- The paper introduces FAV, which aligns few-step generative models using sample-based variational inference by leveraging SVGD and KDE for reward-tilted sampling.
- FAV decouples alignment from generator architecture, demonstrating robust performance across VAEs, GANs, consistency models, and flow-map variants in diverse tasks.
- FAV achieves state-of-the-art results with minimal inference overhead, addressing mode collapse and reward overoptimization while preserving sample diversity.
Summary of "Aligning Few-Step Generative Models by Amortizing Sample-based Variational Inference"
Motivation and Problem Statement
Few-step generative models—including VAEs, GANs, consistency models, and flow-map variants—achieve rapid inference but lack the sequential structure or tractable likelihoods necessary for standard alignment frameworks. Prior alignment methods rely on explicit density evaluation, stepwise trajectories, or specialized SDE/ODE solvers, all of which are incompatible or restrictive for these models. The paper introduces FAV (Few-step Generative Models Alignment via Sample-based Variational Inference), which provides a domain-agnostic, architecture-agnostic alignment framework, only requiring sample access to the generator and reference distribution. FAV casts alignment as sampling from a reward-tilted distribution anchored to a reference, leveraging SVGD for sample-based variational inference and kernel density estimation for intractable score estimation.
FAV Framework
The core of FAV is formulating alignment as sampling from the reward-tilted distribution:
q∗(x)∝pref(x)exp(r(x))
where pref(x) is the reference distribution and r(x) is a reward or utility function. SVGD updates are used to push generator outputs toward q∗, while the score of the reference is estimated nonparametrically via KDE due to its intractability for empirical data or implicit generators. The SVGD transport is amortized into the generator via fixed-point regression, allowing efficient inference without iterative transport at generation time.
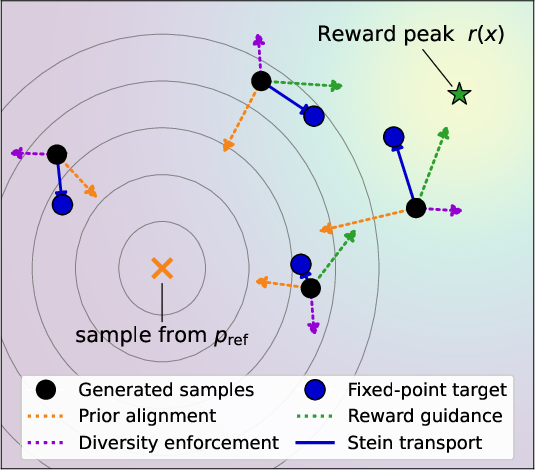
Figure 1: FAV Loss: a fixed-point regression objective distills SVGD transport into the generator, making inference efficient.
This methodology decouples alignment from generator architecture or sampling dynamics, generalizing across VAEs, GANs, consistency models, and flow-maps.
Experimental Validation
Reward-tilted Sampling: Toy and Robotics Tasks
On 8-mode Gaussian mixtures, FAV aligns diverse few-step generators (VAE, drifting, MeanFlow) to reward-tilted distributions, outperforming policy gradient or Adjoint Matching baselines in terms of KL divergence to the target. Baselines degrade or fail in few-step settings due to reliance on multi-step trajectories.
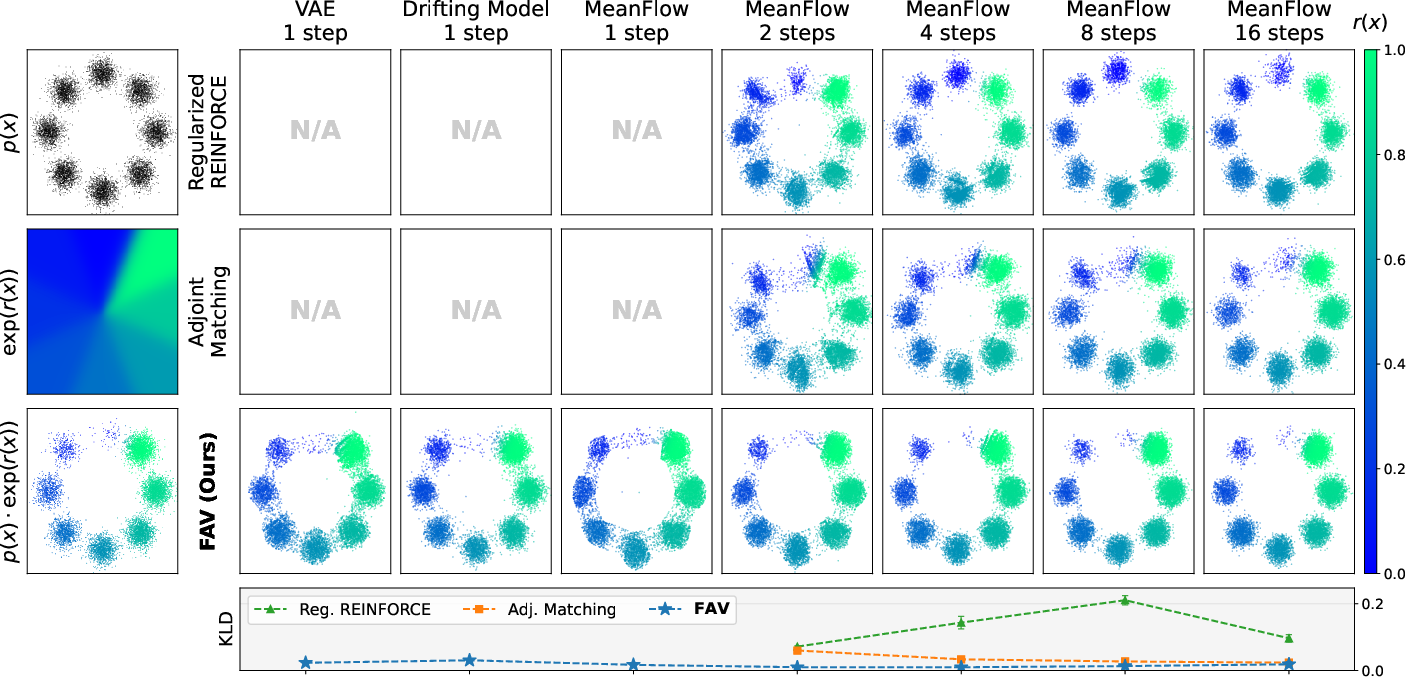
Figure 2: FAV consistently matches the reward-tilted target with lower KL than baselines, even in single-step models.
For robotic policy extraction on OGBench and D4RL, FAV (and FAV-Adaptive with automatic bandwidth selection) achieves the highest average performance on both offline and offline-to-online RL tasks, surpassing strong baselines including multi-step flow policies, latent optimization, distilled policies, and reparameterized policy gradient methods. Notably, FAV enables single-step policy extraction, mitigating credit assignment and overheads of multi-step policies.
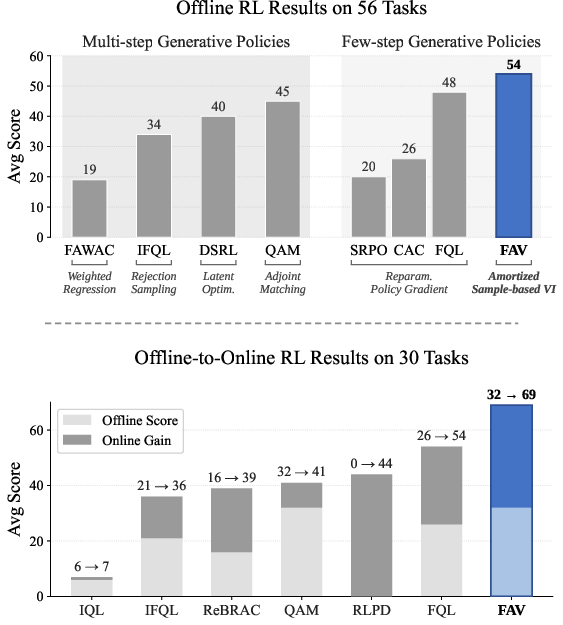

Figure 3: Left: FAV achieves state-of-the-art performance for offline and offline-to-online RL policy extraction by sampling from the Q-tilted distribution.
Image Generator Alignment
On ImageNet-256 and high-res text-to-image tasks, FAV fine-tunes GAN, consistency, and flow-map backbones for aesthetic and human preference rewards. FAV achieves Pareto-optimal tradeoffs between reward, quality, and diversity, outperforming DRaFT, Flow-GRPO, Adjoint Matching, and inference-time search methods. FAV preserves sample diversity and avoids reward overoptimization.
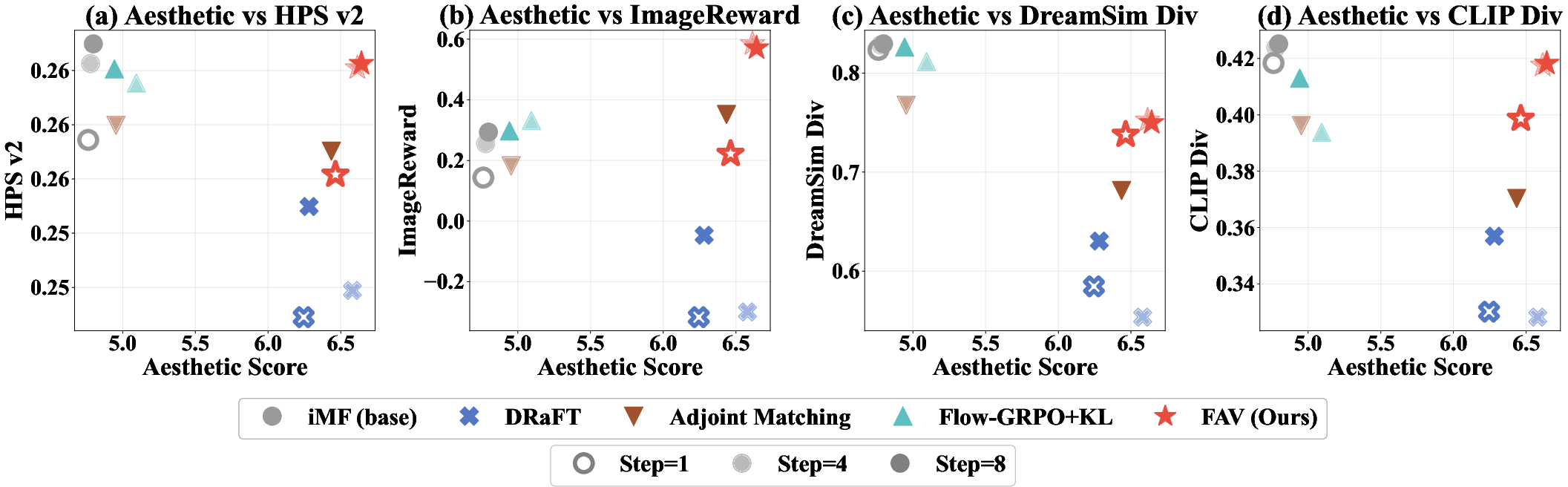
Figure 4: FAV shows Pareto-optimality between reward, quality, and diversity metrics in image alignment.
Inference-time overhead is minimal; FAV generates samples up to two orders of magnitude faster than inference-time alignment methods (Best-of-N, ReNO), while maintaining superior or comparable metrics.
Full-class and backbone generalization are demonstrated, with FAV outperforming DRaFT across all generator classes and rewards, including black-box rewards via zeroth-order gradient estimation.
Figure 3: Right: FAV improves high-resolution text-to-image generator quality under human-preference-tilted sampling.
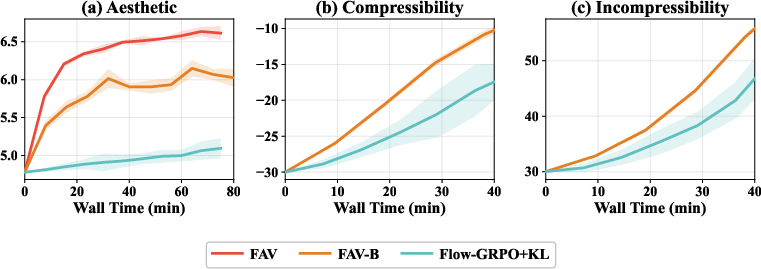
Figure 5: FAV-B achieves strong alignment using black-box rewards, outperforming Flow-GRPO+KL with greater efficiency.
Theoretical Guarantees
KDE-based score estimation in FAV is consistent in total variation under standard regularity and asymptotic conditions. The prior alignment, reward guidance, and repulsive terms in the SVGD velocity field are ablated: reward guidance is essential for reward optimization, prior alignment prevents mode collapse, and repulsive interactions marginally enhance diversity.
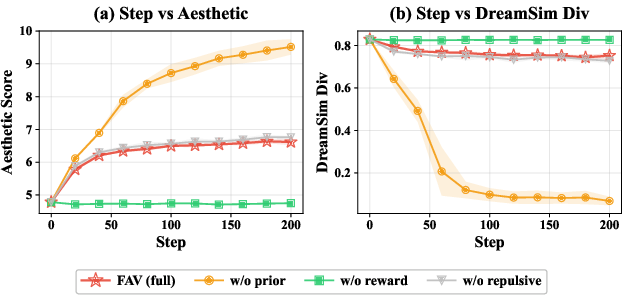
Figure 6: Ablation analysis demonstrates necessity of reward and prior terms for balanced alignment.
Kernel bandwidth τ and alignment coefficient β are critical hyperparameters governing locality and reward-diversity tradeoff; adaptive bandwidth selection (Scott's rule in FAV-Adaptive) stabilizes performance across tasks.
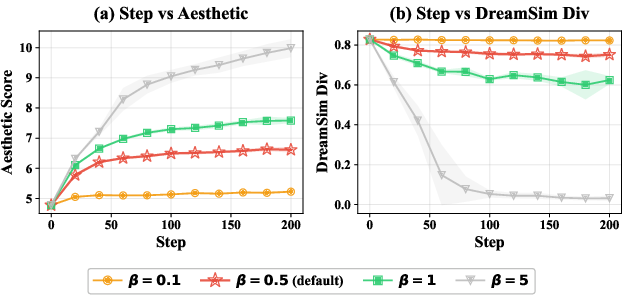
Figure 7: FAV's reward-diversity tradeoff and overall performance are sensitive to temperature β.
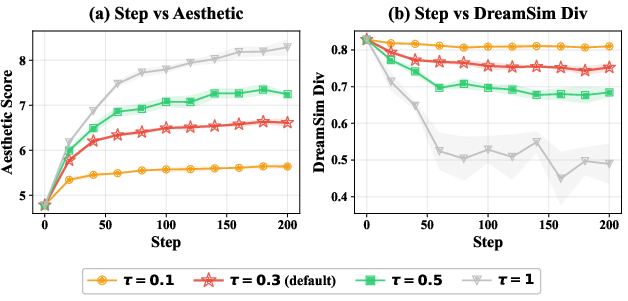
Figure 8: Kernel bandwidth τ directly modulates interaction locality and mode structure.
Implications and Future Directions
Practically, FAV enables scalable, efficient, and architecture-agnostic policy extraction and reward alignment for generative models, including high-resolution image generators and control policies. Its sample-based nature offers applicability to black-box reward settings and empirical distribution anchoring. Theoretically, the construction generalizes variational inference and SVGD-based methods to reward-aligned sampling in implicit models. The framework is robust to generator class and can readily adapt to both direct pre-training and fine-tuning regimes.
Potential improvements include more sophisticated or adaptive KDE score estimation for high-dimensional data, enhanced robustness to sparse rewards, and integration of FAV with large-scale vision or language reward models. The approach connects policy extraction in RL, preference-based image generation, and general-purpose reward-tuned sampling, and may serve as a foundation for future unified alignment routines for emerging fast-inference generative architectures.
Conclusion
FAV presents an efficient, general alignment methodology for few-step generative models, leveraging sample-based SVGD transport and KDE score estimation, and amortizing updates via fixed-point regression. Experimental results demonstrate that FAV outperforms a broad array of alignment and policy extraction baselines across robotics and vision tasks, preserves diversity, mitigates reward overoptimization, and remains efficient in both training and inference. The framework's generality, architecture agnosticism, and ability to operate in black-box settings highlight its utility for contemporary and future generative modeling applications (2605.26552).

