- The paper introduces a novel decomposition of the GEMM kernel that eliminates redundant data repacking through efficient layout propagation.
- It demonstrates significant performance improvements with speedups of up to 2.25x on platforms like x86 and RISC-V.
- The integration into a Llama-3.2 inference pipeline highlights practical benefits in optimizing transformer attention mechanisms.
LP-GEMM: Integrating Layout Propagation into GEMM Operations
Introduction
The paper "LP-GEMM: Integrating Layout Propagation into GEMM Operations" (2604.04599) addresses the inefficiency inherent in standard BLAS APIs when executing sequences of dependent GEMM operations, as typically found in scientific computing and modern machine learning workloads. Conventional BLAS libraries, such as OpenBLAS and vendor-optimized libraries, aggressively optimize individual GEMM invocations but are constrained by the BLAS interface contract, which mandates repacking input matrices and restoring a canonical output layout for every operation. This design results in redundant packing and unpacking in consecutive GEMM workloads, leading to unnecessary computational overheads.
LP-GEMM proposes a decomposition of the GEMM kernel to enable efficient layout propagation across GEMM sequences, simultaneously eliminating redundant data transformations while preserving the ability to revert to a BLAS-compliant data layout at boundaries. Evaluations on x86 (AVX-512) and RISC-V (RVV 1.0) architectures demonstrate significant speedups (up to 2.25x over OpenBLAS for sequential GEMMs), and competitive results against specialized libraries such as Intel MKL. The methodology is further validated via its integration into a standalone Llama-3.2 inference implementation.
Motivation and Context
Sequential GEMM operations are ubiquitous in both classical scientific workloads and contemporary deep learning pipelines. In MLPs and Transformer models, the outputs of one GEMM frequently serve as inputs to subsequent GEMMs, interleaved with activation and normalization layers. However, as visualized in (Figure 1), traditional OpenBLAS executes each GEMM independently, causing each output to be unpacked before storage and repacked on next consumption, even when the operations occur contiguously in memory.
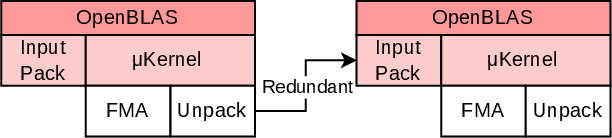
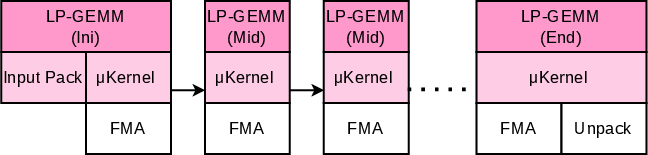
Figure 1: Consecutive GEMM executions using OpenBLAS. The illustration depicts only two GEMMs, but the same pattern generalizes to an arbitrary number of consecutive operations.
The GotoBLAS framework (adopted by OpenBLAS and modern high-performance libraries) partitions GEMM into tiled and packed micro-kernels (Figure 2), maximizing data locality and execution throughput. However, packing and unpacking dominate cost as the number of chained GEMMs increases.
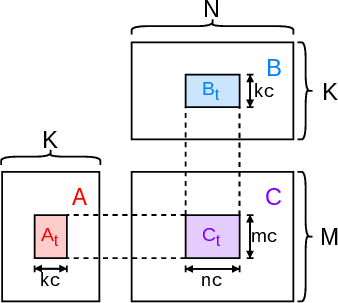
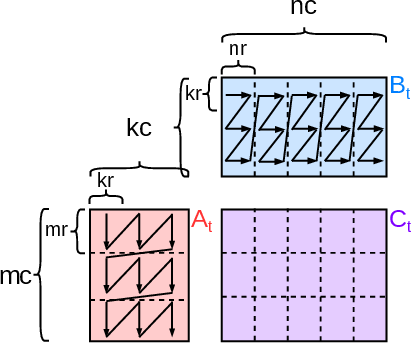
Figure 2: GotoBLAS's outer tiling. Each tile is packed for memory hierarchy efficiency before micro-kernel computation.
As depicted in (Figure 3), the opportunity exists to eliminate redundant data movement by preserving 'internal' layouts within a sequence, only reverting to canonical layouts at user-observable boundaries.
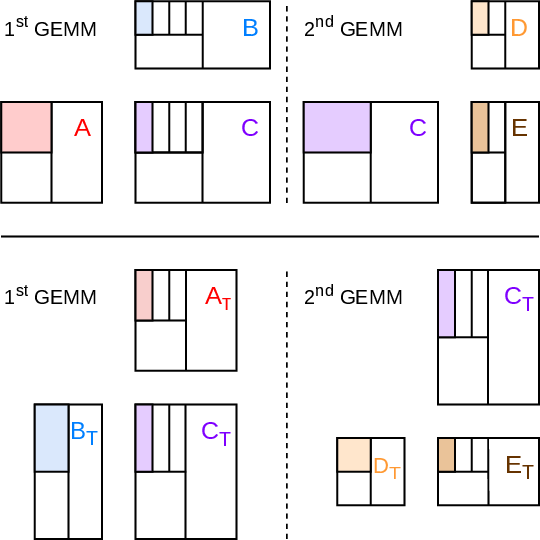
Figure 3: Overview of sequential GEMM operations using different data layouts. The results are the same as using OpenBLAS with column-major or row-major, respectively.
LP-GEMM Kernel Decomposition
LP-GEMM proposes three specialized GEMM kernels:
- Initial GEMM (ini-GEMM): Performs the canonical packing prior to the first GEMM in a sequence and propagates the resultant layout.
- Intermediate GEMM (mid-GEMM): Skips input packing and consumes/produces packed layouts directly, maximizing efficiency across sequences.
- Ending GEMM (end-GEMM): Consumes packed data and unpacks it to the canonical BLAS layout on completion.
This decomposition aligns the computation order, packed layout, and final storage layout, obviating the need for unnecessary repacking/unpacking except at the true boundaries (see Figure 4 for micro-kernel layout propagation and storage ordering).
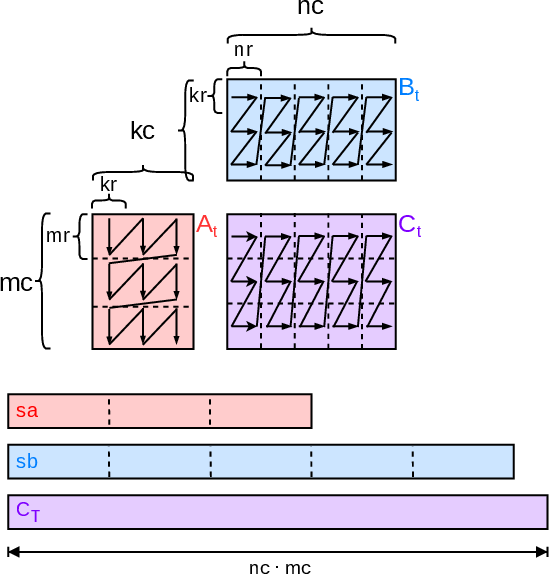
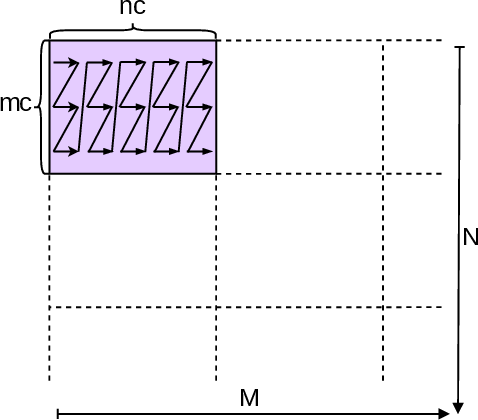

Figure 4: Micro-kernel compute order and layout. LP-GEMM aligns the packed, computed, and stored layouts to maximize reuse.
By design, LP-GEMM violates strict BLAS output layout conformity internally but ensures BLAS-compliant outputs are produced at required boundaries via the end-GEMM kernel as needed.
Integration with Machine Learning Workloads
The paper provides an in-depth implementation of LP-GEMM inside a BLAS-based Llama-3.2 inference pipeline, focusing on the Transformer attention mechanism. Layout propagation is complicated by operator interleaving (e.g., activation, softmax, rotary embedding) and the multi-head structure of attention. LP-GEMM addresses these by:
- Propagating appropriate strides to accommodate splitting and merging across attention heads and by statically determining efficient memory access paths.
- Modifying non-GEMM operations (e.g., Softmax, RoPE, RMSNorm) to handle or exploit the propagated layout.
Empirical verification is performed via bitwise-equivalent cross-validation with PyTorch implementations and open weights from Meta Llama 3.2.
Experimental Evaluation
The experimental campaign characterizes single-GEMM, attention-layer, and pure-sequence GEMM performance on Intel x86 (AVX-512 Xeon Gold 6252, Figures 5/6) and RISC-V (SpacemiT X60, RVV 1.0), pitted against OpenBLAS, BLIS, Intel MKL, oneDNN, and FlashGEMM.
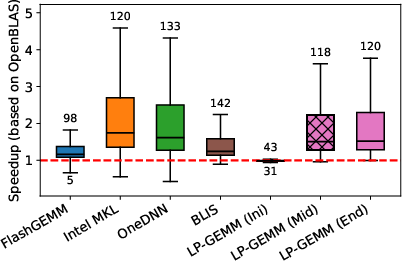
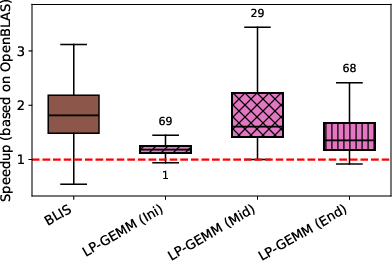
Figure 5: Intel Xeon Gold 6252 results for LP-GEMM compared to OpenBLAS and competitors.
Single GEMM:
LP-GEMM’s initial kernel (ini-GEMM) matches OpenBLAS in performance, as expected, due to similar work profiles aside from unpack elimination. In contrast, mid-GEMM and end-GEMM, which capitalize on eliminating repacking for internal GEMMs within a sequence, yield median speedups exceeding 1.5x and up to 2x (see Figure 6).
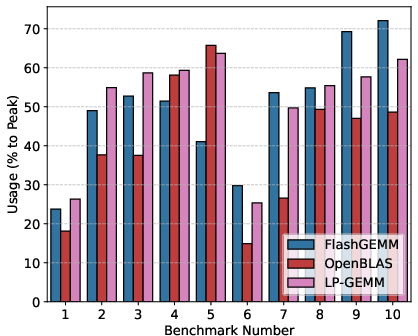
Figure 6: Usage comparison of LP-GEMM with FlashGEMM and OpenBLAS, using benchmarks extracted from DNNs. LP-GEMM avoids repacking overheads and outperforms alternatives in sequenced GEMMs.
Transformer Attention Layer:
In an attention-layer workload (Figure 5), LP-GEMM demonstrates up to 2x speedup for multi-head attention (low token counts) and substantial improvements across typical context sizes for both x86 and RISC-V platforms. Packing complexity dominates for smaller matrices in x86; for RISC-V, performance scales more linearly due to less cache-optimized baseline kernels.
Consecutive GEMMs:
Synthetic three-GEMM sequences, as used in FlashGEMM benchmarking, highlight that LP-GEMM consistently outperforms both OpenBLAS and FlashGEMM, especially as sequence length increases. The major gain accrues from removing intermediary packing phases, even in the absence of deep kernel tuning.
Theoretical and Practical Implications
The formal separation of packing, layout, and storage order and their controlled propagation has several noteworthy implications:
- Workload-Aware Kernel Optimization: LP-GEMM demonstrates that optimal GEMM kernel performance in dataflow pipelines is not simply a property of per-GEMM optimization, but rather of cross-operation layout management.
- Orthogonality to Kernel Tuning: The design is orthogonal to micro-kernel advances. Thus, methods such as those in Intel MKL or next-generation architectures can be composed with LP-GEMM for compound effects.
- Compiler and Framework Integration: The approach enables layout propagation to become a first-class transformation in ML compilers and optimization frameworks, reducing runtime ‘glue-code’ while unifying abstract dataflow and memory layout management.
- Extension to Non-GEMM Operators: Although LP-GEMM currently focuses on GEMM sequences, the approach is generalizable to other layout-tolerant/tolerant operators such as convolutions, and to more sophisticated pipeline scheduling.
Future Directions
- Integration with highly tuned micro-kernels: Since LP-GEMM focuses on the control of layout and packing, integrating it with commercial and hardware-specific highly tuned micro-kernels could yield even greater pipeline speedups.
- Generalization to arbitrary dataflow DAGs: Beyond strict sequences, extending propagation to manage arbitrary dependency graphs, supporting layout-aware fusion and lowering, is a key opportunity.
- End-to-end ML compiler adoption: Extending LP-GEMM as a transformation within e.g., TVM, XLA, or MLIR pipelines, with static layout propagation analysis, promises broad adoption in both research and production code.
Conclusion
LP-GEMM presents a principled methodology for integrating layout propagation into chained GEMM operations, systematically removing data transformation overheads that dominate in practical workloads. Experiments on x86 and RISC-V demonstrate significant improvements over standard and advanced vendor libraries, both in microbenchmarks and in high-level machine learning workloads. The practical and theoretical findings advocate for a shift toward pipeline-optimized, layout-aware dense linear algebra libraries, and serve as groundwork for future research in cross-operation memory management, compiler-level optimization, and efficient workload lowering for modern architectures.

