- The paper introduces the Fleming-Viot Diffusion (FVD) algorithm, which uses a novel birth-death resampling mechanism to maintain diversity during inference.
- It integrates adaptive control of selection pressure and stochastic rebirth to balance reward maximization with comprehensive sample distribution.
- Empirical evaluations on MNIST, CIFAR-10, and text-to-image tasks demonstrate FVD’s superior performance, efficiency, and scalability over existing methods.
FVD: Inference-Time Alignment of Diffusion Models via Fleming-Viot Resampling
Overview
The paper "FVD: Inference-Time Alignment of Diffusion Models via Fleming-Viot Resampling" (2604.06779) addresses the challenge of reward alignment in diffusion models without retraining or fine-tuning, focusing on inference-time procedures to steer sample generation toward reward-favored distributions. The central proposal is the Fleming-Viot Diffusion (FVD) algorithm, which leverages a birth-death resampling paradigm inspired by population genetics (Fleming-Viot processes) to overcome catastrophic diversity collapse exhibited by prior Sequential Monte Carlo (SMC) and particle-based methods. FVD integrates adaptive control of selection pressure and stochastic rebirth mechanisms to achieve scalable, parallel inference-time alignment with empirical superiority over established baselines.
Motivation and Prior Methods
Diffusion models are widely deployed in various generative tasks, often with the practical requirement of reward alignment—where generated content must maximize task-specific, perceptual, or preference-based reward functions while remaining well-distributed on the learned data manifold. RL-based fine-tuning approaches (e.g., DDPO, DPOK, D3PO, DiffDPO) are computationally intensive and require retraining whenever the reward function changes. In contrast, inference-time alignment methods modify the sampling trajectory to target the reward-favored distribution π∗(x)∝pθ(x)exp(λr(x)), sidestepping model parameter updates.
Classical inference-time methods can be categorized as follows:
- Gradient-based guidance: Requires differentiable rewards and incurs per-step gradient computational overhead; often destabilizes the denoising chain.
- Particle-based SMC: Maintains a population of trajectories but suffers severe diversity collapse due to aggressive multinomial resampling.
- Search-based and value-function approaches: Either inefficient at scale (search-based), or computationally costly due to rollouts and limited parallelism (value-based, e.g., DTS).
The main failure mode in particle-based SMC is the rapid loss of diversity under strong selection, leading to over-optimized but non-diverse samples that concentrate on narrow modes (mode collapse).
Fleming-Viot Diffusion (FVD): Methodological Innovations
FVD replaces multinomial resampling in SMC with a Fleming-Viot process—an interacting particle system characterized by independent Bernoulli survival and uniform donor selection. This decouples selection from replication, bounding offspring variance, and significantly mitigates lineage collapse.
Key methodological components:
- Survival and Death Mechanism: At each resampling step, each particle independently survives with probability determined by a normalized potential based on reward proxies (e.g., Tweedie estimate). Dead particles are revived via uniform random donor selection and stochastic DDIM rebirth noise, ensuring trajectory divergence and preventing deterministic path collapse.
- Adaptive Selection Pressure: The absorption rate (fraction of deaths per step) is monotonic in alignment strength λ, enabling Robbins-Monro-style online adaptation to a target absorption rate α∗. This provides an interpretable, reward-scale-independent knob for diversity exploitation trade-off.
- Fully Parallelizable Architecture: FVD maintains parallelism and scales efficiently with compute, in contrast to sequential tree search methods like DTS.
Empirical Evaluation
Class-Conditional Posterior Sampling
On MNIST and CIFAR-10, FVD demonstrably outperforms FKD, DTS, and other baselines in terms of FID, MMD, and mean reward, while preserving sample diversity. In particular:

Figure 1: FVD and DTS preserve diversity and data distribution alignment on CIFAR-10, avoiding mode collapse seen in FKD and TDS.
Text-to-Image Generation
For prompt-conditioned and aesthetic optimization benchmarks (DrawBench, LAION Aesthetic Predictor):
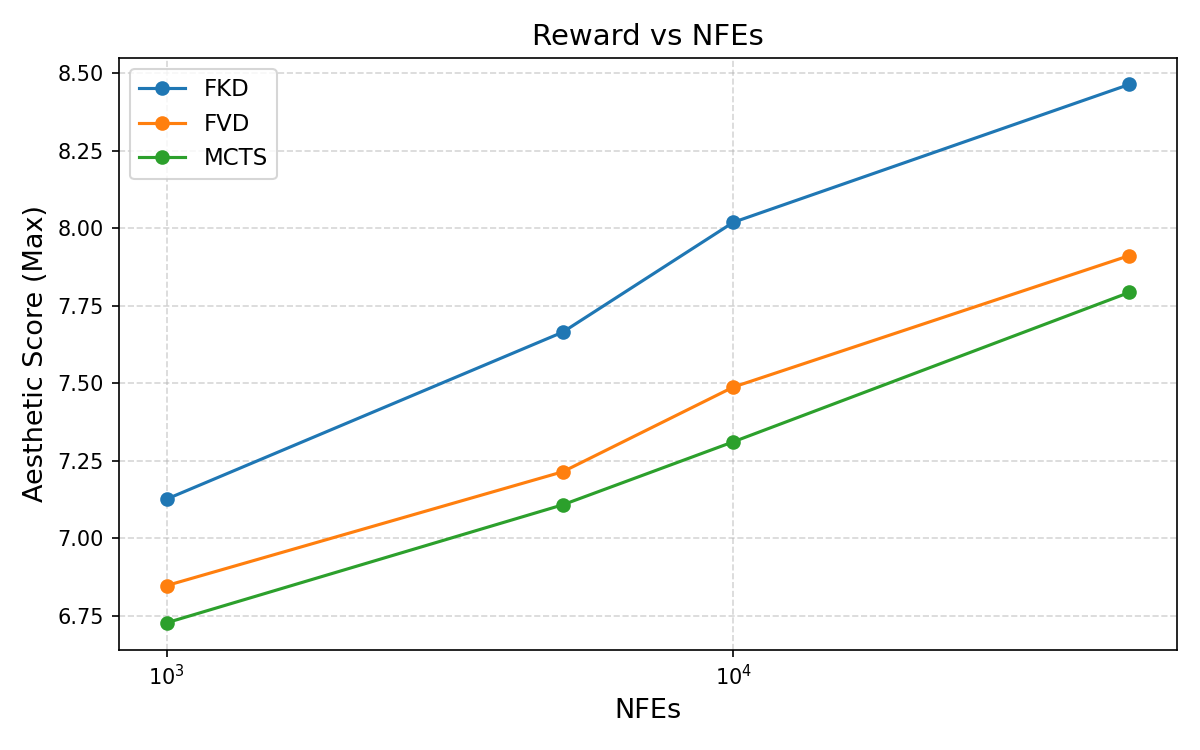
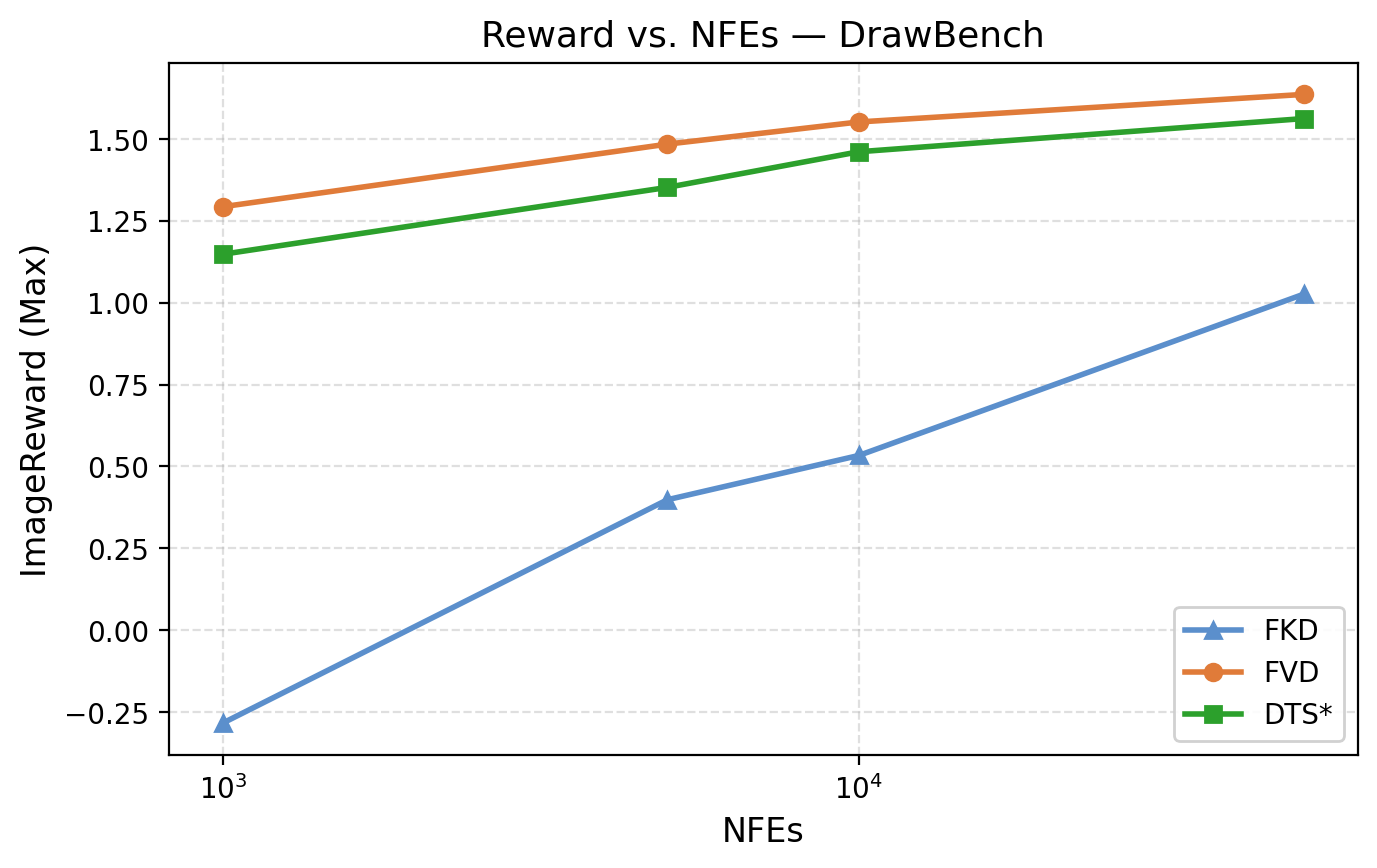
Figure 3: FKD attains highest raw rewards but overfits; FVD achieves competitive rewards with superior visual fidelity.
Diversity Preservation and Collapse Analysis
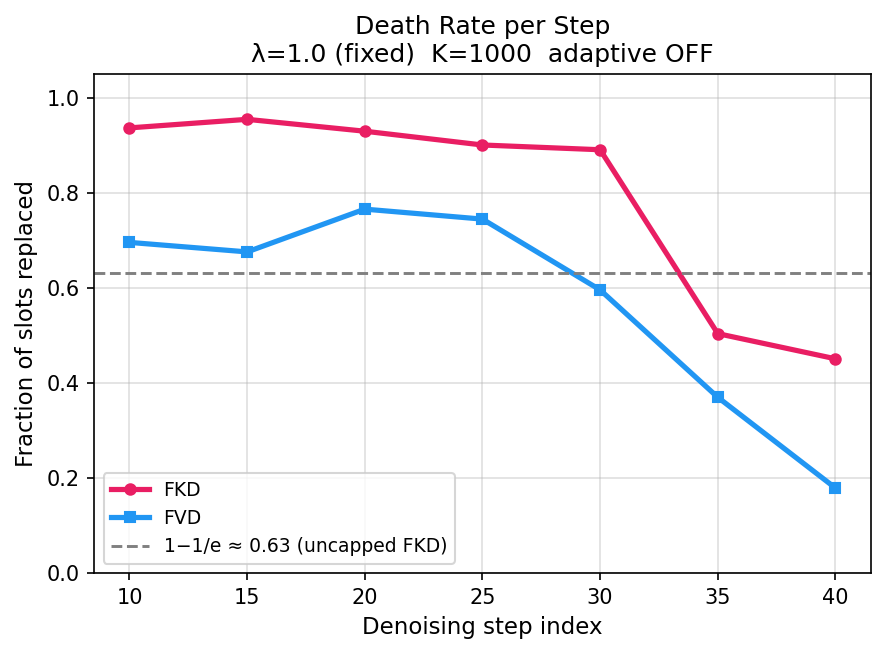
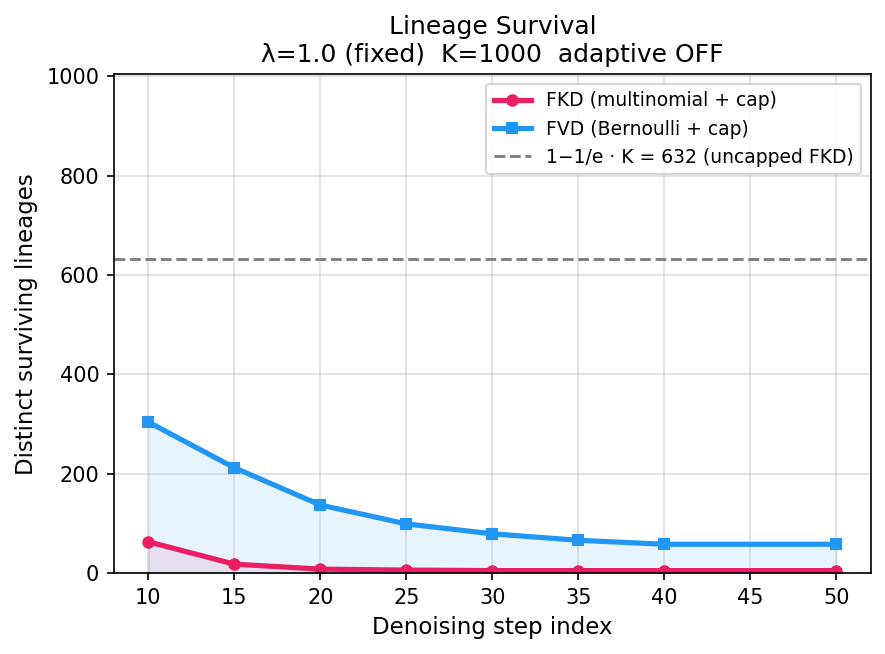
Figure 5: FVD maintains lower death rates and retains significantly more distinct lineages than FKD during denoising.
- Quantitative lineage analysis: FVD preserves ∼10× more lineages than FKD, fundamentally improving diversity retention.
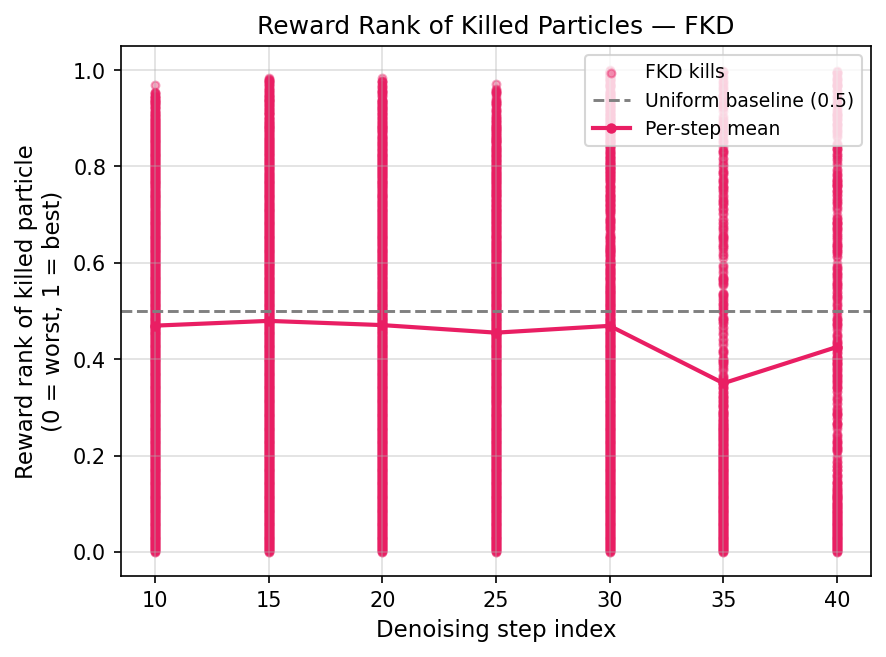
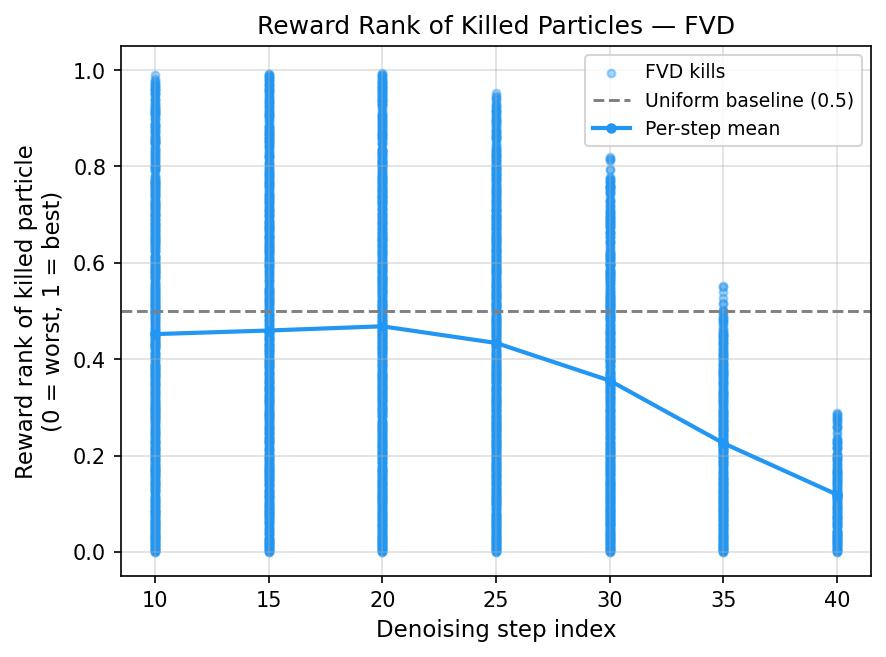
Figure 6: FVD concentrates particle removals among low-reward samples while FKD removes particles indiscriminately across reward ranks.
- Reward specificity in FVD's survival mechanism provides selective pruning, preserving high-reward candidates.
Efficiency and Adaptivity
- FVD is approximately 66× faster than value-based DTS at matched NFEs (wall-clock), offering substantial practical benefits for scalable deployment.
- Robbins-Monro adaptive control for λ delivers improved FID and stability over fixed settings, especially in regimes of non-optimal manual tuning.
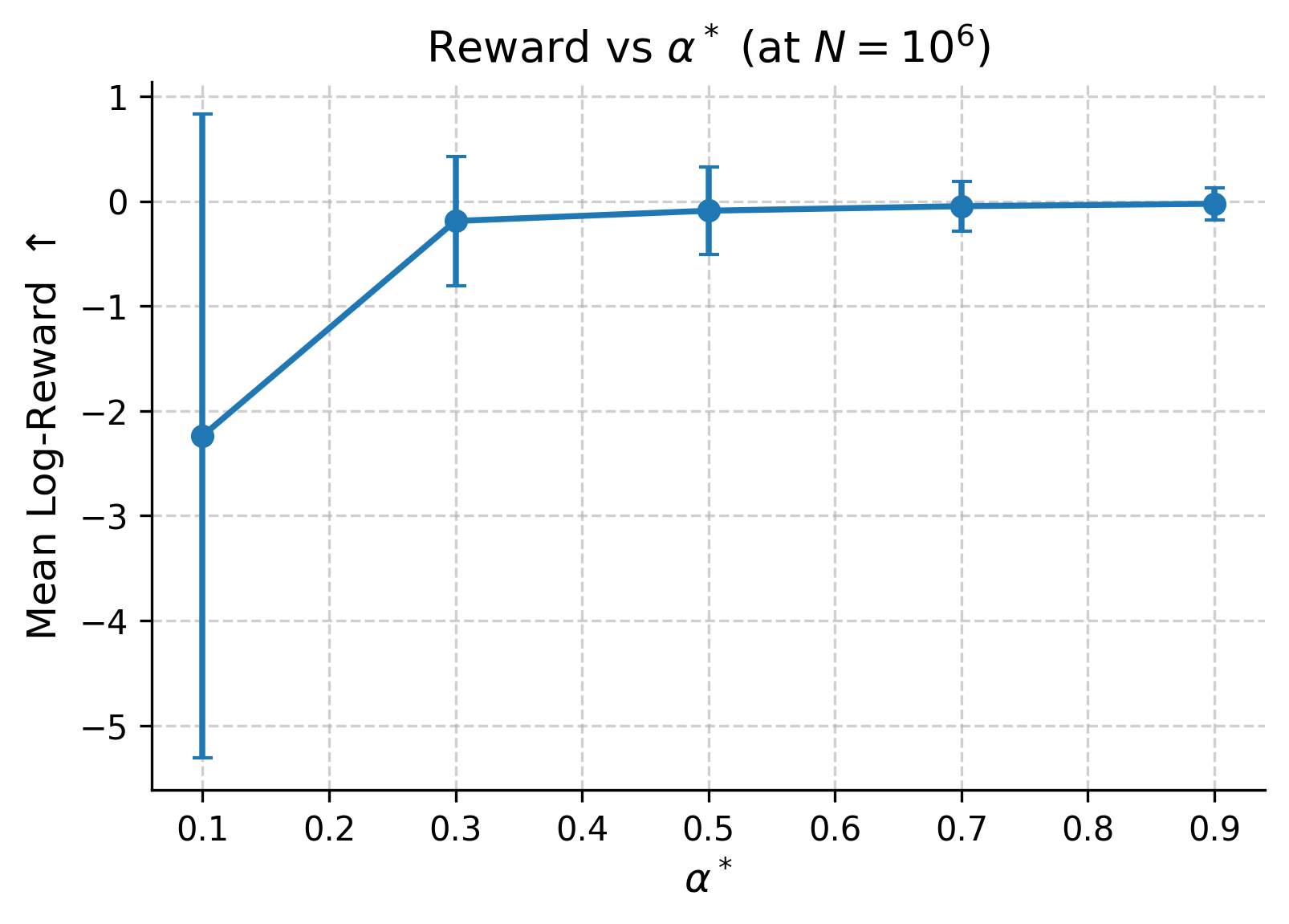
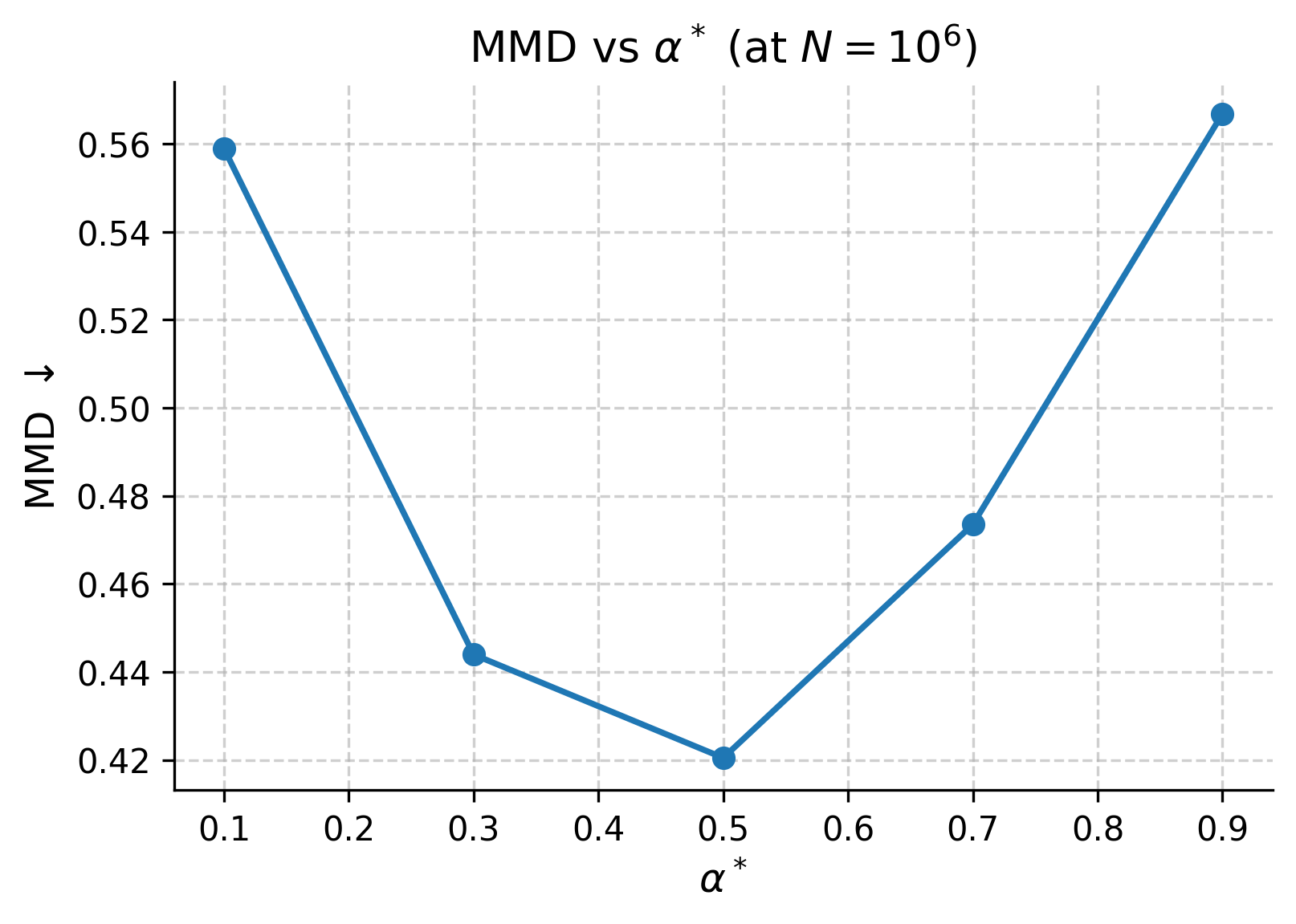
Figure 7: α∗ tunes the reward-diversity trade-off; intermediate values optimize coverage and reward without collapse.
- Target absorption rate directly controls selection strength, enabling interpretable tuning of diversity vs. reward maximization.
Theoretical Underpinnings
The practical FVD algorithm is motivated by large-population mean-field analysis: in the idealized Fleming-Viot process, the empirical law of resampled particles converges to the reward-tilted target distribution π∗(x0)∝pθ(x0)exp(λr(x0)). Independent Bernoulli deaths and stochastic rebirth form a robust proxy for exact path measure targeting, with analytical justification for variance bounds and collapse prevention (see propositions in the appendix).
Practical and Theoretical Implications
FVD establishes a new standard for inference-time reward alignment in diffusion models, marrying diversity preservation with scalable parallelism and adaptive regularization. The theoretical framework—birth-death dynamics, stochastic rebirth, and online Robbins-Monro updates—is broadly extensible to other generative modeling paradigms. FVD's strong empirical performance and efficiency underscore its potential for practical deployment in production-scale, preference-aligned generative tasks.
The approach prompts further exploration into alternative generative frameworks (e.g., flow matching, consistency models), more robust reward proxying, and multi-objective alignment scenarios.
Conclusion
FVD introduces a principled, efficient, and diversity-preserving inference-time alignment method for diffusion models. By leveraging Fleming-Viot birth-death resampling, adaptive selection control, and stochastic trajectory perturbation, FVD achieves superior reward-diversity trade-offs, outperforms strong baselines across multiple benchmarks, and enables scalable alignment without retraining. The algorithm's empirical, efficiency, and theoretical characteristics mark meaningful progress in practical reward-driven generative modeling, with numerous avenues for future research.


