- The paper presents a 229.9B-parameter decoder-only Transformer that activates only 9.8B parameters per token, matching larger systems in real-world benchmarks.
- It employs a multi-domain, agent-driven post-training pipeline and interleaved thinking for efficient code synthesis, tool utilization, and autonomous ML engineering.
- The integration of dynamic expert routing, prefix tree merging, and mixed-domain RL yields scalable, cost-efficient intelligence with robust self-evolution capabilities.
MiniMax-M2 Series: Efficient Agentic Intelligence via Mini Activations
Architectural Innovations
The MiniMax-M2 series leverages Mixture-of-Experts (MoE) architecture to reconcile high-capacity modeling with economical compute cost. The M2 backbone is a 229.9B-parameter, 62-layer decoder-only Transformer utilizing only 9.8B activated parameters per token. Each feed-forward layer contains 256 fine-grained experts, with sigmoid gating and expert-specific bias terms, enabling eight simultaneous activations per token and smooth routing dynamics. Attention employs full multi-head, GQA-style mechanism with RoPE, intentionally eschewing efficiency-centric hybrids due to observed degradation in multi-hop reasoning and long-context retrieval performance. The model sustains a 192K-token native context window, made feasible by a robust infrastructure stack and progressive long-context training.
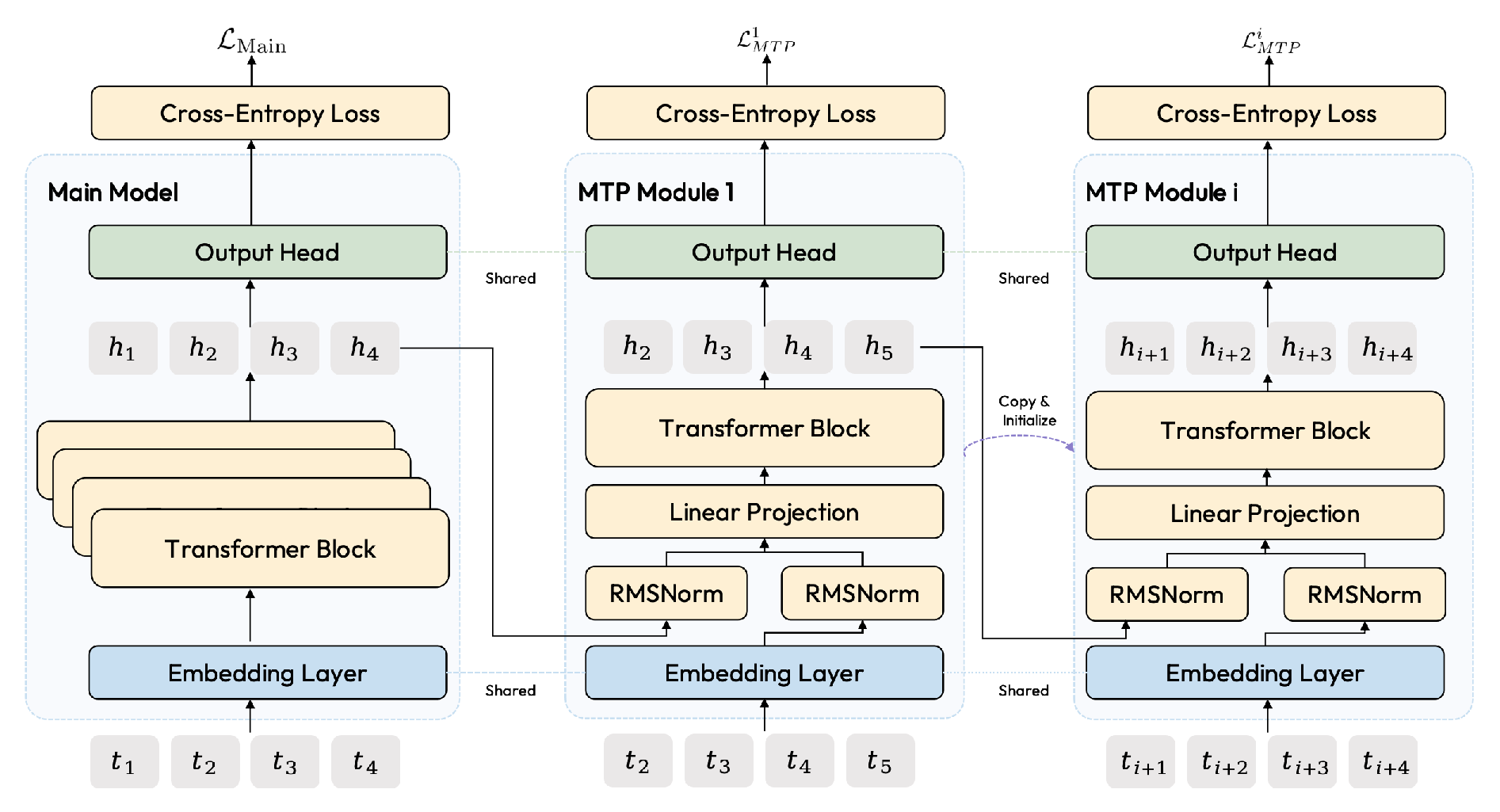
Figure 1: Multi-Token Prediction (MTP) module architecture used in M2.
Multi-Token Prediction (MTP) is integrated throughout pre-training and RL, furnishing joint next-K token prediction during both forward and speculative-decoding inference, accelerating throughput and enhancing agentic trajectory modeling.
Data Pipeline Engineering
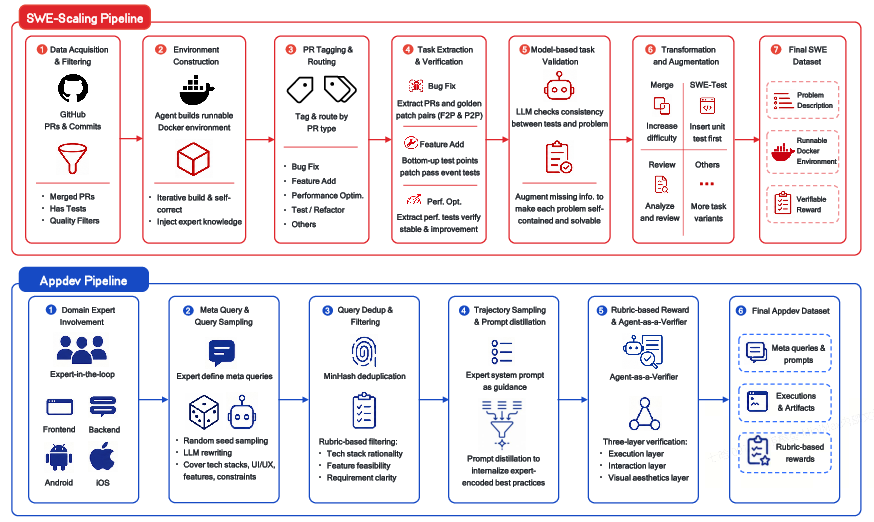
The series is characterized by multi-domain, agent-driven post-training pipelines:
RL System and Infrastructure
MiniMax-M2 RL is executed on Forge, an agent-native system decoupling agent execution from training/inference, supporting both white-box and black-box agent architectures.
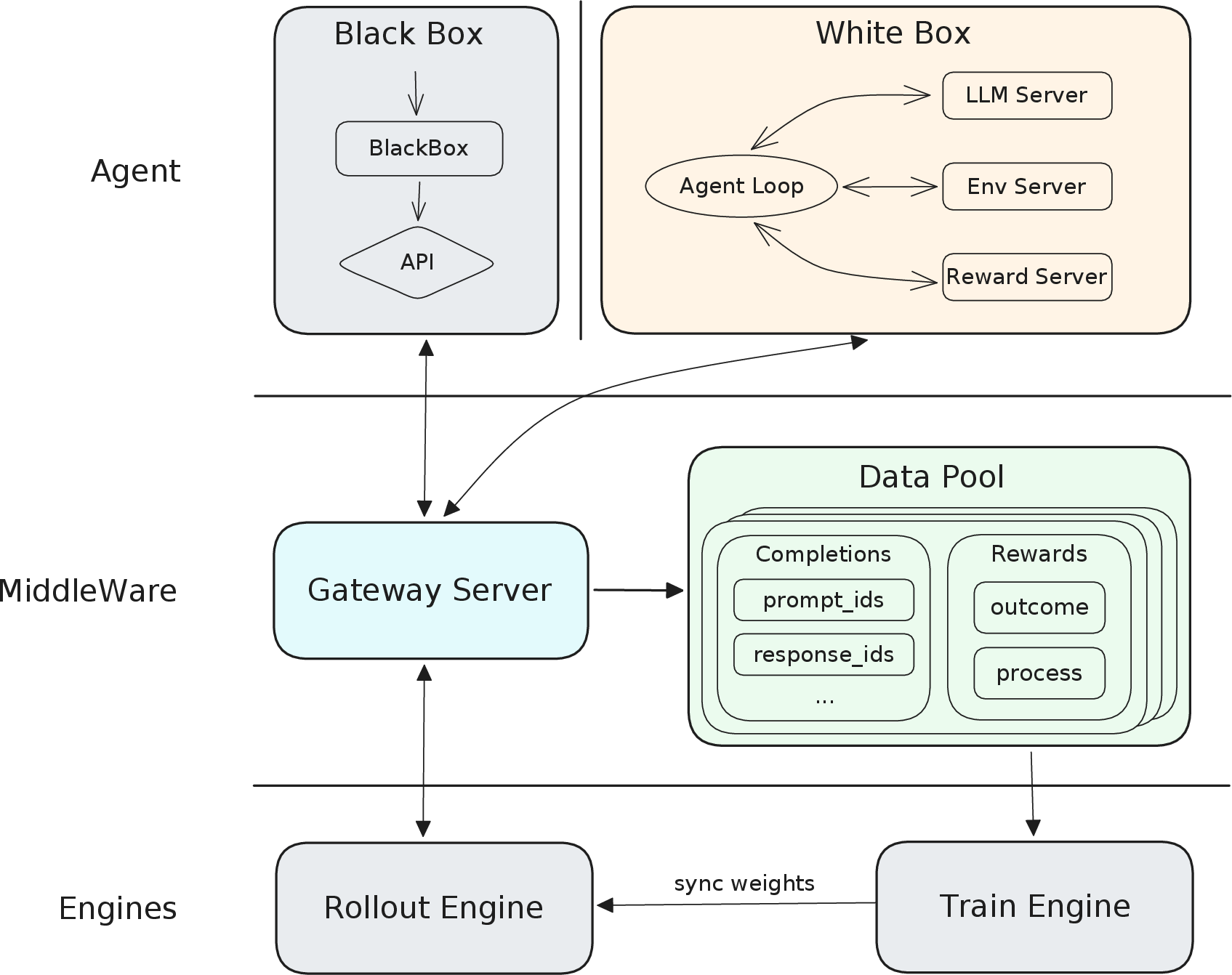
Figure 3: Overview of the Forge RL system. Three decoupled modules---Agent Side, Training/Inference Side, and the middleware abstraction layer (Gateway Server, Data Pool)---communicate through standardized interfaces, allowing the agent and the training loop to scale independently.
Critical algorithmic advancements include:
- Windowed FIFO scheduling: Interpolates FIFO and greedy rollout scheduling for throughput-consistent sample distributions.
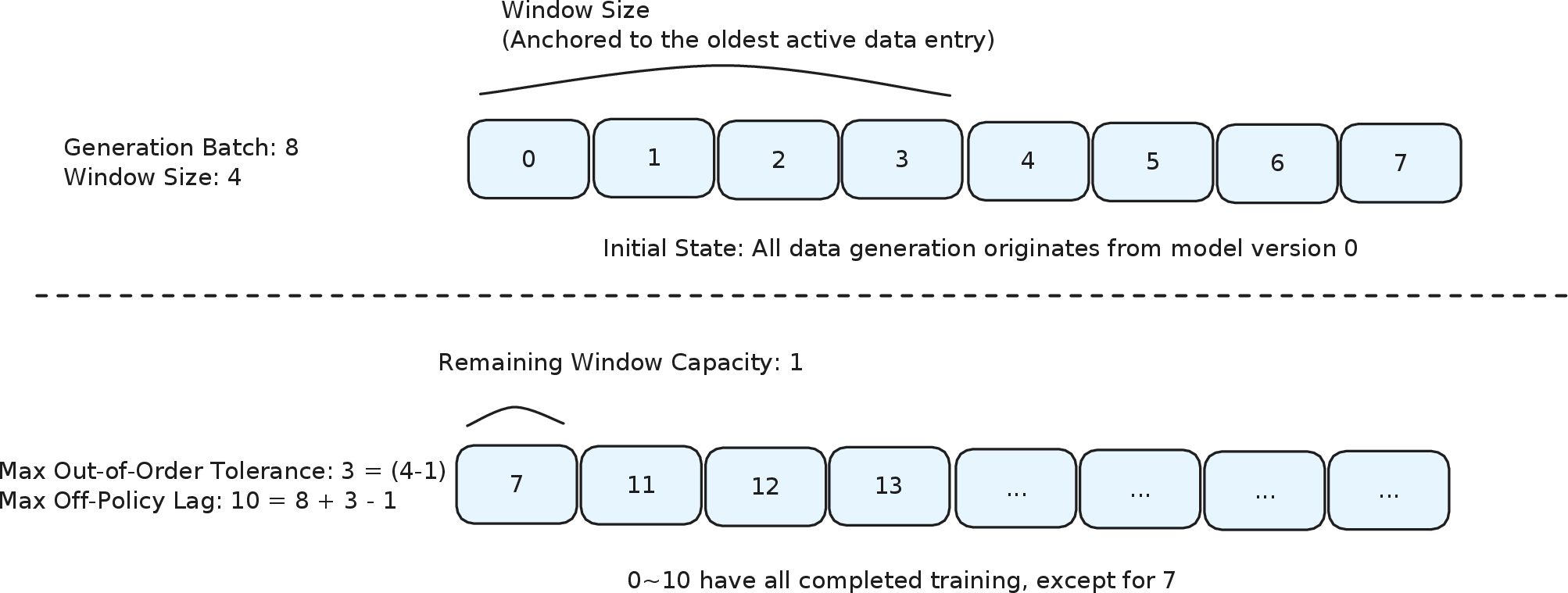
Figure 4: Windowed FIFO scheduling. The training scheduler only fetches completed trajectories within a sliding window of size W over the generation queue: within the window, completion order is free (mitigating head-of-line blocking); across window boundaries, strict FIFO is enforced (preserving distributional consistency).
- Prefix tree merging: Enables mathematically equivalent loss computation with up to 40x training speedup by sharing prefix computations among agentic trajectory branches.
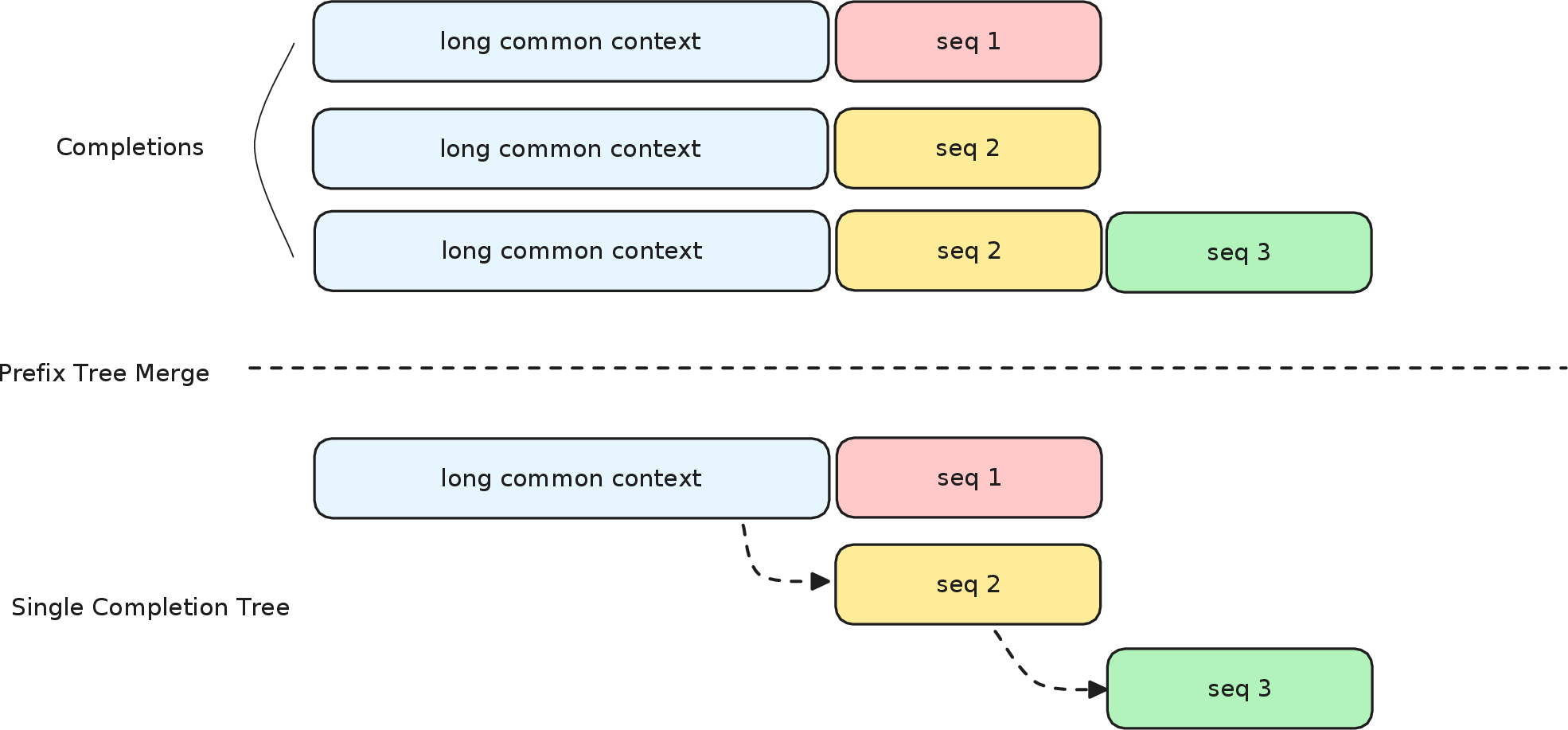
Figure 5: Prefix tree merging. Completions that share a common prefix within a training batch are merged into a tree; the shared prefix is computed exactly once in the forward pass and the computation branches into individual response segments. The tree is deconstructed before the loss is computed independently per sample, so the procedure is mathematically equivalent to independent-sample training while eliminating redundant prefix recomputation.
- Mixed-domain RL: Maintains broad knowledge and reasoning capacity alongside task-specific skill by joint optimization and progressive difficulty/context length scheduling.
Agentic Mechanisms: Interleaved Thinking and Self-Evolution
MiniMax-M2 operationalizes interleaved thinking as a trajectory protocol, alternating reasoning and tool-invocation blocks with persistent reasoning state, unlike front-loaded or stateless strategies.
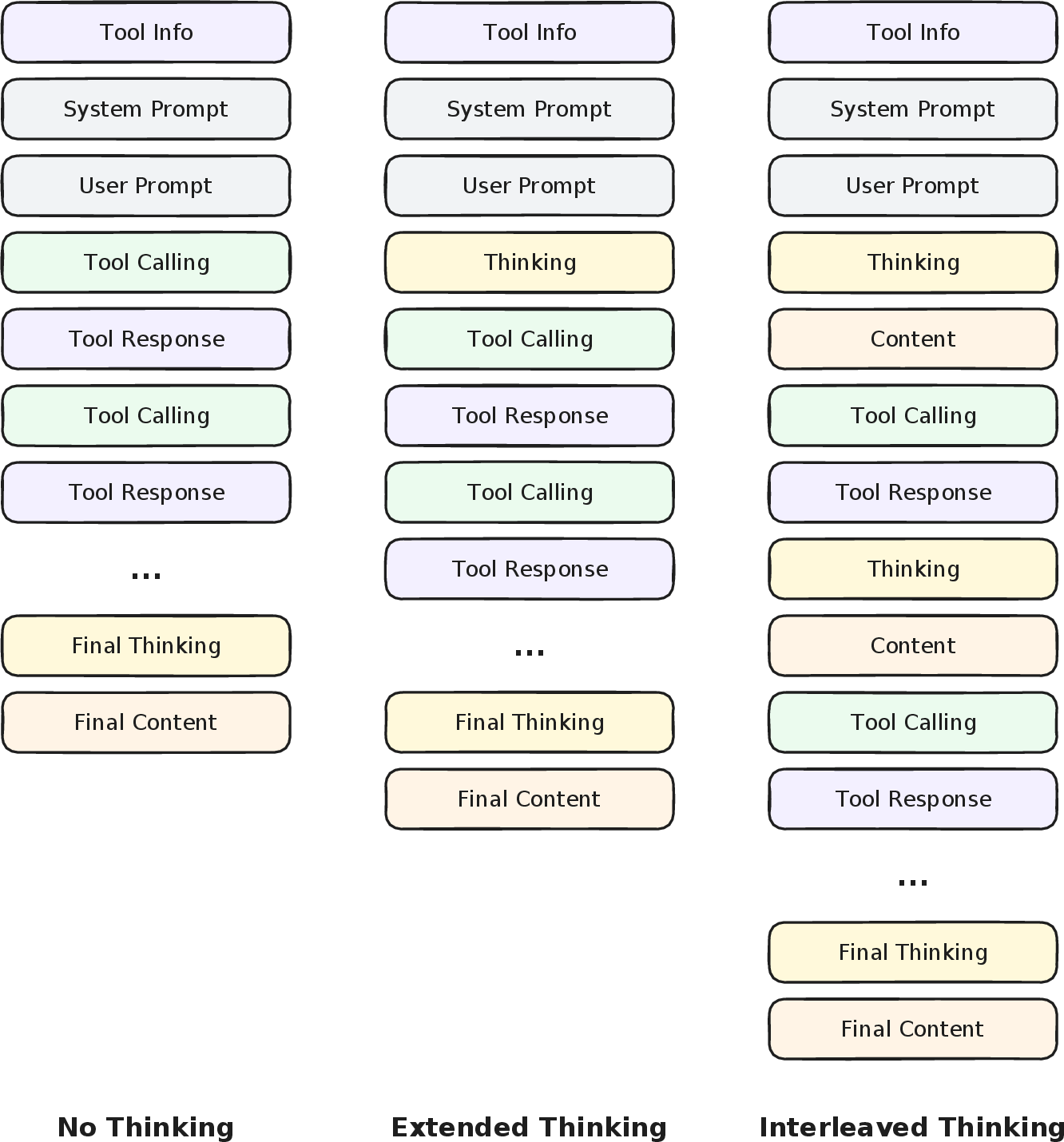
Figure 6: The Plan-Act-Reflect loop of interleaved thinking in M2.
This method enables structured plan-act-reflect loops, supporting iterative self-correction and consistent planning across extended horizons.
M2.7 demonstrates early-stage self-evolution: it autonomously triages failed runs, edits agent scaffolds, and conducts multi-round self-upgrade cycles in ML engineering tasks.
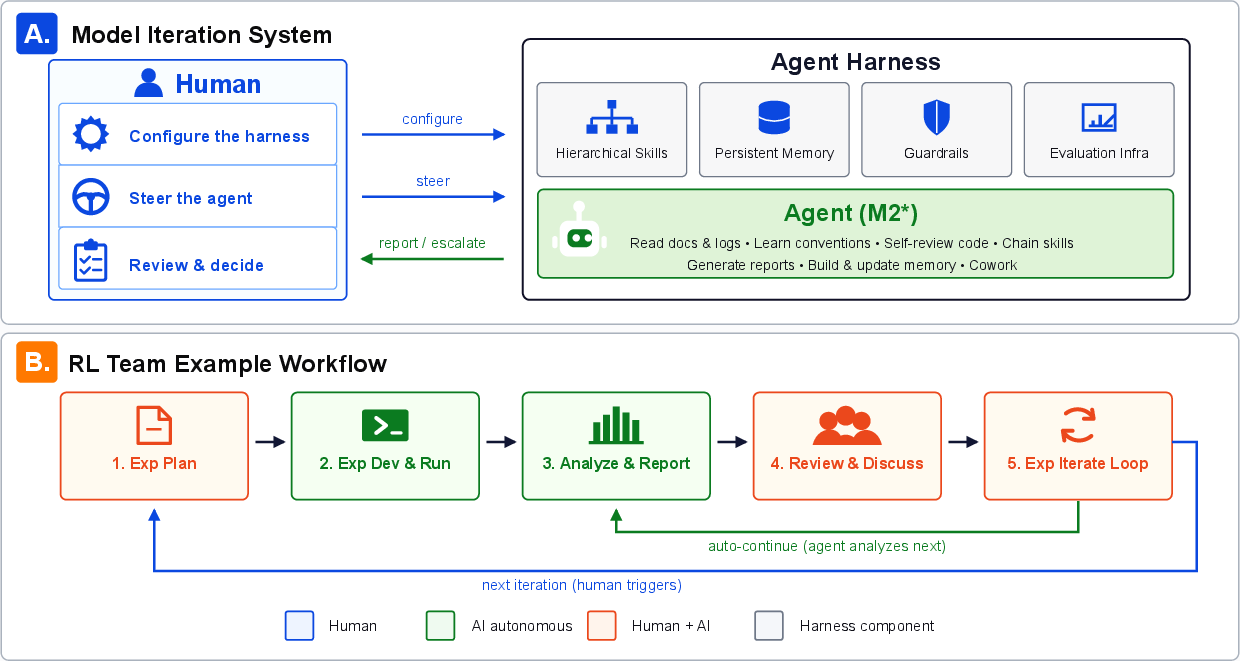
Figure 7: (A) The Model Iteration System used to drive M2.7's autonomous execution. (B) The dual-loop workflow used by our RL team.
Despite activating only ∼10\,B parameters per token, M2.7 achieves performance at or near parity with frontier closed-weight systems activating an order of magnitude more. Numerical highlights include:
- SWE-bench Pro: 56.2
- Terminal-Bench 2.0: 57.0
- BrowseComp: 77.8
- GDPval-AA: 50.0
- AIME 2026: 94.2
- GPQA-Diamond: 89.8
- MLE Bench Lite: 66.6 medal rate
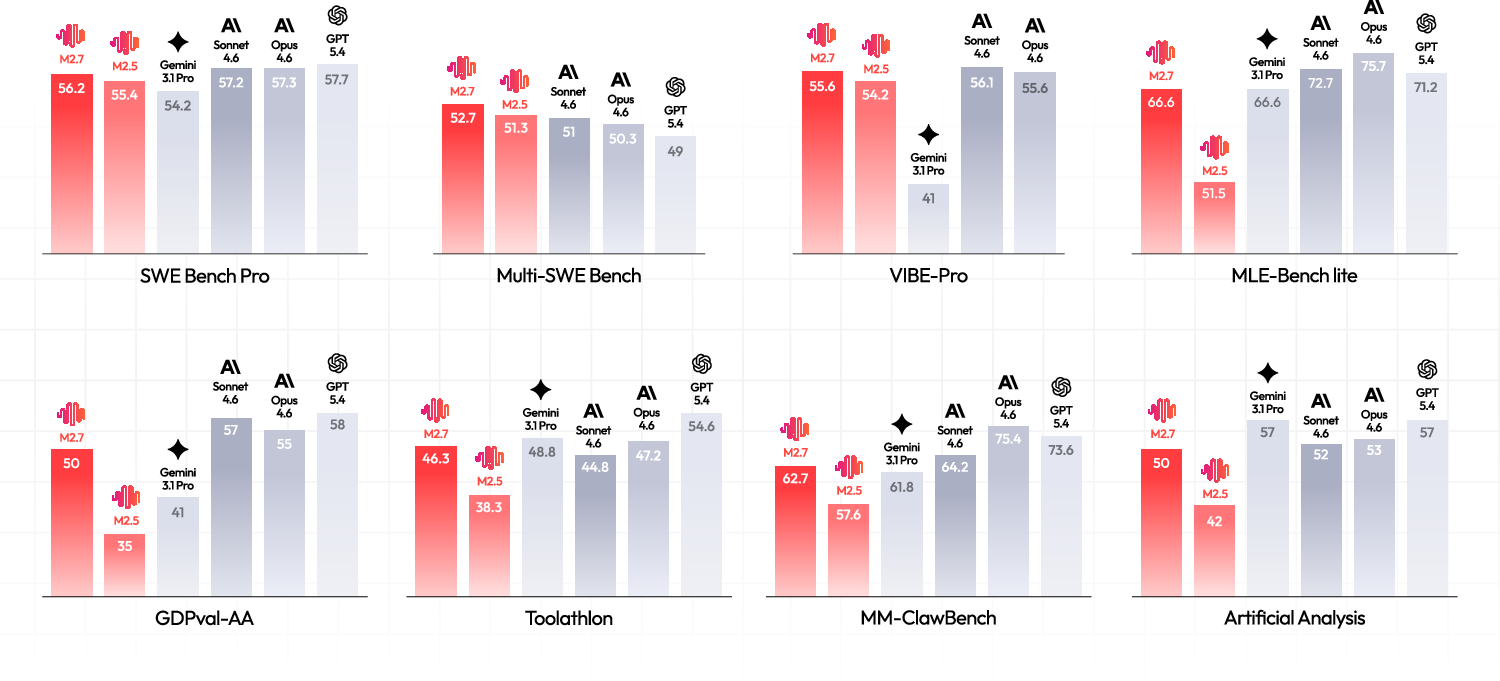
Figure 8: Performance of MiniMax-M2.7 versus closed-weight frontier baselines across agentic coding, agentic cowork, and reasoning knowledge benchmarks. With only ∼10\,B activated parameters, MiniMax-M2.7 remains competitive with substantially larger and more compute-intensive systems.
Capability accrual across M2, M2.5, M2.7 checkpoints tracks investments in agentic data, RL system engineering, and self-evolution, with pronounced improvements in deep-search, tool-use, and autonomous ML engineering.
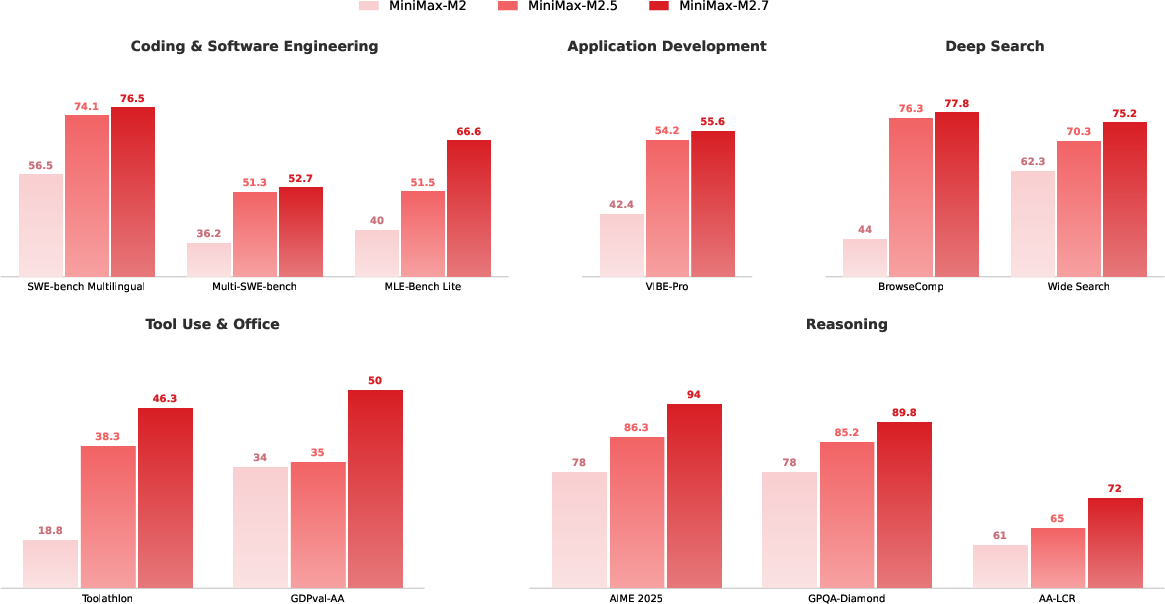
Figure 9: Capability progression of the MiniMax-M2 series across eleven benchmarks. All eleven benchmarks improve across the three checkpoints, with the largest gains concentrated in deep-search, tool-use, and autonomous ML-engineering domains where data pipelines added new task families.
Case Study: Self-Evolution in Autonomous ML Engineering
In controlled MLE Bench Lite trials, M2.7 operates as an autonomous ML engineer, iterating over internal feedback to yield a 66.6\% medal rate, including multiple gold/silver medals, equaling Gemini 3.1 Pro.
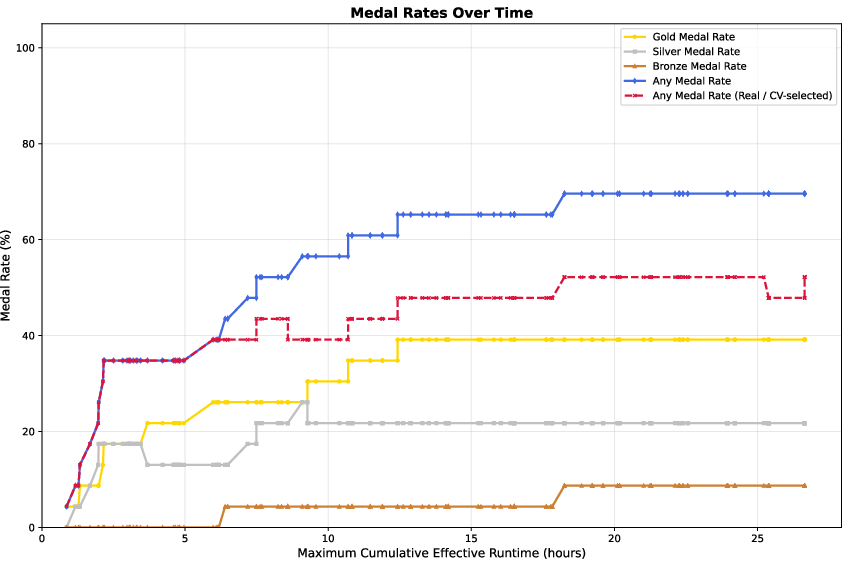
Figure 10: Medal rate of M2.7 on MLE Bench Lite across iterative trials.
This empirically establishes autonomous scaffold improvement and iterative self-correction, closing the loop on agentic self-evolution in practice.
Implications and Future Directions
The MiniMax-M2 series concretely demonstrates that highly-scaled sparse MoE architectures, when combined with rigorous agentic trajectory pipelines, robust RL infrastructure, and persistent interleaved thinking, deliver frontier real-world intelligence with a fraction of the per-step compute. Theoretical implications suggest further exploration into expert specialization, dynamic gating strategies, and large-scale sparse RL. Practically, the system architecture supports deployment scenarios previously hindered by cost and latency, particularly in agentic code synthesis and multi-tool workflows. The observed self-evolution capacities presage a future where autonomous model-driven infrastructure iteration and improvement will be foundational to scaling intelligent systems. Subsequent M2.x releases are expected to expand data diversity, increase RL system complexity, and refine recursive self-improvement mechanisms, potentially advancing both sample efficiency and autonomous agent robustness.
Conclusion
The MiniMax-M2 series fuses mini activation design with agent-centered RL and self-evolution, achieving frontier-scale agentic intelligence. Its architectural, data, and system innovations validate the thesis that a sparse, dynamically-routed model, deeply integrated with agentic environments and agent-specific reward signals, can match closed-weight capacity models in real-world performance regimes. The implications for scalable, efficient agent deployment and continued autonomous improvement are substantial, and future research should systematically deepen each axis—data, RL, and self-evolution—in tandem (2605.26494).