- The paper introduces an RL-based method that reframes unmasking in diffusion language models as a sequential decision process.
- It demonstrates that, compared to heuristic-driven approaches, the RL policy achieves superior trade-offs between generation accuracy and computational efficiency.
- The proposed policy is scalable and transferable across models, paving the way for automated and adaptive sampling in generative tasks.
Reinforcement Learning of Unmasking Strategies for Diffusion LLMs
Introduction and Motivation
This work addresses the challenge of unmasking policy design for masked discrete diffusion LLMs (dLLMs). dLLMs reverse a noising process and iteratively generate text by unmasking subsets of tokens, as opposed to the traditional autoregressive (AR) paradigm. A central advantage of this family is potential inference acceleration via parallel token generation. However, determining which tokens to unmask at each step is nontrivial—naive heuristics can harm generation accuracy, especially as the degree of parallelism increases.
Existing heuristic-driven scheduling, such as confidence-thresholded unmasking (e.g., Fast-dLLM), achieves high throughput in semi-autoregressive (semi-AR) regimes but has notable drawbacks: requirements for manual hyperparameter tuning, sharp performance degradation for large block sizes, and limited adaptability to new domains or model architectures. This paper reframes unmasking as a sequential decision process and proposes an RL-based approach that learns adaptive policies, thereby automating and potentially improving the sampling mechanism.
Masked Diffusion and the Unmasking Problem
Masked diffusion models (MDMs) extend BERT-style denoising to a generative setting: the forward process stochastically applies a masking operator across the sequence, and the model is trained to reconstruct the original sequence from any such corruption. Text generation proceeds by iterative unmasking. At each timestep, positions to unmask must be selected—either greedily, randomly, or through a more structured strategy based on model confidence estimates.
Heuristic-based methods (notably high-confidence or threshold-based unmasking) make use of tokenwise predictive distributions, but have well-documented limitations. Notably, they are sensitive to operational parameters such as the confidence threshold or the number of tokens unmasked in parallel, and their effectiveness deteriorates when moving to block sizes outside the semi-AR regime, as empirically demonstrated in the paper.
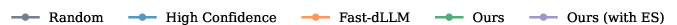
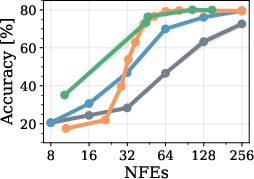
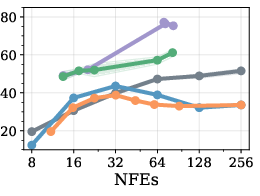
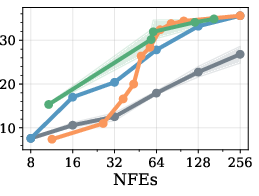
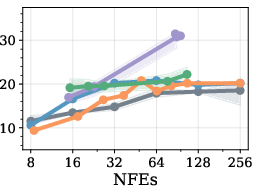
Figure 1: GSM8k dataset accuracy and sampling efficiency for different unmasking policies and block lengths on LLaDA. Heuristic-based methods perform well in the semi-AR regime (BL=32), but degrade substantially in the fully parallel case (BL=256).
RL-Based Unmasking Policies
The central contribution is a formalization of dLLM sampling as an MDP, where:
- States are given by the prompt and the current (partially masked) sequence.
- Actions are binary vectors indicating which positions to unmask at the current timestep.
- Transitions correspond to the (stochastic) unmasking and replacement of mask tokens with samples from the model's predictive distributions.
- Rewards encode both accuracy (via task-specific correctness) and efficiency (penalizing the number of function evaluations).
The unmasking policy is parametrized by a shallow, lightweight transformer (sub-0.01% the size of the underlying generator), taking as input the vector of token confidences, a mask indicator, and the current timestep. Policy outputs are per-position Bernoulli logits, with at least one position forced to be unmasked in every step to avoid degenerate solutions. Training is performed using Group Relative Policy Optimization (GRPO), an efficient and scalable policy gradient method for handling group-wise rollouts in RL.
The policy is incentivized by a multiplicative reward structure that nullifies the reward for incorrect generations and discounts by compute cost otherwise. This is shown to avoid reward hacking issues that are prevalent with additive reward structures.
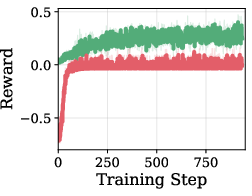
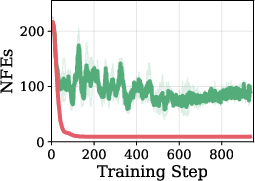
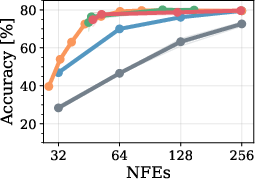
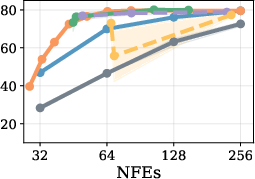
Figure 2: Effect of reward structure on training; multiplicative reward yields stable training and avoids reward hacking, whereas additive reward results in suboptimal degenerate policies.
Empirical Analysis
Semi-Autoregressive Generation
RL-trained unmasking policies match the best heuristic methods (notably Fast-dLLM) under semi-AR settings—where block length is modest and temporal correlation in generation is strong. The RL approach outperforms both random and high-confidence unmasking strategies, and in extreme low-compute regimes (maximal parallelism) even surpasses fixed heuristics in Pareto trade-off between accuracy and sample efficiency.
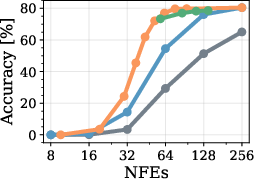
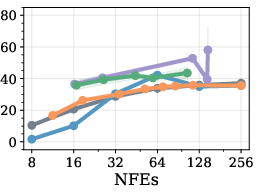
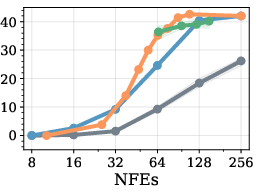
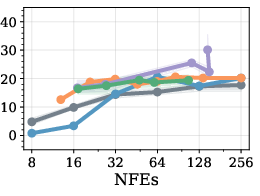
Figure 3: Pareto comparison on GSM8k (LLaDA, BL=32); RL policies trace the Fast-dLLM frontier and show improvements in the high-efficiency regime.
Full-Parallel (Non-Semi-AR) Generation
Performance of heuristic-driven sampling deteriorates markedly for large block sizes, while RL-trained policies maintain superior accuracy for a given number of function evaluations. Furthermore, by augmenting training with "expert steering" (mixtures of RL exploration and imitation of strong heuristics), policies cover the high-accuracy region of the Pareto front, which heuristics alone cannot reliably reach outside their favored settings.

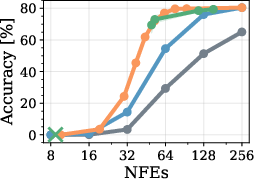
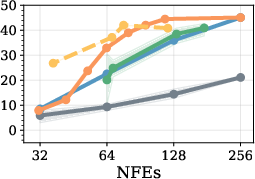
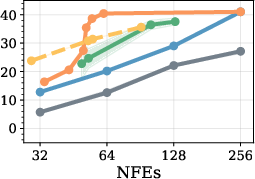
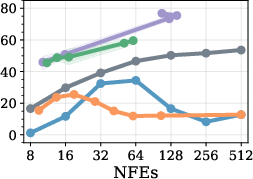
Figure 4: Model transfer results; RL policies trained on LLaDA perform robustly when evaluated on Dream, showing potential for cross-model generalization.
Transferability
RL policies exploiting token confidences transfer readily across architectures (e.g., from LLaDA to Dream), provided distributions of confidences are similar. Domain transfer (e.g., math to code generation) is less robust; policies underperform confidence-thresholding heuristics unless the training set covers the evaluation domain. Similarly, policies trained for one sequence length generalize well to longer sequences due to flexible policy parameterization using position encodings.

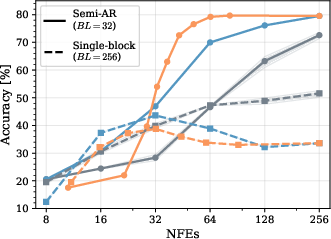
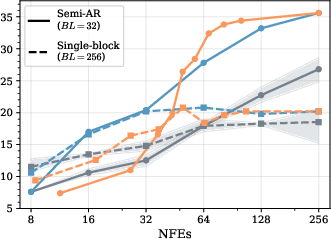
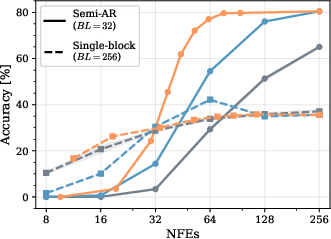
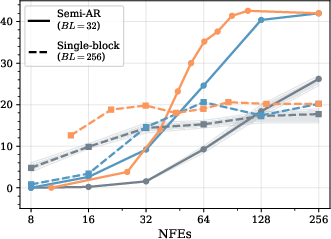
Figure 5: Transferability across models (LLaDA-trained policy evaluated on Dream; consistent performance to Fast-dLLM heuristic).
Policy Design Ablations
Detailed ablation studies reveal several core findings:
- Multiplicative reward functions are superior for stability and avoiding trivial solutions.
- Parameterizing the policy with token confidences is both effective and efficient; leveraging higher-order predictive moments (e.g., top-50 confidences or full hidden states) does not yield improvement in downstream accuracy.
- Dynamic Plackett-Luce sampling (instead of per-token Bernoulli) offers very similar empirical behavior, suggesting policy capacity is not the rate-limiting factor in the semi-AR regime.
Practical and Theoretical Implications
The proposed RL-based unmasking mechanism demonstrates that efficient and accurate sampling policies for dLLMs can be learned autonomously, obviating manual hyperparameter tuning and exposing the possibility of domain- or architecture-agnostic sample scheduling. Such approaches smooth the performance–efficiency Pareto curve, especially outside the regime where current heuristic methods degrade.
Theoretically, the framing of unmasking as an MDP introduces new perspectives for discrete diffusion model research, creates opportunity for further exploration of adaptive computation, and for parallel advances in policies that incorporate richer observation (e.g., joint unmask/remask, multimodal signals).
Conclusion
The RL-trained unmasking policy introduced in this work matches and often exceeds heuristic-based sampling for dLLMs, with strong results for both semi-AR and fully parallel regimes. The design is scalable, easily transferable within model families, and provides a first step toward fully automated adaptive sample scheduling for diffusion-based generative modeling. Nonetheless, further work is required to enhance fine-grained controllability of the accuracy-efficiency trade-off and to extend domain generalization.
Future Directions
Open questions include:
- Joint learning of accuracy–efficiency trade-off as a continuous policy parameter.
- Domain-general, mixture-trained policies for robust cross-task applicability.
- Incorporation of semantic or structural information while maintaining computational frugality.
- Extension to remasking and other non-unmask-only paradigms, and to multimodal generation.
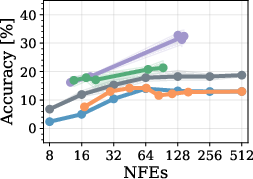
Figure 6: Policy robustness across varying α (compute penalty) values shows that high-penalty policies diverge, while moderate penalties yield stable and effective Pareto frontiers.

