- The paper introduces a novel training-free paradigm that synergizes mathematical and agentic reasoning using behavior-preserving null-space merging.
- It achieves a 7.2% improvement on SWE-Bench Verified by controlling reasoning depth while preserving the interactive agent behavior.
- The method provides fine-grained control over reasoning and action balance, ensuring enhanced stability, interpretability, and computational efficiency.
Synergizing Mathematical and Agentic Reasoning with M2A
Recent advances in LLMs have led to significant progress both in mathematical reasoning (e.g., chain-of-thought on closed-domain problems) and agentic reasoning (multi-turn, interaction-driven problem solving in open environments). However, these two forms of reasoning embody fundamentally different behavior patterns: mathematical reasoning typically involves single-turn, internal logic construction, while agentic reasoning requires intermittent alternation between internal thought and external action via multi-turn environment interaction. Empirical evidence demonstrates that naive multi-task training or model merging fails to synergize these modalities, leading to unstable and often degraded agentic behavior.
The paper "M2A: Synergizing Mathematical and Agentic Reasoning in LLMs" (2605.09879) addresses this lack of synergy. M2A introduces a training-free paradigm: it merges mathematical reasoning into agentic LLMs by aligning parameter updates in a behavior-preserving manner. The core design objective is to enhance internal reasoning while strictly maintaining the agent-specific think–act–observe interaction loop, overcoming the conflicts that afflict standard joint training or brute-force weight merging.
M2A Approach: Behavior-Preserving Model Merging
Failure Modes of Existing Approaches
Multi-task supervised fine-tuning (SFT) on a mixture of mathematical and agentic datasets superficially transfers the pattern of longer reasoning chains to agent models but fails to improve agentic task completion. In practice, it can even degrade agent performance by disrupting the agent’s interaction frequency.
Naive model merging—directly averaging or linearly combining parameter deltas from reasoning and agent models—does not respect the behavioral distinctions between the two domains. This often results in models that ‘overthink’ (i.e., generate lengthy internal reasoning without acting) or fail to interact effectively with the environment.
M2A reframes the integration challenge as a problem of preserving the agent’s behavior-critical parameter subspace. The solution comprises three main components:
- Agent-Critical Subspace Calibration: M2A identifies the directions in hidden state space that encode agentic behavior by extracting features around behavioral transition markers (e.g., special tokens for thinking, function calls, and their boundaries) from agent model activations.
- Null-Space Projection: Before merging, the parameter updates responsible for mathematical reasoning are projected to the orthogonal complement (null space) of the agent-critical subspace for each layer. This ensures that reasoning injection does not perturb the think–act–observe dynamics encoded by the agent.
- Adaptive Layer-Wise Merging: The magnitude and locus of reasoning integration are adaptively controlled. Each layer’s merge coefficient is scaled to normalise the norm mismatch between agent and reasoning parameter deltas, and only layers exhibiting sufficient update alignment (as measured by cosine similarity) are merged.
By these mechanisms, M2A injects mathematical reasoning ability while strictly prohibiting update directions that would interfere with agentic action patterns.
Empirical Results and Analysis
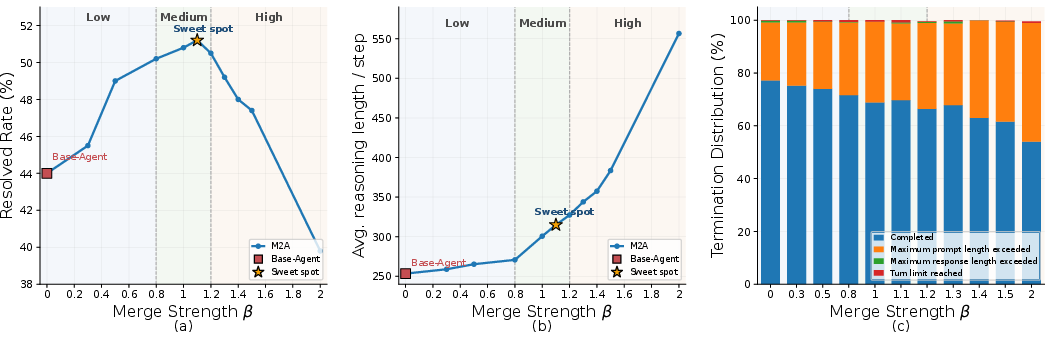
M2A is evaluated on SWE-Bench Verified, a challenging real-world coding-agent benchmark based on resolving GitHub issues. Critical observations regarding performance and behavioral traits are as follows.
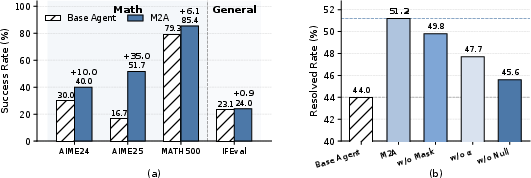
Figure 1: (a) M2A demonstrates simultaneous improvements in mathematical and agentic reasoning benchmarks; (b) Component ablation shows that null-space projection, layer normalization, and layer masking are crucial for M2A's superior agentic performance.
Theoretical and Practical Implications
M2A demonstrates that classical multi-task generalization failures in LLMs, caused by interference between behaviorally distinct domains, can be circumvented by geometric control in parameter space. By explicitly identifying and protecting behavioral subspaces specific to agentic operation, reasoning enhancements become synergistic rather than disruptive.
Behaviorally-informed merging provides several advantages:
- Train-free upskilling: M2A achieves substantial capability transfer without gradient-based adaptation, making it computationally attractive for large-scale or resource-constrained deployments.
- Behavioral stability: Unlike naïve merging, which can induce pathological activity (e.g., infinite internal monologues), M2A ensures that agents act and observe at the correct junctures, leading to higher productivity and fewer context exhaustion failures.
- Fine-grained control: Practitioners can explicitly tune reasoning depth for domain- or task-specific requirements by adjusting merge strength and layer selection.
Empirical Insights on Trajectory Shift
Qualitative analysis confirms that M2A induces a measurable shift from trial-and-error editing toward evidence-grounded action. Agents using the merged model gather more evidence, commit fewer but more targeted edits, and maintain robust performance in the presence of longer reasoning traces. Critically, these advances do not degrade general instruction-following ability, maintaining versatility beyond the agentic context.
Future Directions
This paradigm opens avenues for further exploration:
- Extending behavior-critical subspace calibration to more diverse agentic behaviors and multimodal domains
- Automated discovery of optimal merge strength and protected subspaces for arbitrary task pairs
- Exploiting behaviorally-preserving merging for continual, life-long agent training without catastrophic forgetting.
The fine-grained behavioral control and stability conferred by M2A could lead to more interpretable, reliable, and customizable LLM agents—both in software engineering and broader autonomous interaction scenarios.
Conclusion
M2A offers a principled, training-free method to synergize mathematical and agentic reasoning in LLMs by behavior-preserving null-space model merging. The result is a substantial and controllable performance increase in agentic tasks, without sacrificing stability or generality. This work establishes a technical foundation for future LLM systems that integrate heterogeneous reasoning modalities without behavior interference.