchilov2019adamw})"
- Agentic workflows: Processes where AI agents autonomously conduct research tasks such as experiment design and monitoring. "Agentic Workflows."
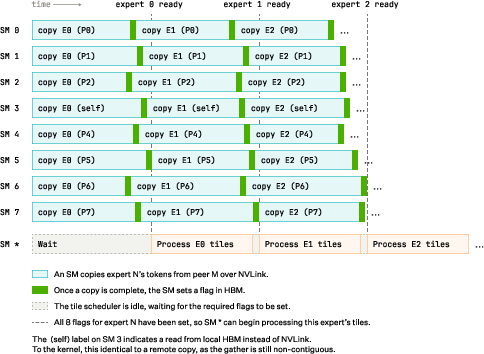
- All-to-all collectives: Distributed communication operations where each participant sends data to every other participant. "This requires two all-to-all collectives per layer: a dispatch to send tokens to the GPUs owning their expert weights, and a combine to retrieve the processed tokens back."
- AutoMixer: An automated system for tuning pre-training data mixtures instead of using static, manually designed ratios. "we added an AutoMixer (\Cref{sec:automixing})"
- BF16: A 16-bit floating-point format (bfloat16) used to speed up training while retaining enough range for stability. "We use BF16 mixed precision training throughout all stages"
- Blender: An internal streaming data service that mixes sources and serves synchronized batches to training jobs. "Streaming is handled by Blender, our internal data service,"
- Byte-Pair Encoding (BPE): A subword tokenization method that builds a vocabulary from frequent byte-pair merges. "trained with Byte-Pair Encoding~\citep{sennrich-etal-2016-neural}"
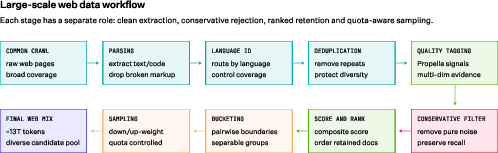
- Common Crawl: A large-scale web crawl dataset frequently used to source web documents for pre-training. "Early stages extract, route, and deduplicate Common Crawl documents."
- Cross-replica hash checks: Periodic hash comparisons of model weights across replicas to detect divergence or silent corruption. "Cross-replica Hash Checks."
- CUDA graphs: A CUDA feature that records and replays GPU workloads to reduce launch overhead. "We also support enabling CUDA graphs for the Newton--Schulz procedure"
- CUTLASS: NVIDIA’s GEMM kernel library used to implement high-performance matrix operations. "standard CUTLASS-based grouped GEMM kernels used by PyTorch"
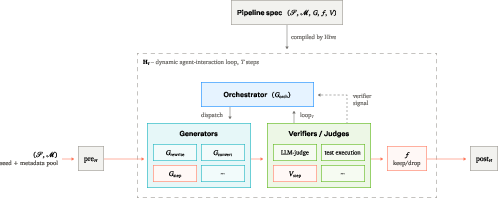
- Dagster: A data orchestration framework used here as the control plane for experiments and asset lineage. "We use Dagster~\citep{dagster} as the central control plane"
- Data-parallel attention: Attention computed independently on different batch shards without cross-rank communication. "sequence-parallel attention is sometimes referred to as data-parallel attention in the literature."
- DDP (Distributed Data Parallel): A strategy that replicates models across processes and synchronizes gradients during training. "Distributed Data Parallel (DDP),"
- Deduplication, snapshot-level fuzzy: Removing near-duplicate documents across web snapshots using fuzzy matching to improve knowledge retention. "Snapshot-level fuzzy deduplication is preferred"
- EMA (Exponential Moving Average): A technique to average recent checkpoints to stabilize the final model. "we apply an exponential moving average (EMA) over the 10 most recent checkpoints"
- EGP (Expert Group Parallel): Parallelism mode that shards experts across ranks in MoE layers. "Expert Group Parallel (EGP) shards experts across ranks"
- EP (Expert Parallelism): A parallelization scheme that distributes different experts of MoE layers across devices. "Expert Parallel (EP)~\citep{shazeer2017moe}"
- ETP (Expert Tensor Parallel): Shards the parameters within a single expert across devices along tensor dimensions. "Expert Tensor Parallel (ETP) shards the weights of a single expert"
- Expert collapse: A failure mode in MoE training where experts degenerate, losing specialization and destabilizing training. "Expert Collapse."
- FP32: 32-bit floating-point precision typically used for master weights and numerically sensitive reductions. "with the master weights in FP32"
- FP8: 8-bit floating-point precision used for aggressive quantization to reduce memory and compute costs. "we quantize the model's MoE layers to FP8, INT4, and NVFP4, as well as the KV cache to FP8."
- FoundationDB: A distributed, transactional key-value store used here to mirror and query cluster topology. "is mirrored out of Kubernetes into FoundationDB~\citep{foundationdb}"
- FSDP (Fully Sharded Data Parallel): A method that shards model parameters, gradients, and optimizer states across devices to save memory. "Fully Sharded Data Parallel (FSDP)~\citep{zhao2023fsdp}"
- GlotLID: A language identification model used to filter documents by language. "This pipeline leverages GlotLID~\citep{kargaran-etal-2023-glotlid}"
- Global Attention (GA): Attention layers where tokens attend globally across the entire sequence. "Sliding Window Attention (SWA) and Global Attention (GA)~\citep{beltagy2020longformer, gemmateam2024gemma2improvingopen}"
- GQA (Grouped Query Attention): An attention variant that reduces KV heads via grouping to improve efficiency. "we use Grouped Query Attention (GQA)~\citep{ainslie-etal-2023-gqa}"
- Grouped GEMM: Batched matrix multiplications grouped to efficiently process multiple experts or tiles. "standard CUTLASS-based grouped GEMM kernels used by PyTorch"
- HBM (High Bandwidth Memory): On-package memory with very high bandwidth used in modern accelerators. "to local High Bandwidth Memory (HBM)."
- Hive: A configurable agent-driven framework for synthetic data generation pipelines. "we built Hive as a component of the Model Factory"
- INT4: 4-bit integer precision used for highly compressed weight quantization. "we quantize the model's MoE layers to FP8, INT4, and NVFP4, as well as the KV cache to FP8."
- KV cache: Cached key and value tensors used to speed up autoregressive decoding. "we quantize the model's MoE layers to FP8, INT4, and NVFP4, as well as the KV cache to FP8."
- Kubernetes: A container orchestration system used to schedule and manage training jobs at cluster scale. "Jobs are scheduled by Kubernetes~\citep{kubernetes}"
- LM head input-gradient all-reduce: The precision-sensitive cross-rank reduction of gradients at the input to the output (LM head) layer. "we therefore enforce the LM head input-gradient all-reduce in FP32"
- Model Factory: An integrated system of components and processes that industrializes model development. "we refer to as our Model Factory"
- MoE (Mixture-of-Experts): Architectures that route tokens to a subset of specialized expert networks for efficiency and capacity. "Laguna XS.2 and M.1 are both Mixture-of-Experts (MoE)~\citep{shazeer2017moe} models"
- Moonlight-style learning-rate scaling: A learning-rate rescaling approach to align effective weight decay when using Muon. "we adopt Moonlight-style learning-rate scaling~\citep{liu2025muon}."
- Muon optimizer: An optimizer that uses momentum with orthogonalization (e.g., Newton–Schulz) to stabilize and accelerate training. "We use the Muon optimizer~\citep{jordan2024muon}, specifically the Moonlight variant of \citet{liu2025muon}"
- NCCL: NVIDIA’s collective communication library for multi-GPU operations. "detects hangs, NCCL failures,"
- Newton--Schulz: An iterative method used here to orthogonalize gradients in the optimizer. "orthogonalize them via Newton--Schulz"
- NVFP4: NVIDIA’s 4-bit floating-point quantization format. "we quantize the model's MoE layers to FP8, INT4, and NVFP4, as well as the KV cache to FP8."
- NVLink: A high-speed GPU interconnect for peer-to-peer transfers. "via vectorized 128-bit loads over NVLink"
- Pipeline Parallel (PP): Partitioning model layers across devices to increase effective model size and throughput. "Pipeline Parallel (PP)~\citep{huang2019gpipe}"
- Pre-norm Transformer: A Transformer variant where normalization occurs before the sub-layer, improving training stability in deep networks. "models using a pre-norm Transformer architecture~\citep{vaswani2017transformer, xiong2020prenorm}"
- Propella: A multi-property document annotation model used to score and tag web data quality. "The document tags are produced with Propella~\citep{idahl2026propella}, an open multi-property document annotation model"
- RDMA: Remote Direct Memory Access used to broadcast checkpoints efficiently without CPU mediation. "and broadcasts the weights to the remaining ranks via RDMA."
- RoPE (Rotary Positional Encodings): A positional encoding technique enabling extrapolation to longer contexts. "We employ Rotary Positional Encodings (RoPE)~\citep{su2024rope}"
- SDC (silent data corruption): Undetected hardware-induced computation errors not caught by ECC. "silent data corruption (SDC) \citep{dixit2021sdc}"
- Sequence packing: Concatenating multiple sequences into fixed-length blocks to improve training efficiency. "despite sequence packing, 5\% of training tokens were padding,"
- Sequence-parallel (SP): Sharding activations along sequence (or batch for attention) across TP ranks to reduce communication. "either tensor-parallel (TP) or sequence-parallel (SP)."
- Shared expert: An MoE expert applied to every token in addition to routed experts, improving stability and coverage. "plus a shared expert~\citep{dai-etal-2024-deepseekmoe} that processes every token."
- Sliding Window Attention (SWA): Attention limited to a fixed window to reduce quadratic cost while retaining locality. "Laguna XS.2 uses interleaved Sliding Window Attention (SWA)"
- SM (Streaming Multiprocessor): GPU compute units that schedule and execute kernels. "Streaming Multiprocessors (SMs)"
- Token-choice routing: An MoE routing scheme that selects experts per token based on learned scores. "Laguna XS.2 uses token-choice routing~\citep{shazeer2017moe}"
- Top-k: Selecting the k highest-scoring elements (e.g., experts) during routing. "after top-k~\citep{liu2024deepseek}"
- Volcano: A Kubernetes batch scheduler used as an initial basis before moving to a custom scheduler. "An initial version was based on Volcano~\citep{volcano}."
- Warmup-Stable-Decay (WSD): A learning-rate schedule with a warmup phase, a flat stable phase, and a final decay. "we adopted a Warmup-Stable-Decay (WSD) learning rate schedule~\citep{hu2024minicpm} instead of cosine."
- WSD scaling law: An empirically fitted rule predicting the optimal peak learning rate under WSD as a function of model size and token budget. "we therefore fit a WSD-specific scaling law"
- YaRN: A method for extending context length by rescaling positional encodings during fine-tuning. "Both sub-stages apply YaRN~\citep{peng2024yarn} to global attention layers only"
- z-loss: A regularization term applied to logits to reduce drift and stabilize training. "no z-loss~\citep{zoph2022stmoedesigningstabletransferable, chowdhery2023palm}"
Collections
Sign up for free to add this paper to one or more collections.

