- The paper introduces a principled framework for prompt reweighting via functional derivatives to control the distribution of prompts.
- It employs a quantile-based reweighting strategy that adaptively emphasizes challenging yet learnable prompts, leading to improved pass@k metrics.
- Empirical results demonstrate that CurveRL outperforms baseline methods and maintains stable training by mitigating weight collapse.
Principled Distribution-Aware Context Reweighting in RLVR: An Analysis of CurveRL
Introduction
The optimization of LLMs for complex reasoning tasks via Reinforcement Learning with Verified Rewards (RLVR) has recently been dominated by groupwise context or prompt-level reweighting techniques. Despite empirical advances, the theoretical optimality of such context reweighting—crucial in RLVR's contextual bandit setting—remains unclear. The work "CurveRL: Principled Distribution-Aware Context Reweighting for LLM Reasoning" (2605.24331) addresses this gap, presenting a rigorous functional-analytic framework for context reweighting and introducing CurveRL, a distribution-aware, rank- and density-sensitive reweighting strategy.
Theoretical Framework: Prompt Reweighting as Distribution Control
RLVR differs fundamentally from standard RL in that the prompt distribution is endogenously controllable during training, creating a new axis—context distribution control—distinct from action-level exploration. CurveRL formalizes prompt reweighting by expressing the policy update as:
∇θJ(θ)=Ex∼d0[wθ(x)∇θpθ(x)]
where wθ(x) is the prompt weight, pθ(x) is the pass rate, and d0 is the base prompt distribution. The main insight is that wθ(x) should be chosen not heuristically, but as the functional derivative of a specified utility functional over the pass-rate function space, capturing both local and global sensitivity.
Standard approaches (e.g., REINFORCE, GRPO, MaxRL) correspond to specific pointwise utility functionals, but these degenerate for prompts with similar pass rates—a phenomenon termed weight collapse. The authors show that optimal weighting must be considered in the space of functionals over pθ(⋅), which inherently enables distribution-aware, cross-prompt coupling.
CurveRL: Distribution-Aware Reweighting in Quantile Space
CurveRL introduces a utility functional defined not in terms of individual pass rates, but in terms of the quantile (i.e., CDF ranking) of the pass rate under an evolving reference distribution Fref. The resulting prompt weighting,
wθ(x)=Fref(pθ(x))fref(pθ(x))
combines both the local density and the rank of the prompt with respect to the entire prompt population, introducing adaptivity and mitigating weight collapse seen in pointwise schemes. Tasks that lie near the "learning frontier"—prompts neither trivial nor hopelessly hard—are emphatically sampled during optimization, deferring to the current distributional state of the model’s competence.
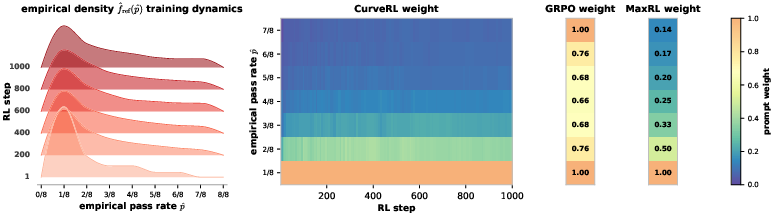
Figure 1: Distribution-aware and data-driven weighting of CurveRL on Qwen3-4B-Base; weights dynamically emphasize difficult, but learnable, prompts as pass-rate distributions evolve.
The CurveRL policy gradient update relies on sliding-window estimators of Fref and fref, ensuring stability and adaptivity. This design is robust under monotonic calibration transformations, conferring invariance to miscalibrations in the raw pass-rate scale.
CurveRL's empirical evaluation employs Qwen3-1.7B-Base and Qwen3-4B-Base on the POLARIS-53K corpus, targeting complex math-reasoning benchmarks. The comparisons span GRPO, MaxRL, and the non-reweighted baseline, using both single-shot (pass@1) and multi-sample (pass@wθ(x)1) metrics.
CurveRL consistently yields superior pass@wθ(x)2 curves across multiple model sizes and benchmarks, maintaining or improving both pass@1 and pass@wθ(x)3 simultaneously—contravening prior findings where improvements in pass@wθ(x)4 would degrade pass@1 due to prompt interference effects.
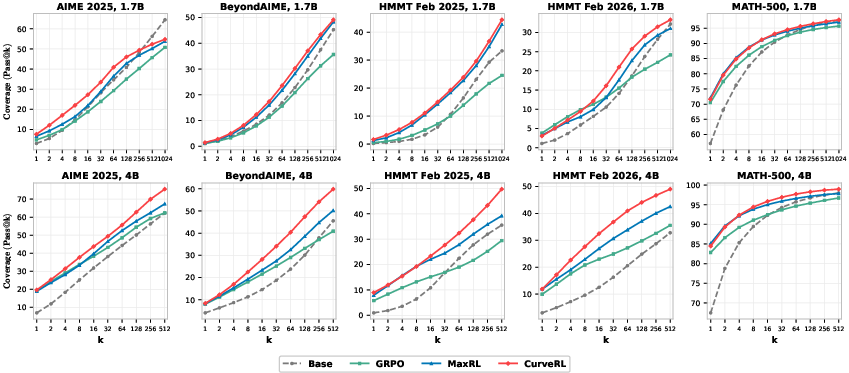
Figure 2: Pass@wθ(x)5 scaling on five representative benchmarks. CurveRL achieves dominant pass@wθ(x)6 curves compared to GRPO, MaxRL, and the base model, for a wide range of wθ(x)7 and two model scales.
Moreover, post-training difficulty spectrum analysis shows that CurveRL reduces the unsolvable prompt fraction and expands the proportion of prompts in the hard and medium regions—those amenable to test-time scaling via repeated sampling.
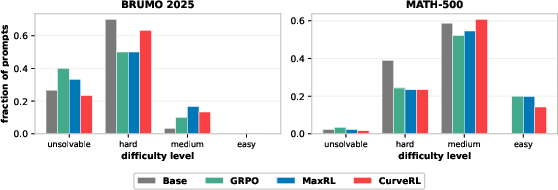
Figure 3: Prompt Distribution across Difficulty in Qwen3-1.7B-Base. CurveRL reduces unsolvable prompts and enlarges the hard/medium mass relative to baselines.
Additional ablations indicate CurveRL’s weighting adapts throughout training, diverging from the static allocations of GRPO/MaxRL and maintaining a richer pool of prompts contributing non-trivial gradients.
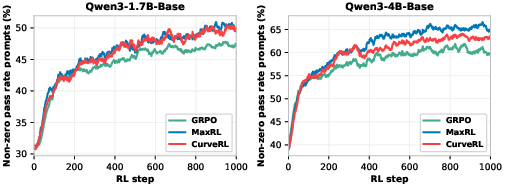
Figure 4: Fraction of prompts where the model generates at least one correct rollout out of 8 samples—CurveRL sustains a higher fraction of learnable prompts as training progresses.
Theoretical and Practical Implications
The theoretical schema advanced by CurveRL—optimality via functional derivatives over distribution-valued pass-rate functions—establishes an extensible blueprint for principled RLVR algorithm design. It links optimal prompt weighting to utility theory and risk-sensitive control, encoding risk-preference directly in the functional.
Practically, CurveRL’s explicit distribution-awareness decouples optimization from assumptions of pass-rate calibration, allowing stable training even in non-stationary or misaligned difficulty landscapes. The method's performance in expanding the effective boundary of solvable prompts positions it as a candidate for systems where scalable test-time sampling or robust generalization is imperative.
Future Directions
The study suggests fruitful avenues for combining pointwise and distribution-aware utilities, for instance via joint parametrizations capturing both local sensitivity and global spectrum structure, though naïve combinations may induce conflicting geometric effects. Additionally, extending the definition of utility and functional derivatives directly to the (often high-dimensional) prompt space may unlock new classes of curriculum and sample selection strategies untethered from pass-rate projections.
Conclusion
CurveRL introduces a principled, distribution-aware method for prompt reweighting in RLVR, defined as the functional derivative of a utility functional over the space of pass-rate functions. Empirical and theoretical studies demonstrate its efficacy in mitigating weight collapse and expanding model capability, improving both pass@1 and pass@wθ(x)8 metrics. The results reframe context distribution control in RLVR as a core design dimension, providing new tools for reasoning model post-training and suggesting further research in distributional and functional-optimality-driven RL algorithms.
Reference:
"CurveRL: Principled Distribution-Aware Context Reweighting for LLM Reasoning" (2605.24331)