VLA-REPLICA: A Low-Cost, Reproducible Benchmark for Real-World Evaluation of Vision-Language-Action Models
Abstract: Vision-Language-Action (VLA) models have shown strong promise for general-purpose robotic manipulation, but their real-world evaluation remains limited by a lack of accessible, reproducible, and consistent benchmarks. Simulation benchmarks fail to capture real-world complexity, while existing real-world benchmarks often require expensive hardware, centralized evaluation, or are limited in task diversity. We introduce VLA-REPLICA, a low-cost, easily reproducible real-world benchmark for evaluating VLA models. Built from off-the-shelf components, our system can be quickly assembled and replicated across laboratories, providing a consistent environment for policy evaluation anywhere in the world. VLA-REPLICA includes a diverse suite of manipulation tasks and a small-scale demonstration dataset for target-domain adaptation, with real-world evaluation protocols for both in-distribution and out-of-distribution settings. Experiments with imitation learning and state-of-the-art VLA models reveal model strengths and limitations, while consistent results across independently constructed setups demonstrate the reproducibility of our benchmark.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
VLA-REPLICA: A simple explanation
Overview
This paper introduces VLA-REPLICA, a low-cost, easy-to-build testing setup for robots that can understand vision, language, and actions (called “VLA” models). Think of it like a standardized obstacle course where different robots can be fairly tested on real-world tasks, not just in video-game-like simulations. The goal is to make it simple for labs anywhere to build the same setup, run the same tests, and compare results honestly.
What questions does the paper ask?
To make the idea clear, here are the main questions the researchers wanted to answer:
- How can we test smart robots in the real world in a way that’s cheap, easy to repeat, and fair across different places?
- Can modern VLA models learn from a small number of real examples and perform well on those tasks (in-distribution)?
- Can these models handle new variations of tasks they’ve never seen before, like changes in colors, shapes, or instructions (out-of-distribution)?
- Will the same robot policy get similar results if we build the same setup in a different lab (reproducibility)?
How did they do it? Methods and setup
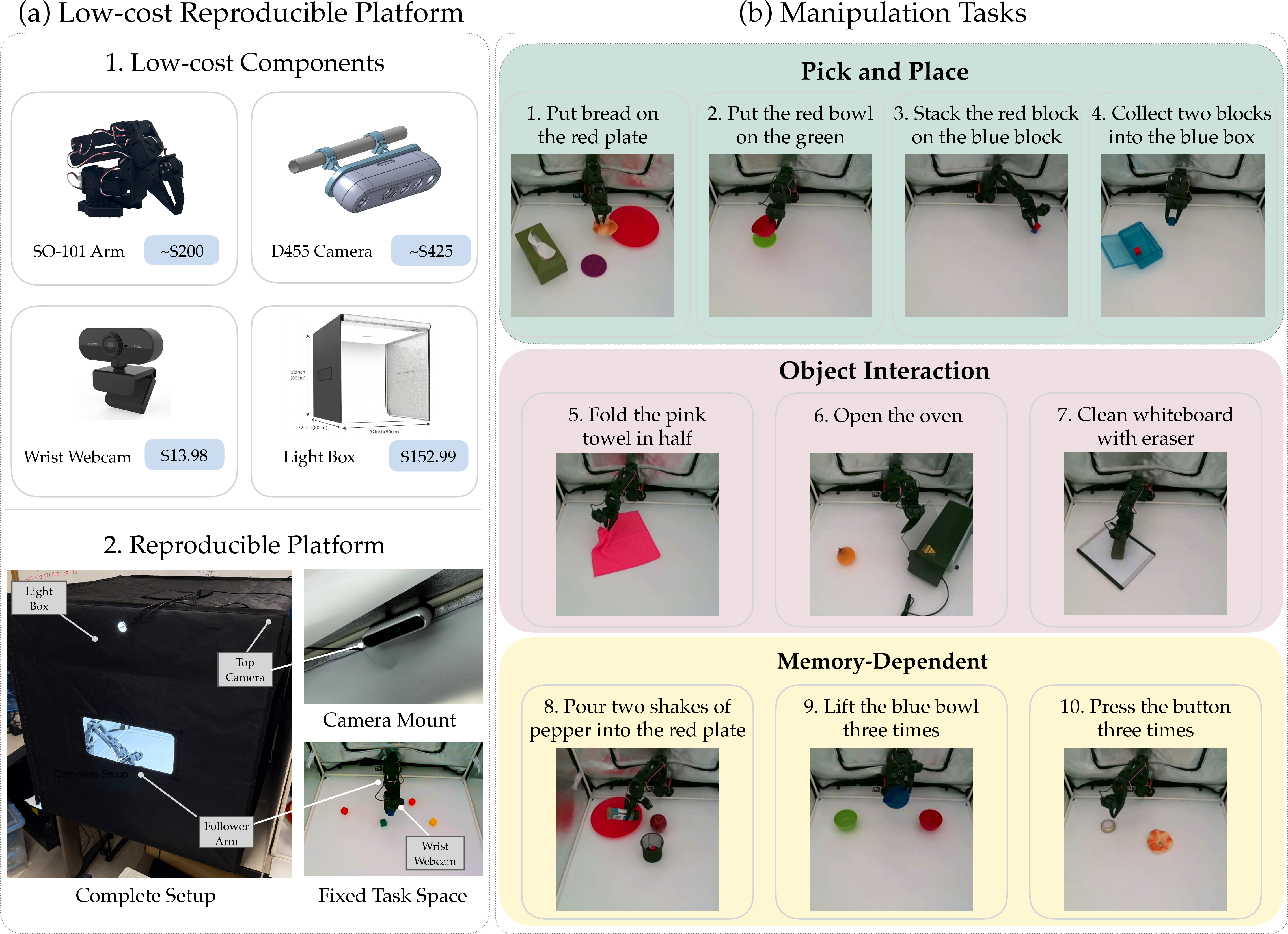
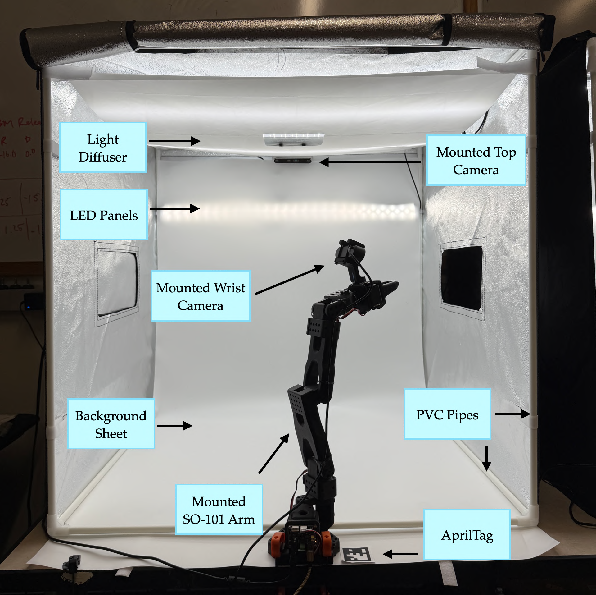
The team built a physical robot testing station using affordable parts, so anyone can recreate it:
- The robot: a low-cost SO-101 robotic arm (mostly 3D-printed parts).
- Cameras: one camera attached to the robot’s wrist to “see what the hand sees,” and another camera above the workspace for a top-down view.
- A light box: a small photo studio box that keeps lighting steady and consistent, so videos and images look the same everywhere.
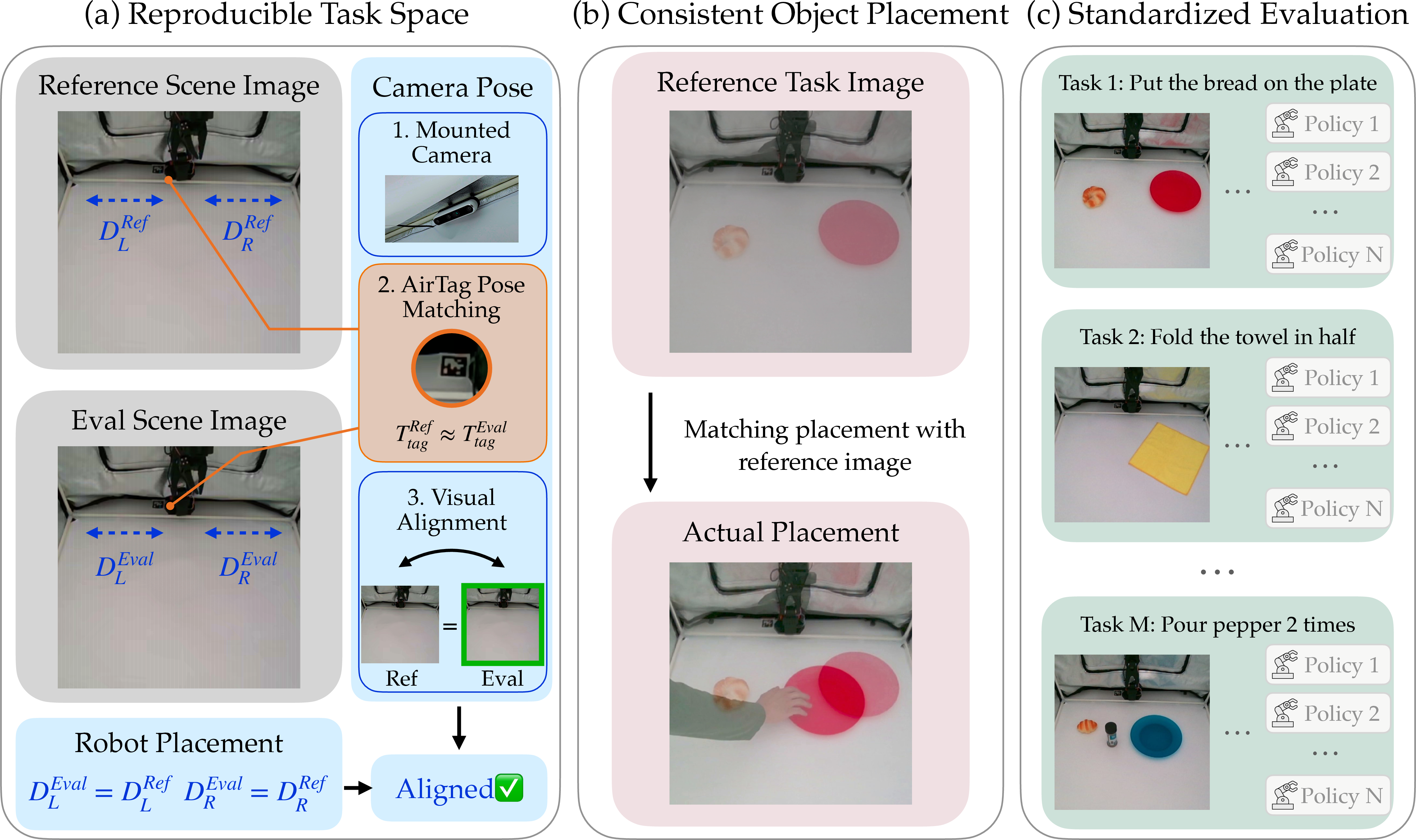
- Object placement by overlay: they use reference images overlaid on the live camera feed so you can place objects exactly where the test requires. It’s like tracing a picture to get everything in the right spot.
- Calibration: robots need to agree on what a “move” means. They use a simple calibration process so actions can be translated between different SO-101 arms. Think of this like setting the same “zero point” on two different game controllers so pushing the joystick halfway means the same thing on both.
They built a suite of 10 real-world tasks that cover:
- Pick and place (like putting bread on a plate, stacking blocks).
- Object interaction (like folding a towel, opening a toy oven, erasing a whiteboard).
- Memory/counting tasks (like shaking pepper a certain number of times, pressing a button a set number of times).
They collected 500 short demonstration videos showing how to do these tasks, then used them to train or fine-tune robot policies. They tested two types of scenarios:
- In-distribution (ID): tasks similar to the training examples but with different positions or small variations.
- Out-of-distribution (OOD): tasks with changes not seen during training, like new colors, shapes, or different repetition counts (e.g., “press the button 4 times” when the model only trained on 1 or 3 times).
What did they find, and why does it matter?
Key results:
- Fine-tuned VLA models generally did better than models trained from scratch on the demonstration videos. Pretraining helps.
- Robots handled soft, forgiving objects (like bread or towels) better than rigid, tricky ones (like small blocks), which require precise grasps.
- Models were okay at handling new colors or slightly different shapes, but struggled with tasks that need memory and counting (e.g., “shake pepper exactly 2 times”). Many kept going too long or lost track of the count.
- When the same setup was rebuilt in a different place, results were similar. This shows the benchmark is genuinely reproducible.
Why it’s important:
- Real-world testing is usually expensive or hard to standardize; this setup makes it affordable (about $1,050) and easy to copy.
- It helps the research community fairly compare different robot models and improve them.
- It reveals current weaknesses in VLA models, especially with precise manipulation and keeping track of repeated actions.
What’s the bigger impact?
This benchmark can speed up progress in robotics by giving everyone a common, real-world playing field that’s inexpensive and consistent. It:
- Makes it easier for schools, smaller labs, and hobbyists to test advanced robot models.
- Encourages honest comparisons so improvements are clear and trustworthy.
- Highlights where VLA models need work, like better memory for counting or more precise gripping.
Simple limitations to keep in mind:
- It focuses on tabletop tasks with one type of robot; more types of robots and environments would be even better.
- There are “only” 10 tasks, which is fewer than huge simulation test suites, but they’re real and reproducible.
- Tiny differences in hardware, lighting, or object placement can still affect results, even with careful setup.
In short, VLA-REPLICA is like a shared robotics “test track” that’s cheap, easy to build, and gives realistic feedback on how well vision-and-language-powered robots can actually perform in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open problems that remain unresolved and could guide future research and benchmark development:
- Embodiment generality: The benchmark is tied to a single low-cost SO-101 arm and end-effector; it is unknown how results transfer to other robot embodiments (different kinematics, payloads, grippers, compliance, torque sensing) or higher-precision industrial arms.
- Action space limitations: Only joint-angle position control is standardized; the impact of alternative action spaces (Cartesian pose, velocity control, impedance/force control, hybrid position–force) on learning and reproducibility is unexplored.
- Hardware non-idealities: The calibration assumes linear scaling and ignores servo backlash, non-linearities, thermal drift, and latency; no quantification of how these factors affect policy performance or reproducibility across units.
- Long-term stability: There is no assessment of performance drift over time (e.g., servo wear, repeated assembly/disassembly); define maintenance and recalibration intervals and measure their effect on results.
- Sensor configuration scope: Only a top RGB-D and a wrist RGB camera are used; the contribution of additional sensing (tactile, force-torque, joint torques, higher-fidelity wrist RGB-D) to performance and robustness is untested.
- Camera settings control: Auto-exposure/white balance, camera intrinsics/extrinsics variability, and their tolerances are not reported; specify fixed settings and quantify sensitivity to deviations (e.g., ±1–2% focal length, ±5° pose).
- Lighting realism: The light-box at ~5600K reduces real-world variability; robustness to lighting changes (temperature, intensity, shadows, glare) and open-world backgrounds is not evaluated.
- Object supply variability: The benchmark uses commodity objects whose colors/materials can vary by batch/vendor; there is no tolerance spec or color calibration procedure, nor a 3D-printable canonical object set to ensure long-term availability.
- Task scale and diversity: Only 10 tasks (8 for OOD) are included; missing are long-horizon, multi-stage assembly, precision insertion, deformable manipulation breadth, tool-use diversity, and tasks requiring force-sensitive control.
- OOD breadth: OOD shifts are mostly color/shape swaps and small count changes; generalization to novel categories, textures, sizes, masses, friction, clutter, distractors, occlusions, and multi-object compositions remains untested.
- Language generalization: Instructions appear templated; there is no evaluation of paraphrases, compositional instructions, multi-turn dialogue, referring expressions, or multilingual commands.
- Memory and state tracking: Models fail on counting/memory tasks; it remains open how to design tasks and sensors to robustly test temporal state (e.g., event detectors, audio/tactile cues, external counters) and which model architectures best address it.
- Automatic success detection: Success is reported as binary rates over five trials, but the benchmark lacks automated, programmatic success criteria (e.g., vision-based detectors, fiducials, depth-based geometry checks) and corresponding accuracy validation.
- Statistical rigor: Results lack confidence intervals, hypothesis tests, and seed variability; increase trials per task, run ≥3–5 training seeds, and report mean±std and significance to enable reliable comparisons.
- Sample efficiency: All models use 500 demos; there is no learning-curve analysis vs. number/quality/diversity of demonstrations, multi-operator data, or noisy/partial demonstrations.
- Training fairness and transparency: Fine-tuning scopes differ across VLA baselines (e.g., frozen vs. unfrozen encoders) without standardized hyperparameters, compute budgets, input resolutions, or data augmentations; a shared, pre-registered recipe is needed.
- Inference constraints: The benchmark does not standardize or report inference hardware, latency, control frequency, or energy; evaluate policy sensitivity to latency/jitter and define acceptable real-time budgets.
- Zero-shot capability: The study emphasizes fine-tuning on target-domain demos; zero-shot or few-shot performance without fine-tuning, and cross-embodiment zero-shot transfer, remain unassessed.
- Sim-to-real integration: There is no paired simulation suite or domain randomization protocol to study sim-to-real transfer aligned with the real tasks and objects.
- Reproducibility at scale: Reproducibility is shown at one additional site and on a subset of tasks; multi-site (≥5 labs), blinded replications with pre-registered protocols and inter-lab variance analyses are needed.
- Setup tolerances: The overlay-based reconstruction lacks quantitative tolerances (e.g., object position/orientation errors ±x mm/±y°) and empirical sensitivity curves mapping placement error to success rate.
- Reset and operator effects: Human variability in scene setup, reset procedures, and teleoperation skill is not quantified; introduce standardized checklists, training for operators, and audits of reset quality.
- Failure taxonomy: The paper reports success rates but not failure-mode analyses (e.g., grasp pose errors, perception misclassification, memory lapses); release labeled failure logs to guide targeted improvements.
- Data and logging standard: There is no mandated logging schema for actions, observations, timestamps, and events; define a standardized, versioned log format to enable cross-lab auditing and post-hoc analysis.
- Leaderboard and governance: Although “distributed evaluation” is supported, there is no public leaderboard, submission format, or governance for versioning benchmark updates and ensuring comparability over time.
- Safety protocols: Safety considerations (e-stop standards, pinch hazards, failure containment) are not specified; define minimum safety requirements for labs reproducing the benchmark.
- Instruction provenance: The process for generating task instructions (diversity, ambiguity handling) is not documented; provide instruction sets with paraphrase clusters and difficulty tiers.
- Robustness to disturbances: There is no evaluation under perturbations (table bumps, object slips, moving distractors); add standardized disturbance scripts to probe closed-loop robustness.
- End-effector diversity: Only one gripper type appears used; test effect of different grippers (soft, suction, underactuated) on benchmark results and generality claims.
- Environmental scaling: The setup is limited to a small light box; it is unclear how policies scale to larger workspaces, mobile manipulation, or partially observable settings beyond a fixed top view.
- Continuous improvement pathway: The paper does not define a roadmap for expanding tasks, objects, or sensing; outline a versioning strategy and compatibility plan to prevent benchmark fragmentation.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging VLA-REPLICA’s low-cost hardware, standardized environment, test scenes, calibration tooling, and released demonstrations.
- BoldLab-grade real-world evaluation of VLA policies: Standardize in-lab benchmarking of language-conditioned robot manipulation across ID and OOD scenarios using the provided 10-task suite and 90 test scenes. Sectors: robotics, software, academia. Tools/workflows: camera overlay app, AprilTag calibration, universal action-space mapping, LeRobot training scripts, success-rate reporting. Assumptions/dependencies: access to SO-101 arm, RealSense D455, light box, object set, and pretrained VLA weights or compute for fine-tuning.
- BoldPolicy QA and regression testing for robot control stacks: Integrate the benchmark as a continuous test suite to catch performance regressions after model updates (e.g., post-fine-tuning). Sectors: robotics software, DevOps/ML Ops. Tools/workflows: CI pipelines triggering ID/OOD trials, automated success-rate dashboards, change impact reports. Assumptions/dependencies: stable hardware calibration and repeatable scene setup; test automation scripts; operator time or automation for object placement.
- BoldTarget-domain adaptation workflow: Fine-tune pretrained VLA models on the released 500 demonstrations to adapt policies to local workspaces and objects. Sectors: industrial robotics R&D, SMEs in automation, academia. Tools/workflows: 40K-step fine-tuning using LeRobot, teleoperation for additional demos, universal action recording and replay. Assumptions/dependencies: GPU/compute availability; access to pretrained models; consistent telemetry and data logging.
- BoldCross-lab reproducibility studies: Build identical setups across institutions to generate directly comparable results without centralized evaluation. Sectors: academia consortia, open benchmark communities. Tools/workflows: shared reference scenes, camera overlay alignment, action normalization (Eq. 3), common reporting templates. Assumptions/dependencies: adherence to lighting specs and object placements; sourcing identical hardware; local operator training.
- BoldEducation lab kit and curriculum: Use the <$1100 bill of materials to teach modern VLA, imitation learning, calibration, and real-world evaluation in courses and clubs (including high schools). Sectors: education, maker/hobbyist communities. Tools/workflows: setup instructions, task definitions, grading rubrics for success-rate targets, capstone assignments (e.g., towel fold vs. block stacking). Assumptions/dependencies: budget, supervision and safety protocols, space for the light box.
- BoldPre-deployment OOD stress testing for color/shape variability: Evaluate whether prototypes retain performance when object color/shape or counts change (e.g., bowls, towels, cubes), prior to field trials. Sectors: warehouse/retail micro-fulfillment, service robotics R&D. Tools/workflows: OOD scene pack, differential performance tracking vs. ID. Assumptions/dependencies: mapping benchmark tasks to domain-relevant surrogates; substituting domain objects where appropriate.
- BoldScene setup standardization toolkit: Use the overlay-based placement procedure and lighting control in any tabletop manipulation experiment to reduce variance and improve result comparability. Sectors: robotics research, HRI, lab infrastructure. Tools/workflows: top-view camera mounting, overlay GUI, lighting presets, placement checklists. Assumptions/dependencies: camera positioning and stability; operator compliance.
- BoldHardware QA and fleet calibration for SO-101-class arms: Apply the universal action-space calibration to detect servo offset issues and normalize commanded angles across devices. Sectors: robotics hardware labs, prototyping shops. Tools/workflows: lerobot-setup-motors, AprilTag pose logging, angle-to-encoder conversion via calibration matrices. Assumptions/dependencies: servo health; correct zero-position procedures; consistent joint limits.
- BoldRapid pilot evaluation for startups and SMEs: Stand up an affordable real-world testbed in under an hour to iterate on VLA-based manipulation prototypes without expensive platforms or centralized services. Sectors: startup R&D, innovation labs. Tools/workflows: BOM + setup guide, demo dataset bootstrapping, success-rate gates for release criteria. Assumptions/dependencies: local technical staff; safety compliance; model licensing.
Long-Term Applications
These applications require further research, scaling, or ecosystem development to reach maturity.
- BoldCertification and standards for reproducible real-robot evaluation: Establish “VLA-REPLICA Certified” criteria for policy readiness, with mandated ID/OOD thresholds and calibration audits. Sectors: policy/regulatory, industry consortia, insurers. Tools/products: certification audits, standardized reports, compliance badges. Assumptions/dependencies: governance body, consensus metrics, legal and safety frameworks.
- BoldDecentralized benchmark network and federated leaderboards: Create a global, self-run evaluation network with auditable protocols and cross-site comparability. Sectors: academia/industry benchmark communities. Tools/products: result submission portal, audit procedures, provenance tracking, scene seeds. Assumptions/dependencies: trust and verification mechanisms; standardized hardware and environments; reproducibility monitors.
- BoldExtension to multiple embodiments and task families: Scale VLA-REPLICA to different arms, grippers, and long-horizon tasks (assembly, tool-use sequences) with harmonized action spaces and scene overlays. Sectors: manufacturing robotics, household/service robots. Tools/products: Replica-X kits per embodiment, cross-robot action mapping utilities, expanded object libraries. Assumptions/dependencies: new calibration pipelines; gripper/contact models; broader safety protocols.
- BoldMemory-aware control modules and evaluation: Develop architectures that robustly track action counts and temporal context (addressing observed failures on counting tasks) and validate them on expanded memory tasks. Sectors: robotics AI, software. Tools/products: event counters, recurrent or external memory modules, temporal consistency checks, enriched datasets. Assumptions/dependencies: algorithmic advances; larger-scale demonstrations; improved sensing (e.g., force/tactile, audio).
- BoldSimulation-to-real alignment workflows: Use overlay and lighting standardization to bridge synthetic scene renderings with real setups, enabling low-friction sim pretraining then real fine-tuning. Sectors: simulation software, robotics R&D. Tools/products: scene generators matched to real camera intrinsics/extrinsics, photometric lighting models, domain adaptation pipelines. Assumptions/dependencies: accurate calibration; high-fidelity assets; data pipelines between sim and real.
- BoldCommercial test kits and managed services: Package hardware, scenes, scripts, and support into turnkey evaluation products for labs and enterprises; offer Benchmark-as-a-Service with on-site or remote assistance. Sectors: hardware vendors, robotics testing services, education suppliers. Tools/products: boxed kits, maintenance SLAs, remote audit services, training modules. Assumptions/dependencies: supply chain reliability; customer support; recurring updates to tasks and metrics.
- BoldSafety validation and insurance underwriting: Adopt reproducible stress tests (including OOD and memory tasks) as part of safety cases, procurement checklists, and liability assessments for robot deployments. Sectors: enterprise risk, insurance, compliance. Tools/products: standardized hazard scenarios, failure mode catalogs, scoring rubrics tied to insurance premiums or deployment gates. Assumptions/dependencies: recognized standards bodies; integration with broader safety norms (ISO/IEC).
- BoldSector-tailored acceptance testing: Adapt tasks to domain-specific surrogates (e.g., tray handling in healthcare, fold-and-place in hospitality, bin picking in micro-fulfillment) to evaluate readiness pre-deployment. Sectors: healthcare, hospitality, warehousing, agriculture, energy facilities. Tools/products: domain-specific object sets and scenes, task success criteria, OOD variants for robustness. Assumptions/dependencies: mapping from benchmark to real operations; safety and hygiene constraints; operator training.
- BoldEducation standards and global competitions: Integrate VLA-REPLICA into curricula and international competitions, enabling comparable results across schools and countries and fostering reproducible robotics education. Sectors: education, STEM outreach. Tools/products: standardized syllabi, competition rules, judging metrics, open datasets. Assumptions/dependencies: funding and coordination; teacher training; accessible documentation.
- BoldOpen science mandates and funding policy: Encourage agencies and journals to require reproducible real-world evaluation (e.g., VLA-REPLICA or equivalent) for grants and publications in robotics. Sectors: research policy, publishing. Tools/products: reproducibility checklists, recommended benchmarks, artifact-evaluation protocols. Assumptions/dependencies: community buy-in; flexibility to accommodate other embodiments; sustained maintenance of benchmark assets.
Glossary
- 6-DoF: A robot with six independent joints/axes, allowing movement in 3D space with orientation control. "a 6-DoF low-cost SO-101 follower arm"
- Action normalization: The process of mapping raw actuator commands into a standardized action representation. "Action Normalization."
- Action space: The set of all possible actions a control policy can output for a robot. "constrains each arm to its own specific action space."
- AprilTag calibration: Using AprilTag fiducial markers to align and calibrate camera or robot poses. "via AprilTag calibration and video overlay matching."
- Calibration matrix: A matrix used to scale and transform signals (e.g., joint commands) into a standardized coordinate/action space. "a 6×6 diagonal calibration matrix"
- Centralized evaluation: A benchmarking setup where user policies are executed by a central service rather than locally. "require expensive hardware, centralized evaluation, or are limited in task diversity."
- Diffusion Policy: A method that models action generation as a denoising diffusion process conditioned on observations. "extends Diffusion Policy"
- Diffusion Transformer: A transformer-based policy that uses diffusion-based objectives for generating action sequences. "a multi-task Diffusion Transformer"
- Distractor objects: Non-target items placed in a scene that can confuse or challenge a policy during evaluation. "including both target and distractor objects."
- End-effector: The tool or gripper at the end of a robot arm used to interact with the environment. "attach it onto the end-effector of the SO-101 follower arm."
- Flow-matching objective: An alternative generative objective that matches probability flows for action generation instead of diffusion. "replaces the diffusion objective with a flow-matching objective for action generation."
- Gripper pose: The position and orientation of the robot’s gripper relative to the object or workspace. "rigid objects such as blocks are sensitive to the gripper pose"
- Image overlay: Superimposing a reference image onto a live camera feed to standardize object placement and scene setup. "the use of image overlay as a practical tool"
- Imitation learning: Training policies by learning from expert demonstrations rather than explicit reward signals. "Experiments with imitation learning and state-of-the-art VLA models"
- In-distribution (ID): Data or tasks that follow the same distribution as the training set, used to assess fitting within known conditions. "in-distribution (ID) and out-of-distribution (OOD) settings."
- Joint limits: The mechanical bounds of each robot joint’s range of motion. "swept throughout the joint limits"
- Multimodal data: Datasets that combine multiple data types (e.g., vision, language, actions) for training. "leveraging large-scale multimodal data"
- Object-centric interactions: Tasks focused on manipulating specific objects and their properties rather than abstract planning. "other object-centric interactions"
- Out-of-distribution (OOD): Data or tasks that differ from the training distribution, used to test generalization. "in-distribution (ID) and out-of-distribution (OOD) settings."
- Policy checkpoints: Saved snapshots of a trained model’s parameters for later evaluation or deployment. "users submit policy checkpoints or inference APIs"
- RGB-D camera: A camera that captures both color (RGB) and depth (D) information. "Intel RealSense D455 RGB-D camera"
- Raw encoder value: The unprocessed numeric reading from a motor’s position encoder. "a raw encoder value in range "
- Robot embodiment: The specific physical configuration and hardware characteristics of a robot system. "new robot embodiments"
- Servo motor: An actuated motor with feedback control used to precisely position robot joints. "Dynamixel STS3215 servo motors"
- Sim-to-real gap: The discrepancy between performance in simulation and the real world due to unmodeled physical complexities. "they suffer from the well-known sim-to-real gap"
- Teleoperator: A human operator who controls a robot remotely to provide demonstrations or supervision. "through an expert teleoperator"
- Universal action space: A standardized action representation shared across differently constructed robots, enabling reproducible control. "defining a universal action space that all SO-101 arms must share."
- VLA pretraining: Pretraining a Vision-Language-Action model on large datasets before fine-tuning on a target domain. "VLA pretraining provides a useful initialization"
- Vision-Language-Action (VLA) models: Models that map visual and linguistic inputs to robot actions for language-conditioned control. "Vision-Language-Action (VLA) models have shown strong promise"
- VLM: Vision-LLM; a model that learns joint representations of visual and textual inputs. "we fine-tune the VLM and keep the vision encoder frozen."
- Zero position: A standardized reference pose of a robot used for calibration across different hardware instances. "the universal ``zero position'' of all SO-101 arms."
Collections
Sign up for free to add this paper to one or more collections.

