- The paper introduces PerMix-RLVR to mitigate the trade-off between persona robustness and expressivity by integrating diverse persona prompts into RLVR training.
- It employs a latent style model and KL-regularized RL objective to filter non-competent persona-induced behaviors, improving stability and accuracy in benchmarks.
- Empirical results demonstrate up to +21.2% improvement in Persona Stability Score and enhanced role fidelity, benefiting tasks like math reasoning and role-playing.
PerMix-RLVR: Mitigating the Trade-off Between Persona Robustness and Expressivity with Verifiable-Reward Alignment
Motivation and Problem Setting
Persona prompting, wherein the system prompt assigns a particular role or identity (e.g., "You are a mathematical expert"), is a pervasive strategy for influencing LLM behavior. However, empirical evidence demonstrates that optimal persona selection is both labor-intensive and unreliable: persona-induced performance varies substantially, and even closely related prompts can drive significant task accuracy variance (Figure 1).
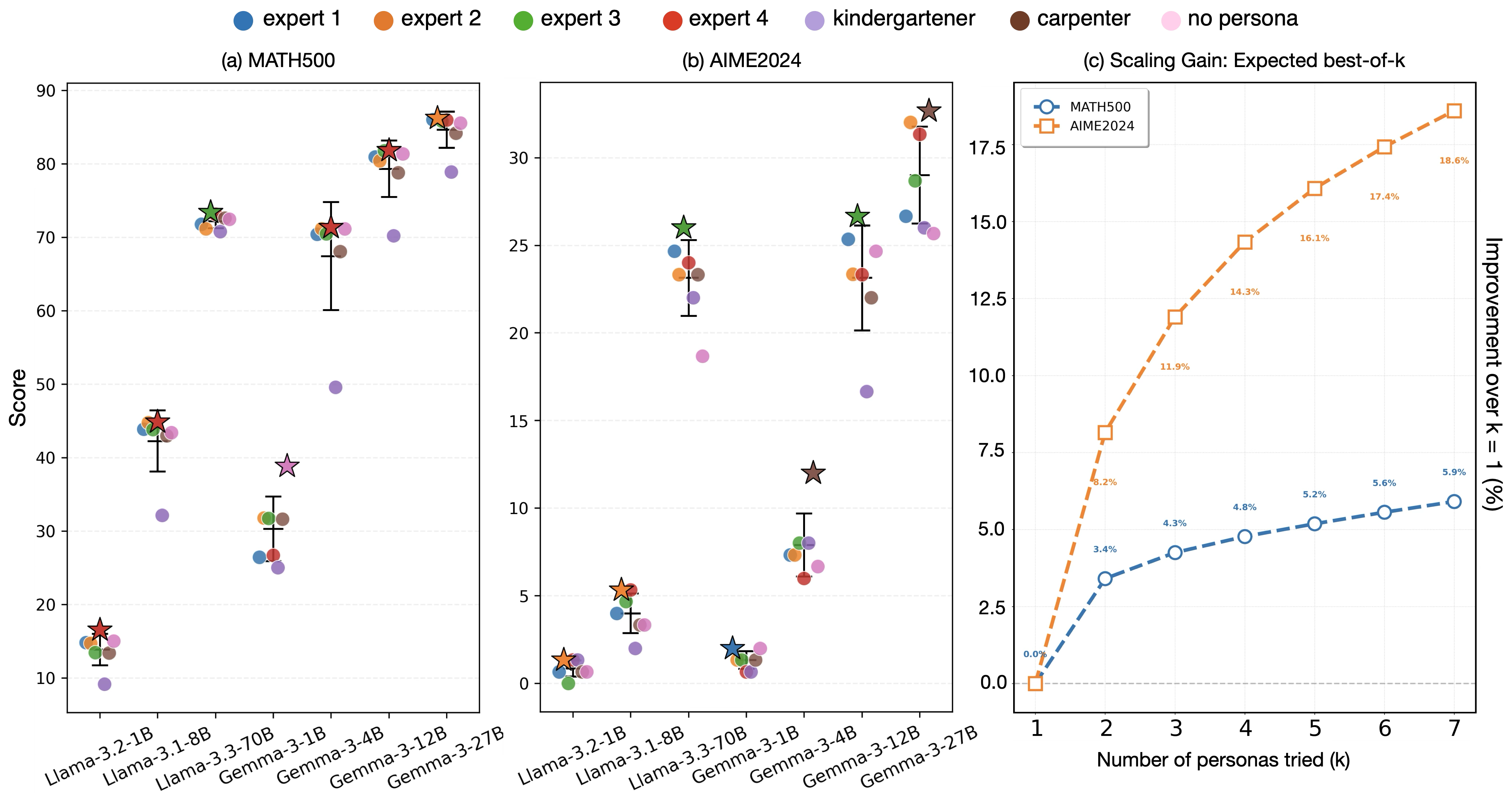
Figure 1: The "persona lottery" – Llama3 and Gemma3 display wide accuracy variance across seven sample personas, and the expected maximum performance increases sublinearly with additional prompt exploration.
Previous efforts have largely focused on inference-time prompt engineering, meta-prompting, or ensemble strategies to mitigate this instability. Yet, these approaches impose additional computational cost and fail to guarantee robust generalization. The central contribution of this work is to address persona sensitivity as a property of the model itself, operationalized by the interaction of post-training objectives with the persona prompt. The key question is reframed: is it possible to train intrinsic persona-robust models without sacrificing role-playing fidelity when required?
RLVR Alignment: Empirical and Theoretical Analysis
A systematic study across base and post-trained models (Llama3, Gemma3, Qwen3 families) reveals a strong connection between the post-training alignment recipe and the persona robustness of LLMs. Models trained with reinforcement learning from verifiable rewards (RLVR)—objective-based RL on tasks where outputs can be automatically checked for correctness (e.g., math or code)—consistently demonstrate high persona robustness. In contrast, models relying on SFT or knowledge distillation exhibit pronounced persona-induced sensitivity.
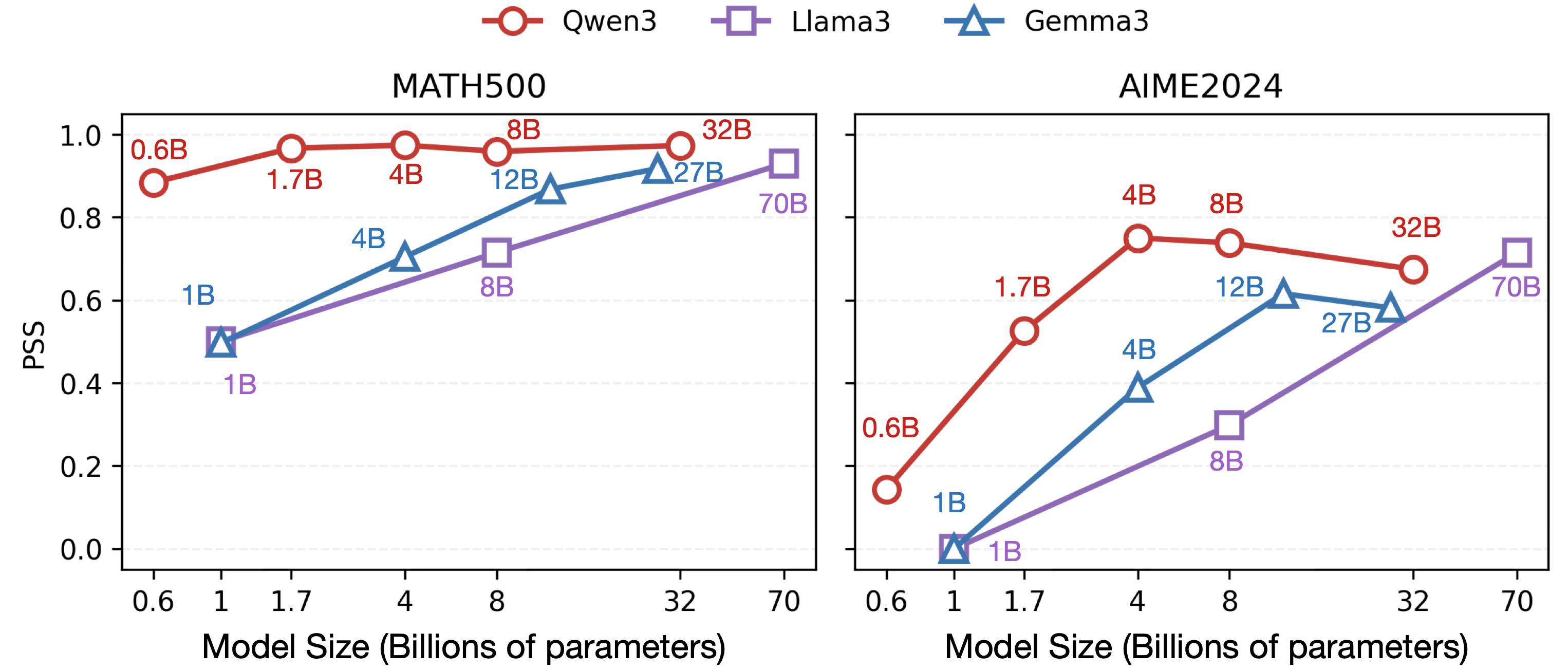
Figure 2: RLVR-aligned model families consistently exhibit elevated Persona Stability Scores (PSS), indicating stable accuracy across prompt persona variation.
This effect is formalized using a latent style model: RLVR is shown to act as a probabilistic filter, upweighting those response styles (including persona-induced) that increase correctness under the reference policy, and largely suppressing persona-induced modes that do not. Theoretically, the KL-regularized RLVR objective maximizes expected verifier reward while penalizing KL divergence from a reference (Appendix, Proposition 1):
- Accuracy and robustness improve as the RLVR temperature drops.
- Thus, RLVR compresses the performance gap between best and worst personas, yielding higher PSS.
However, this outcome-driven filtering mechanism exposes a critical limitation: by suppressing low-competence persona-induced styles, RLVR may also attenuate persona-fidelity, i.e., the model’s ability to authentically role-play or adhere to persona cues when they are required for the task (as validated by pairwise LLM-judge assessments).
The PerMix-RLVR Algorithm
To reconcile this trade-off, the paper introduces PerMix-RLVR, a persona-mixed RLVR strategy. PerMix-RLVR extends standard RLVR by sampling and conditioning on a broad pool of persona prompts throughout training, creating persona-mixed input distributions. The RLVR update is thus performed under diverse persona-conditioned style priors rather than the default neutral style prior.
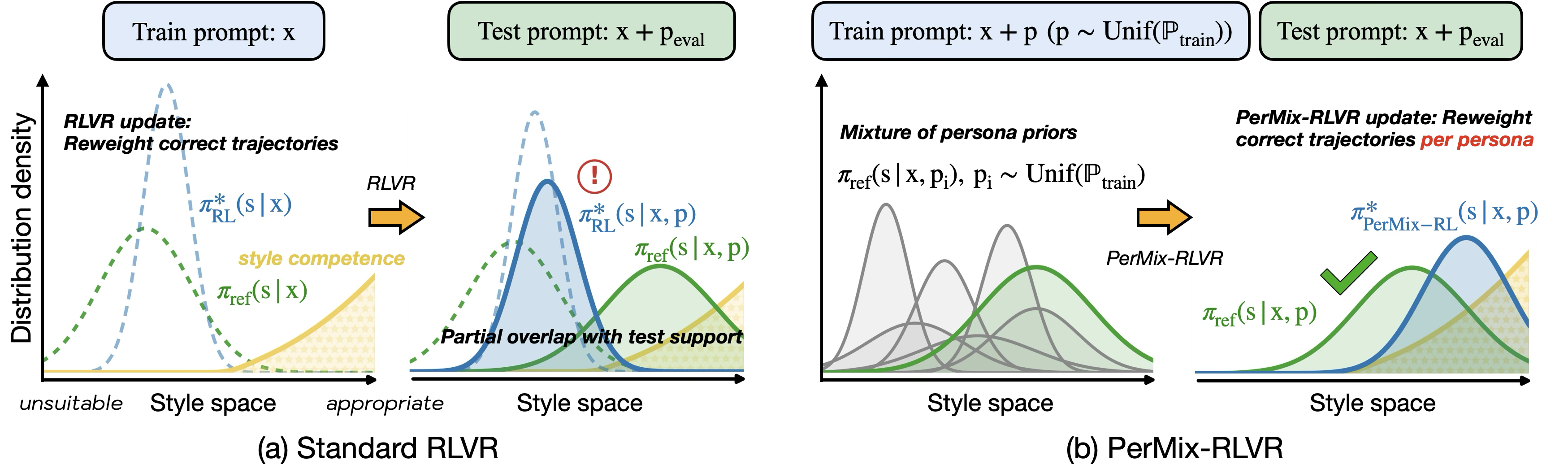
Figure 3: Standard RLVR acts as a filter over the reference style prior, which can fail for previously unseen persona shifts. PerMix-RLVR explicitly aligns the model under a mixture of persona priors, improving both test-time robustness and fidelity.
Empirically, PerMix-RLVR demonstrates strong improvements in both persona-robust accuracy and persona expressivity/fidelity versus standard RLVR and all SFT/KD baselines:
- On MATH500 (math reasoning): PerMix-RLVR increases the Persona Stability Score by +21.2% over RLVR.
- On PersonaGym (role-playing): Persona-fidelity is enhanced by +11.4% over RLVR.
Theoretical analysis confirms that persona-mixed RLVR aligns the optimal style filter under a union of persona priors, providing coverage and calibration even for previously unseen persona shifts at inference time.
Experimental Results
Comprehensive experiments span in-distribution (GSM8K), out-of-distribution (MATH500, LiveCodeBench), and role-playing (PersonaGym) benchmarks, measuring:
- Worst, mean, best persona-conditioned Pass@1 accuracy
- PSS (persona stability)
- PersonaGym persona consistency score (fidelity)
Key findings include:
- RLVR greatly outperforms SFT or sequence-level KD in robustness, but can reduce persona expressivity.
- Explicit persona mixing during RLVR training (PerMix-RLVR) further boosts worst-case performance, yielding the highest PSS in nearly all settings.
- PerMix-RLVR closes the expressivity gap and attains stronger persona-role alignment versus RLVR.
- In cross-domain generalization to code, PerMix-RLVR consistently improves worst-case accuracy and PSS, outperforming teacher-based KD except on the most extreme benchmarks where all methods collapse.
Practical and Theoretical Implications
These results have direct implications for the design of controllable, robust LLM deployments:
- RLVR can be leveraged as a post-training technique to reduce user burden in crafting optimal persona prompts for reasoning tasks with verifiable objectives.
- However, this approach is insufficient in domains where persona expressivity, creativity, or strict role-adherence is required.
- Persona-mixing at training time (PerMix-RLVR) enables LLMs to retain high accuracy and robustness while also allowing for controllable persona adoption without an explosion in inference-time computational cost.
- For tasks and applications requiring both accuracy and persona-adherence (e.g., instructional agents, chatbots with strong identity requirements), persona-mixing RLVR or its extensions should be preferred to SFT or standard RLVR.
Theoretically, this paradigm connects with multi-objective RL formulations, Bayesian robust optimization over conditional priors, and paves the way toward more sophisticated reward conditioning schemes (e.g., hybrid verifiable + persona-consistency rewards).
Conclusion
PerMix-RLVR advances the state-of-the-art in persona-conditioned post-training by operationalizing the insight that persona robustness and expressivity are dynamically traded off as a function of the reward alignment protocol. Explicit persona-mixing at RLVR training time delivers the most balanced results on all considered axes—task accuracy, persona robustness, and role fidelity. This framework suggests new avenues for scalable, robust, and controllably expressive LLMs, motivating future algorithmic extensions incorporating reinforcement learning from persona-consistency rewards or modular objectives for blended control.