- FineVLA advances language-conditioned robotic manipulation by aligning vision-language-action models through fine-grained instructions.
- The framework uses diverse datasets to unify and annotate robot trajectories, enhancing action-instruction alignment and policy steerability.
- Empirical results demonstrate optimal policy steerability with mixed instruction types, improving success rates and execution compliance.
FineVLA: Action-Aligned Fine-Grained Instruction for Steerable VLA Policies
Framework Overview
"FineVLA: Fine-Grained Instruction Alignment for Steerable Vision-Language-Action Policies" (2605.27284) introduces a comprehensive open-source pipeline to enable and rigorously evaluate fine-grained language conditioning in Vision-Language-Action (VLA) models for robotic manipulation. FineVLA builds a closed action-instruction alignment loop linking heterogeneous trajectory unification, human-verified process-level annotation with a ten-dimensional schema, scalable video-language annotation, and steerable policy learning under controlled mixtures of fine-grained and goal-level instructions.
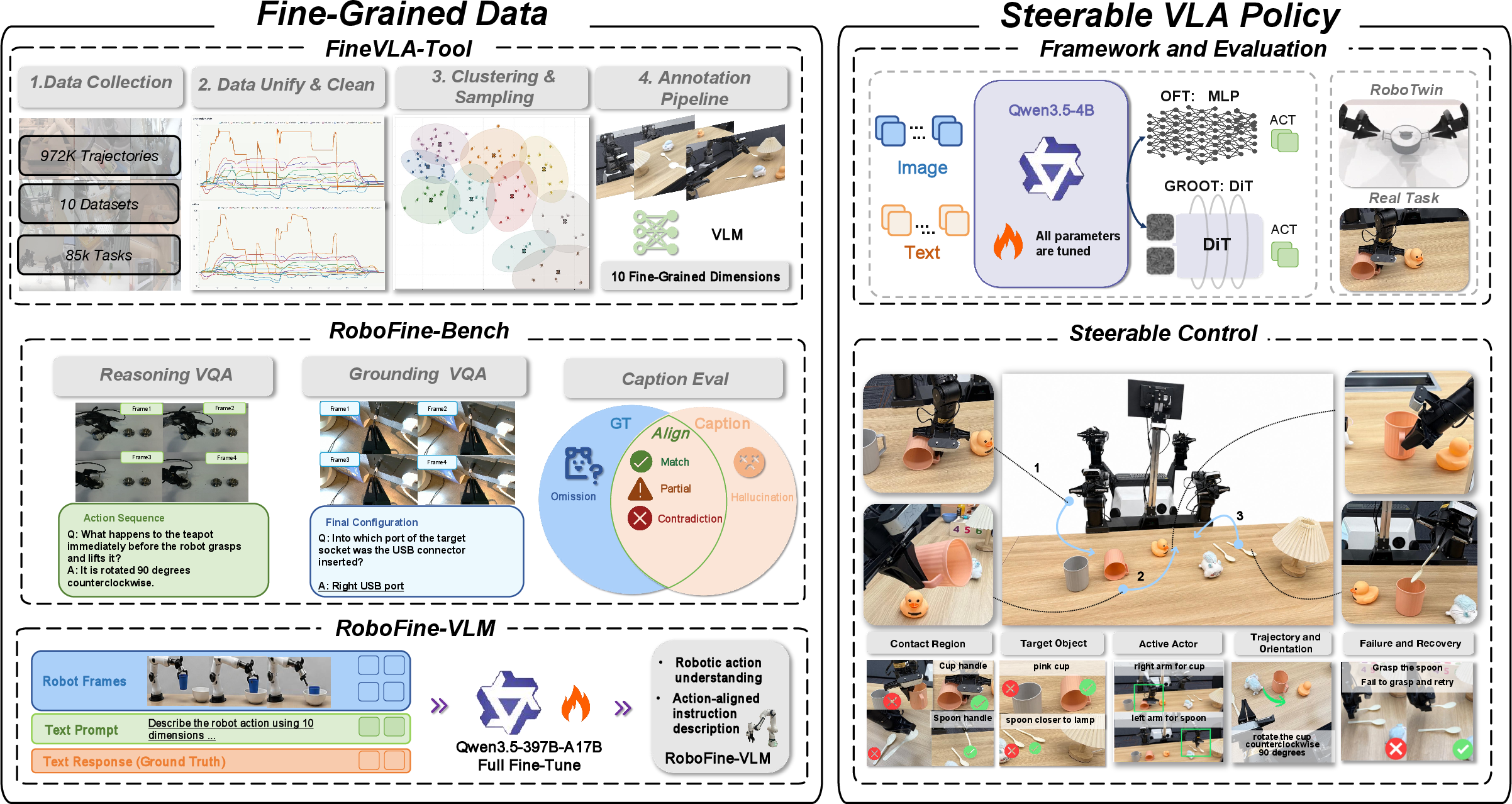
Figure 1: FineVLA architecture connecting fine-grained data generation, process-level annotation, robotic video understanding, scalable VLM-based annotation, and steerable policy training/evaluation across simulation and real-world platforms.
FineVLA-Tool aggregates 972,247 robot trajectories from ten major open datasets, canonicalizing action/state representation across embodiments and temporal conventions. Redundant demonstrations are removed with DTW-based clustering in action-space, ensuring maximum diversity per annotation budget. Representative samples are decomposed and annotated in a ten-dimensional schema covering action sequence, actor identity, target object, initial/final object configuration, contact/approach, trajectory/orientation, object interaction, failure/recovery, and body motion. Annotation is a hybrid of large-model drafting (Qwen3.5-Plus) and human review, producing FineVLA-Data: 47,159 high-density, process-level instruction episodes (average information density ∼96.8 words/trajectory, 10.4× over original coarse instruction).
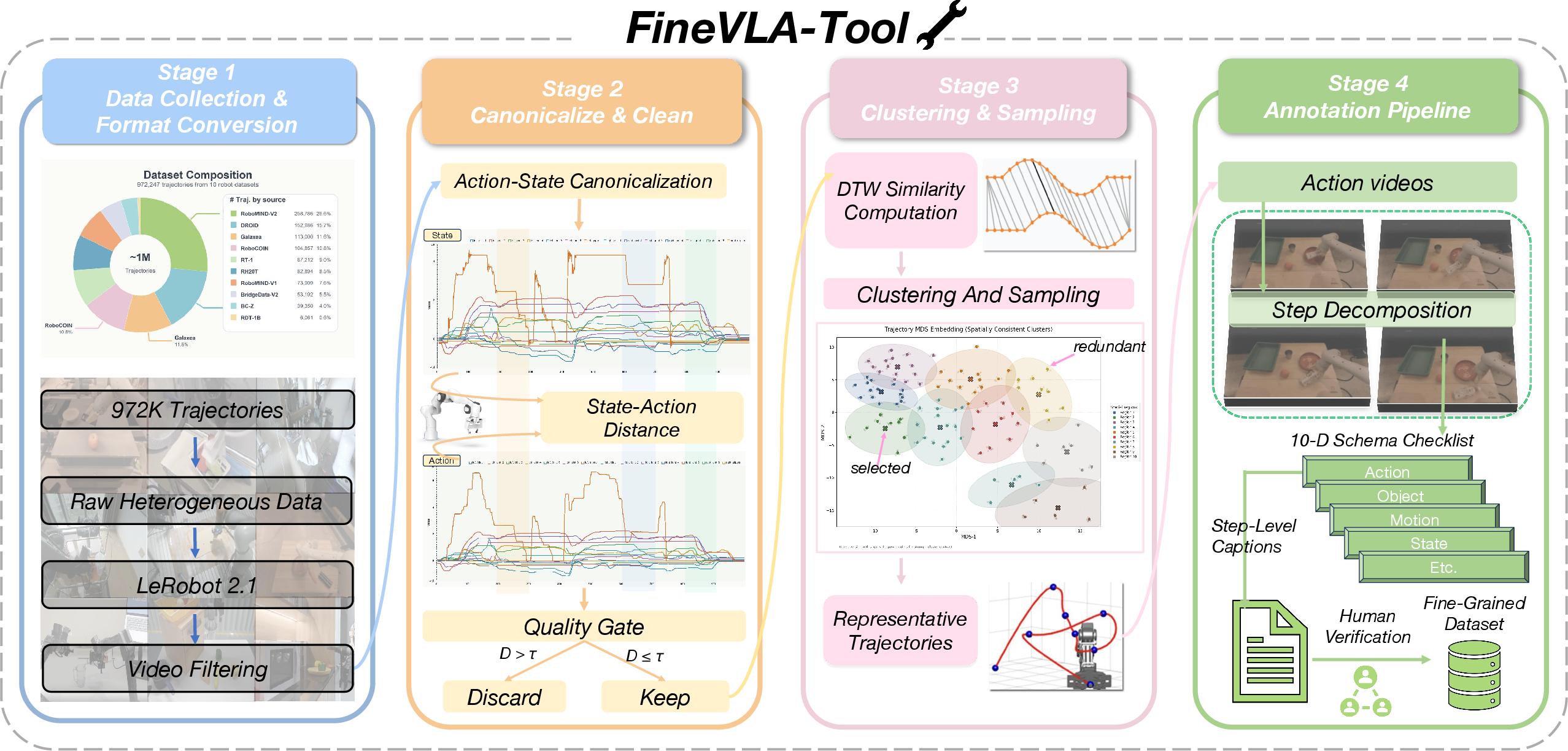
Figure 2: FineVLA-Tool pipeline: dataset unification, canonicalization, DTW-based clustering, sampling for diversity, multi-aspect annotation, human verification.
RoboFine-Bench: Fine-Grained Robotic Video Evaluation
RoboFine-Bench is a held-out video benchmark spanning 500 episodes strictly separated from policy and VLM training. Each trajectory carries step-level annotation fragmented into 10,816 atomic facts and 1,030 VQA questions aligned with the ten FineVLA dimensions. The evaluation protocol comprises:
- VQA track: Probing discriminative understanding on entity/scene grounding, action/motion reasoning, and interaction/state transitions.
- Caption track: Assessing generative alignment to ground-truth fine-grained process steps via Consistency, Coverage, and Anti-Hallucination metrics (using LLM-based judging over atomic fact sets).
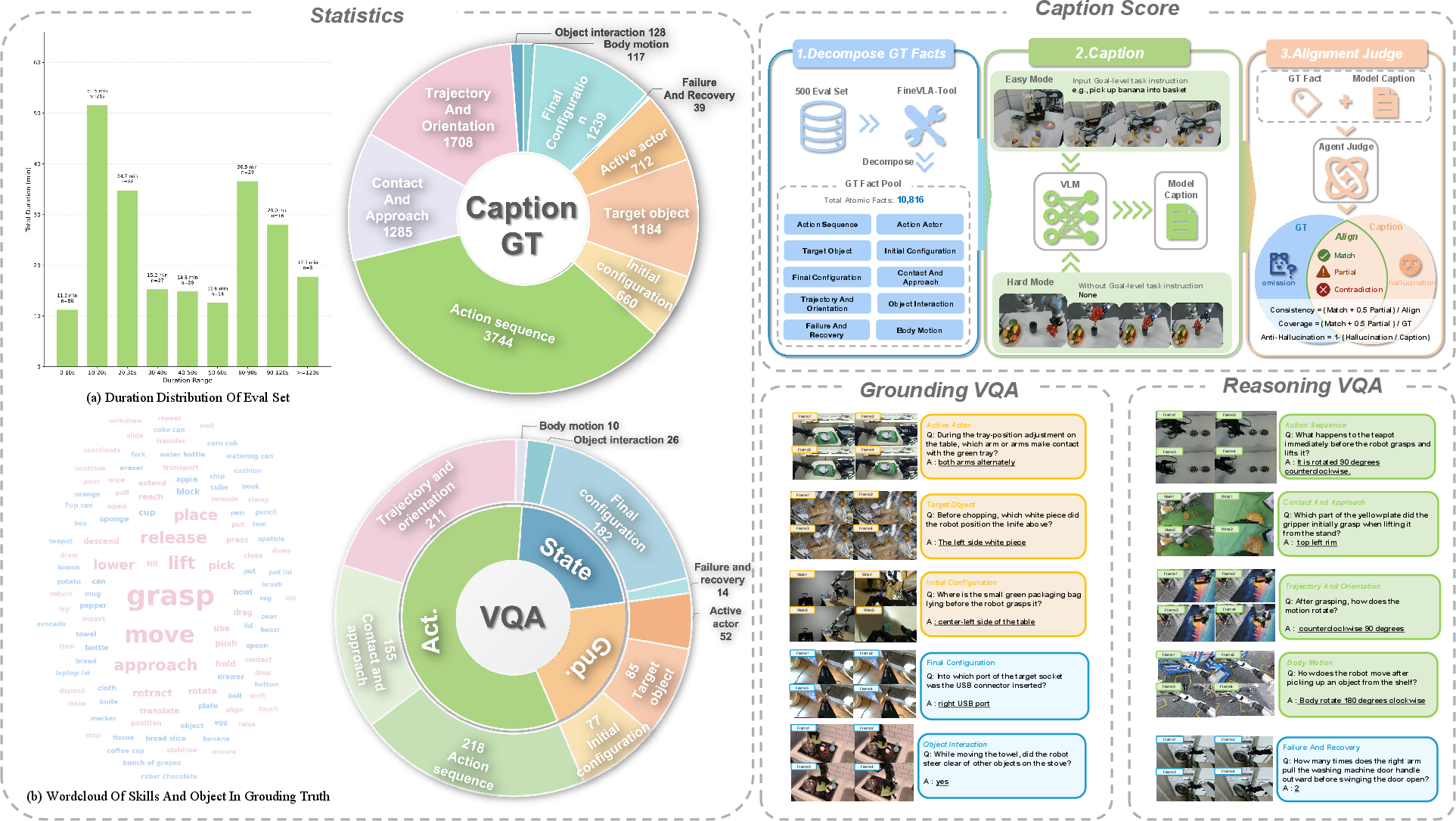
Figure 3: RoboFine-Bench structure, statistics, and task coverage: video durations, diverse manipulation skills/objects, ground-truth fact distributions; example VQA/caption probes.
RoboFine-VLM: Robotics-Specialized Scalable Annotator
RoboFine-VLM, a Qwen3.5-397B-A17B SFT on FineVLA-Data, produces action-aligned step-level captions for unseen robot trajectories, supporting scalable fine-grained annotation expansion. Unlike generic VLMs, RoboFine-VLM is tuned to produce detailed execution-relevant descriptions covering critical control factors.
Policy Training: Instruction Mixtures and Steerability
FineVLA-Policy instantiates two controlled action-decoding architectures (StarVLA-OFT and StarVLA-GR00T), always using identical visual observations and actions, modifying only the paired instruction—either raw goal-level or process-level fine-grained language. Policies are trained with various FG:Raw sampling ratios: Raw-only, FG-only, and several intermediate mixtures.
Empirical Results: Benchmark, Simulation, and Real-World
RoboFine-VLM achieves strong performance on the held-out benchmark: 71.0% overall VQA accuracy (besting Gemini-3.1-Pro by +8.9 points), with substantial gains in action/motion reasoning (68.4% vs. 58.4%) and generative caption alignment (83.6% overall under the hard setting, best across all models). Scores correlate strongly with human rankings (Pearson/Spearman ≥0.97).
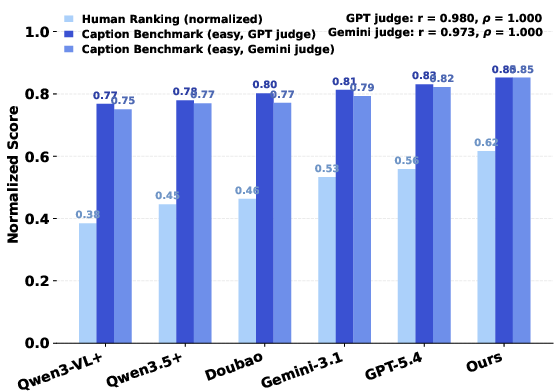
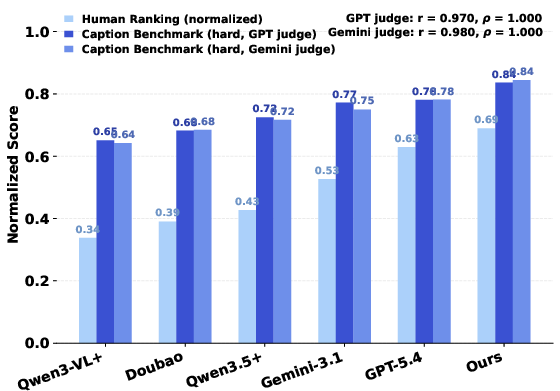
Figure 4: Caption-track model comparison in easy and hard settings; RoboFine-VLM ranks highest in both human and automatic alignment judgments.
Simulation: RoboTwin Manipulation
In RoboTwin dual-arm simulation, fine-grained (FG)-only supervision yields better success rates than raw-only across datasets and architectures (e.g., AlohaMix-OFT: +6.5/+4.7 on Easy/Hard). However, peak performance appears in mixed FG:Raw settings (1:2 or 1:1), tracing a consistent inverted-U trend. The FG:Raw=1:1 policy reaches 86.8%/82.5% on AlohaMix-OFT Easy/Hard (Raw-only: 71.8%/71.4%). Fine-grained supervision narrows architectural gaps and scales more effectively with larger, diverse training corpora.
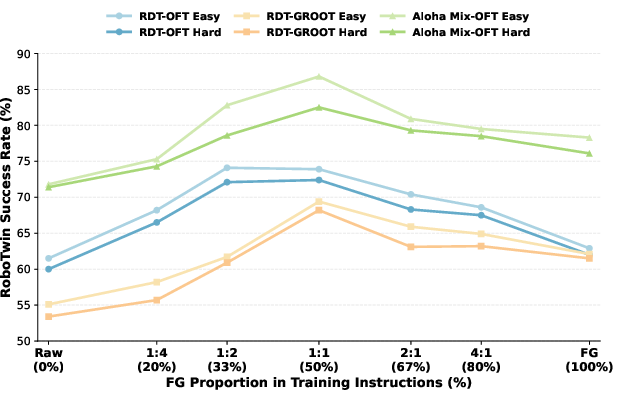
Figure 5: RoboTwin mixing-ratio curves: FG and raw instructions are complementary; optimal steerability emerges at 1:2/1:1 mixtures.
Real-World Steerable Control
Evaluated on Cobot Magic dual-arm robotic platform, mixed fine-grained/goal-level supervision (FG:Raw=1:1) maximizes in-distribution partial score (62.7/100; Raw-only: 49.9), with the largest gains on execution-sensitive factors impenetrable to goal-level language—pose (+23), color (+18), approach (+18). Language variants produce distinct manipulation strategies in otherwise identical visual contexts, indicating explicit steerability.

Figure 6: Real-world paired control factor evaluation: color, pose, approach, rotation, and arm; fine-grained language reliably modulates execution attributes.
Analysis and Implications
Instruction Mixing and Complementarity
Fine-grained supervision augments rather than replaces goal-level instruction. Pure FG-only over-specifies, potentially reducing generalization to compact goal-language, while raw-only leaves execution choices implicit. The inverted-U trend demonstrates that optimal policy steerability arises from combining both types: goal-level language encodes task semantics, fine-grained language constrains execution.
Architecture and Scaling Effects
Dense fine-grained annotation reduces reliance on specialized action-decoding frameworks, closing gaps between architectural variants and providing more benefit as dataset diversity increases. This establishes fine-grained supervision as a scalable axis independent of architectural tweaks.
Language-Critical Factor Control
Separate evaluation on language-critical control factors quantifies compliance with process-level instruction—object pose, color, approach direction, rotation, arm—proving that fine-grained annotation directly improves compliance in factors completely absent from goal-level labels.
Benchmark Validity
Caption alignment scores are robust across LLM judges (GPT-5.4, Gemini-3.1-Pro) and closely track human preferences in ranking experiments. VQA and caption tracks jointly validate coverage of the annotation schema and demonstrate that RoboFine-VLM’s alignment is not mere task-prior exploitation.
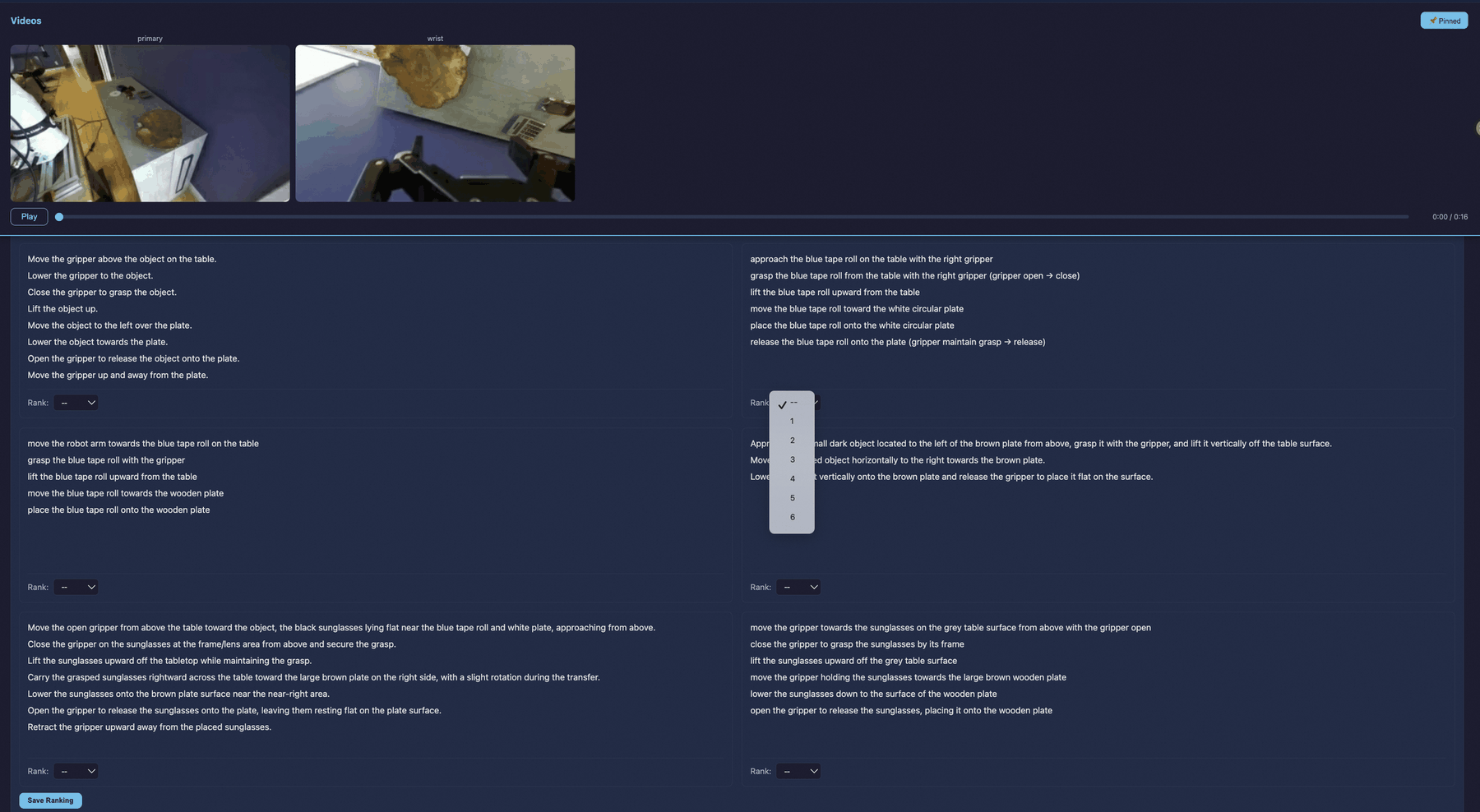

Figure 7: Human ranking interface: multi-model caption comparison for fine-grained ranking and robust benchmark validation.
Limitations and Future Directions
Remaining failures arise from grounding errors (incorrect factor selection), execution errors (unstable manipulation), and compositional generalization (incomplete actor-target binding). RoboFine-VLM still requires partial human verification for annotation quality. Real-world validation is restricted to tabletop dual-arm manipulation with limited task set. Safety-critical deployment demands integration of feasibility checks for fine-grained instruction-following.
Conclusion
FineVLA establishes a new paradigm for steerable VLA policy design grounded in action-instruction alignment, spanning comprehensive open-source fine-grained annotation, scalable robotics-specialized VLM training, rigorous video understanding benchmarks, and controlled policy evaluation. The strong empirical results confirm:
- Fine-grained supervision improves both task success and instruction-compliance without sacrificing goal-level completion.
- Optimal steerable control requires mixing goal-level and process-level instructions.
- Fine-grained annotation directly enables explicit modulation of execution-sensitive factors previously unaddressable.
The release of FineVLA’s tools, benchmark, models, and training code establishes reproducible foundations for research and broad practical deployment in instruction-conditioned robotic manipulation. Future work should expand compositional generalization, validation across broader task/embodiment regimes, and incorporate robust physical safety models for fine-grained language-following policies.