- The paper introduces NudgeRL, which employs strategy nudging to guide exploration in RLVR by appending context cues that drive diverse reasoning trajectories.
- The method uses an inter-intra advantage assignment and a distillation objective to efficiently transfer context-guided learning into a context-free policy.
- Empirical findings show NudgeRL achieves up to 8× sample efficiency and superior performance on challenging mathematical reasoning benchmarks.
NudgeRL: Efficient Strategy-Guided Exploration in RLVR
Introduction
Reinforcement Learning with Verifiable Rewards (RLVR) has become foundational for advancing the reasoning capabilities of LLMs, particularly on domains such as mathematical problem solving. RLVR enables scalable policy optimization by utilizing reward functions based on the verifiability of generated answers. However, exploration remains a central obstacle: success in RLVR is fundamentally limited by the diversity and efficiency with which a policy samples and improves upon novel reasoning trajectories.
Traditional methods, such as Group-Relative Policy Optimization (GRPO), typically address exploration via naive sampling (increasing rollout budgets) or minor modifications to the optimization objective (e.g., entropy regularization, decoupled clipping). These approaches provide limited semantic control over the exploration process and readily fall prey to collapse into dominant, univariate modes of reasoning, thereby neglecting rare but promising strategies.
This work introduces NudgeRL, a framework for explicitly structured and diversity-targeted exploration in RLVR settings. The method leverages Strategy Nudging, which conditions rollouts on lightweight, strategy-level textual contexts, and introduces an inter-intra advantage assignment scheme along with a distillation-augmented objective. The result is a principled alternative to brute-force sampling or privileged information methods, yielding strong empirical improvements in mathematical reasoning benchmarks.
Structured Strategy Nudging for Exploration
The primary innovation in NudgeRL is the use of Strategy Nudging during the rollout phase. Rather than relying exclusively on policy-induced diversity, the method appends context-specific, keyword-level strategy prompts (e.g., "Shoelace formula", "Generating functions") to each rollout. These contexts are generated automatically and deliberately force the model to traverse distinct reasoning modes, which dramatically increases the likelihood of sampling otherwise rare, high-value solution trajectories.

Figure 1: Strategy Nudging appends lightweight, heuristic contexts to input prompts, inducing coverage over diverse reasoning approaches and substantially mitigating exploration collapse compared to naive sampling methods.
The approach is motivated by the mathematical costs of random discovery of rare trajectories: for a trajectory y with π(y∣x0)≪1, brute-force sampling requires O(1/π(y∣x0)) rollouts in expectation. By leveraging context c to shift probability mass, NudgeRL reduces this discovery cost for targeted regions of the reasoning space, thus efficiently surfacing successful modes that are otherwise inaccessible.
Empirical clustering of generated solutions confirms that context-based prompting robustly increases the number of distinct reasoning strategies sampled per prompt, with no dependency on privileged, problem-specific knowledge.
Inter-Intra Group Advantage and Distillation Objective
NudgeRL augments the policy update mechanism to handle the more complex context-conditioned rollout structure. The Inter-Intra Group Advantage addresses the problem that traditional group-wise advantage assignment (as in GRPO) conflates context-induced reward variation with underlying trajectory quality. The method separately normalizes intra-context and global baselines, and introduces a flexible weighting parameter λ that governs prioritization between exploitation of reliable contexts and exploration of less conventional modes.

Figure 2: NudgeRL's learning mechanism: (a) Inter-Intra Group Advantage enables reliable advantage assignment across diverse contexts; (b) Advantage-weighted distillation bridges the distributional gap between context-forced exploration and context-free inference, promoting cross-context generalization.
To resolve the train-test mismatch—where the model is ultimately deployed under original, context-free prompts—NudgeRL employs a distillation-augmented RL objective. Trajectories sampled under context conditioning are distilled back into the base policy, selectively reinforcing high-advantage solutions to improve the context-free inference capability.
Empirical Evaluation and Ablations
Extensive experiments are conducted on challenging math datasets (AIME24, AIME25, AMC23, MATH500, Apex) using Qwen3-4B-Instruct-2507 and Olmo3-7B-Instruct-SFT models. Baselines include GRPO (across multiple rollout budgets) and oracle-prefix methods (POPE).
Key empirical findings:
- Superior sample efficiency: NudgeRL matches the performance of GRPO with up to 8× larger rollout budgets, achieving state-of-the-art average pass@1 scores using only 8 rollouts per prompt. Larger rollout budgets in naive GRPO yield diminishing returns and can degrade performance due to sampling redundancy and training instability.
- Effectiveness without privileged information: NudgeRL outperforms oracle-guided exploration (POPE), despite using only unverified strategies generated by a lightweight LLM. This highlights that diversity-driven exploration, not privileged solution signals, is the key bottleneck in RLVR.
- Rapid learning dynamics: On training and held-out test sets, NudgeRL exhibits faster and more robust reward and pass@k improvements, reflecting both superior exploration and more efficient credit assignment.
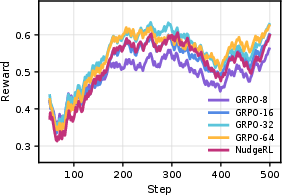
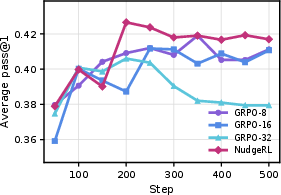
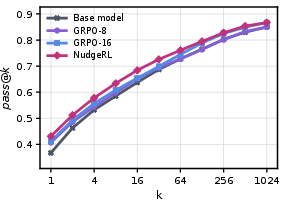
Figure 3: EMA-smoothed training reward shows NudgeRL overtaking all GRPO variants in convergence speed and stability.
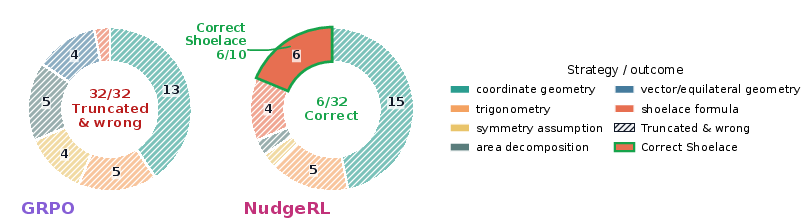
Figure 4: Case study—NudgeRL reliably internalizes rare but effective strategies (e.g., shoelace formula) and discovers correct solutions where GRPO collapses to truncated or unsuccessful reasoning pathways.
Ablation studies demonstrate:
- Moderate values of context dropout (pdrop=0.5) and distillation coefficient (λdistill=0.1) both maximize performance, balancing exploration diversity and stable training.
- Random sampling of contexts (vs. top-ranked selection) provides better coverage of successful solution modes, supporting the hypothesis that the primary benefit of context nudging is in diversification, not direct hinting.
- The λ parameter, controlling inter-context exploitation-exploration balance, is best set slightly above 1 (λ=1.1), enabling robust preference for reliable strategies without suppressing diversity.
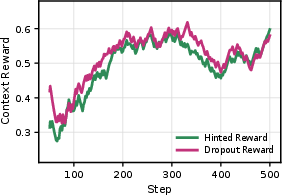
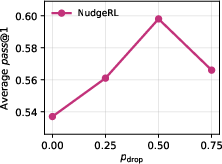
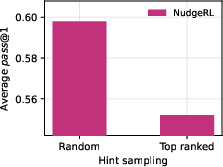
Figure 5: Ablation on π(y∣x0)≪10 highlights the importance of balancing context-conditioned and base prompt sampling for optimal performance.
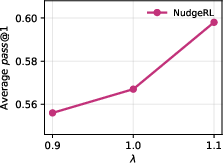
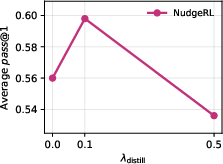
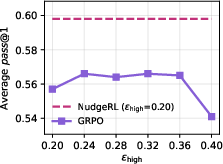
Figure 6: Varying π(y∣x0)≪11 tunes the trade-off between exploration and exploitation; π(y∣x0)≪12 yields the best generalization.
Theoretical and Practical Implications
The structured approach to exploration instantiated by NudgeRL demonstrates that effective RLVR policies are not primarily constrained by sample quantity, but by the semantic diversity of trajectories surfaced during training. Privileged supervision (oracle prefixes, solutions, or text feedback) offers only limited gain compared to principled structuring of the exploration process.
This finding has significant implications:
- Scalability: Lightweight contexts can be generated offline and reused, decoupling exploration efficiency from computational intensity or annotation costs.
- Generalizable policy improvements: Diversity-driven exploration supports the robust distillation of successful strategies into base policies, minimizing dependency on externally-imposed hints.
- Limitations: The use of static context pools may diminish in effectiveness as the base policy improves. Adaptive, policy-aware context generation could yield further improvements, particularly for non-stationary or advancing LLMs.
Conclusion
NudgeRL provides a principled, computationally efficient, and empirically validated mechanism for overcoming exploration bottlenecks in RLVR for reasoning LLMs. By structuring rollout diversity with strategy-level context conditioning, and transferring successful behaviors via distillation, NudgeRL effectively outperforms brute-force and oracle-based exploration schemes across benchmarks. The methodology illustrates that scalable, context-driven exploration is both sufficient and preferable for advancing LLM reasoning capacities in RLVR settings. Future work should investigate closed-loop, policy-adaptive context generation and broader applications of structured exploration beyond mathematical reasoning.
References
NudgeRL: "Nudging Beyond the Comfort Zone: Efficient Strategy-Guided Exploration for RLVR" (2605.15726)