CODA: Rewriting Transformer Blocks as GEMM-Epilogue Programs
Abstract: Transformer training systems are built around dense linear algebra, yet a nontrivial fraction of end-to-end time is spent on surrounding memory-bound operators. Normalization, activations, residual updates, reductions, and related computations repeatedly move large intermediate tensors through global memory while performing little arithmetic, making data movement an increasingly important bottleneck in otherwise highly optimized training stacks. We introduce CODA, a GPU kernel abstraction that expresses these computations as GEMM-plus-epilogue programs. CODA is based on the observation that many Transformer operators exposed as separate framework kernels can be algebraically reparameterized to execute while a GEMM output tile remains on chip, before it is written to memory. The abstraction fixes the GEMM mainloop and exposes a small set of composable epilogue primitives for scaling, reductions, pairwise transformations, and accumulation. This constrained interface preserves the performance structure of expert-written GEMMs while remaining expressive enough to cover nearly all non-attention computation in the forward and backward pass of a standard Transformer block. Across representative Transformer workloads, both human- and LLM-authored CODA kernels achieve high performance, suggesting that GEMM-plus-epilogue programming offers a practical path toward combining framework-level productivity with hardware-level efficiency.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about speeding up the training of LLMs by changing how certain parts of the model are computed on a GPU. The authors introduce a way called CODA to “bundle” many small, slow steps together so they happen right next to a big, fast step, cutting down on time wasted moving data around.
In short: Instead of doing a big matrix calculation, sending the result out to memory, then doing several small follow-up steps, CODA does the small steps immediately while the data is still “hot” and nearby. That saves time and makes training faster.
What questions did the researchers ask?
- Can we turn many of the “extra” Transformer steps (like normalization, activations, and residual adds) into tiny programs that run right after a big matrix multiply, before writing results to memory?
- Can this be done in a structured, reusable way that keeps performance high but is still easy to program?
- Will this approach speed up real Transformer workloads in both the forward pass (normal computation) and the backward pass (gradient computation), and can AI models help write these kernels?
How did they do it?
The big idea, in everyday terms
- Think of GPU training like a busy kitchen:
- The “big dish” is a giant matrix multiplication (called GEMM), which GPUs cook extremely fast.
- Around it are many small tasks (like sprinkling salt, mixing in sauce, measuring averages) that don’t take much compute but waste time because you keep carrying the dish back and forth to the pantry (global memory).
- CODA says: do those small tasks right at the stove, before you carry the dish away. In GPU terms, run these operations in the GEMM’s “epilogue” (the short section that runs after the main matrix multiply) while the data is still on the chip.
What is GEMM and what is an epilogue?
- GEMM stands for General Matrix Multiply. It’s the core math step in many neural networks and is extremely optimized on GPUs.
- The epilogue is the “cleanup/finishing” step that runs after the main multiply. CODA turns the epilogue into a smart, programmable place to do extra work efficiently.
The building blocks CODA provides
To keep things fast and simple, CODA offers a small set of “lego pieces” that epilogues can use. These cover most of the extra steps in Transformers without needing heavy, custom code:
- Elementwise and pairwise maps: simple per-value tweaks (like activations) or pair-based tweaks (like rotating pairs of features for RoPE or combining gate/value in SwiGLU).
- Vector loads/stores: read or write one row or column of values and broadcast them over the tile (good for weights like RMSNorm’s gamma).
- Tile loads/stores: read or write a small tile (chunk) of a matrix (e.g., a piece of the residual stream).
- Tile reductions: compute partial sums or maxima over a row or column inside this tile; a tiny follow-up step later combines these partials from all tiles.
- Stateful transforms: keep small running stats in the epilogue (like max and sum of exponentials for stable softmax/loss).
These are intentionally limited so they stay fast and predictable on GPUs.
Examples inside a Transformer
- Residual + RMSNorm between GEMMs:
- Normally: GEMM → write to memory → add residual → RMSNorm → write → next GEMM.
- With CODA: Do residual add and part of RMSNorm right in the epilogue of the first GEMM; collect small “partial statistics” per tile; run a tiny reduction to finish the RMS value; apply the final scale in the epilogue of the next GEMM. This avoids extra full-tensor memory trips.
- Pairwise activations (RoPE, SwiGLU):
- These work on feature pairs. CODA arranges the data so each thread already holds adjacent pairs and applies the activation right there, avoiding writing big intermediates to memory.
- Cross-entropy loss:
- Compute logits with a GEMM, and in the epilogue gather the target logit and accumulate stable log-sum-exp stats per tile. A small follow-up reduction finishes it, cutting out a separate, memory-heavy softmax pass.
What about the backward pass?
The same idea applies in reverse. The math of gradients lets you fuse the “gradient versions” of those small steps into GEMM epilogues too. The only wrinkle is RMSNorm, which needs some reductions, but CODA handles them by emitting tile-level partials and combining them with lightweight reductions—still avoiding big memory trips.
Letting an AI help write kernels
Because CODA limits the epilogue to a small, well-structured set of operations, the authors could ask an AI coding model to assemble these pieces rather than write complex GPU code from scratch. Both human-written and AI-written CODA kernels ran fast.
What did they find?
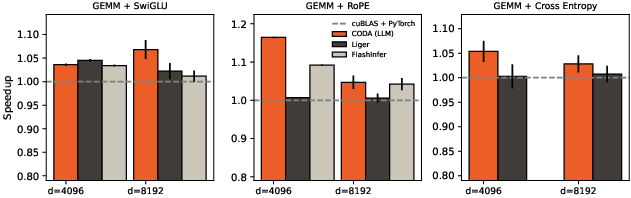
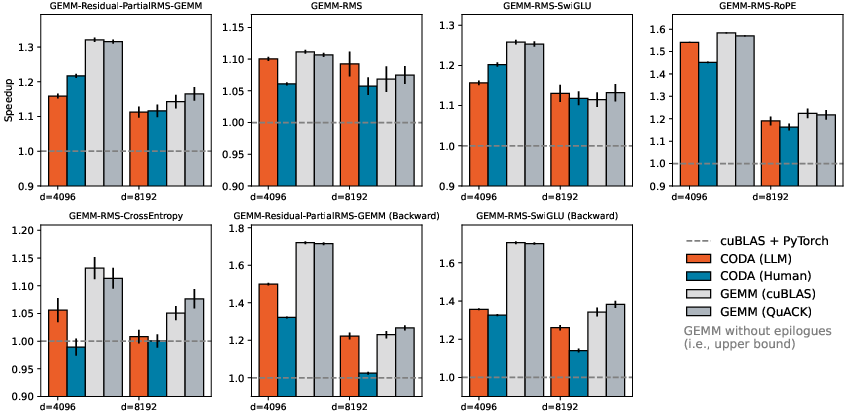
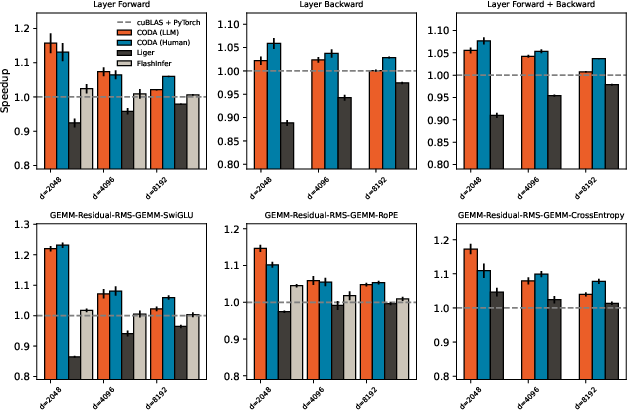
- Speedups: Across many common Transformer tasks (like RoPE, SwiGLU, cross-entropy, and RMSNorm “sandwiched” between GEMMs), CODA’s GEMM-plus-epilogue kernels were much faster than standard implementations that rely on separate kernels and memory round-trips.
- Broad coverage: With a little algebra (rearranging steps), CODA’s epilogues could cover most of the non-attention computation in both forward and backward passes of a standard Transformer layer.
- Accuracy: Delaying certain scales (like in RMSNorm) to the next epilogue did not harm results; in some cases, careful GEMM/epilogue design even reduced numerical error.
- Programmability: The small, reusable epilogue primitives made it practical for both humans and an LLM to build high-performance kernels without diving into low-level, hand-tuned CUDA.
Why this matters: The main cost in these steps is moving data around (memory bandwidth), not the math. CODA reduces data movement, so the whole training step becomes faster.
Why does this matter?
- Faster training: Less waiting on memory means models train quicker, which saves time and money.
- Better use of new hardware: As GPUs get even faster at matrix math (FP8/FP4), the “memory problem” gets worse. CODA directly attacks that bottleneck.
- Easier development: You get the speed of specialized kernels but keep a cleaner, more programmable structure—helpful for research teams and for automating performance work with AI helpers.
- Lower energy: Doing less data movement can also save power, which is important at scale.
Limits and what’s next
- Today, CODA focuses on a common Transformer design and on single-GPU kernels. Extending it to other model types and multi-GPU training is future work.
- Because CODA “reshuffles” where work happens (for speed), it can blur the clean boundaries between modules in high-level frameworks, making integration a bit trickier.
- Still, the approach shows a promising middle ground: keep programming simple at the framework level, but run the key steps where the GPU can do them most efficiently.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open problems that remain unresolved and could guide future work:
- Coverage beyond non-attention ops: No reparameterization for attention (softmax, masking, dropout, KV-cache updates). Determine which attention sub-ops can be made tile-local (e.g., masking, causal shifts, scaling) and what auxiliary reductions/state are required to safely move softmax/LSE into epilogues without extra global passes.
- Embeddings and tokenization: The approach excludes embedding lookups/updates and tokenization-related ops. Explore whether embedding gradient accumulation (and optimizer-friendly statistics) can be epilogue-fused or reduced via tile-partials to cut memory traffic.
- Distributed training integration: The method targets single-GPU kernels. Study how CODA’s auxiliary reductions interact with data/tensor/pipeline/sequence parallelism and collectives (e.g., reduce-scatter of partial norms), and design scheduling that preserves overlap with communication.
- End-to-end training impact: Results are kernel/block-level; no full training throughput (tokens/sec), energy, or time-to-train improvements on real models. Provide end-to-end measurements on multi-node runs to validate wall-clock benefits.
- Automatic graph-to-epilogue compilation: Reparameterizations are manual. Develop a compiler pass that recognizes eligible subgraphs, proves/ensures algebraic equivalence (forward and backward), and emits CODA primitives automatically with correctness guarantees.
- Backward-pass generality: Theorem assumes tile-local epilogues. Characterize which common training ops break tile locality (e.g., dropout with RNG state, batch norms, sequence-global ops) and propose epilogue-compatible formulations or staged reductions.
- RMSNorm backward reductions: The row-wise statistic is moved to neighboring GEMM boundaries. Quantify numerical and performance effects across model scales and sequence lengths, and provide formal conditions under which this relocation is always safe and stable.
- Numerical stability in low precision: Evaluate FP8/FP4 accumulation formats and scaling strategies for deferred normalization and stateful LSE in epilogues; characterize overflow/underflow risks and propose stable mixed-precision recipes.
- Cross-entropy backward fusion: Forward uses cut-style epilogue reductions but still materializes logits for backward simplicity. Investigate a fully fused forward+backward cross-entropy variant (including label smoothing, class weighting, ignore_index) with correctness and stability.
- Attention to layout constraints: Pairwise activations rely on arranging adjacent feature lanes. Quantify performance vs. coalescing trade-offs across layouts (channels-last/first), QKV packing, and head-major/minor orderings; provide layout transforms with bounded overhead.
- Auxiliary reduction overheads: The paper asserts “lightweight” reductions but lacks a sensitivity analysis. Measure costs under many tiles, long sequences, and large vocabularies; study stream/graph scheduling to avoid serialization and kernel launch penalties.
- Generalization to architectural variants: Extend reparameterizations to LayerNorm (pre/post), ScaleNorm, AdaNorm, GLU variants, gated-attention, residual branch reorderings, and non-Transformer models (MoE, diffusion U-Nets, CNN backbones). Identify what cannot be made tile-local.
- Mixture-of-Experts (MoE): Expert routing introduces gathers/scatters and irregular communication. Determine whether routing, token dispatch, and expert FFN compute can be reframed as epilogues with grouped/gather TMEM patterns or require new primitives.
- Optimizer/regularizer fusion: The method focuses on forward/backward. Explore epilogue-side accumulation of optimizer statistics (e.g., AdamW moments), weight decay, gradient clipping, and norm computation to reduce extra passes.
- Dynamic shapes and ragged batches: CODA assumes structured shapes. Specify how to handle variable sequence lengths, padding/masking, and shape polymorphism without recompilation explosions; add runtime shape guards and caching strategies.
- Autotuning for epilogues: The GEMM mainloop is fixed; epilogue complexity varies. Build autotuners/cost models that co-optimize tile sizes, TMA patterns, and epilogue compute to keep pipelines balanced across hardware generations.
- Hardware portability: Implementation targets Hopper/Blackwell with TMEM/TMA. Evaluate on A100, AMD MI300, and TPUs; specify missing hardware capabilities, alternative pathways (e.g., async cp), and performance portability gaps.
- Compiler/runtime integration: Provide a clean pathway for PyTorch/JAX to insert CODA kernels without obscuring module semantics (e.g., preserving hooks, gradient checkpointing, activation rematerialization, and debuggability with profilers).
- Quantization-aware support: Extend primitives to fuse dequant/quant (per-tensor/channel/group scales, zero-points, outlier handling), and verify training stability with W8A8/W4A8 regimes; quantify memory and accuracy trade-offs.
- Memory footprint analysis: While memory traffic is reduced, intermediates (e.g., pre-broadcasted RoPE tables) may increase input bandwidth. Provide a byte-traffic and peak-memory accounting per kernel vs. baselines, including L2/L1/shared utilization and cache behavior.
- RNG- and mask-dependent ops: Characterize integrating dropout, attention masks, and stochastic depth into epilogues with deterministic RNG handling, seed management, and reproducibility across distributed runs.
- Verification and testing of LLM-authored kernels: Establish formal spec tests, property-based fuzzing, and gradient checks across edge-case shapes (non-multiples of tiles), ensuring memory safety and determinism; report failure rates and auditing procedures.
- Robust numerical validation: Beyond layer-level BF16 vs. FP32 spot checks, demonstrate training/convergence parity (loss curves, final accuracy) across multiple models/datasets/seeds; provide ablations isolating each reparameterization.
- API stability and ergonomics: CuTeDSL is relatively new. Define a stable API for CODA primitives, migration paths to/beyond CUTLASS EVT, and tooling (linting, tracing, profilers) to ease adoption and reduce maintenance burden.
- Interplay with other fusions: Clarify how CODA coexists with framework/Inductor/Triton fusions; provide heuristics to choose CODA vs. compiler fusion paths; prevent duplicated or conflicting fusions.
- Scheduling in the shadow of mainloops: Provide empirical evidence that epilogues consistently hide under mainloop pipelines across shapes and hardware; specify when epilogues become the bottleneck and how to throttle/split them.
- Coverage audit: The paper claims “nearly all non-attention computation.” Produce a complete operator taxonomy (forward/backward) mapping to CODA primitives and list any uncovered ops (e.g., bias-dropout-add, RMSNorm eps scheduling, residual scaling) with proposed extensions.
- Error-resilience and safety: Address risks of aggressive fusion (harder debugging, silent numerical drift). Propose guardrails: runtime assertions (NaN/Inf checks), configurable fallbacks, and differential testing against unfused references.
- Reuse of tile partials across steps: Investigate whether partial reductions/statistics can be cached across microbatches or gradient-accumulation steps to further reduce memory traffic without correctness loss.
Practical Applications
Immediate Applications
These items can be deployed now on NVIDIA GPUs (Hopper-class or better) where high-performance GEMM kernels and epilogue fusion are available.
- Faster and cheaper LLM pretraining and fine-tuning
- Sector: software, AI/ML platforms, cloud, energy
- What: Replace normalization/activation/residual “glue” ops around GEMMs with CODA-style GEMM-plus-epilogue kernels in training stacks (e.g., TorchTitan-style pipelines) to reduce memory traffic and kernel launches.
- Where in model: non-attention parts of Transformer blocks (e.g., output proj → residual → RMSNorm → next proj; MLP with SwiGLU; RoPE in QKV projections; cross-entropy loss).
- Tools/workflows: Integrate CODA kernels (CuTeDSL/CUTLASS) as PyTorch custom ops; drop-in library modules alongside Liger/FlashInfer; use torch.compile with custom backends where supported.
- Benefits: Higher GPU utilization, lower end-to-end step time, cloud cost savings, reduced power draw.
- Assumptions/dependencies: NVIDIA CUDA stack with fast GEMM mainloops (e.g., QuACK/CUTLASS), Hopper/Blackwell-style epilogue pipelines; attention kernels still separate; limited by tile-local epilogue expressivity and small auxiliary reductions.
- Lower-latency, higher-throughput LLM inference for non-attention layers
- Sector: software, inference serving (vLLM/SGLang/FlashInfer), consumer apps
- What: Fuse RoPE, residual updates, elementwise/pairwise activations, and RMSNorm scaling into projection GEMMs during token generation.
- Tools/products: “Non-attention” plugin pack for inference servers; CUDA extensions that register fused MLP and output projection ops.
- Benefits: Reduced per-token latency and jitter; better throughput per GPU; improved energy efficiency in production serving.
- Assumptions/dependencies: Most benefit realized when attention is already optimized (e.g., FlashAttention/FlashInfer); dynamic-shape handling and caching layouts must match server expectations.
- Faster cross-entropy loss in training
- Sector: software, AI/ML platforms
- What: Use GEMM-with-epilogue reductions (Cut Cross-Entropy–style) to compute indexed logits and log-sum-exp statistics while the logits are still on chip; finish with a lightweight auxiliary reduction.
- Benefits: Removes standalone softmax/loss passes over large vocabularies; reduces memory bandwidth.
- Assumptions/dependencies: Needs careful numerical stabilization (online LSE, max tracking); backward path integration requires logits materialization or equivalent bookkeeping.
- Energy and carbon footprint reduction for data centers
- Sector: policy, sustainability, cloud operations
- What: Apply CODA kernels to reduce memory traffic and power; quantify energy-per-token or energy-per-step improvements for procurement and reporting.
- Workflow: Include CODA-enabled runs in internal energy KPIs and carbon accounting dashboards.
- Assumptions/dependencies: Actual savings depend on model scale, GPU type, batch/seqlen, and power management; attention still dominates at some settings.
- Rapid kernel authoring with LLM assistance for ML systems teams
- Sector: software tooling, developer productivity
- What: Use CODA’s constrained epilogue primitives (vector/tile loads, pairwise maps, reductions, stateful transforms) to let engineers or LLMs compose new fused kernels without writing low-level CUDA from scratch.
- Products: Internal “epilogue composer” CLI/notebook that emits CuTeDSL kernels; CI with microbenchmarks.
- Assumptions/dependencies: CuTeDSL/CUTLASS familiarity; curated examples; guardrails for correctness and numerics (unit tests, reference checks).
- Academic prototyping of new Transformer variants
- Sector: academia
- What: Quickly test normalization changes (e.g., RMSNorm variants), alternative pairwise activations, or new loss epilogues by swapping CODA primitives.
- Benefits: Faster iteration with realistic performance; easier reproducibility of systems-level improvements.
- Assumptions/dependencies: Reforms must remain tile-local or rely on small auxiliary reductions; attention-side innovations still require specialized kernels.
- On-device inference on NVIDIA laptops/workstations
- Sector: consumer, enterprise IT
- What: Use fused MLP/normalization epilogues to shrink latency and power for local assistants and IDE copilots on RTX-class GPUs.
- Assumptions/dependencies: CUDA/NV driver availability; benefits scale with model size and memory bandwidth limits.
- Baseline upgrades for open-source kernel libraries
- Sector: open-source ecosystems
- What: Extend Liger Kernels/FlashInfer/vLLM with CODA-like fused non-attention ops and reparameterized RMSNorm pipelines (including backward).
- Assumptions/dependencies: API compatibility, layout agreements, dynamic-shape support; test coverage for edge cases (odd hidden sizes, vocab partitions).
Long-Term Applications
These require further research, scaling, portability work, or productization beyond a single-GPU CUDA context.
- Automatic graph-to-epilogue reparameterization in compilers
- Sector: software tooling, compilers
- What: Extend PyTorch Inductor, Triton, TVM, or Mirage-like systems to recognize GEMM–Residual–RMSNorm–GEMM and pairwise-activation patterns and automatically lower them to GEMM-plus-epilogue with auxiliary reductions.
- Products: “Epilogue-aware” optimization pass; cost model to decide fusion vs. materialization.
- Dependencies: Robust pattern matching across training+autograd graphs; correctness proofs/validators; dynamic shape handling.
- Portable epilogue IR and multi-backend support (NVIDIA, AMD, Intel)
- Sector: cross-vendor hardware/software
- What: Define a hardware-agnostic epilogue intermediate representation and per-backend codegen (CUDA, HIP/ROCm, oneAPI) to broaden adoption.
- Dependencies: Vendor support for fast tile-local epilogues and async copies; equivalent TMEM/TMA primitives or alternatives; different accumulator layouts.
- Distributed training and communication-aware fusion
- Sector: large-scale training systems
- What: Schedule epilogue compute to overlap with collective communication (e.g., gradient all-reduce, tensor parallel sharding) and pipeline tile reductions across nodes.
- Products: Epilogue–communication co-scheduling in DeepSpeed/DTensor frameworks; topology-aware autotuners.
- Dependencies: Stable NCCL/RCCL timelines, overlap-safe streams; partition-aware reductions; correctness under recomputation/checkpointing.
- Hardware–software co-design for epilogue-centric pipelines
- Sector: semiconductors, systems
- What: Influence GPU design to enlarge “epilogue budget” (e.g., TMEM bandwidth, on-chip scratch, epilogue arithmetic) and expose primitives amenable to CODA-style fusion.
- Dependencies: Vendor roadmaps (e.g., Blackwell TMEM), ISA support for pairwise transforms and reductions; compiler hooks.
- Generalization beyond Transformers
- Sector: healthcare (imaging), robotics (control nets), recommendation systems, vision
- What: Apply GEMM-plus-epilogue to UNets/diffusion, CNN bottlenecks, MoE routers, and large MLP recommenders where bandwith-bound ops surround matmuls.
- Dependencies: Ability to reparameterize layerwise ops as tile-local maps/reductions; validation on non-Transformer numerics.
- Robust FP8/FP4 end-to-end training with fused epilogues
- Sector: AI efficiency
- What: Combine aggressive low precision in mainloop with epilogue-side statistics (online LSE, normalization) and error compensation.
- Dependencies: Calibration, amax/scale management; mixed-precision autograd; numerical validation for stability across long runs.
- Verified, LLM-in-the-loop kernel synthesis
- Sector: software tooling, safety
- What: Integrate LLM-based epilogue authoring with formal/spec-based verification, differential testing, and auto-benchmarking to safely generate kernels at scale.
- Products: CI pipelines that synthesize, verify, and tune kernels per model/config.
- Dependencies: Test oracles, numerical tolerances, reproducibility controls.
- Runtime epilogue composition APIs in major frameworks
- Sector: software
- What: First-class framework APIs to declaratively compose epilogues (maps, pairwise ops, reductions) with automatic selection of kernel variants and layouts at runtime.
- Products: torch.nn “FusedEpilogue” modules; JAX custom calls with autotuned schedules.
- Dependencies: Backward graph plumbing for tile-partial reductions; caching for shape/stride variants.
- Privacy-preserving and edge AI deployments
- Sector: mobile/IoT, enterprise privacy
- What: With lower bandwidth and power needs, on-device models can run more private assistants, document analyzers, and copilots.
- Dependencies: GPU/NPUs with sufficient epilogue support; mobile-friendly backends (e.g., Vulkan/Metal equivalents of epilogue fusion).
- Policy and standards for energy-efficient AI training/serving
- Sector: policy, standards bodies
- What: Encourage reporting “energy per token/step” and adopt epilogue-fusion as a best-practice guideline in green-AI checklists and procurement.
- Dependencies: Accepted benchmarks (e.g., MLPerf extensions), third-party verification, vendor-neutral guidance.
- Autotuners and profilers that recommend epilogue fusions
- Sector: developer tools
- What: Build profilers that detect memory-bound operator chains around GEMMs and suggest or auto-apply CODA-style fusions, with predicted speed/energy benefits.
- Dependencies: Accurate performance models, integration with compilers, safe fallbacks.
- Training planners that exploit new dependency structures
- Sector: MLOps, scheduling
- What: Adjust microbatch sizes, checkpointing, and activation recomputation strategies based on “delayed normalization” and tile-partial reductions to improve throughput.
- Dependencies: End-to-end simulators/cost models; integration with schedulers (Ray, Kubernetes), memory budget constraints.
- Safety/QA processes for fused-kernel numerics
- Sector: QA/compliance
- What: Establish numeric acceptance tests (tolerances vs. FP32 references) for reparameterized RMSNorm scaling in epilogues and epilogue-side LSE.
- Dependencies: Dataset-based validation; drift monitoring during long training runs.
Notes on feasibility across all items:
- CODA currently focuses on single-GPU kernels; distributed and cross-vendor support require further engineering.
- Attention kernels are out-of-scope; benefits target the “non-attention” share of runtime.
- Tile-local constraint means global operations must be reformulated as partial reductions plus auxiliary kernels; graph patterns that defy this may not benefit.
- Integration can obscure framework module boundaries; robust testing and clear APIs are essential to maintainability.
Glossary
- accumulator: On-chip registers or buffers that hold partial sums from the GEMM mainloop before final writes. "an epilogue sees only the local output tile, its accumulators, and consistently indexed auxiliary tensors"
- atomics: Hardware-supported read-modify-write operations that serialize concurrent updates to the same memory location. "We use a separate final reduction rather than atomics, and materialize logits to simplify the backward pass."
- autotuning: Automated search over kernel schedules and parameters to find high-performance implementations. "Compiler systems lower tensor programs to optimized kernels through graph rewriting, scheduling, code generation, and autotuning"
- BF16: A 16‑bit floating-point format (bfloat16) with an 8‑bit exponent used for efficient training computation. "We compare BF16 GEMM-RMSNorm-GEMM outputs against an FP32 reference on Llama-3 8B layers."
- Blackwell TMEM-based pipelines: NVIDIA Blackwell-era execution pipelines that leverage on-chip memory engines (“TMEM”) for overlapped compute and data movement. "as in Hopper Ping-Pong GEMM and Blackwell TMEM-based pipelines."
- broadcast: Replicating a vector or scalar across rows/columns to match a tile’s shape for elementwise operations. "load row or column vectors, broadcast them over an output tile"
- compute-bound: Operations whose runtime is limited by arithmetic throughput rather than memory bandwidth. "We reparameterize the computation so that most memory-bound operations are subsumed into the epilogues of compute-bound kernels."
- cross-entropy: A loss function for classification comparing predicted logits with target labels via log-softmax. "Cross-entropy loss can also be expressed as a GEMM with epilogue-side reductions"
- CuTeDSL: A CUDA template-based domain-specific language used for authoring high-performance kernels. "We implement CODA on top of CuTeDSL"
- CUTLASS: NVIDIA’s CUDA Templates for Linear Algebra Subroutines and Solvers, a library for composing GEMM mainloops and epilogues. "CUTLASS represents GEMM kernels as a composition of a collective mainloop and a collective epilogue"
- data movement: Transfers of tensors across the memory hierarchy, often a performance bottleneck. "Prior work has shown that data movement is a central bottleneck in Transformer training"
- epilogue: The post‑multiply phase of a GEMM kernel that transforms and stores each output tile. "A high-performance GEMM kernel is typically divided into a mainloop and an epilogue."
- Epilogue Visitor Trees: A compositional abstraction for epilogue operations built from reusable primitive nodes. "Epilogue Visitor Trees further express epilogues as compositions of primitives"
- FFN: Feed-forward network sub-layer in a Transformer, often with an expansion factor >1. "with FFN expansion rate $8/3$ rounded to multiples of $256$"
- FlashInfer: A specialized library of high-performance kernels for LLM inference. "rely on specialized LLM kernels in vLLM, SGLang, FlashInfer, and Liger Kernels"
- FP32: 32‑bit IEEE floating-point format, typically used as a numerical reference. "We compare BF16 GEMM-RMSNorm-GEMM outputs against an FP32 reference on Llama-3 8B layers."
- FP4: 4‑bit floating-point format used in cutting-edge low-precision matrix multiplication. "formats such as FP8 and FP4"
- FP8: 8‑bit floating-point format enabling faster, lower-precision matrix multiplications. "formats such as FP8 and FP4"
- GEMM: General Matrix–Matrix Multiplication, the core dense linear algebra primitive in training/inference. "A high-performance GEMM kernel is typically divided into a mainloop and an epilogue."
- GEMM mainloop: The tiled multiply–accumulate phase of a GEMM that produces output fragments before the epilogue. "CODA keeps the GEMM mainloop fixed and exposes a small set of composable epilogue primitives"
- global memory: Off-chip DRAM accessed by the GPU, higher latency/bandwidth-limited compared to on-chip memory. "efficiently writes it back to global memory."
- graph rewriting: Compiler transformation that replaces subgraphs with more efficient equivalents. "Compiler systems lower tensor programs to optimized kernels through graph rewriting, scheduling, code generation, and autotuning"
- Hopper Ping-Pong GEMM: An NVIDIA Hopper scheduling technique overlapping tiles by alternating (“ping-pong”) between buffers. "as in Hopper Ping-Pong GEMM and Blackwell TMEM-based pipelines."
- kernel DSLs: Domain-specific languages for writing GPU kernels at a higher level than CUDA while retaining performance. "programmers use kernel DSLs and libraries such as Triton, ThunderKittens, TileLang, CuTeDSL, Gluon, and TLX"
- language modeling head: The final projection that maps hidden states to vocabulary logits in a LLM. "final MLP down projection → residual stream → final RMSNorm → language modeling head."
- Liger Kernels: A collection of optimized kernels for deep learning workloads. "rely on specialized LLM kernels in vLLM, SGLang, FlashInfer, and Liger Kernels"
- LLM: LLM, a Transformer-based model trained on large text corpora. "Modern LLM systems are programmed at multiple abstraction levels."
- logits: Raw, unnormalized scores (pre-softmax) output by a model for each class/token. "We use a separate final reduction rather than atomics, and materialize logits to simplify the backward pass."
- log-sum-exp (LSE): A numerically stable computation of log(sum(exp(x))) used in softmax and cross-entropy. "the LSE can be accumulated as tile-local maximum and sum-exp statistics."
- materialization boundary: A point in an operator graph where intermediate tensors are written to memory rather than kept on-chip. "operator boundaries often become materialization boundaries"
- on chip: Residing in on-GPU resources (registers/shared memory) as opposed to off-chip DRAM. "while a GEMM output tile remains on chip, before it is written to memory."
- online log-sum-exp: A streaming form of log-sum-exp that maintains running max and sum-exp statistics. "the max and sum-exp statistics used in online log-sum-exp and cross-entropy."
- pairwise activation: An activation that consumes two adjacent feature values jointly (e.g., RoPE, SwiGLU). "A second common pattern in Transformers is a GEMM followed by a pairwise activation."
- QuACK: A high-performance GEMM implementation/template used as a reference in the paper. "We report the errors of CODA and QuACK, on which our GEMM template is based, normalized by the error of the standard PyTorch path."
- registers: Fast per-thread storage on the GPU used to hold fragments before storing to memory. "each thread holds a small tuple of adjacent output values in registers before they are stored."
- residual stream: The running hidden-state path where outputs are added back (residual connection) between sublayers. "attention output projection → residual stream → RMSNorm → MLP gate/up projection;"
- RMSNorm: Root Mean Square Layer Normalization that normalizes activations by their per-row RMS. "RMSNorm is the main case where the backward pass is not purely tile-local."
- RoPE: Rotary Positional Embeddings, a technique that encodes position by rotating feature pairs. "RoPE rotates each feature pair and return two outputs;"
- shared memory: Programmable on-chip memory shared by threads in a block, used to stage tiles. "These values are staged once in shared memory and reused across subtiles."
- SGLang: An LLM inference system with specialized kernels for serving. "rely on specialized LLM kernels in vLLM, SGLang, FlashInfer, and Liger Kernels"
- SwiGLU: A gated activation (Swish + GLU) commonly used in Transformer FFNs. "SwiGLU combines gate and value stream into one output;"
- Tensor Core: Specialized matrix-multiply units on NVIDIA GPUs that accelerate low-precision GEMMs. "whose kernels have been heavily optimized for Tensor Core execution."
- Tensor Memory Accelerator (TMA): A hardware engine for asynchronous bulk tensor transfers between global and shared memory. "uses Tensor Memory Accelerator transfers between global memory and shared memory"
- tile-local: Confined to the data within a single output tile, enabling fusion without cross-tile communication. "a programmable epilogue performs tile-local transformations before the result is written to memory"
- torch.compile: PyTorch’s graph-capture and compilation facility for optimizing execution. "Speedups are relative to cuBLAS with torch.compile."
- Triton: A GPU kernel DSL for writing high-performance kernels in Python-like code. "programmers use kernel DSLs and libraries such as Triton, ThunderKittens, TileLang, CuTeDSL, Gluon, and TLX"
- vLLM: A system/library for efficient LLM inference with specialized kernels and memory management. "rely on specialized LLM kernels in vLLM, SGLang, FlashInfer, and Liger Kernels"
- warp: A hardware execution group of threads that execute in lockstep on NVIDIA GPUs. "Row-wise reductions are accumulated by the warp that owns the row."
Collections
Sign up for free to add this paper to one or more collections.