K-EXAONE Technical Report
Abstract: This technical report presents K-EXAONE, a large-scale multilingual LLM developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of the K-EXAONE Technical Report
1. What is this paper about?
This paper introduces K-EXAONE, a very large AI LLM made by LG AI Research in South Korea. The goal is to reach “frontier-level” performance—meaning it can compete with the best AI models in the world—while being efficient, safe, and useful in many languages (including Korean, English, Spanish, German, Japanese, and Vietnamese). It’s designed to be good at general knowledge, math, coding, following instructions, using tools (like web search or software tools), and understanding very long documents.
2. What questions were they trying to answer?
In simple terms, the team asked:
- How can we build a top-tier AI model even if computing resources (like data centers and chips) are limited?
- Can we make the model smarter and faster by using a “team of specialists” inside the model instead of one giant “generalist”?
- Can the model handle very long inputs—like a full book or many web pages (up to 256K tokens)—while still doing great on normal, shorter tasks?
- How do we train the model so it explains its thinking, follows instructions, uses tools, stays safe, and works well in multiple languages?
3. How did they build and train the model?
Think of K-EXAONE like a well-organized company with many experts and smart workflows.
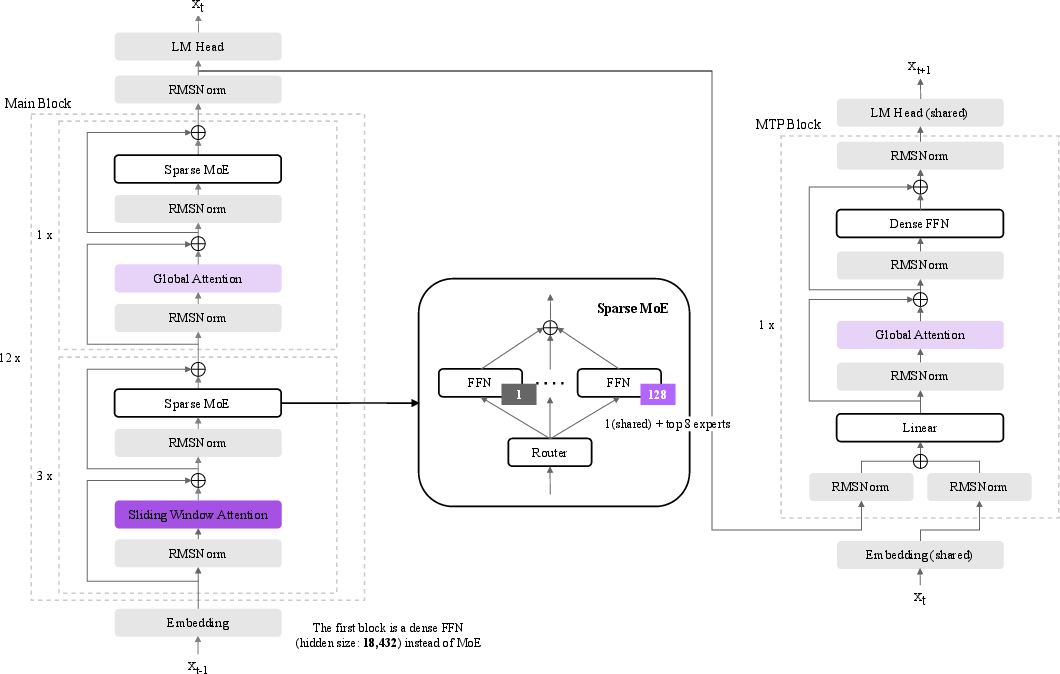
- Model architecture (the “brain’s structure”):
- Mixture-of-Experts (MoE): Imagine a team of 128 specialists. For each piece of text, the model picks the best 8 specialists plus 1 shared expert to help. That way, it uses only what it needs. Even though the model has 236 billion total parameters (think: “knobs” it can adjust), it activates about 23 billion at a time. This saves time and energy while staying very capable.
- Multi-Token Prediction (MTP): Instead of guessing the next word one by one, the model also learns to predict a little further ahead. This helps it “draft” text faster at runtime, giving about 1.5× speed-up in decoding.
- Hybrid attention for long context: Attention is how the model focuses on different parts of the text. K-EXAONE mixes two types:
- Global attention (like looking at a whole page at once)
- Sliding Window Attention (like scanning with a moving magnifying glass)
- This combo keeps memory use low and lets the model handle very long inputs (up to 256K tokens).
- Stabilizers: QK Norm (keeps attention signals from “blowing up”) and RoPE tricks tailored for long texts, so the model stays stable and accurate as documents get longer.
- Tokenizer (how the model splits text into pieces):
- It upgraded from 100K to 150K “word pieces” and added “superwords” (common word chunks packed into single tokens). This shortens inputs by about 30% on average, which saves compute and often improves accuracy—especially for code, math, and multilingual text.
- Training strategy:
- Three-stage pre-training: Start with general knowledge, then add specialized domains and reasoning examples that include “thinking steps” (so the model learns to reason, not just guess answers).
- FP8 precision: A compact number format that makes training cheaper and still stable.
- Context extension in two steps (8K → 32K → 256K): They gradually trained the model to read longer and longer inputs, while rehearsing short tasks so it didn’t “forget” how to do them. They used “Needle-in-a-Haystack” tests to check it could still find small details in huge documents.
- Post-training to align with people:
- Supervised Fine-Tuning (SFT): Teach it to follow instructions using many examples (including high-quality Korean data).
- Reinforcement Learning (RL) with verifiable rewards: Practice on tasks (math, code, STEM) where answers can be checked, and reward good reasoning.
- Preference learning (GrouPER): Sample several answers, score them with rules and rubrics, and train the model to prefer better, safer, clearer responses.
- Tool use and web search:
- When browsing the web, K-EXAONE uses sub-agents:
- A summarizer (takes long pages and keeps the useful parts)
- A “trajectory compressor” (turns many steps of tool calls into a short structured summary)
- This keeps the context clean and avoids repeating the same information.
- Safety and compliance:
- The team filtered data, followed AI ethics guidelines, and tested the model on safety benchmarks to reduce harmful or biased outputs.
4. What did they find, and why does it matter?
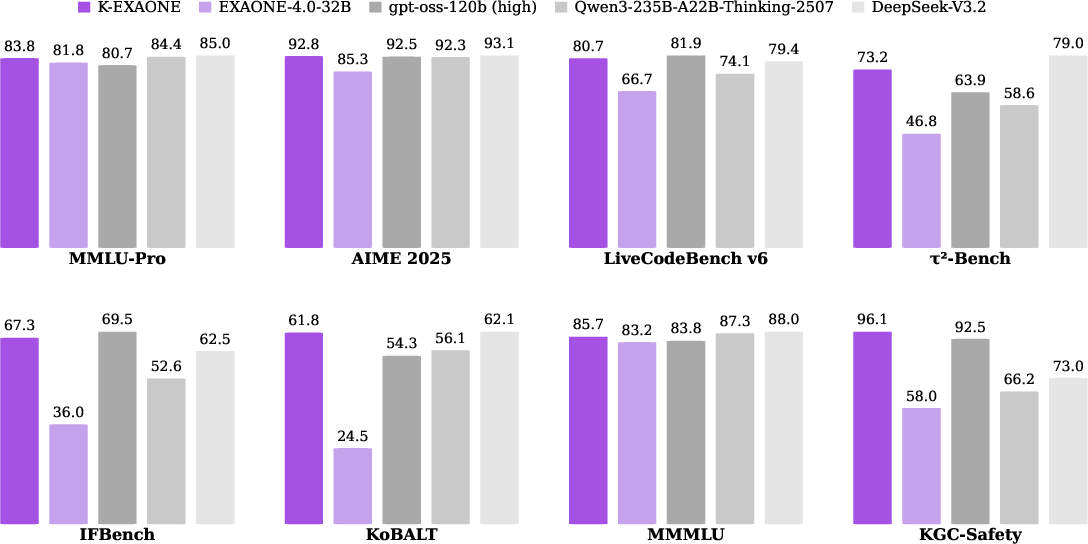
K-EXAONE performed strongly across many tough tests. Here are a few highlights (numbers are scores; higher is better):
- General/world knowledge: It did very well on MMLU-Pro and GPQA-Diamond, showing strong academic knowledge and reasoning.
- Math: It reached very high scores on advanced math contests (like AIME 2025 and HMMT), showing consistent multi-step reasoning skill.
- Coding: It scored highly on LiveCodeBench v6 (competitive programming) and showed promise on practical coding tasks.
- Tool use (agent abilities): It handled multi-step tasks and tool calling well (e.g., τ²-Bench), which matters for real-world workflows like customer support or research assistance.
- Instruction following: It achieved high scores on IFBench and IFEval, meaning it follows complex instructions accurately.
- Long context: It showed strong performance on long-document tests (AA-LCR, OpenAI-MRCR), meaning it can read and reason over very long inputs.
- Korean and multilingual: It performed strongly on Korean benchmarks and did well across multiple languages, including translation.
- Safety: It scored well on safety tests (like WildJailbreak), suggesting it resists harmful prompts better than many peers.
Why this matters:
- It shows that clever architecture (MoE), faster decoding (MTP), and careful training can deliver top performance without always needing the biggest compute budget.
- Long-context strength means it can help with tasks like analyzing long reports, legal documents, or software repositories.
- Multilingual ability makes it more useful globally, especially for Korean users and other supported languages.
5. Why is this important, and what could it lead to?
K-EXAONE is a significant step for building world-class AI in places that don’t have unlimited computing power. By using a “team of specialists” (MoE), smarter tokenization, and careful training, the model is both efficient and powerful.
What this could enable:
- Better assistants for research, coding, and data analysis that can handle long, complex documents.
- Stronger multilingual tools for education, translation, and customer support.
- Safer, more aligned AI that follows instructions and avoids harmful outputs.
- A foundation for future models that scale smarter, not just bigger.
In short, K-EXAONE shows that with the right design and training, we can build AI that is fast, accurate, multilingual, good at reasoning, and safer to use—opening the door to more helpful applications in everyday life.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps, uncertainties, and open questions that remain unresolved by the paper and could guide future research.
- MoE design choices lack ablations: how performance and efficiency vary with expert count (128), top-k routing (top-8), presence of the shared expert, dropless vs capacity-constrained routing, and sequence-level load balancing under different data regimes and batch sizes.
- Expert specialization and routing dynamics are unexamined: which experts specialize by language/domain, how stable routing is across long contexts and multilingual inputs, and whether router freezing during RL impacts specialization retention or causes mode collapse.
- Sensitivity of MoE hyperparameters is unclear: the fixed sequence auxiliary loss (1e-4) and expert-bias update factor (1e-4) are not justified; robustness to these values is unknown.
- MTP self-drafting speed–quality trade-offs are unquantified: claimed ~1.5× throughput gains lack accuracy impact curves across tasks, error propagation analyses, and guidance on when to enable/disable MTP at inference.
- Scope of MTP objective is limited: only +1 future token prediction is described; whether predicting +n tokens or adaptive horizons improves throughput without degrading quality remains unexplored.
- Hybrid attention design lacks empirical justification: no ablations on GA/SWA layer ratios (12 GA / 36 SWA), nor on the effect of shrinking the SWA window from 4096 to 128 on local coherence, retrieval, and long-range reasoning.
- RoPE application only to SWA layers and QK Norm efficacy lack evidence: there are no controlled studies showing their individual contributions to training stability, extrapolation to 256K, and cross-task performance.
- Long-context extension is verified mainly via NIAH but not real tasks at 256K: the paper does not report evaluations on authentic 100–256K-token tasks (e.g., codebase navigation, legal discovery, scientific literature synthesis), nor provide NIAH curves or wedge tests at the maximum context.
- Short-context performance preservation is not measured: rehearsal dataset is proposed, but concrete quantitative deltas (before vs after 256K extension) are missing across core short-context benchmarks.
- FP8 training details and benefits are under-specified: implementation specifics (scaling/clipping, per-tensor vs per-channel, hardware kernels), convergence speed vs BF16, memory/throughput gains, and interaction effects with MoE routing are not reported.
- Data mixture composition is opaque: sources, domain/language proportions, deduplication strategy, and contamination checks for evaluated benchmarks (e.g., AIME 2025, GPQA, LiveCodeBench v6, WMT24++) are not disclosed.
- Thinking-augmented and multilingual synthesis quality is unverified: the paper does not quantify factuality, reasoning correctness, or translation artifacts in synthetic corpora, nor their contribution via controlled data ablations.
- Tokenizer redesign effects beyond bytes-per-token are untested: impacts of SuperBPE superwords (20% of vocab) on downstream accuracy, rare phrase fragmentation, OOV rates in new languages (de, ja, vi), and code/STEM tokenization errors are not analyzed.
- Language coverage remains narrow for a “multilingual” foundation: the model excludes major scripts/languages (e.g., zh, hi, ar, ru, fr), and safety/calibration for non-English languages is not audited.
- Per-language performance variance is omitted: multilingual results are averaged; detailed per-language breakdowns (including error categories) are needed to identify systematic weaknesses and guide data/finetuning.
- Agentic tool-use evaluation relies on synthetic environments: real-world tool ecosystems (live APIs, failures, latency, rate limits, changing schemas) and longitudinal performance under drift are not assessed.
- Sub-agent contributions are not ablated: the summarizer and trajectory compressor are introduced, but there is no measurement of their independent effect on accuracy, latency, context efficiency, or error propagation.
- BrowseComp reporting is inconsistent: only a non-reasoning score is shown; reasoning-mode performance, browsing hallucination rates, and grounding fidelity are not reported.
- Agentic coding results lag top baselines: gaps on Terminal-Bench 2.0 and SWE-bench Verified are not diagnosed; missing analyses of failure modes (planning, environment setup, test flakiness) and targeted training/inference strategies to close the gap.
- RL training lacks scale and reliability details: rollout group size G, sampling budgets, ε truncation thresholds, verifier disagreement rates, and stability with the KL penalty removed are not provided; susceptibility to reward hacking and overfitting is unknown.
- GrouPER preference learning is under-evaluated: no comparison to strong baselines (e.g., DPO, RLAIF variants) across diverse domains, nor sensitivity to group size, reward composition, rubric design, and annotator bias.
- Safety evaluations are limited: beyond WildJailbreak and in-house KGC-Safety, there is no multilingual red-teaming, jailbreak robustness in long contexts, or assessment of safety under tool use and browsing.
- Bias and fairness audits are missing: quantitative measurements across demographic attributes and languages (helpfulness, toxicity, stereotyping, microaggressions) are absent, especially for Korean and newly added languages.
- Privacy risks are not assessed: memorization, data extraction, membership inference, and privacy leakage through long-context processing and browsing are unexamined.
- Evaluation methodology lacks statistical rigor: no seeds, variance, or confidence intervals; temperature/top-p may differ from baselines; MTP disabled without justification; comparability and reproducibility of scores are uncertain.
- Inference efficiency is not fully characterized: actual throughput, latency, KV-cache memory, and cost across hardware (A100/H100/MI300, CPU) in reasoning vs non-reasoning modes, with/without MTP, and at 128K–256K contexts are not reported.
- Deployment and serving guidance is sparse: quantization options, batching strategies, speculative decoding configurations, and production reliability (timeouts, OOMs, expert imbalance) are not documented.
- Environmental impact is unreported: training/inference energy consumption, carbon footprint, and efficiency trade-offs versus dense baselines are not provided.
- Release artifacts are incomplete for reproducibility: pretraining/post-training code, data recipes, reward/verifier pipelines, and evaluation harnesses are not fully described or released; license naming constraints may impede derivative ecosystem development.
- Architectural scalability and limits are unknown: behavior at larger capacity (e.g., >256 experts), higher context lengths (>256K), and different GA/SWA ratios is untested; failure modes under extreme inputs are not characterized.
Glossary
- AGAPO: A reinforcement learning objective that optimizes with verifiable rewards using importance sampling. "For optimization, we use AGAPO~\cite{bae2026exaone40unifiedlarge} with an off-policy policy-gradient using truncated importance sampling."
- Agentic tool use: Goal-directed, multi-step interaction where a model uses external tools to complete tasks. "Agentic Tool Use: -Bench~\citep{barres2025tau2benchevaluatingconversationalagents} and BrowseComp~\citep{wei2025browsecompsimplechallengingbenchmark}"
- Autoregressive decoding: Token-by-token generation where each next token is conditioned on previously generated tokens. "achieving an approximately 1.5 improvement in decoding throughput compared to standard autoregressive decoding."
- BF16 precision: Brain floating point 16-bit format used to balance speed and numeric stability during training. "K-EXAONE is natively trained with FP8 precision and achieves training loss curves comparable to those obtained under BF16 precision"
- Bytes per token: A tokenizer efficiency metric indicating how many bytes of text each token represents. "Comparison of tokenizer efficiency, measured in bytes per token, between K-EXAONE and EXAONE 4.0 across diverse text domains."
- Context length extension: A procedure to increase the maximum input sequence length a model can handle. "we employ a two-stage context length extension procedure."
- Decoding throughput: The rate at which a model generates tokens during inference. "achieving an approximately 1.5 improvement in decoding throughput compared to standard autoregressive decoding."
- Dropless routing policy: An MoE routing strategy that ensures all tokens are sent to experts without capacity-based dropping. "a dropless routing policy~\citep{gale2023megablocks} is adopted to ensure that all tokens are dispatched to experts without capacity-based dropping"
- End-to-end Long-Document Dataset: Full documents used as single training samples to teach long-range dependency modeling. "Rehearsal Dataset, Synthetic Reasoning Dataset, and End-to-end Long-Document Dataset"
- Expert bias update factor: A regularization parameter controlling updates to routing biases in MoE training. "the expert bias update factor is also set to throughout training."
- FP8 precision: 8-bit floating-point format enabling efficient training with acceptable stability. "K-EXAONE is natively trained with FP8 precision"
- Full quantization-aware convergence: Stable optimization behavior when training under low-precision quantization regimes. "demonstrating that FP8 training preserves optimization stability while enabling full quantization-aware convergence."
- Global advantage normalization: Normalizing group-level advantages across a batch to stabilize RL updates. "and global advantage normalization to capture both within-group relative reward signals and batch-level information."
- Global attention (GA): Attention mechanism where tokens can attend to all other tokens globally. "compared to full global attention (GA) across all layers"
- GRPO: A group-based reinforcement learning approach used to enhance reasoning via multiple sampled responses. "Inspired by the GRPO~\cite{shao2024deepseekmathpushinglimitsmathematical}, GrouPER samples multiple responses for each query"
- GrouPER: Group-wise SimPER; a preference learning objective that uses group-level advantages. "We propose GrouPER (Group-wise SimPER), an improved variant of SimPER~\cite{xiao2025simper}"
- Hybrid attention mechanism: Combining local and global attention modules to handle long contexts efficiently. "It also uses a hybrid attention mechanism that integrates global and local attention modules"
- JSON-formatted structured record: A compact representation of tool-use trajectories containing key facts and pending questions. "the trajectory compressor compresses the full interaction into a single JSON-formatted structured record"
- KL penalty: A regularization term penalizing deviation from a reference policy during RL; often omitted for performance. "During training, we exclude the KL penalty to improve performance while avoiding unnecessary computation."
- KV-cache: Cached key-value pairs from attention layers used to speed up incremental decoding. "thereby minimizing KV-cache usage while preserving modeling capacity."
- Layer normalization: A normalization technique applied to neural activations to stabilize training. "QK Norm applies layer normalization to the query and key vectors prior to attention computation"
- LLM-as-a-judge: Using a LLM to evaluate and score outputs for reward or preference signals. "and an LLM-as-a-judge."
- Long-Document Dataset: A dataset of full-length documents used to train long-range reasoning and retrieval. "we place particular emphasis on a Long-Document Dataset during the extension phases"
- Mixture-of-Experts (MoE): An architecture that routes tokens to a subset of specialized experts to scale capacity efficiently. "the adoption of the Mixture-of-Experts (MoE) paradigm"
- Muon optimizer: A specific optimizer used for training large models with improved stability or efficiency. "We adopt the Muon optimizer \cite{liu2025muon} for all training stages"
- Multi-Token Prediction (MTP): An auxiliary objective/module predicting multiple future tokens to boost inference efficiency. "K-EXAONE integrates a dense-layer-based Multi-Token Prediction (MTP) module"
- Needle-In-A-Haystack (NIAH): A long-context evaluation probing a model’s ability to retrieve specific information from large inputs. "Needle-In-A-Haystack (NIAH)~\cite{niah} tests to assess the modelâs ability to retain and retrieve information from long contexts."
- NFC: A Unicode normalization form preserving distinctions important in STEM and code corpora. "We also switch Unicode normalization~\citep{unicode-normalization-17} from NFKC to NFC"
- NFKC: A Unicode normalization form that can fold certain distinctions; replaced by NFC in this work. "We also switch Unicode normalization~\citep{unicode-normalization-17} from NFKC to NFC"
- Off-policy policy-gradient: An RL method that updates a target policy using samples from a different rollout policy. "we adopt an off-policy policy-gradient objective with truncated importance sampling"
- Pre-tokenization regex: Regular expressions applied before tokenization to segment and normalize text. "we update the pre-tokenization regex (regular expression) and normalization method"
- QK Norm: Normalizing query and key vectors before attention to stabilize logits and training. "QK Norm applies layer normalization to the query and key vectors prior to attention computation"
- RoPE (Rotary Positional Embeddings): A positional encoding scheme rotating queries/keys to inject sequence order. "SWA (Sliding Window Attention)~\citep{beltagy2020longformer}-only RoPE (Rotary Positional Embeddings)"
- Routing stability: The reliability of token-to-expert assignments during MoE routing. "To improve routing stability and expert utilization efficiency, sequence-level load balancing is employed in the MoE routing mechanism"
- Rule-based verifiers: Deterministic evaluators used to assign verifiable rewards to model outputs. "For verification, we use a combination of rule-based verifiers and an LLM-as-a-judge."
- Rubric-based generative rewards: Rewards generated by an evaluator model using multi-dimensional rubrics for preferences. "with rubric-based generative rewards that score responses along multiple dimensions."
- Sequence auxiliary loss coefficient: A regularization weight applied to auxiliary MoE losses during training. "For MoE regularization, the sequence auxiliary loss coefficient is fixed to "
- Sequence-level load balancing: Balancing expert utilization across sequences to improve MoE efficiency. "sequence-level load balancing is employed in the MoE routing mechanism"
- Self-drafting: A decoding technique where the model drafts multiple tokens ahead using auxiliary predictors. "K-EXAONE leverages the MTP block for self-drafting"
- Shared expert: An MoE expert used across tokens alongside routed experts to stabilize or generalize behavior. "together with an additional shared expert, resulting in nine concurrently active experts per routing decision."
- SimPER: A preference learning objective that scales probabilities using preference-derived advantages. "an improved variant of SimPER~\cite{xiao2025simper}"
- Sliding Window Attention (SWA): Local attention limiting each token to a fixed-size neighborhood to reduce cost. "SWA (Sliding Window Attention)~\citep{beltagy2020longformer}-only RoPE (Rotary Positional Embeddings)"
- Stop-gradient function: An operation preventing gradients from flowing through certain terms in optimization. "We apply truncated importance sampling at the token level with a stop-gradient function ."
- Sub-agents: Auxiliary models assisting the primary agent with specialized tasks like summarization and compression. "we augment it with two sub-agents: a summarizer and a trajectory compressor."
- SuperBPE: A tokenization strategy introducing superword tokens to reduce sequence length. "we adopt SuperBPE~\citep{liu2025superbpe} strategy that introduces superword tokens"
- Synthetic Reasoning Dataset: A curated dataset with explicit multi-step reasoning content to train reasoning skills. "Synthetic Reasoning Dataset"
- Truncated importance sampling: Capping importance weights to reduce variance in off-policy gradients. "we adopt an off-policy policy-gradient objective with truncated importance sampling"
- Trajectory compressor: A module that compacts long tool-use histories into concise structured records. "the trajectory compressor compresses the full interaction into a single JSON-formatted structured record"
- Unicode normalization: Standardizing Unicode text representations to ensure consistent tokenization. "We also switch Unicode normalization~\citep{unicode-normalization-17} from NFKC to NFC"
- Warmup–Stable–Decay (WSD): A learning rate schedule with an initial warmup, a plateau, and a decay phase. "the WarmupâStableâDecay (WSD) \cite{dremov2025training} learning rate scheduler."
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging K-EXAONE’s current capabilities in long-context processing (up to 256K tokens), agentic tool use, multilingual coverage (ko, en, es, de, ja, vi), strong reasoning/coding benchmarks, and safety alignment.
- Enterprise long-document copilot
- Sector: software, legal, finance, healthcare, public sector
- Use cases: end-to-end analysis of contracts, filings, patient records, regulatory texts, technical manuals without chunking; “needle-in-a-haystack” retrieval and synthesis across entire documents
- Tools/workflows: native SWA+GA long-context inference; document loaders; policy/compliance checklists; redlining and change tracking
- Dependencies/assumptions: inference engine support for SWA/GA and KV-cache optimization; governance for sensitive data; model’s knowledge recency limits; licensing for commercial distribution
- Multilingual customer-support agents with tool orchestration
- Sector: retail, airline, telecom
- Use cases: ticket changes, refunds, troubleshooting, knowledge-base search, form filling in Korean, German, Spanish, Japanese, Vietnamese
- Tools/workflows: tool wrappers for CRM, booking APIs, troubleshooting scripts; sub-agents for summarization and trajectory compression to optimize tool-call histories
- Dependencies/assumptions: integration with internal tools/APIs; verification harnesses (τ²-Bench-like); safety guardrails; robust logging and audit
- Software engineering assistant for real repositories
- Sector: software
- Use cases: guided bug triage and fixes, test generation, CLI-based workflows (Terminal-Bench), patch creation and verification (SWE-bench Verified)
- Tools/workflows: repo indexers; local terminal sandbox; unit/integration test runners; gated patch application; human-in-the-loop review
- Dependencies/assumptions: access to codebases and CI/CD; deterministic verification harnesses; change-risk policies; compute for long-context diffs
- Competitive programming and code generation copilot
- Sector: education, software
- Use cases: algorithm design, solution explanation, code drafting/refactoring for Python/C++/Java
- Tools/workflows: LiveCodeBench-style prompts; linting; performance checks; test case synthesis
- Dependencies/assumptions: up-to-date language runtimes; careful oversight for logic and security flaws
- Domain-specific Korean knowledge assistant
- Sector: public sector, education, media
- Use cases: professional Q&A (KMMLU-Pro), advanced linguistics (KoBALT), culturally-aware content generation (CLIcK), math tutoring (HRM8K)
- Tools/workflows: curated Korean knowledge bases; doc QA pipelines; curriculum-aligned prompts
- Dependencies/assumptions: ongoing domain curation; cultural sensitivity checks; localized safety policies
- Research and web-search assistant with sub-agents
- Sector: academia, R&D, market intelligence
- Use cases: web literature review, multi-page summarization, iterative evidence gathering using summarizer and trajectory compressor
- Tools/workflows: browser tools; JSON-structured research logs; reference tracking; relevance feedback loops
- Dependencies/assumptions: reliable search APIs; content deduplication; source credibility filters; network and data access policies
- Multilingual translation and localization
- Sector: media, education, enterprise localization
- Use cases: high-quality translation (WMT24++), term consistency management, domain-adapted localization for products and documentation
- Tools/workflows: terminology management; QA checklists; human-in-the-loop post-editing; SuperBPE token efficiency for cost control
- Dependencies/assumptions: domain glossaries; regional compliance and style guides; specialized evaluation for low-resource domains
- Instruction-following automation
- Sector: software, operations, knowledge management
- Use cases: workflow standardization, SOP execution, templated report generation, data extraction and formatting
- Tools/workflows: IFBench/IFEval-inspired prompt templates; structured output validation; MTP self-drafting to increase throughput
- Dependencies/assumptions: schema validators; prompt governance; inference engine support for MTP (self-drafting) to unlock speedups
- Long-context Retrieval-Augmented Generation (RAG) without heavy chunking
- Sector: software, knowledge management
- Use cases: simplified pipelines that ingest entire documents or collections; reduced context fragmentation
- Tools/workflows: hybrid RAG (index + 256K context ingestion); caching and memory-aware routing; retrieval audit trails
- Dependencies/assumptions: vector store integration; memory cost controls; clear data retention policies
- Compliance and safety review assistant
- Sector: enterprise risk, policy, legal
- Use cases: policy alignment checks, content moderation, jailbreak robustness assessment (WildJailbreak), culturally-aware safety review (KGC-Safety)
- Tools/workflows: rule-based and rubric-based evaluators; configurable risk thresholds; reporting dashboards
- Dependencies/assumptions: policy definitions; regular red-teaming; documented escalation paths
- Education and tutoring in STEM and languages
- Sector: education
- Use cases: step-by-step reasoning tutoring in math/science; language exercises; exam practice with explanations
- Tools/workflows: curriculum-aligned problem sets; reasoning traces; automated grading; preference-aligned feedback (GrouPER)
- Dependencies/assumptions: age-appropriate safeguards; content provenance; adaptation for local curricula
- On-prem and private deployments with cost-efficiency
- Sector: enterprise IT
- Use cases: internal assistants where data must stay on-prem; optimized inference via MoE active-parameter footprint and SuperBPE token efficiency
- Tools/workflows: supported inference engines (SWA/GA); quantization-aware deployment; KV-cache management
- Dependencies/assumptions: GPU availability; licensing terms for commercial distribution; capacity planning; monitoring
Long-Term Applications
The following applications are feasible with further research, scaling, integration, or productization. They build on K-EXAONE’s methods (MoE routing, FP8 training, long-context extension, verifiable RL, GrouPER preference learning, synthetic tool environments).
- Autonomous multi-day research agents
- Sector: academia, pharma R&D, market intelligence
- Concept: sustained, iterative research with trajectory compression, periodic summarization, hypothesis tracking, and verifiable evidence chains
- Dependencies/assumptions: robust memory and state management; long-horizon planning; high-quality verifiers; governance for autonomy and accountability
- Full-stack AI developer agent integrated with CI/CD
- Sector: software
- Concept: continuous code repair, refactoring, security patching, and test maintenance tied to production pipelines
- Dependencies/assumptions: strong formal verification; policy gates; reproducibility and audit trails; advanced SWE-bench-like evaluators at scale
- National-scale multilingual civic services
- Sector: public sector, policy
- Concept: citizen Q&A, form assistance, regulatory guidance in multiple languages; culturally aligned safety policies and ethical standards
- Dependencies/assumptions: updated policy corpora; fairness audits; accessibility and inclusion requirements; service reliability SLAs
- Long-horizon legal and regulatory reasoning
- Sector: legal, finance, energy, healthcare
- Concept: cross-document case-law synthesis, regulatory change tracking, impact analysis and scenario modeling over thousands of pages
- Dependencies/assumptions: domain-tuned verifiers; legal liability frameworks; explainability and provenance; human oversight
- Scientific discovery copilots with verifiable RL
- Sector: pharma, materials, energy
- Concept: hypothesis generation, experiment design, protocol drafting, and automated literature synthesis with verifiable reward signals
- Dependencies/assumptions: domain-specific validators; integration with lab tools; data licensing for scientific content; rigorous safety reviews
- Cross-lingual knowledge transfer for low-resource languages
- Sector: education, public sector, media
- Concept: extend tokenizer and data synthesis pipelines to new languages using thinking-augmented pretraining and balanced corpora
- Dependencies/assumptions: curated bilingual/multilingual datasets; community partnerships; ethical data sourcing; evaluation benchmarks per language
- Agentic workflow marketplace
- Sector: software platforms
- Concept: catalog of verifiable, synthetic tool environments (coding, analytics, operations) with standardized pass criteria and reusable evaluators
- Dependencies/assumptions: interoperability standards; secure sandboxing; reputation systems for workflows; governance of third-party tools
- Personalized knowledge management at book-length scale
- Sector: productivity, education
- Concept: continuous ingestion of emails, books, notes, reports; lifelong learning models with retrieval, summarization, and planning across 256K contexts
- Dependencies/assumptions: privacy-preserving storage; user-controlled data policies; robust local inference; explainable personalization
- Energy-efficient large-scale training and deployment
- Sector: energy, cloud providers, AI infrastructure
- Concept: mainstream FP8 training and MoE routing improvements to reduce compute/energy, plus self-drafting decoding in production
- Dependencies/assumptions: hardware and framework maturity for FP8; routing stability at larger scales; end-to-end energy measurement standards
- High-assurance safety and alignment frameworks
- Sector: enterprise risk, public policy
- Concept: standardized red-teaming, rubric-based reward modeling (GrouPER), and multi-dimension preference alignment for sensitive domains
- Dependencies/assumptions: domain rubrics; independent audits; impact assessments; continuous monitoring tools
- Healthcare long-context clinical reasoning
- Sector: healthcare
- Concept: reasoning across longitudinal patient records, imaging reports, and multi-visit histories to propose care summaries and differential diagnoses
- Dependencies/assumptions: medical verifiers; regulatory compliance (HIPAA/PHI equivalents); clinician-in-the-loop; bias and safety constraints
- Financial analysis and regulatory reporting automation
- Sector: finance
- Concept: multi-document synthesis (10-K/10-Q, prospectuses), scenario modeling, risk narratives with explainable references
- Dependencies/assumptions: domain validation; auditability; up-to-date market data feeds; model accountability frameworks
Notes on feasibility and dependencies across applications:
- Model scale and compute: 236B total parameters with ~23B active; long-context inference is memory-intensive; throughput improvements rely on MTP and engine support.
- Licensing: commercial distribution to third parties requires separate agreement; adhere to LG AI model license terms.
- Safety and compliance: integrate KGC-Safety-like checks, jailbreak testing, and domain-specific policies; ensure data privacy and consent.
- Knowledge recency and correctness: model may not reflect latest information; complement with retrieval and human review.
- Tool integration: agentic use depends on robust APIs, sandboxes, and verifiable pass criteria; maintain detailed logs and audit trails.
Collections
Sign up for free to add this paper to one or more collections.