Not Every Rubric Teaches Equally: Policy-Aware Rubric Rewards for RLVR
Abstract: Reinforcement learning with verifiable rewards has made post-training highly effective when correctness can be checked automatically. However, many important model behaviors require satisfying several qualitative criteria at once. Rubric-based rewards address this setting by grading prompt-specific criteria and aggregating them into a scalar reward. Yet standard static aggregations conflate a criterion's human-assigned importance with its current usefulness as an optimization signal. We show that this assumption breaks down in rubric RL: many important criteria are already saturated or currently unreachable, while criteria that distinguish rollouts are not necessarily those with the largest human weights. We introduce POW3R, a policy-aware rubric reward framework that preserves human weights and category balance as the rubric objective while adapting criterion-level reward weights during training. POW3R uses rollout-level contrast to emphasize criteria that currently separate the policy's outputs, making the GRPO reward more informative without changing the underlying evaluation target. Across three base policies on two datasets spanning multimodal and text-only settings, POW3R wins $24$ of $30$ base-policy/metric comparisons, improving both mean rubric reward and strict completion (the fraction of prompts whose response satisfies every required rubric criterion) over vanilla GRPO with rubric rewards, and reaches the same plateau in $2.5$--$4\times$ fewer training steps. Rubric rewards should therefore distinguish what should matter in the final answer from what can teach the current policy.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at how to better “teach” AI models using rubrics—the same kind of checklists teachers use to grade homework. The authors show that when training a model with a rubric, not every rubric item is equally helpful at every moment. They introduce a method called POW3R that notices which rubric items are currently useful for learning and gently shifts training focus toward those, while still respecting what humans say is important overall.
The big idea in simple terms
Imagine you’re practicing essays with a grading checklist: facts, structure, grammar, following instructions, and style. If you already nail grammar every time, spending all your study time on grammar won’t help you improve. On the other hand, if you always mess up structure, drilling only structure might be too hard at first. You learn fastest by focusing on the parts where your performance varies—where you sometimes get it right and sometimes not—because that’s where you can pick up clear lessons.
This paper brings that idea to AI training with rubrics.
What questions the paper asks
The authors focus on three easy-to-understand questions:
- Do standard rubric scores treat “what matters in the final answer” the same as “what helps the model learn right now”?
- Are many rubric items either already always passed or always failed (so they don’t teach the model anything at the moment)?
- Can we reweight rubric items during training—without changing the overall grading goal—so the model learns faster and better?
How they did it (in everyday language)
Here’s the training setup, step by step:
- Group comparisons instead of a single score: For each question (or image–question pair), the model generates several different answers. An AI grader checks each answer against a rubric with multiple items (like accuracy, completeness, following instructions, etc.). The training then compares those answers within the group: if one answer scores higher than the others, the model learns to prefer that style. If all answers tie, there’s no lesson to learn from that group.
- The problem with static weights: Normally, you add up rubric items using fixed human-chosen weights (for example, “accuracy is worth 5 points, style is worth 2”). But fixed weights assume that the most important items are also the most helpful for learning right now. The authors found that’s often false—many “important” items are already always passed (saturated) or always failed (dead), so they don’t help the model improve at that time.
- The POW3R idea: Keep the rubric and human weights the same overall, but adjust where the training effort goes inside each category based on “contrast”—how much model answers currently differ on each item.
- If all answers pass an item or all fail it, turn that item down a bit (it isn’t teaching anything today).
- If answers are mixed on an item (some pass, some fail), turn it up (it’s a good teaching opportunity).
- Keep each category’s total importance and the human weight priorities intact, so the final grading target doesn’t change—only the training emphasis does.
- Gentle, stable adjustments: POW3R computes a “contrast score” for each item from how the group of answers performed, blends it with the default weight, clips it to avoid big swings, and smooths it over time. Think of it as turning the volume knob slightly up on what’s currently informative and slightly down on what isn’t.
What they tested on
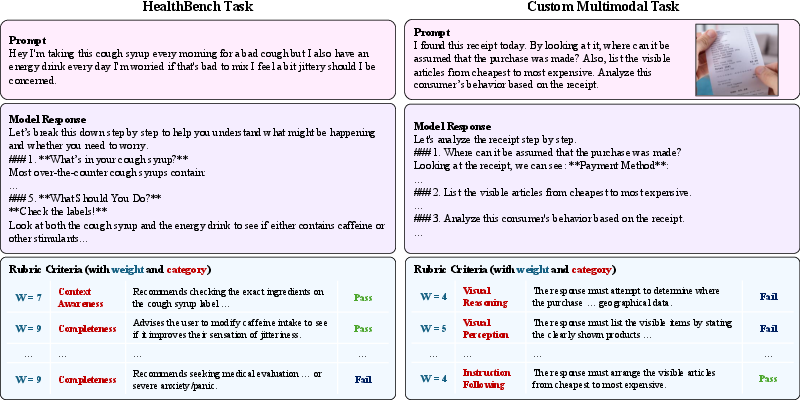
- A multimodal dataset (images + text) with six rubric categories: visual perception, visual reasoning, content completeness, instruction following, truthfulness, and style.
- A text-only medical advice dataset (HealthBench) with expert-written, weighted criteria.
In both cases, the AI grader rated each rubric item for each answer, and the training compared multiple answers per question.
Main findings (why this works)
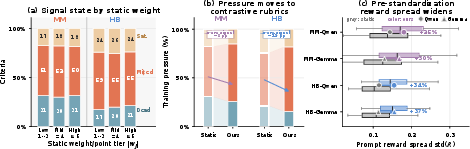
- Many rubric items don’t teach at first: About half of all items were not helpful for learning right away—17–26% were “saturated” (everyone passes) and 20–33% were “dead” (no one passes). The human-chosen importance of an item didn’t predict whether it was currently useful for training.
- POW3R makes training signals clearer: By shifting weight away from dead/saturated items and toward items with mixed results, POW3R spread out the answer scores more. That means more groups had a clear “winner,” which gives the model a stronger learning signal.
- Better results, faster:
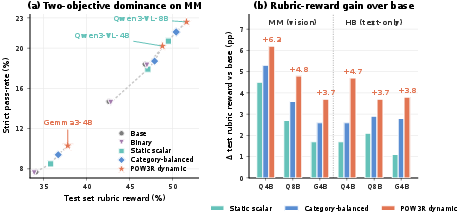
- POW3R beat standard methods in 24 out of 30 comparisons across different models and both datasets.
- It improved both average rubric score and “strict completion” (the share of answers that satisfy every required rubric item).
- It reached the same quality level in 2.5–4× fewer training steps.
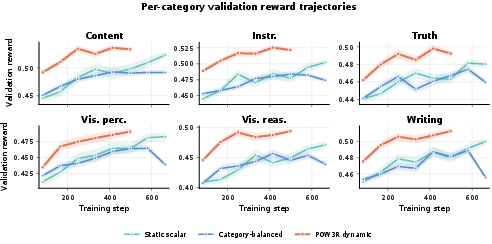
- Broad, not narrow, gains: Improvements showed up across categories like visual perception, reasoning, instruction following, content, and truthfulness. Areas that were already easy (like style, often) changed less—because there wasn’t much room to learn there.
- No obvious overfitting: On several external vision–language tests the performance stayed steady or improved slightly, suggesting POW3R didn’t just “game” the rubric.
Why this matters
- Smarter practice, same goals: POW3R keeps the original rubric and human priorities as the end goal. It just teaches smarter by focusing on items that can actually move the needle for the current model.
- Better use of data and compute: Because the model learns from clearer differences within answer groups, it improves faster and reaches higher quality with the same training recipe.
- A general idea: The lesson isn’t only about rubrics. Any time you have multiple goals, it can help to separate “what’s important in the final result” from “what helps the model learn right now,” and adjust training focus accordingly.
Limitations and future directions
- Depends on AI graders: If the grader makes systematic mistakes, the training focus can be misdirected. Stronger, more consistent graders would help.
- Limited public rubrics: There aren’t many large, public datasets with detailed, weighted rubrics across different domains. Testing this more widely—like for code, scientific writing, or multiple languages—would be valuable.
- Next steps: Try stronger graders, longer training, and rubrics that adapt and grow with the model over time.
Takeaway in one sentence
Not every rubric item teaches equally at every moment—POW3R trains models to aim for the same human-defined goals while learning faster by paying more attention to the rubric items that actually distinguish good and not-so-good answers right now.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper. These items focus on what is missing, uncertain, or unexplored, and are framed to guide follow-up research.
- Judge reliability and bias propagation:
- How do verdict biases, temperature settings, and prompt templates of the LLM judges quantitatively affect POW3R’s factor estimation and downstream policy updates?
- Can integrating judge uncertainty (e.g., via calibration, inter-rater disagreement, or confidence scores) mitigate over-emphasis of noisy criteria that appear “contrastive” due to judge error?
- Sensitivity to hyperparameters and design choices:
- How sensitive are outcomes to λ (blend), βema (EMA), ε (smoothing), clipping bounds [], minimum-valid-verdict thresholds, and the definition of contrastiveness (e.g., sqrt-variance vs. other dispersion measures)?
- What is the optimal update cadence for (per step, per epoch, per prompt batch), and does stale factor information degrade performance?
- Group size and sampling effects:
- How do different GRPO group sizes G, sampling temperatures, and decoding strategies impact the stability and utility of contrastiveness estimates and the overall gains from POW3R?
- Robustness to noisy or adversarial criteria:
- Does POW3R inadvertently upweight spurious or adversarially exploitable criteria that increase rollout variance without reflecting true quality?
- Can additional regularizers (e.g., reliability-weighted factors or noise-robust estimators) prevent variance inflation from judge noise or prompt artifacts?
- Category mass and human preference fidelity:
- POW3R enforces uniform category mass; when rubrics are intended to have non-uniform category importance, does this distort the true human preference target?
- What are the effects of learning (or preserving) explicit category-level weights, and can POW3R be extended to respect human category priorities while still being policy-aware within categories?
- Objective mismatch during training vs. evaluation:
- The method optimizes a category-balanced, policy-aware reward but evaluates with a static scalar. How does this mismatch influence generalization and does aligning training and evaluation objectives change results?
- Generalization beyond the tested domains:
- Does POW3R transfer to domains with different rubric structures (e.g., coding assistance, scientific writing/peer review, multi-lingual settings, long-form dialogue), where saturation patterns and criterion granularity differ?
- How does POW3R perform under truly open-ended or sparse-feedback tasks where criteria are scarce or loosely defined?
- Dataset coverage and external validity:
- The main multimodal dataset is in-house; to what extent do results replicate on publicly available, large-scale rubric datasets with static human weights, or on datasets authored by independent organizations?
- Longer-horizon and longer-schedule behavior:
- What happens when training runs significantly longer than ~600 GRPO steps? Do benefits persist, plateau, or reverse (e.g., via overfitting to contrastive but less important criteria)?
- How do the dynamic factors evolve across stages of learning, especially as previously contrastive criteria become saturated?
- Integration with step-wise or token-level credit assignment:
- Can per-criterion policy-aware factors be combined with step-wise/trajectory-level rewards or token-level credit assignment to localize learning to the evidence or reasoning steps relevant to a criterion?
- Extensions to graded (non-binary) criteria and partial credit:
- The paper treats criteria as binary for factor estimation. How do results change with graded rubric scores (e.g., 0–1 or multi-point scales), and which dispersion measures best capture contrastiveness for continuous outcomes?
- Theoretical analysis:
- Under what assumptions does policy-aware reweighting provably improve advantage variance, sample efficiency, or convergence properties relative to static aggregation?
- Can we bound the bias–variance trade-off introduced by using rollout-variance-driven factors under noisy judges?
- Comparisons to stronger multi-objective baselines:
- How does POW3R compare to alternative dynamic scalarization methods (e.g., uncertainty-guided weighting, hypervolume maximization, Pareto front methods, PCGrad/GradNorm variants) or learned reward aggregation models?
- Can a learned per-criterion reliability model or a small auxiliary discriminator outperform simple variance-based factors?
- Safety and domain-critical priorities:
- In safety-critical domains (e.g., clinical advice), can POW3R overweight contrastive but less critical criteria at the expense of safety constraints? What safeguards ensure high-weight safety criteria remain prioritized even when they are saturated?
- Cost, latency, and compute trade-offs:
- What is the end-to-end cost per training step given per-criterion judging, and how does the speed-up in steps-to-target translate to actual wall-clock and dollar savings?
- Can active judging (e.g., selective criterion evaluation or early stopping of judge calls) preserve gains with fewer judge queries?
- Continual and online adaptation:
- How stable are policy-aware factors across distribution shifts (new tasks, updated judges, domain drift), and can POW3R be adapted to continual learning without oscillations or catastrophic forgetting?
- Prompt- and global-level coupling:
- The method computes factors per prompt. Would sharing information across prompts (e.g., per-criterion global reliability priors) improve factor stability, especially for rare criteria?
- Handling dead/saturated regimes:
- When most criteria in a prompt are dead or saturated, POW3R reverts to α≈1 and still yields no gradient. Can adaptive rubric augmentation, curriculum design, or difficulty calibration revive learning in such cases?
- Interaction with GRPO standardization:
- Since advantage collapses when within-group std(R)=0, could alternative standardization or per-criterion advantage broadcasting further mitigate tied-group collapse beyond reweighting?
- Reproducibility under proprietary judges:
- Results depend on GPT-5.4-nano/mini prompts and settings. How reproducible are gains with open-source judges, different judge architectures, or under judge drift over time?
- External benchmark impacts:
- Although external VLM scores are maintained or slightly improved, why are gains modest on some benchmarks? Are there benchmarks where rubric-driven gains harm other abilities (e.g., tool use, spatial reasoning, OCR-heavy tasks)?
- Ethical and fairness considerations:
- Do policy-aware weights inadvertently amplify biases present in rubrics or judges (e.g., stylistic preferences, cultural assumptions)? What auditing protocols detect and mitigate such shifts?
- Release and community validation:
- Will the in-house multimodal dataset, rubrics, and judging prompts be released for independent replication? If not, can surrogates or standardized suites be proposed to benchmark policy-aware aggregation methods?
Practical Applications
Immediate Applications
The following applications can be deployed using current tooling (GRPO/RLVR pipelines, rubric-based LLM judges) with modest engineering effort.
- Policy-aware reward aggregation in existing RLHF/RLAIF/RLVR stacks
- What: Replace static weighted-sum rubric rewards with POW3R’s policy-aware, category-normalized aggregation to emphasize currently contrastive criteria while preserving human-assigned weights and category mass.
- Where it fits: As a drop-in reward module in GRPO training loops (e.g., for multimodal and text-only assistants).
- Sectors: Software platforms building assistants; healthcare (clinical QA, patient education), education (tutors), enterprise productivity (writing/coding assistants), customer support, finance (compliance drafting), legal (policy-compliant drafting).
- Tools/products/workflows:
- “POW3R Reward Aggregator” SDK/plugin for RL frameworks (e.g., DAPO, TRL-like stacks).
- Training-time switch to compute per-criterion pass-rate/variance, apply bounded reweighting, and renormalize by category.
- CI job to validate reward spread and reduce std(R)=0 groups.
- Assumptions/dependencies: Access to criterion-level LLM judge outputs; GRPO-style group sampling (G≥8–16 recommended); reliable rubric categories and integer weights; judge cost budget.
- Rubric-pressure diagnostics for training and evaluation audits
- What: Use the paper’s diagnostic to track “dead/saturated/mixed” criteria, per-category pressure allocation, and prompt-level reward spread to identify where the reward gives zero advantage signal.
- Sectors: ML Ops, safety/QA teams; regulated domains (healthcare, finance, public-sector AI procurement).
- Tools/products/workflows:
- “RubricScope” dashboard that plots pass rates, criterion variance, and within-category pressure shares over time.
- Alerts when many prompts hit std(R)=0 or when high-weight criteria are saturated/dead.
- Assumptions/dependencies: Logging of per-criterion verdicts; stable rubric taxonomy; judge consistency.
- Faster, cheaper post-training iterations
- What: Achieve the same plateau in 2.5–4× fewer steps by reallocating within-category pressure, reducing compute and labeling costs for iterative model updates.
- Sectors: Any RL post-training program under tight compute budgets.
- Tools/products/workflows:
- “Target-reward scheduler” that stops training once validation thresholds are crossed (as in the paper’s threshold table).
- Assumptions/dependencies: Comparable GRPO configuration; monitoring of validation rubric scores.
- Multi-dimensional quality alignment for enterprise assistants
- What: Train assistants to simultaneously satisfy factuality, completeness, instruction-following, guarded tone, and formatting rubrics, with improved strict completion (all-required criteria passed).
- Sectors: Customer support, enterprise knowledge management, legal/compliance drafting, financial reporting.
- Tools/products/workflows:
- Organization-specific rubric libraries with category balance (e.g., Safety, Compliance, Helpfulness, Style).
- “Strict-completion gate” in deployment: ship only responses that satisfy all required criteria.
- Assumptions/dependencies: High-quality domain rubrics; human/SME review of rubric definitions; explicit required vs optional criteria.
- Multimodal assistants that actually look at images
- What: In vision-LLMs, reweight visual perception/reasoning criteria when they are contrastive to mitigate “reasoning past the image.”
- Sectors: Healthcare imaging triage, document understanding (charts, screenshots), industrial inspection, retail catalog QA.
- Tools/products/workflows:
- Perception-focused rubric categories (grounding, object/region references).
- Evidence-gated prompts plus rubric items tied to visual references.
- Assumptions/dependencies: Rubric criteria anchored to specific visual elements; reliable multimodal judge behavior.
- Curriculum-aware rubric design and data curation
- What: Use the diagnostic to prune or rewrite saturated/dead criteria and author more contrastive items, improving label efficiency.
- Sectors: Dataset creation teams in industry/academia; MOOC/ed-tech rubric authors.
- Tools/products/workflows:
- “Contrastive authoring assistant” that proposes criterion rewrites where pass-rate ≈ 0 or 1.
- Assumptions/dependencies: Access to intermediate verdict stats; rubric governance process.
- Safety and compliance monitoring via criterion variance
- What: Identify high-variance safety/compliance criteria where the model is inconsistent; focus human review and red-teaming there.
- Sectors: Safety engineering, trust & safety, regulated industries.
- Tools/products/workflows:
- “Variance router” to route human audit to criteria/prompts with highest vj.
- Assumptions/dependencies: Transparent criterion logs; privacy controls on prompt data.
- Academic use: teaching and research on multi-objective RL
- What: Use POW3R as a concrete example of training-time scalarization, and the diagnostic to study learnability vs importance decoupling.
- Sectors: Academia (CS/ML courses, RL research).
- Tools/products/workflows:
- Teaching labs: implement the variance-based factor with clipping and EMA; ablate λ, EMA, clip bounds.
- Assumptions/dependencies: Small compute budgets suffice on toy tasks; open rubrics or course rubrics.
- Evaluation-time rubric normalization for fair comparisons
- What: Keep the evaluation scalar target fixed (static aggregation) while using policy-aware weighting only during training; prevents metric drift and overfitting to moving targets.
- Sectors: Benchmarking groups, internal eval teams.
- Tools/products/workflows:
- Dual-path eval: dynamic for training, static for reporting.
- Assumptions/dependencies: Separation of train-time reward from test-time scoring; consistent held-out judges.
Long-Term Applications
The following are promising but require further research, scaling, or system development.
- Co-evolving rubrics and policy-aware training
- What: Jointly learn rubrics (generate/refine criteria) and policy-aware weights, keeping category mass aligned to governance priorities while adapting to model capability growth.
- Sectors: Education (adaptive grading), scientific writing/coding assistants, enterprise governance.
- Tools/products/workflows:
- “Rubric co-pilot” that proposes new criteria when categories lack contrast or miss failure modes; human-in-the-loop approval.
- Assumptions/dependencies: Reliable rubric generation; safeguards against reward gaming; SME oversight.
- Multi-judge ensembles and uncertainty-aware reward routing
- What: Combine multiple judges (LLMs or human+AI) and weight criteria using both verdict variance across rollouts and inter-judge disagreement to reduce bias and overfitting.
- Sectors: Safety-critical domains (healthcare, finance, legal), public procurement.
- Tools/products/workflows:
- Judge arbitration layer with cost–quality budget; active selection of which criteria get higher-effort judging.
- Assumptions/dependencies: Budget for multiple judges; calibration datasets; robust aggregation schemes.
- Token- or step-level policy-aware credit assignment
- What: Extend criterion-level reweighting to token-level or chain-of-thought step reweighting to emphasize segments that drive pass/fail distinctions.
- Sectors: Reasoning-heavy assistants (math, coding), robotics planning via language (semantic plans).
- Tools/products/workflows:
- Attribution traces (rationales) aligned to rubric items; per-span rewards.
- Assumptions/dependencies: Reliable rationale extraction; alignment between steps and criteria; prevention of spurious shortcuts.
- Continual learning and deployment monitoring with policy-aware signals
- What: In production, monitor criterion variance and strict completion; trigger targeted fine-tuning when drift increases in high-priority categories (e.g., safety, grounding).
- Sectors: SaaS assistants at scale, customer support, search/QA platforms.
- Tools/products/workflows:
- “Policy-aware drift detector” and auto-refresh pipelines that prioritize contrastive areas.
- Assumptions/dependencies: Streaming evaluation infrastructure; privacy-preserving logging; guardrails for on-call updates.
- Cross-domain standardization of rubric taxonomies and weights
- What: Create shared, interoperable rubric ontologies (e.g., factuality, safety, instruction-following, grounding) with agreed category mass for audits and procurement.
- Sectors: Standards bodies, regulators, consortia (health, finance, education).
- Tools/products/workflows:
- Reference rubric sets; certification checklists using strict completion and per-category scores.
- Assumptions/dependencies: Industry consensus; legal frameworks; mapping of domain-specific criteria to common taxonomy.
- Contrast-aware labeling and compute budgeting
- What: Dynamically allocate judge calls, human labels, and compute toward prompts/criteria with highest expected training signal (variance), reducing overall cost.
- Sectors: Data operations, labeling vendors, startups optimizing RL budgets.
- Tools/products/workflows:
- “Contrastive scheduler” that throttles low-signal criteria; adaptive group size G per prompt.
- Assumptions/dependencies: Online estimation stability; guard against neglecting rare but critical criteria.
- Application to tool-use and agentic systems
- What: Use policy-aware rubric rewards where criteria capture correct tool invocation, evidence citation, and reference chaining; emphasize criteria that distinguish successful tool sequences.
- Sectors: Retrieval-augmented systems, code agents, research assistants.
- Tools/products/workflows:
- Rubrics with tool-calling categories (grounding, citation, function choice); event-level verdicts.
- Assumptions/dependencies: Tool telemetry; robust judges for tool outcomes; prevention of tool misuse gaming.
- Safety-case construction and regulatory audits
- What: Build audit trails showing that human importance weights were preserved while training pressure was adaptively routed to learnable criteria; report per-category improvements and strict completion.
- Sectors: Medical devices software, financial advisory, public-sector AI.
- Tools/products/workflows:
- “Policy-aware audit pack” with criterion-level timelines, variance trendlines, and holdout performance.
- Assumptions/dependencies: Longitudinal logging; immutable records; third-party validation.
- Extension beyond GRPO to other RL objectives
- What: Integrate policy-aware scalarization into PPO variants, off-policy RL, or population-based RL where group-relative standardization differs.
- Sectors: Research, advanced model training groups.
- Tools/products/workflows:
- Adapters that compute criterion variance without GRPO’s within-prompt group.
- Assumptions/dependencies: Theoretical/empirical validation; equivalent contrast signals for other objectives.
- On-device or privacy-preserving policy-aware training
- What: Apply policy-aware reward routing with local/edge judges or federated verdict aggregation for sensitive domains (health/finance).
- Sectors: Healthcare providers, banks, edge AI vendors.
- Tools/products/workflows:
- Lightweight judges, secure aggregation; local rubric caches.
- Assumptions/dependencies: Efficient judges; privacy guarantees; limited compute constraints.
Common assumptions and dependencies across applications
- Judge quality and bias: Policy-aware factors depend on judge verdicts; systematic judge bias will steer training pressure. Multi-judge or calibration can mitigate this.
- Rubric quality: Benefits hinge on well-authored, category-labeled criteria with meaningful required/optional flags and human weights that represent organizational priorities.
- Contrast signal availability: If most criteria are saturated or dead, gains are limited until rubrics are revised or models are diversified (temperature, decoding).
- Compute/config: Requires group-based sampling (GRPO-like), criterion-level scoring, and logging; λ, EMA, and clipping bounds need light tuning but are robust.
- Reward hacking risk: As with any reward shaping, guard against models exploiting judge idiosyncrasies; keep evaluation metric fixed (static aggregation) and use external benchmarks.
Glossary
- Advantage (GRPO advantage): The standardized per-token signal used to weight updates for a rollout within GRPO; zero when all rollouts tie. "where every advantage is zero."
- Binary reward: An all-or-nothing reward signal that gives credit only if every required criterion is met. "Binary: a sparse all-or-nothing reward,"
- Category-balanced reward: A rubric aggregation that normalizes weights so each rubric category contributes equally, regardless of how many criteria it contains. "Category-balanced: the static category-balanced reward"
- Category mass: The total reward weight allocated to a rubric category after normalization or reweighting. "so that the human weight prior and category mass remain intact."
- Category-normalized baseline: The baseline reward that equalizes total weight across rubric categories before combining criterion scores. "Category-normalized baseline."
- Dead criterion: A rubric criterion currently failed by all rollouts and thus providing no group-relative learning signal. "A criterion is dead when no rollout passes it (), saturated when every rollout passes it (), and mixed when verdicts differ across the rollout group;"
- DeepSpeed ZeRO-3: A distributed optimization strategy that partitions optimizer states, gradients, and parameters to enable training larger models. "under DeepSpeed ZeRO-3"
- Dense spatial rewards: Fine-grained reward signals defined over spatial regions (e.g., pixels or bounding boxes) to supervise visual grounding. "adds visual perception rewards, evidence gates, dense spatial rewards, or token-level reweighting"
- EMA (Exponential Moving Average): A smoothing method that updates weights or factors by blending past values with current estimates. "and EMA-updates:"
- Evidence gates: Reward mechanisms that incentivize models to cite or attend to relevant evidence before receiving credit. "adds visual perception rewards, evidence gates, dense spatial rewards, or token-level reweighting"
- GRPO (Group Relative Policy Optimization): A reinforcement learning algorithm that compares multiple rollouts per prompt to compute relative advantages without a learned value model. "We post-train policies with Group Relative Policy Optimization (GRPO)"
- GRPO standardization: The within-group normalization of scalar rewards to zero mean and unit variance before computing advantages. "before GRPO standardization"
- KL coefficient (Kullback–Leibler): The weight on the KL-regularization term that keeps the policy close to a reference model during training. "KL coefficient "
- Outcome supervision: A training setup where each rollout receives a single scalar reward at the end (as opposed to stepwise or token-level feedback). "We use outcome supervision:"
- Pareto dominance: A multi-objective comparison where one method is strictly better on at least one metric and no worse on others. "so it Pareto-dominates the other four constructions"
- Policy-aware factors: Dynamic per-criterion multipliers that reweight rubric items based on how much they currently differentiate policy rollouts. "Policy-aware factors."
- POW3R (Policy-Aware Rubric Reward): A framework that preserves human rubric weights and category balance while dynamically reweighting criteria to emphasize those that separate current rollouts. "We introduce POW3R, a policy-aware rubric reward framework"
- Reference-to-policy ratio: The ratio of probabilities under the reference and current policies used in the KL penalty computation. "for the reference-to-policy ratio"
- Reward scalarization: The process of combining multiple rubric criteria into a single scalar signal for optimization. "a broader fixed-scalarization issue in multi-reward RL"
- Reward spread: The standard deviation of rollout rewards within a group before standardization, indicating how separable the rollouts are. "Prompt-level reward spread"
- RLVR (Reinforcement Learning with Verifiable Rewards): Post-training where success can be automatically checked by a verifier or judge, enabling scalable reinforcement signals. "Reinforcement learning with verifiable rewards (RLVR) has become a central recipe"
- Rollout: A sampled response from the policy for a given prompt, used within a group to compute relative advantages. "we sample rollout groups on prompts"
- Rollout contrastiveness: The degree to which a criterion’s judgments vary across rollouts, measured by the variability of verdicts and used to guide reweighting. "measures each criterion's rollout contrastiveness from the smoothed standard deviation of its judge verdicts"
- Rubric aggregation: The method of combining individual rubric criterion scores into a single rollout reward. "rubric aggregation deserves to be treated as a first-class training-time design choice"
- Rubric-based rewards: Rewards constructed by scoring prompt-specific criteria with a judge and aggregating them into a scalar for RL. "Rubric-based rewards extend RL post-training"
- Rubric-pressure diagnostic: An analysis that tracks how much training pressure each criterion receives and whether it provides contrastive signal. "Rubric-pressure diagnostic."
- Saturated criterion: A rubric criterion currently passed by all rollouts and thus providing no group-relative learning signal. "saturated when every rollout passes it ()"
- Schulman k3 estimator: A specific form of the KL divergence estimator used per token in policy optimization. "the per-token Schulman~k3 estimator is"
- Sparse reward: A reward signal that provides credit only in rare, all-correct cases, offering little gradient signal otherwise. "a sparse all-or-nothing reward,"
- Strict completion: The metric measuring the fraction of prompts whose responses satisfy every required rubric criterion. "strict completion (the fraction of prompts whose response satisfies every required rubric criterion)"
- Token-level reweighting: Adjusting contributions of individual tokens to the training objective based on their importance or alignment. "token-level reweighting"
- Training pressure: The effective share of the optimization signal that each criterion contributes during training. "We track each criterion's training pressure"
- Variance (criterion): The variability of a criterion’s pass/fail judgments across rollouts, indicating how contrastive it is. "variance "
- VLM benchmarks: External evaluation suites for vision-LLMs assessing perception and reasoning across tasks. "external VLM benchmarks"
Collections
Sign up for free to add this paper to one or more collections.