- The paper introduces AffordVLA, which implicitly injects affordance priors into vision-language-action models to enhance task-specific robotic manipulation.
- It utilizes a novel three-module architecture that aligns zero-shot affordance features with intermediate VLM representations without extra annotations.
- Experimental evaluations in simulation and real-world scenarios demonstrate significant improvements in success rates and training efficiency over existing baselines.
AffordVLA: Injecting Affordance Representations into Vision-Language-Action Models via Implicit Feature Alignment
The advancement of Vision-Language-Action (VLA) models has unlocked new levels of generality in robotic manipulation tasks, especially due to effective leveraging of pretrained Vision-LLMs (VLMs). However, a persistent limitation lies in the models' inability to robustly identify and act upon task-relevant object regions—a deficit in their affordance-aware perception. Most current VLA approaches distribute their visual attention broadly across the scene, neglecting manipulation-centric cues critical in cluttered or visually complex environments. This undermines robustness in unstructured operational spaces—a quintessential requirement for autonomous robotics deployment.
Explicit affordance-based policies address this via external perception modules or mask-based annotations but suffer from annotation scalability challenges, error propagation, and substantial inference overhead. The central goal of AffordVLA is to implicitly inject affordance priors into VLA visual representations, yielding robust, manipulation-centric policies without additional data collection or inference-time auxiliary channels.
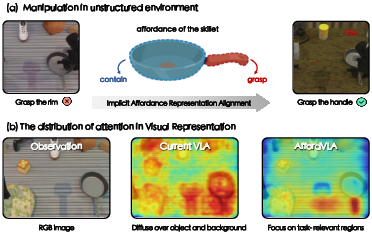
Figure 1: Existing VLAs lack affordance-aware localization, often attending to irrelevant object or background regions, while AffordVLA focuses on task-conditioned, functional interaction regions.
Architecture and Mechanism
AffordVLA introduces a threefold system: an affordance teacher, an understanding expert, and an action expert.
- Affordance Teacher: A zero-shot module utilizing high-capacity perception (Qwen3-VL for task parsing and SAM3 for visual encoding) to extract task-conditioned affordance visual representations given an image and instruction. It produces intermediate features that capture local semantic and spatial structure, rather than explicit segmentation masks, guiding subsequent learning.
- Understanding Expert: Based on a VLM backbone (Gemma-2B and SigLIP-So400m), this module integrates language, vision, and robot state into unified multimodal contextual embeddings.
- Action Expert: Utilizes bidirectional attention Transformers and conditional flow matching to predict continuous robot action chunks.
During training, intermediate visual representations from the understanding expert are aligned—via a loss that maximizes cosine similarity—with the teacher's affordance-conditioned features. Training is performed exclusively on robot demonstration data, requiring no extra annotations. At inference, the affordance teacher is omitted, ensuring the model preserves baseline VLA efficiency.
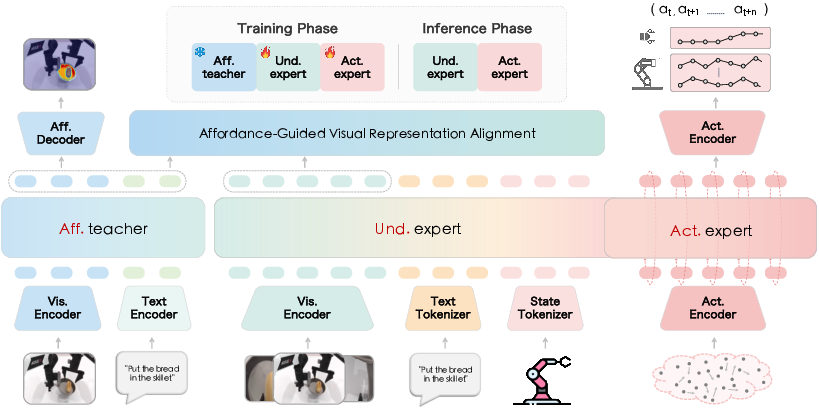
Figure 2: AffordVLA consists of an affordance teacher (training only), understanding expert (VLM backbone), and action expert; affordance supervision shapes VLA representations by alignment.
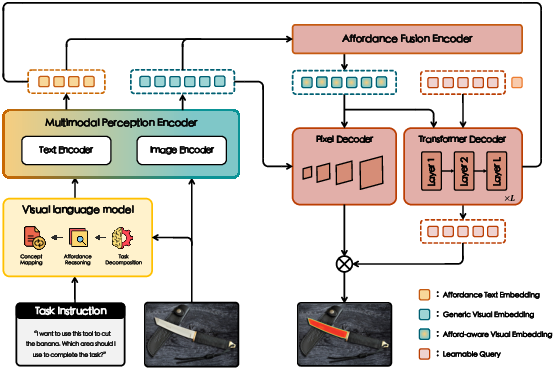
Figure 3: The zero-shot affordance teacher pipeline: (1) task parsing converts instructions/observations into affordance concept prompts; (2) an open-vocabulary perception module derives region-level affordance features.
Zero-Shot Affordance Supervision Efficacy
Extensive evaluation of the zero-shot affordance teacher on the AGD20K dataset (unseen split) validates its ability to produce high-quality task-conditioned affordance distributions without training or fine-tuning on the benchmark. Compared to both weakly supervised and other zero-shot baselines, the teacher provides substantially superior performance (KLD: 0.905, SIM: 0.496, NSS: 1.906), closely rivaling fully supervised affordance segmentation approaches.
Qualitative results further confirm that, under varied instructions and object types, the teacher's predicted regions dynamically correspond to the functionally relevant portions (e.g., handles for grasping, blades for cutting), rather than globally segmenting objects.

Figure 4: Task-conditioned affordance predictions localize functional regions based on action semantics, demonstrating open-world generalization.
Experimental Results: Simulation and Real-World
Simulation: RoboTwin2.0 Benchmark
AffordVLA achieves a mean success rate of 61.2% (Easy) and 28.8% (Hard) across five manipulation tasks, outperforming state-of-the-art baselines (e.g., DP3, RDT, π0) by large margins—up to +20.5% in certain cases under increased scene complexity. Performance retention under strong visual distractions and domain randomization highlights the utility of implicit affordance alignment for robustness.
Real-World Robotic Manipulation
Evaluation on eight real-world manipulation tasks encompassing tool use, deformable and cluttered object handling, and functional placement corroborates superior effectiveness and versatility. AffordVLA consistently delivers higher success rates compared to π0, π0.5, and explicit affordance-injection baselines. Notably, explicit concatenation of affordance masks degrades inference efficiency by over 2x and reduces reliability due to disruption of VLM feature distributions.
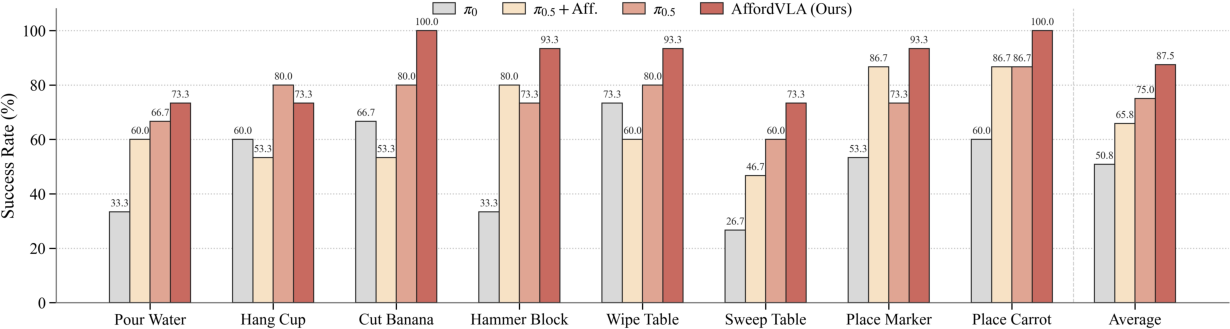
Figure 5: AffordVLA outperforms baselines in real-world manipulation success rates across diverse tasks.
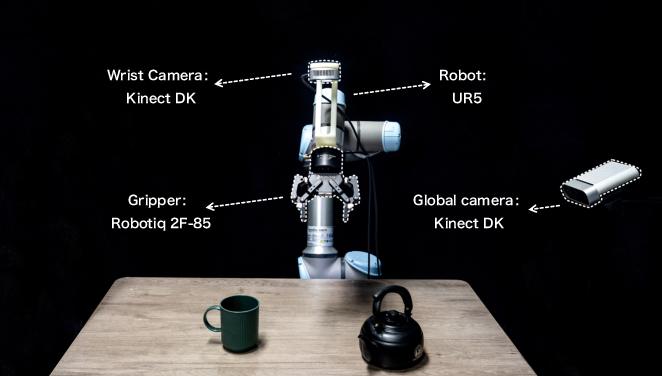
Figure 6: The physical platform used for real-world experiments: UR5 arm, Robotiq gripper, and global+tactile camera setup.

Figure 7: Qualitative action sequences by AffordVLA executing diverse manipulation instructions in cluttered and open environments.
Impact of Implicit Affordance Alignment
Ablation on the RoboTwin2.0 simulation suite reveals that removal of the feature alignment loss significantly reduces success rates, particularly in visually challenging scenarios. Attention heatmap visualizations show a post-alignment shift directing focus from backgrounds/non-functional regions to relevant object parts required for the commanded action.
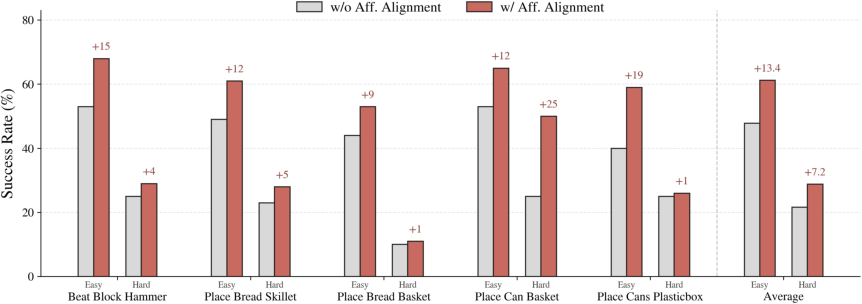
Figure 8: Incorporation of implicit affordance alignment yields marked improvements in simulation manipulation success, especially under increasing distraction.
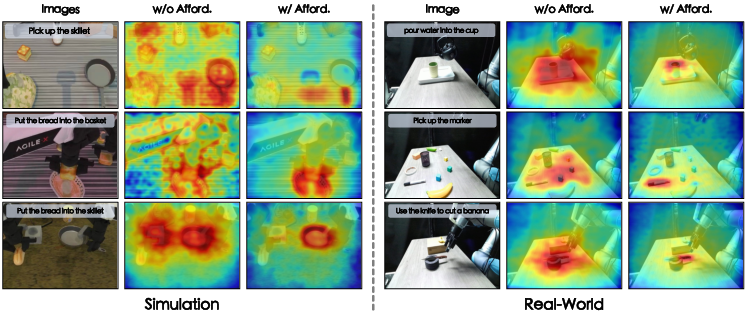
Figure 9: Visual attention migrates toward functional regions relevant to task execution following alignment.
Additionally, training efficiency improves meaningfully: to reach 45% success on RoboTwin2.0, AffordVLA converges approximately 5,200 iterations faster than non-aligned counterparts. t-SNE projections verify the induced similarity between VLA visual spaces and affordance teacher features, confirming the internalization of affordance priors in learned representations.
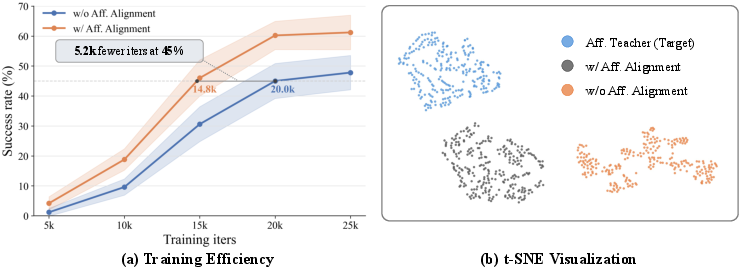
Figure 10: (a) Training speedup due to alignment; (b) Aligned features exhibit closer distributional structure to the affordance teacher as revealed by t-SNE.
Practical and Theoretical Implications
The AffordVLA paradigm demonstrates that affordance priors can be internalized efficiently and scalably into VLA models, resulting in robust, generalizable, and computationally efficient visuomotor policies. By divorcing affordance supervision from inference, AffordVLA meets the real-time demands of robotic systems without incurring annotation or latency penalties.
Theoretically, the alignment of intermediate representations enables the VLA backbone to transcend the global semantic bias of foundation models and to dynamically condition its perceptual focus based on task requirements. This approach addresses one of the most salient open challenges in bridging perception and control for generalist robots.
Future Directions
Despite strong empirical gains, caveats remain: teacher representation noise may affect training under severe scene ambiguity; affordance priors are not directly integrated into action generation, potentially limiting performance in contact-sensitive tasks; and generalization across multi-step, temporally extended, or platform-diverse scenarios remains open.
Future advancements might include hierarchical task decomposition leveraging affordance representations for stage transitions, tighter coupling of affordance cues in the policy output module, and large-scale evaluation across new robot morphologies and domains.
Conclusion
AffordVLA establishes an effective, annotation-agnostic method for affordance-aware policy learning in VLA models, advancing both the practical robustness and theoretical understanding of task-conditioned visuomotor representation alignment. This framework lays groundwork for further integration of perceptual and functional priors at scale in multisensory, open-world robotic systems.

