Continuous Adversarial Flow Models
Abstract: We propose continuous adversarial flow models, a type of continuous-time flow model trained with an adversarial objective. Unlike flow matching, which uses a fixed mean-squared-error criterion, our approach introduces a learned discriminator to guide training. This change in objective induces a different generalized distribution, which empirically produces samples that are better aligned with the target data distribution. Our method is primarily proposed for post-training existing flow-matching models, although it can also train models from scratch. On the ImageNet 256px generation task, our post-training substantially improves the guidance-free FID of latent-space SiT from 8.26 to 3.63 and of pixel-space JiT from 7.17 to 3.57. It also improves guided generation, reducing FID from 2.06 to 1.53 for SiT and from 1.86 to 1.80 for JiT. We further evaluate our approach on text-to-image generation, where it achieves improved results on both the GenEval and DPG benchmarks.




































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What’s this paper about?
This paper introduces a new way to train image‑generating models called Continuous Adversarial Flow Models (CAFMs). The big idea: take a popular family of “flow” models that turn random noise into pictures step‑by‑step over time, and teach them using a smart “critic” (a discriminator) instead of a simple “distance” rule. This helps the model make images that look more like the real data—without relying so much on extra tricks like heavy “guidance.”
What problem are they trying to solve?
Many modern image generators use “flow matching,” which learns how to push noise toward a real image by following a path through time. These models usually learn by minimizing plain old squared error (think: measuring with a straight ruler in flat space). But real images tend to live on a complicated, curved “manifold” (imagine a twisty, hilly landscape). Using a straight ruler can lead the model to generalize in the wrong way, so it may create images that don’t quite match the true data unless you add strong guidance during sampling.
The authors ask: Can we replace this fixed, simple ruler with a learned judge that better understands what “looks real,” and do it in continuous time (the same setting flow models operate in), so we can improve how the model generalizes?
What exactly do they aim to do?
In simple terms, their goals are to:
- Teach flow models with a learned critic (like in GANs) so the model learns a better sense of what “real” looks like.
- Do this in continuous time, matching how flow models naturally work (not step‑by‑step “discrete” time).
- Make this practical as a post‑training “upgrade” to existing flow models, so you don’t have to train from scratch.
- Improve how well the model’s samples match the true data distribution, both without guidance and with guidance.
How does their method work? (Plain‑language view)
Think of image generation like guiding a boat from random noise to a real image by following a river’s current over time:
- The generator learns a “velocity field”: at any moment and place (an in‑between image), it should know which direction to move next.
- Traditional flow matching trains this using a simple distance rule (mean squared error), which is like telling the boat “move the shortest straight line,” even if the river curves.
CAFMs add a learned critic:
- The discriminator (critic) looks at two things at each point in time: the real direction (how a real sample would move) and the generator’s direction (how the model wants to move).
- Instead of judging the position (the in‑between image) itself, the critic judges the direction of motion—does this direction look like a real, natural move toward a real image?
- Technically, they measure how the critic’s score would change if you move a tiny step in a given direction (this is a “directional derivative,” computed efficiently with JVP—Jacobian‑vector product). In everyday terms: “If I step this way right now, does the critic think I’m heading toward realism or not?”
Training is a friendly competition (adversarial training):
- The generator learns to pick directions the critic approves of.
- The critic learns to tell apart real directions from fake ones.
- Over time, the generator follows more natural, in‑distribution paths, and the critic becomes neutral once the generator’s directions match the real ones.
Two extra stabilizers help:
- Centering penalty: keeps the critic’s outputs from drifting too far.
- “Minimum effort” regularizer: gently prefers smaller, simpler moves so the generator doesn’t exploit weird shortcuts.
Post‑training vs. from‑scratch:
- You can attach this critic to an already trained flow model and fine‑tune it (post‑training), which is more efficient.
- You can also train everything from zero, but that’s slower.
What did they find?
In short: strong improvements, especially without guidance.
- On ImageNet 256×256 image generation:
- Latent‑space model (SiT):
- Guidance‑free FID improved from 8.26 to 3.63 after only ~10 epochs of post‑training.
- With guidance, best FID improved from 2.06 to 1.53.
- Pixel‑space model (JiT):
- Guidance‑free FID improved from 7.17 to 3.57.
- With guidance, FID improved from 1.86 to 1.80.
- On text‑to‑image benchmarks:
- GenEval overall score improved (e.g., from about 0.81 to 0.85 in one setting).
- DPG‑Bench overall improved (from about 83.7 to 85.2).
Why that matters:
- FID (Fréchet Inception Distance) is a standard score comparing the statistics of generated and real images—lower is better. Big drops mean the samples look more like the real data.
- Higher text‑to‑image scores mean the images match the prompts more accurately and look better.
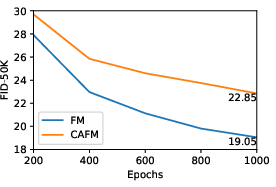
They also show that training from scratch with CAFM works, though it converges more slowly than standard flow matching—reinforcing that CAFM shines as a post‑training upgrade.
Why is this important, and what could it lead to?
- Better base models: By judging directions (how images evolve over time) with a learned critic, the generator produces images that fit the real data distribution more faithfully, especially without heavy guidance.
- Practical upgrades: Because CAFM is designed as a post‑training step, it can plug into many existing flow models to boost quality quickly.
- Manifold awareness: Replacing a fixed “straight‑line ruler” with a learned judge helps the model respect the complex shape of real image space (the “manifold”), leading to sharper, more realistic results.
- Works with guidance too: Improving the base model also improves guided results; guidance remains useful, but you might need less of it.
Caveat:
- No model perfectly captures everything, especially rare or unusual cases. Guidance and other techniques can still help when you want extra control or ultra‑high fidelity.
Overall, this paper shows a clear path to making flow‑based image generators more realistic by bringing the strengths of adversarial training into the continuous‑time world where flow models live.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable future work.
- Theory of convergence and identifiability: No formal proof is provided that the JVP-based adversarial objective yields the correct marginal velocity field under an optimal discriminator (or under finite capacity), nor conditions for uniqueness/stability of the equilibrium.
- Objective choices and f-divergence effects: The impact of different contrastive functions (hinge, logistic, f-GAN variants) on training dynamics, convergence, and sample quality is not systematically explored beyond a bounded quadratic choice.
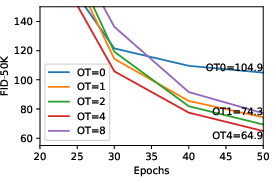
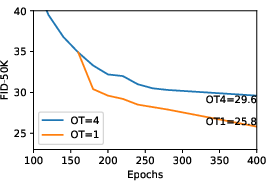
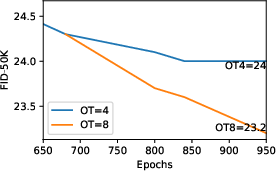
- Role and necessity of the optimal transport regularizer: Theoretical justification and empirical boundaries of when helps/hurts (especially in high dimensions) are not characterized; schedules for reducing are ad-hoc and dataset-agnostic.
- Null-space exploitation and remedies: While the scalar discriminator can leave a null space in , only a minimum-norm regularizer is considered; alternatives (e.g., multi-head/vector-field discriminators, multiple tangents per point, or contrast over subspace projections) are not investigated.
- Time reparameterization invariance: The method fixes ; whether the objective is invariant to reparameterizations of (or how to choose/learn ) is unstudied, leaving open robustness to different time scalings.
- Discriminator architecture design: The paper uses a near-G architecture with RMSNorm and a [CLS] token but does not explore architectural choices tailored for JVP (e.g., spectral normalization, Lipschitz control, convolutional vs transformer, shallow vs deep, conservative-field constraints).
- Stability without gradient penalties: Although the authors report gradient penalties are unnecessary, the conditions and failure modes (datasets, architectures, batch sizes) where penalties become necessary are not mapped.
- Computational and memory overhead: Quantitative profiling of JVP/vmap cost, multi-step discriminator updates (N), and scaling behavior with resolution/model size is missing; no throughput or wall-clock comparisons vs FM/AFM.
- Numerical precision and autodiff issues: The stability of forward-mode JVP under mixed precision, activation scaling, and long training runs is not evaluated; failure cases (overflow/underflow, exploding gradients in JVP) remain unclear.
- Sampler interactions and step efficiency: Whether CAFM changes the stiffness of the learned ODE/SDE fields, allowing fewer integration steps or different solvers, is not investigated.
- Diversity vs fidelity trade-offs: Potential mode collapse or reduced diversity (a known adversarial risk) is not assessed with precision/recall, coverage/density, or intra-FID metrics.
- Distributional faithfulness beyond FID/IS: Reliance on FID/IS/GenEval/DPG leaves gaps on calibrated distribution matching (e.g., precision/recall curves, two-sample tests, feature-wise coverage, human evaluation).
- Guidance interplay: While CAFM improves guided results, a principled analysis of how CAFM modifies the guidance landscape (e.g., CFG sensitivity, saturation, linearity) is absent.
- Generalization across modalities and tasks: Despite motivation from images and mention of video, experiments are limited to ImageNet and 512px text-to-image; applicability to audio, video, 3D, or higher-resolution image synthesis is untested.
- Robustness to dataset shift: Whether CAFM helps or harms OOD generalization (e.g., rare categories, compositional prompts, domain shifts) is not evaluated.
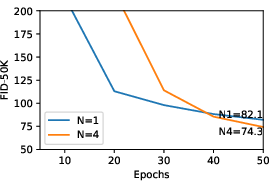
- Discriminator warm-up and schedule design: The paper uses heuristic warm-up and fixed N for post-training; the minimal compute recipe, optimal N schedules, and learning-rate strategies for stable/efficient post-training are not established.
- Post-training overfitting/instability: Risks of overfitting with longer CAFM post-training, or late-stage discriminator-generator oscillations, are not measured; stopping criteria are unspecified.
- Comparisons to manifold-aware and perceptual-loss baselines: Direct, controlled comparisons to Riemannian FM, perceptual distance training, or learned feature-space criteria are missing.
- AFM vs CAFM benefits: Claims that continuous time mitigates gradient vanishing are not backed by head-to-head comparisons against AFM under matched settings and datasets.
- Interpretability of the learned “manifold metric”: The hypothesis that D captures manifold-aware structure is not quantified (e.g., by relating D’s gradients to perceptual distances or by visualizing potential fields beyond qualitative plots).
- Conditioning alignment in T2I: Improvements in GenEval/DPG are shown, but text-image alignment metrics (e.g., CLIPScore), hallucination rates, and compositional consistency across diverse prompts are not reported.
- Safety and bias: The effect of adversarial post-training on harmful content, spurious correlations, or representational bias (given D’s strong influence on perceptual cues) is not assessed.
- Data augmentation for D: The method forgoes discriminator augmentations (common in GANs); whether augmentations (ADA, adaptive jitter, color/geometry) improve stability or generalization is unexplored.
- Scaling and reproducibility at higher resolutions: Results are limited to 256px and 512px; the method’s stability, compute feasibility, and gains at 1024px+ or with larger backbones remain untested and unreproducible from the given details.
- Conditioning on latent vs pixel spaces: Although gains are shown in both, a principled analysis of when CAFM is most beneficial (latent vs pixel, different VAEs, latent dimensionality) is not provided.
- Safety of using a scalar potential: There is no constraint enforcing that D represents a conservative field appropriate for velocity discrimination; whether enforcing conservativeness or Helmholtz decomposition would help is an open question.
- Identifiability with sparse tangents: Discriminating only along and directions may leave unobserved directions unconstrained; exploring multiple random tangents or tangent ensembles per is suggested but not tested.
- Hyperparameter sensitivity: Aside from a few ablations (mainly for pretraining), a systematic sensitivity analysis (batch size, EMA, optimizer betas, norm types, , N) is missing for post-training, which is the primary use case.
Practical Applications
Immediate Applications
The following use cases can be deployed now using the paper’s methods and implementation guidance (e.g., JVP/vmap in PyTorch, discriminator warm-up, D-to-G update ratio, RMSNorm swap, centering penalty). Each item includes sector links and feasibility notes.
- Post-training upgrade for existing flow/diffusion models
- Sectors: Software, Media & Entertainment, AI Platforms
- What: Apply CAFM post-training to pre-trained flow-matching models (e.g., SiT, JiT, Z-Image) to improve guidance-free and guided image quality (lower FID, higher IS; better GenEval/DPG alignment).
- Tools/workflows:
- Swap LayerNorm→RMSNorm in the discriminator, warm up D for 2–4 epochs.
- Use forward-mode AD for JVP, vmap for efficiency; D updates per G update N≈16; λ_cp≈1e-3; λ_ot=0 for post-training.
- Maintain original G architecture and inference sampler; reuse established DDP/FSDP training stacks.
- Assumptions/dependencies: Requires frameworks with efficient forward-mode AD (PyTorch functorch), additional compute for D and multiple D steps; reported gains demonstrated at 256px ImageNet and specific T2I settings.
- Higher-fidelity default (unguided) sampling in image/T2I products
- Sectors: Creative tooling, Advertising, Gaming, E-commerce
- What: Improve out-of-the-box sample fidelity without heavy classifier-free guidance (CFG), enabling better default results for end users and prompt alignment (e.g., improved GenEval/DPG).
- Tools/workflows: Integrate a CAFM-finetuned checkpoint as the default model; keep CFG as a user-adjustable option at lower settings (paper shows improved best FID at lower CFG vs baseline).
- Assumptions/dependencies: Gains vary by base model and content domain; results shown for SD-VAE latent and pixel-space DiT-family backbones.
- Quality control and A/B evaluation with a learned “manifold critic”
- Sectors: MLOps, Model Evaluation, Platform Safety
- What: Use the trained discriminator’s JVP signal as a learned manifold-aware critic to flag off-manifold (OOD) generations and to compare checkpoints in offline evaluation.
- Tools/workflows: Batch-score candidate generations with D_jvp(x_t, t, v, 1) as a supplemental signal alongside FID/IS; feed into QA dashboards.
- Assumptions/dependencies: D_jvp is not a calibrated metric; must be validated per domain and used as a relative comparator, not a hard safety signal.
- Better base models for downstream distillation or acceleration efforts
- Sectors: Software infrastructure, Model Compression
- What: Apply CAFM post-training before distillation or few-step acceleration pipelines to start from a more faithful base distribution (often improves sharpness/details).
- Tools/workflows: Insert CAFM finetune phase prior to standard distillation recipes; reuse the same samplers (e.g., Heun ODE, EM SDE) and evaluation harnesses.
- Assumptions/dependencies: Paper does not target few-step generation directly; acceleration benefits are indirect and must be empirically verified.
- Synthetic data generation for perception model training
- Sectors: Robotics, Autonomous Vehicles, Retail (catalog imagery)
- What: Generate more in-distribution textures, contours, and sharpness for synthetic datasets by post-training base FMs with CAFM; reduces reliance on high guidance that can bias distributions.
- Tools/workflows: CAFM-finetuned class-conditional or T2I models to produce training corpora; D_jvp-assisted filtering of off-manifold samples.
- Assumptions/dependencies: Domain shift still requires domain-specific tuning; realism gains need task-level validation.
- Domain-specific finetuning with improved fidelity (e.g., product photos, fashion, interior)
- Sectors: E-commerce, Design, Marketing
- What: Finetune base FMs on curated domain data followed by CAFM post-training to improve realism and reduce artifacts.
- Tools/workflows: Standard LoRA/adapter finetuning on domain data → CAFM post-train for 5–10 epochs; deploy updated checkpoints.
- Assumptions/dependencies: Data quality dominates; legal/data-rights considerations apply; D must co-train on representative domain samples.
- Academic research on generalization in generative flows
- Sectors: Academia
- What: Use CAFM as a controlled intervention to study how adversarial objectives alter finite-capacity generalization vs Euclidean MSE in flow matching.
- Tools/workflows: Ablate discriminator architectures, contrastive objectives, and OT regularizers; compare with manifold-aware or perceptual-loss baselines.
- Assumptions/dependencies: Findings may be architecture- and dataset-specific; needs careful experimental control.
- Inference-time scoring/triage for content moderation pipelines
- Sectors: Policy, Trust & Safety
- What: Employ D_jvp as an internal triage signal to route suspiciously off-manifold generations to stricter moderation or post-processing.
- Tools/workflows: Lightweight pass of D on selected timesteps to generate a risk score; integrate with existing moderation classifiers.
- Assumptions/dependencies: Must not be used as a sole decision-maker; calibrated thresholds and human-in-the-loop recommended.
Long-Term Applications
These concepts require additional research, domain adaptation, or scaling to become robust and widely deployable.
- Multi-modal extensions: video, 3D, and audio flows
- Sectors: Film/Animation, AR/VR, Audio
- What: Extend continuous adversarial training in derivative space to temporal (video), geometric (3D), and waveform (audio) flows to reduce OOD artifacts while preserving distribution fidelity.
- Dependencies: Efficient JVP over spatiotemporal/3D architectures; compute scaling; stability strategies for high-dimensional tangents.
- Safer, more faithful generative systems with reduced hallucination
- Sectors: Education, Enterprise content, Scientific illustration
- What: Combine CAFM with controllable sampling/guidance to keep samples closer to training distribution while achieving user intents, aiming to reduce egregious hallucinations.
- Dependencies: New guidance schemes that respect D_jvp-informed manifold constraints; user studies for safety/faithfulness trade-offs.
- Domain-critical data augmentation (medical, remote sensing)
- Sectors: Healthcare, Geospatial/Defense
- What: Investigate CAFM for generating distribution-faithful augmentations where off-manifold artifacts are costly (e.g., medical imaging).
- Dependencies: Rigorous clinical validation, bias/fairness audits, privacy compliance; domain-specific discriminators and losses.
- Learned manifold regularizers for guidance and sampling
- Sectors: Core ML, Software tooling
- What: Use the learned potential field (D) to regularize guidance or design new samplers that respect manifold-aware directions during ODE/SDE integration.
- Dependencies: Theoretical work on coupling D_jvp with sampler dynamics; stability and convergence analyses.
- Faster or lower-cost inference via reduced guidance/steps
- Sectors: Cloud AI, Edge deployment
- What: If CAFM improves base fidelity, future systems may achieve target quality with lower CFG or fewer integration steps.
- Dependencies: Systematic studies across resolutions and datasets; co-design with samplers and schedulers. Current paper does not claim step reduction.
- Dataset diagnostics and bias analysis via potential fields
- Sectors: Policy, Compliance, Data Engineering
- What: Analyze D’s learned potential landscape to detect underrepresented modes, spurious correlations, or biases in training data.
- Dependencies: Methodology to map potentials back to semantic factors; benchmarks for bias detection; interpretability tooling.
- Privacy and memorization studies
- Sectors: Policy, Privacy Engineering
- What: Explore whether improved distribution matching via adversarial flows reduces overfitting/memorization relative to MSE-trained flows.
- Dependencies: Membership inference and memorization audits; differential privacy variants for CAFM training.
- Standardized CAFM finetune kits in open-source ecosystems
- Sectors: OSS, Developer Platforms
- What: Package recipes (JVP/vmap modules, RMSNorm D, warm-up schedules, hyperparameters) for DiT/SDXL-like architectures to streamline adoption.
- Dependencies: Broad framework support for forward-mode AD; community benchmarks at multiple resolutions/modalities.
Cross-cutting assumptions and dependencies
- Compute and training stability: CAFM adds a discriminator and multiple D steps; stability relies on centering penalty, RMSNorm in D, and carefully tuned D:G update ratios.
- Framework support: Efficient forward-mode AD and vmap are required (e.g., PyTorch functorch); distributed training compatibility is critical for scaling.
- Generalization scope: Reported gains are strongest for 256px ImageNet and specific T2I setups; scaling to higher resolutions and other modalities is promising but unproven.
- Safety and governance: More realistic outputs can increase misuse risks; watermarking, provenance, and moderation should be co-developed with CAFM deployments.
Glossary
- Adversarial flow models (AFMs): A class of discrete-time flow models trained with a discriminator and generator in a minimax setup. "Adversarial flow models (AFMs)~\cite{lin2025adversarial} are a type of discrete-time flow model trained with an adversarial objective."
- Adversarial training: A minimax optimization framework where a generator learns to fool a discriminator that learns to distinguish real from generated samples. "Adversarial training involves a minimax optimization game where aims to maximize discrimination while aims to minimize discrimination by ."
- Bounded contrastive function: A specific loss function form that keeps discriminator outputs within a range to stabilize training. "we adopt a bounded contrastive function, similar to prior work~\cite{mao2017least}:"
- Centering penalty: A regularizer that keeps discriminator outputs near zero to prevent unbounded drift. "and a centering penalty~\cite{karras2018progressive} to prevent logit drifting:"
- Classifier-free guidance (CFG): A sampling technique that steers generation by combining conditional and unconditional model outputs. "For classifier-free guidance (CFG)~\cite{ho2021classifierfree}, the sweep finds that CAFMs achieve the best FID using CFG 1.3, which is lower than the original SiT at CFG 1.5."
- Conditional velocity: The time derivative of the interpolated sample conditioned on source and noise variables. "The time derivative at position conditioned on and , called the conditional velocity , can be derived as:"
- Continuous adversarial flow models (CAFMs): The proposed continuous-time flow models trained with an adversarial objective via discriminator derivatives. "In this paper, we introduce continuous adversarial flow models (CAFMs), which extend AFMs to continuous time."
- Continuous normalizing flow (CNF): A model that transforms distributions by integrating an ODE over continuous time. "CAFMs are a type of continuous normalizing flow (CNF)~\cite{chen2018neural} that generates samples by integrating an ordinary differential equation (ODE) from noise to data."
- Continuous-time flow model: A generative model operating over continuous time that transports samples via ODE integration. "We propose continuous adversarial flow models, a type of continuous-time flow model trained with an adversarial objective."
- Data manifold: The lower-dimensional structure hypothesized to underlie high-dimensional data. "However, the underlying data manifold is not known in advance and must itself be inferred and generalized from the limited training data."
- Difference equation: A discrete-time update rule used for generating samples in AFMs. "To generate, AFMs transport samples from the noise distribution to the data distribution by solving the difference equation:"
- Discriminator augmentation: Applying augmentations to discriminator inputs to stabilize adversarial training. "They rely on gradient penalties~\cite{roth2017stabilizing}, discriminator augmentation~\cite{karras2020training}, and discriminator reset~\cite{lin2025adversarial} to mitigate the issue."
- Discriminator reset: Periodically reinitializing the discriminator to counter training instabilities such as vanishing gradients. "They rely on gradient penalties~\cite{roth2017stabilizing}, discriminator augmentation~\cite{karras2020training}, and discriminator reset~\cite{lin2025adversarial} to mitigate the issue."
- Euler–Maruyama SDE sampler: A numerical method for simulating stochastic differential equations during sampling. "We use the exact inference and evaluation code provided by SiT, and use the Euler-Maruyama SDE sampler with 250 integration steps to match SiT's best setting."
- Exponential moving average (EMA): A smoothing technique for model parameters to improve evaluation stability and sample quality. "We use an exponential moving average (EMA) with a short decay of 0.99 on ."
- Forward KL divergence: A divergence measure minimized (implicitly) by flow/score matching objectives. "Flow matching, through its connection to score matching~\cite{song2021scorebased}, minimizes forward KL divergence."
- Forward-mode automatic differentiation: An autodiff mode that efficiently computes Jacobian-vector products for functions like the discriminator. "JVP can be efficiently computed with forward-mode automatic differentiation."
- Fréchet Inception Distance (FID): A metric for distributional similarity between real and generated images based on features of an Inception network. "as measured by the Fréchet Inception Distance (FID)~\cite{heusel2017gans} and Inception Score (IS)~\cite{salimans2016improved}."
- Generative adversarial networks (GANs): Generative models trained via a discriminator-generator game to match data distributions. "Generative adversarial networks (GANs)~\cite{goodfellow2014generative} are a standalone class of generative methods."
- Guidance: A technique to steer generation toward a modified or conditioned distribution during sampling. "Guidance steers the sampling process of generative models toward a modified distribution."
- Heun ODE sampler: A second-order numerical ODE solver used for deterministic sampling in flow models. "We follow JiT to use the Heun ODE sampler with 50 steps."
- Inception Score (IS): A metric assessing the quality and diversity of generated images using a pre-trained Inception classifier. "as measured by the Fréchet Inception Distance (FID)~\cite{heusel2017gans} and Inception Score (IS)~\cite{salimans2016improved}."
- Jacobian-Vector Product (JVP): The directional derivative of a function (here, the discriminator) along a given tangent vector. "we denote the Jacobian-Vector Product (JVP) of with primal and tangent as:"
- LayerNorm: A normalization technique for neural networks; here compared with RMSNorm in the discriminator. "we find that switching LayerNorm~\cite{ba2016layer} to RMSNorm~\cite{zhang2019root} significantly improves training stability"
- Manifold-aware distance: A distance metric reflecting geometry of the data manifold rather than Euclidean space. "One reason flow matching generates out-of-distribution samples is that it uses a Euclidean distance criterion rather than a manifold-aware one."
- Marginal velocity: The expected conditional velocity given the current interpolated sample, defining the probability flow’s field. "learns the marginal velocity of the probability flow"
- Mean squared error (MSE): A pointwise squared error criterion commonly used to train flow-matching models. "The mean squared error (MSE) variant, with an additional factor of , is most commonly used:"
- Ordinary differential equation (ODE): A differential equation governing continuous-time evolution used to transport samples. "integrating an ordinary differential equation (ODE) from noise to data."
- Optimal transport objective: A regularization term encouraging minimal movement between source and target states for stable training. "AFMs additionally introduce an optimal transport objective on :"
- Optimal transport regularization: A continuous-time penalty encouraging minimum-norm velocities to resolve discriminator null-space ambiguity. "The continuous-time optimal transport regularization on is equivalent to its discrete counterpart in \cref{eq:ot_discrete} in the limit of :"
- Perceptual distance: A learned feature-space distance intended to better reflect human perception than Euclidean norms. "replaces Euclidean loss with perceptual distances derived from frozen feature networks"
- Probability flow: The trajectory of distributions evolving over time between a prior and the data distribution. "flow matching (FM) learns the velocity field of a probability flow~\cite{song2021scorebased} between noise and data distributions."
- R1 and R2 gradient penalties: Regularizers applied to discriminator gradients to stabilize adversarial training. "Additionally, is regulated by gradient penalties and ~\cite{roth2017stabilizing} to mitigate the problem of vanishing gradient"
- Riemannian flow matching: An extension of flow matching to non-Euclidean geometries defined on manifolds. "Riemannian flow matching~\cite{chen2023flow} extends flow matching to non-Euclidean geometries"
- RMSNorm: A normalization variant using root mean square statistics; found to improve stability in the JVP-based discriminator. "we find that switching LayerNorm~\cite{ba2016layer} to RMSNorm~\cite{zhang2019root} significantly improves training stability"
- Score matching: A training principle relating to learning gradients of log-densities (scores), connected here to flow matching. "Flow matching, through its connection to score matching~\cite{song2021scorebased}, minimizes forward KL divergence."
- Vectorizing map (vmap): A functional transform that vectorizes computations (e.g., multiple JVPs) for efficiency. "Additionally, we use vectorizing map (vmap) to efficiently compute multiple tangents at the same primal when updating ."
- Vanishing gradient problem: A failure mode where gradients become too small for effective learning, especially in adversarial setups. "Additionally, is regulated by gradient penalties and ~\cite{roth2017stabilizing} to mitigate the problem of vanishing gradient"
Collections
Sign up for free to add this paper to one or more collections.