- The paper introduces RTDMD, a framework that merges distribution matching distillation with reward-tilted reinforcement learning to optimize few-step generators.
- It employs ambient conditioning and consistency regularization to stabilize training and enhance the fidelity of text-to-image outputs.
- Empirical results demonstrate superior performance on metrics like CLIPScore, PickScore, and HPSv2 across multiple model backbones compared to previous methods.
Reinforcing Few-step Generators via Reward-Tilted Distribution Matching
Introduction and Motivation
Efficient generative modeling has seen substantial advancements through the distillation of multi-step diffusion models into "few-step" architectures, which retain generative competence while drastically reducing inference cost. However, such few-step generators typically face difficulties in aligning sample distributions with nuanced human-centric rewards due to their constrained trajectory space and inherent training instabilities. The paper "Reinforcing Few-step Generators via Reward-Tilted Distribution Matching" (2605.26108) proposes Reward-Tilted Distribution Matching Distillation (RTDMD), a unified two-stage framework that systematically integrates distribution matching distillation (DMD) with reinforcement learning (RL)-driven reward optimization for text-to-image flows.
Framework: Reward-Tilted Distribution Matching Distillation (RTDMD)
RTDMD minimizes the KL divergence from the student distribution to a "reward-tilted" teacher distribution, p~ψ(x)∝pψ(x)exp(βr(x)), where pψ is the base model, r(x) is an extrinsic reward (e.g., preference score), and β controls reward intensity. Crucially, the gradient for this objective decomposes into (1) a distribution matching term and (2) a direct reward maximization term, motivating a staged optimization pipeline.
Stage 1: Ambient-Consistent Distribution Matching Distillation (AC-DMD)
The first stage executes cold-start distillation. Conventional DMD faces two barriers: training the student and fake score networks on increasingly noisy latent trajectories and unstable generator distributions, especially given the limited update regime required for few-step generators. AC-DMD addresses these by:
- Performing distribution matching not only over the entire path but focusing on subintervals emerging from each noisy intermediate latent, improving local optimality of the fake score fitting.
- Introducing a consistency regularizer on the fake score model, enforcing self-consistency across predictions over adjacent time slices, inspired by recent advances in self-consistency for denoisers.
This regularization yields greater stability and more faithful tracking of the evolving student distribution under limited compute, as evidenced by clear improvements in qualitative generations.

Figure 1: Visual generations produced by RTDMD under 4 NFE on FLUX.2 4B, showcasing high-fidelity and prompt-faithful samples without classifier-free guidance.


Figure 2: Qualitative comparison of different distillation methods (AC-DMD with various γ) highlighting the stabilizing effect of consistency regularization during cold-start training.
Stage 2: Joint Distribution Matching and Reward Maximization
Following cold-start, stage two performs joint optimization using the complete KL decomposition. Here, RTDMD makes several technical contributions:
- Hybrid Policy Gradient: Few-step generators entail a mixture of stochastic (intermediate) and deterministic (final) steps. RTDMD derives a principled hybrid estimator: stochastic steps are optimized with a group-normalized REINFORCE objective (GRPO) variant, while deterministic final steps receive direct gradient backpropagation from the differentiable reward.
- Step-Subset GRPO (SubGRPO): To reduce gradient variance, SubGRPO leverages shared noise among non-selected steps, attributing reward differences more reliably to the subset of interest, effectively generalizing Rao–Blackwellized variance reduction to this context.
These refinements enable robust reward propagation across short-step generators, yielding superior alignment with both differentiable and non-differentiable reward metrics.
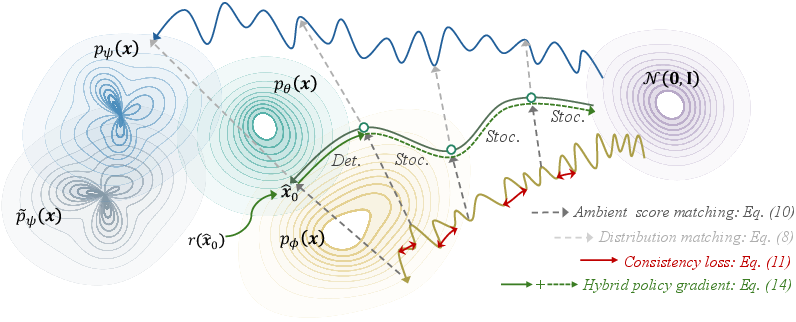
Figure 3: Overview of RTDMD, visualizing the interplay of deterministic and stochastic steps and the flow of gradients for effective reward optimization.


Figure 4: Comparison of reinforcement learning strategies post cold-start, illustrating the qualitative improvements of SubGRPO and the necessity of including the deterministic final step in the reward gradient.
Empirical Evaluation
RTDMD demonstrates substantial improvements over strong baselines across diverse model backbones (SD3-M, SD3.5-M, FLUX.2 4B), benchmarks, and reward types:
- Quantitative: On SD3-M at 4 NFE, RTDMD achieves a CLIPScore of 0.3161, a PickScore of 22.86, and HPSv2 of 0.3211, consistently outperforming RL-only, DMD-only, and prior RL+DMD hybrids (e.g., GDMD, DMDR, Rdm) often by statistically significant margins.
- Generalization: On challenging compositional benchmarks (GenEval, GenEval2, OCR), RTDMD achieves competitive or superior results versus much larger or longer-step models, indicating strong reward transfer and distributional alignment.
- Qualitative: Visual inspection reveals consistently higher prompt adherence and aesthetic quality, especially under significant step reduction (e.g., 4 NFE), compared to standard DMD or RL-only approaches.



Figure 5: Qualitative comparison at 4 NFE; RTDMD achieves superior prompt fidelity and compositional accuracy versus baseline few-step models using identical noise seeds.
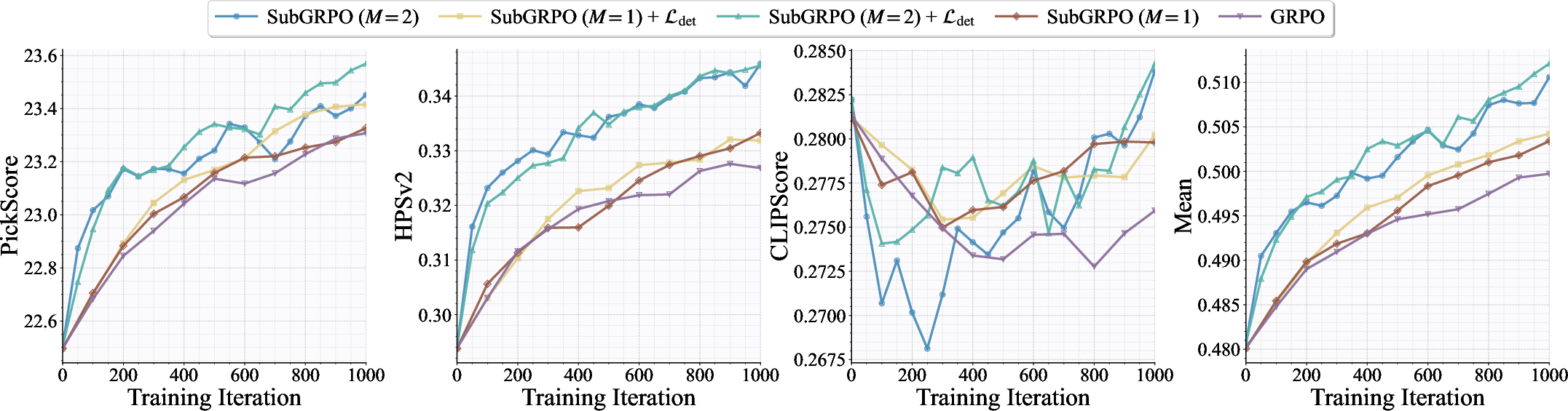
Figure 6: Evaluation curves for PickScore, HPSv2, and CLIPScore, demonstrating rapid and stable convergence in the final reward-optimization stage.
Ablation Studies
Ablation confirms:
- The inclusion of ambient conditioning and consistency regularization in AC-DMD robustly improves fake score tracking and resultant student generations.
- SubGRPO yields lower-variance and higher-performing gradients than naive GRPO, especially when selecting an optimal subset size (M=2).
- Including the deterministic final step in gradient computation (hybrid policy gradient) consistently boosts all relevant reward metrics.
Theoretical and Practical Implications
The RTDMD framework offers a general methodology for aligning few-step diffusion or flow models to arbitrary reward landscapes, elegantly unifying DMD with RL through KL-divergence minimization to a reward-tilted target. This result theoretically clarifies how policy gradients and score-based distillation jointly influence sample quality and reward alignment, bridging prior ad-hoc or heuristic hybrids. Practically, it enables single-stage, low-latency generation (4-step) with state-of-the-art quantitative and qualitative outcomes across modern diffusion backbones, without sacrificing prompt fidelity or compositional complexity.
Future Directions
RTDMD opens avenues for:
- Applying reward-tilted matching to domains where reward signal is sparse or non-differentiable (e.g., video, editing, open-ended creative generation).
- Integrating additional off-policy or constraint-based reward signals, or considering distributed/online scenarios with evolving human feedback.
- Extending the framework to multi-modal or temporally-structured conditional generative tasks where trajectory length and reward sparsity present distinct challenges.
Conclusion
RTDMD establishes a theoretically principled and empirically validated framework for reward-driven few-step generator training. By decomposing reward-tilted KL divergence into precise distribution-matching and reward-gradient terms, and stabilizing these with ambient conditioning, consistency regularization, and low-variance hybrid gradients, RTDMD achieves state-of-the-art few-step text-to-image generation. The method’s flexibility and sample efficiency make it a substantial reference point for both theory and large-scale generative modeling practice.

Figure 7: Additional visual generations from RTDMD (FLUX.2 4B, 4 NFE) illustrating prompt diversity and high sample fidelity without classifier-free guidance.