VLA-Arena: An Open-Source Framework for Benchmarking Vision-Language-Action Models
Abstract: While Vision-Language-Action models (VLAs) are rapidly advancing towards generalist robot policies, it remains difficult to quantitatively understand their limits and failure modes. To address this, we introduce a comprehensive benchmark called VLA-Arena. We propose a novel structured task design framework to quantify difficulty across three orthogonal axes: (1) Task Structure, (2) Language Command, and (3) Visual Observation. This allows us to systematically design tasks with fine-grained difficulty levels, enabling a precise measurement of model capability frontiers. For Task Structure, VLA-Arena's 170 tasks are grouped into four dimensions: Safety, Distractor, Extrapolation, and Long Horizon. Each task is designed with three difficulty levels (L0-L2), with fine-tuning performed exclusively on L0 to assess general capability. Orthogonal to this, language (W0-W4) and visual (V0-V4) perturbations can be applied to any task to enable a decoupled analysis of robustness. Our extensive evaluation of state-of-the-art VLAs reveals several critical limitations, including a strong tendency toward memorization over generalization, asymmetric robustness, a lack of consideration for safety constraints, and an inability to compose learned skills for long-horizon tasks. To foster research addressing these challenges and ensure reproducibility, we provide the complete VLA-Arena framework, including an end-to-end toolchain from task definition to automated evaluation and the VLA-Arena-S/M/L datasets for fine-tuning. Our benchmark, data, models, and leaderboard are available at https://vla-arena.github.io.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces VLA-Arena, a big, open-source “testing ground” for robot models that use vision, language, and actions (called VLA models). Think of it like an obstacle course for robots in a simulator: the robot sees a scene (vision), reads an instruction (language), and then tries to do something (action). VLA-Arena helps researchers measure not just whether these models succeed, but exactly how and where they struggle.
What questions does the paper try to answer?
The paper focuses on simple, clear questions:
- How good are current robot models at following instructions and acting safely in different situations?
- Do these models truly learn general skills or do they just memorize patterns from training?
- How much do changes in language or visuals affect their performance?
- Can these models do longer, multi-step tasks by combining smaller skills?
- What tools and data are needed to test these abilities fairly and reproducibly?
How did the researchers test the models?
The authors designed a structured, step-by-step way to test VLA models in a simulator. Imagine video game levels that get harder in different ways. They control difficulty along three independent axes (like turning three knobs):
1) Task Structure (L0–L2)
- L0: “Easy” tasks that look like what the models saw during training.
- L1: Slightly changed tasks (more objects, new combinations, minor obstacles, simple safety rules).
- L2: “Hard” tasks that look quite different from training (new workflows, more clutter, dynamic obstacles, strict safety rules, new object types).
This checks whether models generalize or just memorize. To be fair, models are only fine-tuned on L0, then tested on L1 and L2 to see if they can adapt.
2) Language Commands (W0–W4)
Language is changed gradually using smart word substitutions from WordNet (a big dictionary of word meanings).
- W0: Original instruction (e.g., “Pick up the apple and put it on the bowl.”)
- W1–W4: Replace 1–4 key words with close meanings (e.g., “Select the eating apple and set it on the vessel.”)
This checks whether models still understand instructions when wording changes slightly but meaning stays similar.
3) Visual Observation (V0–V4)
The visuals get more challenging step by step:
- V0: Normal lighting, colors, and camera.
- V1: Lighting changes (brightness/contrast/saturation/temperature).
- V2: Object colors change.
- V3: Camera viewpoint moves.
- V4: Visual noise added (like fuzzy or grainy images).
This sees how well models handle real-world variation, like different lighting or camera angles.
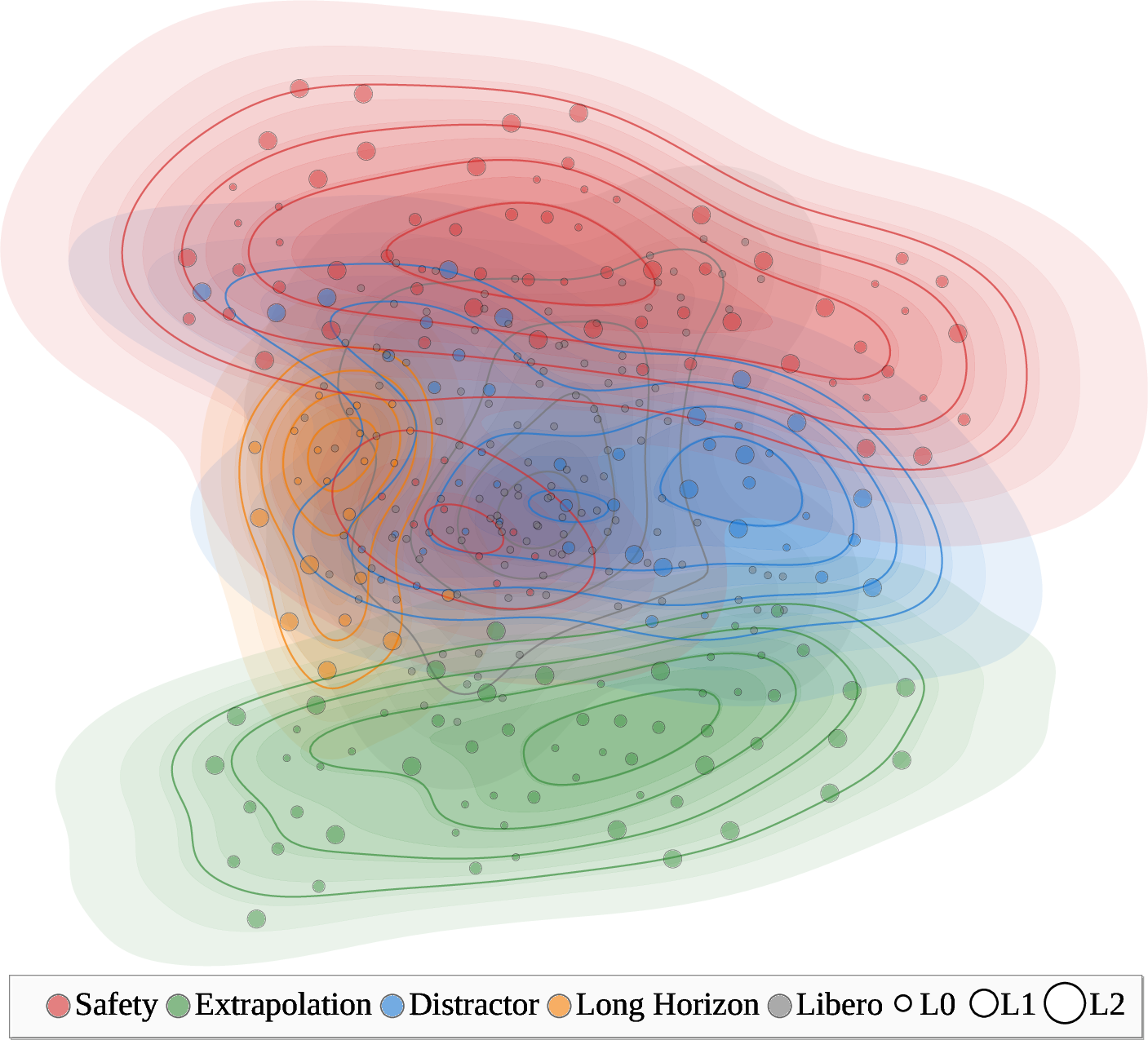
To define tasks precisely and safely, the authors created CBDDL, a formal “rulebook” that can describe dynamic objects (things that move) and safety constraints (like “don’t spill” or “don’t collide”). Using this, they built a benchmark split into four big dimensions, each with task suites and difficulty levels:
- Safety: Avoid hazards, grasp dangerous tools safely, don’t spill, navigate around static and moving obstacles.
- Distractor: Find and manipulate the right object among clutter and moving distractions.
- Extrapolation: Use known skills in new combinations, follow new workflows, handle unseen objects.
- Long Horizon: Chain multiple steps together to finish a longer task.
Finally, they evaluated several state-of-the-art VLA models (from different architectures) and released an open-source toolkit and datasets (S/M/L sizes) so others can train and test consistently.
What did they find, and why does it matter?
Here are the main findings, explained in everyday terms:
- Models often memorize, not generalize:
- They do well on tasks that look like training (L0), but their performance drops when tasks change even a little (L1/L2). This suggests they remember specific setups rather than learning flexible skills.
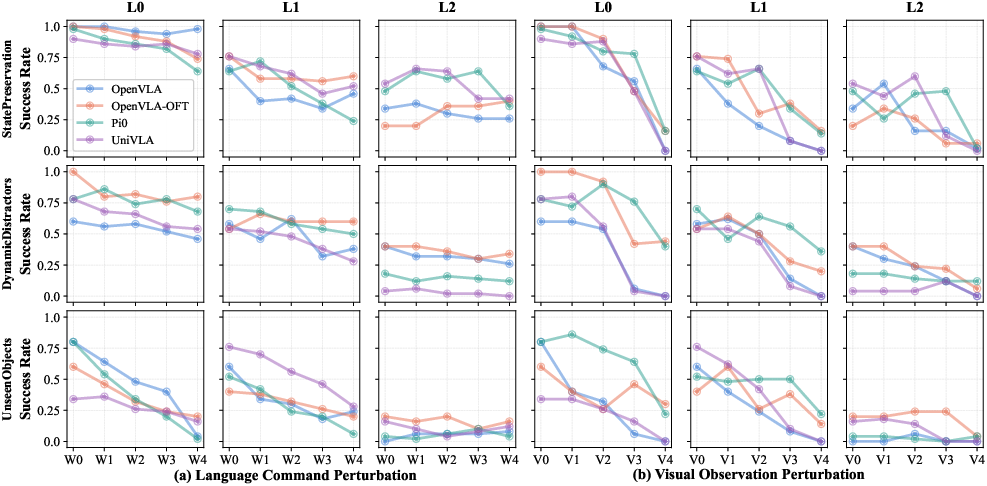
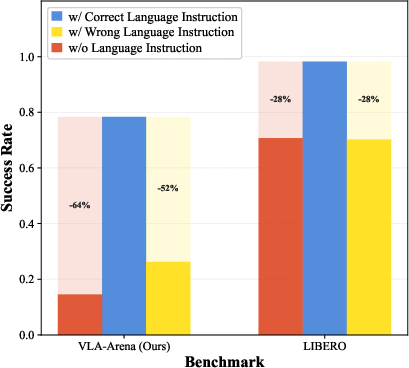
- Language changes hurt less than visual changes:
- Swapping words with close meanings (W1–W4) usually doesn’t break models too much. But visual changes (V1–V4), like lighting shifts, color changes, different camera angles, or noise, cause bigger drops. In short, models are more sensitive to how things look than to how instructions are phrased.
- Safety vs. performance trade-off:
- No model was both highly successful and strongly safe. Some models hit goals but ignored safety rules (like colliding or spilling), while others were safer but less successful. This is a big warning for real-world robots.
- Trouble with long, multi-step tasks:
- Many models struggle to combine learned skills to complete longer workflows. They can do basic actions but have difficulty chaining them reliably when the sequence gets complex.
These results highlight gaps in current robot learning: we need models that truly generalize, handle visual variation better, respect safety, and can plan longer sequences.
Why is this research useful?
- It provides a fair, transparent way to measure VLA models across safety, distractions, generalization, and long-horizon skills.
- The structured difficulty levels and axes (L/W/V) make it clear where and when models start to fail, helping researchers target weaknesses.
- The open-source framework, datasets, tools, and leaderboard make it easier for the community to build, compare, and improve models consistently.
- The safety dimension is especially important for real-world robots—before deploying robots around people or fragile objects, we need to know they can follow safety rules.
- By exposing common failure modes (memorization bias, visual fragility, weak skill composition), VLA-Arena points the way to better training, architectures, and evaluation strategies.
In short, VLA-Arena is like a well-designed obstacle course and lab test for robot models, showing not just whether they succeed, but how they can become safer, smarter, and more reliable in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed at guiding future research:
- Real-world validation under safety constraints is absent: results are entirely in simulation; no evidence of sim-to-real transfer for Safety (e.g., HazardAvoidance, DynamicObstacles), trajectory safety, or collision avoidance on physical robots.
- Scope limited to a single embodiment and sensing setup: no evaluation across different robot kinematics, grippers, workspace geometries, or multi-sensor configurations (e.g., depth, stereo, tactile, force/torque), hindering conclusions on cross-embodiment generalization.
- Language perturbation design (W0–W4) focuses on WordNet single-hop substitutions and ignores richer linguistic phenomena (negation, coreference, ellipsis, multi-sentence instructions, temporal connectives, conditionals, quantifiers, referential ambiguity), leaving grounded language understanding under realistic instructions untested.
- No cross-lingual robustness assessment: instructions are English-only; it is unknown how VLAs perform with multilingual commands or code-switching.
- Visual perturbations (V0–V4) exclude common real-world degradations such as occlusions, motion blur, lens distortion, shadows/specularities, extreme low-light, rolling shutter artifacts, or depth sensor noise, limiting conclusions about perceptual robustness.
- Perturbation calibration and comparability are not established: the difficulty increments across W and V levels are heuristic; there is no human or baseline-based calibration to ensure levels are comparable (e.g., equal “distance” in difficulty across axes or suites).
- Safety metric “cumulative cost (CC)” is insufficiently specified: units, aggregation, normalization across tasks/suites, and mapping to real-world risk are unclear, making cross-task and cross-model CC comparisons potentially misleading.
- Failure analysis is coarse: evaluation is mostly success rate (SR) and CC; there is no standardized taxonomy of failure modes (e.g., perception vs language vs planning), nor per-step diagnostics (e.g., where plans break, which subskills fail) to guide targeted improvements.
- Long-horizon evaluation lacks measures of planning quality: no metrics for plan optimality, subgoal correctness, temporal consistency, memory use, or recovery from errors; SR alone may hide brittleness in multi-step composition.
- CBDDL’s expressivity and correctness are not validated: it is unclear how fully CBDDL covers dynamic, stochastic, or partial-observability constraints (e.g., human-in-the-loop hazards) and whether constraint checking is sound and complete.
- Unclear simulator fidelity for physical phenomena: tasks like StatePreservation suggest liquid handling, but there is no mention of fluid simulation, deformables, compliance, or frictional variability—raising uncertainty about generalization to physically complex real-world interactions.
- Dataset composition and bias not analyzed: VLA-Arena-S/M/L datasets are introduced but lack detailed coverage statistics (object categories, assets, textures, scene diversity), bias assessments, and licensing considerations that could affect generalization.
- No scaling-law analysis: the impact of dataset size (S/M/L), training budget, or augmentation on extrapolation and robustness is not measured, leaving open how performance scales with data and compute.
- Fine-tuning only on L0 may conflate memorization with generalization: alternative training regimes (e.g., curriculum across L0–L1, mixed-perturbation training, RL vs supervised) are not explored, making the “memorization vs generalization” claim under-specified.
- Robustness asymmetry (language vs vision) is reported but not explained: there are no ablations isolating architectural choices, attention mechanisms, pretraining corpora, or augmentations to identify causes and remedies for weak visual robustness.
- Distractor tasks do not model adversarial or agent-reactive distractors: dynamic distractors follow fixed trajectories; scenarios where distractors occlude targets adaptively or causally respond to the agent’s motion remain unexplored.
- No standardized timing and control protocol: action frequencies, observation latencies, and controller loops are not specified, impeding reproducibility and making dynamic obstacle/distractor comparisons ambiguous.
- Leaderboard statistical rigor is unclear: there are no confidence intervals, multiple seeds, or significance testing across models; run-to-run variance and sensitivity to initialization or environment stochasticity remain unknown.
- Partial-credit criteria are missing: tasks with multiple subgoals or workflows provide only binary SR; finer-grained scoring (e.g., percentage of subgoals achieved, trajectory smoothness, contact safety) could reveal progress not captured by SR.
- Cross-scene and cross-simulator portability untested: it is unknown whether policies trained/evaluated in VLA-Arena generalize to other simulators (e.g., RLBench, ManiSkill) or to different scene generators without retraining.
- Object generalization insufficiently probed: UnseenObjects focuses on novel instances and new categories via 3D assets; it remains open whether models generalize to semantically novel affordances (e.g., atypical handles, deformable items) and out-of-category functions.
- Command grounding to safety constraints is underexplored: models are not tested on instructions that explicitly encode constraints (e.g., “don’t move the mug near the candle”) vs implicit hazard awareness, leaving the link between language and safety behaviors unresolved.
- Human factors not evaluated: instruction ambiguity, preference alignment, and user-in-the-loop correction are absent, yet critical for real deployments with safety-sensitive tasks.
- Limited task diversity: tasks are primarily tabletop manipulation; mobile manipulation, navigation, multi-room planning, and multi-agent interaction are not addressed, constraining generalization claims.
- Action representation coverage is narrow: only two paradigms (autoregressive and continuous) are compared; hybrid approaches (e.g., hierarchical discrete-continuous, model-predictive control, closed-loop RL with learned dynamics) are not benchmarked.
- Recovery and resilience remain open: there is no evaluation of error detection, re-planning after failure, or robustness to mid-episode perturbations (e.g., target moved after plan initiation).
- Ethical and safety certification pathways are not discussed: how CC or other safety metrics translate into deployment-ready thresholds or certifications is unclear, leaving practical adoption unanswered.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the VLA-Arena framework, datasets, and findings.
- Model selection and readiness gating for robot deployments (Sector: robotics, logistics, manufacturing, healthcare)
- Use VLA-Arena’s 170 tasks and four dimensions (Safety, Distractor, Extrapolation, Long Horizon) to benchmark candidate VLA controllers before piloting on real hardware.
- Workflow/product: “VLA Readiness Report” with success rate (SR) and cumulative cost (CC) thresholds per L0–L2 task; procurement checklists keyed to minimal SR/CC in Safety suites.
- Assumptions/dependencies: Sim-to-real gap must be acknowledged; CC must be mapped to real risk tolerances; coverage of domain-specific hazards may need custom scenes.
- Safety QA and regression testing in CI/CD (Sector: robotics software/MLOps)
- Integrate CBDDL-defined Safety tasks (StaticObstacles, HazardAvoidance, StatePreservation, DynamicObstacles) into continuous integration to prevent safety regressions.
- Workflow/product: “Safety Gate” pipeline that blocks releases when CC exceeds a set threshold under L1/L2 and V1–V3 perturbations.
- Assumptions/dependencies: Simulator determinism and seed control; agreed internal CC limits; sufficient compute to run nightly test matrices.
- Instruction robustness “fuzzing” and data augmentation (Sector: software, robotics)
- Use the WordNet-based slot substitution (W0–W4) to automatically fuzz user commands and expand training data for instruction following.
- Workflow/product: “Language Perturbation Fuzzer” that auto-generates paraphrases for training and pre-deployment validation.
- Assumptions/dependencies: WordNet coverage in the target language (non-English requires lexical resources); domain-specific terminology may need custom synonym lists.
- Visual robustness testing and augmentation (Sector: robotics, perception)
- Apply V0–V4 visual perturbation pipeline (lighting, color, viewpoint, noise) to assess perception sensitivity and calibrate augmentations for training.
- Workflow/product: “Camera Stress Test Suite” and “Augmentation Tuner” to harden models against facility-specific lighting and sensor noise.
- Assumptions/dependencies: Photorealism and calibration of the simulator; representativeness of perturbations vs on-site camera stacks.
- Fine-tuning with VLA-Arena-S/M/L and curriculum validation (Sector: robotics R&D)
- Use the provided datasets to fine-tune models on L0, then validate generalization on L1–L2 across suites to avoid overfitting/memorization.
- Workflow/product: “Generalization Audit” that quantifies the memorization vs generalization gap per suite.
- Assumptions/dependencies: Compute budget; model compatibility with datasets; consistent evaluation protocol.
- Risk-aware deployment dashboards (Sector: operations, product management)
- Present SR/CC across the three axes (task structure, language, visual) to inform go/no-go decisions and site rollout plans.
- Workflow/product: “Capability Frontier Dashboard” for executives and safety officers.
- Assumptions/dependencies: Agreement on pass/fail thresholds; translation of CC to site-specific safety SLAs.
- Task and hazard authoring with CBDDL (Sector: enterprise robotics, integrators)
- Encode facility- or hospital-specific procedures and constraints (e.g., “avoid sterile zones,” “preserve container contents”) as shareable, testable tasks.
- Workflow/product: “CBDDL-to-Sim Compiler” that turns SOPs into standardized, version-controlled test scenes.
- Assumptions/dependencies: Authoring expertise; coverage of dynamic objects and constraints; ongoing maintenance of scene assets.
- Academic reproducibility and teaching labs (Sector: academia, education)
- Adopt VLA-Arena for coursework, ablations along W/V/L axes, and reproducible benchmarks for new architectures or training strategies.
- Workflow/product: Course labs, standardized experiment templates, and open leaderboards.
- Assumptions/dependencies: Hardware access for optional sim-to-real validation; alignment with IRB/ethics when applicable.
- Leaderboard-driven open evaluations (Sector: research community, vendors)
- Submit models to the public leaderboard for transparent comparison and iterative improvement.
- Workflow/product: Vendor datasheets that include VLA-Arena metrics by suite and difficulty.
- Assumptions/dependencies: Willingness to publish results; consistent runtime configurations.
- Policy and procurement checklists (Sector: public sector, enterprise procurement)
- Reference VLA-Arena thresholds in RFPs (e.g., “≥0.8 SR on L1 HazardAvoidance at V2; CC ≤ X”).
- Workflow/product: “Conformance Checklist” mapping suites to operational requirements.
- Assumptions/dependencies: Stakeholder agreement on metrics; third-party verification options.
- Insurance and warranty support (Sector: finance/insurtech)
- Use CC/SR distributions across Safety suites as quantitative signals for underwriting and warranty terms.
- Workflow/product: “Robotics Risk Score” instrumented with VLA-Arena results.
- Assumptions/dependencies: Actuarial acceptance; correlation studies between sim metrics and real incident rates.
- Consumer robot developer testing (Sector: consumer robotics)
- Validate household assistants against Distractor and Extrapolation suites with home-like clutter and novel objects.
- Workflow/product: “Home Scenario Pack” for pre-release QA of instruction following and visual robustness.
- Assumptions/dependencies: Realism and coverage of consumer environments; mapping of tasks to device capabilities.
Long-Term Applications
These use cases require additional research, standardization, or ecosystem development.
- Pre-market safety certification standard anchored in CBDDL (Sector: policy, standards, robotics)
- Establish a UL/ISO-style certification where models must pass codified Safety suites at defined SR/CC thresholds before public deployment.
- Tools/products: Accredited test labs; certification kits; public registry of certified models.
- Assumptions/dependencies: Consensus on thresholds; legal/regulatory adoption; periodic standard updates.
- Evaluation-as-a-service and digital-twin integration (Sector: cloud platforms, industrial software)
- Offer “VLA Test Cloud” where vendors upload policies for large-scale, scenario-rich evaluation integrated with facility digital twins.
- Tools/products: API for batch evaluations; report automation; “twinning” of real camera intrinsics and obstacle dynamics.
- Assumptions/dependencies: Secure model handling; scalable simulation; high-fidelity domain models.
- Runtime constraint-aware safety monitors (Sector: robotics controls)
- Train monitors from CBDDL constraints to filter or veto unsafe actions at run time, complementing learned policies.
- Tools/products: “Safety Shield” middleware; learned constraint checkers; risk-aware planners.
- Assumptions/dependencies: Low-latency inference; verifiable coverage of constraints; formal verification integration.
- Curriculum-driven, compositional VLA training (Sector: AI/robotics research)
- Architectures and training regimens that explicitly target extrapolation and long-horizon skill composition to reduce memorization.
- Tools/products: Hierarchical planners, skill libraries, memory modules; compositional evaluation harnesses.
- Assumptions/dependencies: New datasets and objectives; scaling laws for composition; robust credit assignment.
- Sector-specific benchmark packs (hospitals, warehouses, retail, labs) (Sector: healthcare, logistics, retail)
- Tailor suites to regulated domains (e.g., sterile fields, medication handling, dynamic human obstacles).
- Tools/products: “Healthcare VLA Pack,” “Warehouse VLA Pack,” with standardized assets and CBDDL tasks.
- Assumptions/dependencies: Domain expert input; compliance overlays (HIPAA, OSHA); human-in-the-loop protocols.
- Multilingual instruction robustness at scale (Sector: global robotics, software)
- Extend W0–W4 language perturbations to many languages and dialects, capturing morphology and polysemy beyond English WordNet.
- Tools/products: Cross-lingual synonym resources; semantic-slot transfer; locale-specific instruction evaluators.
- Assumptions/dependencies: Quality lexical resources; cultural/operational nuance; multilingual grounding.
- Automated visual domain adaptation pipelines (Sector: perception systems)
- Use V-level diagnostics to auto-select augmentations, sensors, and camera placements that optimize robustness for each site.
- Tools/products: “Perception Calibrator” that recommends hardware and training policies given VLA-Arena diagnostics.
- Assumptions/dependencies: Reliable mapping from sim stress tests to real performance; site survey tooling.
- Insurance, liability, and warranty frameworks tied to standardized metrics (Sector: finance, legal)
- Create clauses and premiums keyed to certified SR/CC bands, with continuous monitoring for policy compliance.
- Tools/products: Real-time conformance reports; usage-based insurance for robots (UBIR).
- Assumptions/dependencies: Regulatory approval; incident reporting standards; secure telemetry.
- Consumer-grade scenario authoring and sharing (Sector: consumer robotics, prosumer tools)
- Enable end-users to author home scenes and constraints in simplified CBDDL and share community-validated packs.
- Tools/products: Visual authoring UIs; crowd-sourced scenario libraries; “home safety presets.”
- Assumptions/dependencies: Usability; content moderation; device interoperability.
- Education and workforce skilling at national scale (Sector: education, workforce development)
- Standardize VLA-Arena-based curricula for safe robot operation and evaluation in vocational programs and universities.
- Tools/products: MOOC modules; lab kits; educator guides aligned with emerging standards.
- Assumptions/dependencies: Funding; alignment with industry needs; lab infrastructure.
Cross-cutting insights to inform all applications
- Address visual vulnerability first: Findings show stronger fragility to visual perturbations than to language substitutions; prioritize camera robustness and augmentation strategies in both QA and training.
- Treat safety as a first-class metric: The observed safety-performance trade-off argues for explicit safety objectives and runtime gating, not just SR optimization.
- Design for generalization, not memorization: Train on L0 but measure on L1–L2; prefer curricula and architectures that encourage compositionality and extrapolation.
These applications build directly on the paper’s contributions: a structured, orthogonal difficulty design; CBDDL with formal safety constraints; principled language and visual perturbations; open datasets and toolchain; and empirical findings that pinpoint where current VLAs fail.
Glossary
- Affordances: The actionable properties of an object that suggest how it can be manipulated or used. "This suite assesses the understanding of object affordances and contact safety by requiring it to grasp dangerous implements by their handles while avoiding hazardous parts."
- Asymmetric robustness: A property where a model’s resilience differs across modalities or conditions (e.g., stronger to language than vision). "Our extensive evaluation of state-of-the-art VLAs reveals several critical limitations, including a strong tendency toward memorization over generalization, asymmetric robustness, a lack of consideration for safety constraints, and an inability to compose learned skills for long-horizon tasks."
- Autoregressive: An architectural paradigm that generates outputs sequentially, conditioning each step on previous ones. "Conducting an extensive study on VLA-Arena with leading models from the two dominant architectural paradigms: autoregressive and continuous action generation"
- BDDL: Behavior Domain Definition Language, a formalism for specifying tasks and environments in simulation. "We use constrained BDDL (CBDDL), our extension of BDDL"
- Capability frontiers: The current limits of a model’s abilities across defined evaluation axes. "enabling a precise measurement of model capability frontiers."
- CBDDL (Constrained BDDL): An extension of BDDL that adds dynamic objects and formal safety constraints to define tasks precisely. "The entire benchmark is formally defined in our constrained behavior domain definition language (CBDDL) to precisely identify the frontiers of model performance."
- Compositional reasoning: The ability to solve tasks by combining known skills or concepts into novel workflows. "This suite evaluates the ability of compositional reasoning by requiring models to execute novel workflows composed of known skills."
- Compositional understanding: Grasping how known elements (objects, relations, skills) can be recombined to handle new scenarios. "Success demands compositional understanding, long-horizon planning, and applying learned skills to unfamiliar contexts."
- Continuous action generation: Producing control outputs as continuous values rather than discrete tokens. "Conducting an extensive study on VLA-Arena with leading models from the two dominant architectural paradigms: autoregressive and continuous action generation"
- Cross-embodiment generalization: The ability to transfer learned policies across different robot bodies. "This has led to an expanding range of capabilities, including cross-embodiment generalization"
- Cross-scene generalization: The ability to transfer skills across different environments or scene configurations. "This has led to an expanding range of capabilities, including cross-embodiment generalization \cite{bu2025learning, chen2025villa0x0}, cross-scene generalization \cite{hu2024flare}, dexterous manipulation"
- Cumulative cost (CC): A metric aggregating safety-related penalties accrued during task execution. "Safety tasks report both cumulative cost (CC, above each sparkline) and success rate (SR, below each sparkline)"
- Cumulative hierarchy of visual difficulty: A staged scheme where each visual perturbation level adds to the previous, creating progressively harder conditions. "A Cumulative Hierarchy of Visual Difficulty."
- Decoupled analysis: Evaluating different factors (e.g., language vs. vision) independently to isolate failure sources. "introduce graded perturbations to any task for decoupled analysis."
- Distribution shifts: Significant changes between training and testing distributions that challenge generalization. "L2 tasks represent significant distribution shifts requiring robust adaptation and complex reasoning."
- Dynamic risk assessment: The capability to anticipate and avoid moving hazards during task execution. "testing the model's capacity for dynamic risk assessment."
- End-to-end toolchain: An integrated pipeline covering data, training, and evaluation without manual gaps. "we provide the complete VLA-Arena framework, including an end-to-end toolchain from task definition to automated evaluation"
- Extrapolation: Generalizing to tasks with structures or conditions more complex than those seen in training. "For Task Structure, VLA-Arena's 170 tasks are grouped into four dimensions: Safety, Distractor, Extrapolation, and Long Horizon."
- Extrinsic properties: Camera parameters (position/orientation) that define viewpoint relative to the world. "This level introduces variations in the camera's extrinsic properties by randomizing camera's positions within a defined volume around the workspace."
- Fine-tuning: Post-training adaptation of models on a specific dataset or task subset. "Each task is designed with three difficulty levels (L0-L2), with fine-tuning performed exclusively on L0 to assess general capability."
- Foundation models: Large pre-trained models with broad capabilities that can be adapted to many tasks. "benchmarks such as LIBERO and VLABench were designed to better align with the capabilities of foundation models"
- Gaussian noise: Random noise drawn from a normal distribution added to images to simulate sensor imperfections. "The final level tests the model's resilience to imperfect sensor data by injecting Gaussian noise directly into the image observations."
- Hypernyms: Words with broader meaning that encompass more specific terms. "This typically includes direct synonyms (e.g., put and place) or immediate hypernyms and hyponyms"
- Hyponyms: Words with more specific meaning within a broader category. "This typically includes direct synonyms (e.g., put and place) or immediate hypernyms and hyponyms"
- Leaderboard: A public ranking of model performance on a benchmark. "Our benchmark, data, models, and leaderboard are available at \url{https://vla-arena.github.io}."
- Long-horizon planning: Planning and executing sequences of many interdependent steps. "Success demands compositional understanding, long-horizon planning, and applying learned skills to unfamiliar contexts."
- Orthogonal axes: Independent evaluation dimensions whose effects can be isolated and combined. "quantify difficulty across three orthogonal axes"
- Perturbations: Systematic modifications to inputs (language or vision) to test robustness. "language (W0-W4) and visual (V0-V4) perturbations can be applied to any task to enable a decoupled analysis of robustness."
- PrepositionCombinations: A task suite testing generalization to novel object-preposition pairings. "PrepositionCombinations: This suite evaluates the compositional understanding of spatial relationships by testing novel pairings of objects and prepositions not seen during training."
- Risk-aware motion planning: Planning trajectories that fulfill task goals while respecting safety constraints. "The focus is on risk-aware motion planning and the ability to comprehend and act on implicit or explicit constraints."
- Safety constraints: Rules that restrict actions to prevent harm or damage during task execution. "which improves upon BDDL by incorporating two key features: the ability to define dynamic objects and a formal syntax for specifying safety constraints."
- Semantic grounding: Linking language expressions to their intended meanings and actions in context. "Language Command: Semantic Grounding"
- Semantic slots: Key positions in an instruction where words can be substituted while preserving structure. "The linguistic difficulty level is then defined simply as the number of semantic slots in which the original word has been substituted"
- Semantically informed WordNet-based replacements: Word substitutions guided by lexical relations from WordNet to maintain meaning. "semantically informed WordNet-based replacements,"
- Synsets: Sets of cognitive synonyms in WordNet representing a single concept. "we consider words to be viable substitutes if their synsets are connected by a shortest path length of 1 in the word graph."
- Success rate (SR): The proportion of tasks successfully completed by a model. "Safety tasks report both cumulative cost (CC, above each sparkline) and success rate (SR, below each sparkline)"
- Vision-Language-Action (VLA): Models that integrate perception, language, and control to perform robotic tasks. "Vision-Language-Action models (VLAs) aim to build generalist robot control policies"
- VLA-Arena: A comprehensive open-source benchmark and framework for evaluating VLA models. "we introduce a comprehensive benchmark called VLA-Arena."
- WordNet: A lexical database organizing English words into synsets and semantic relations. "WordNet-based replacements"
- Zero-shot generalization: Successfully handling tasks or objects not encountered during training without additional learning. "This suite assesses the ability of zero-shot generalization."
Collections
Sign up for free to add this paper to one or more collections.