- The paper introduces a benchmark that evaluates LMMs' goal-oriented embodied navigation in 3D urban airspace, highlighting a substantial performance gap compared to human operators.
- It employs a high-fidelity Unreal Engine-based simulator to collect 5,037 annotated navigation trajectories and evaluates models with strict spatial metrics like SR, SPL, and DTG.
- The findings reveal that critical decision bifurcation errors and compounded planning failures underscore the need for improved geometric perception, cross-view integration, and episodic memory in LMMs.
Evaluating LMM Spatial Action: Benchmarking Goal-Oriented Embodied Navigation in Urban Airspace
Introduction and Motivation
Spatially grounded autonomous action is a foundational capacity for embodied AI. While LMMs achieve strong results on perception and linguistic reasoning tasks, there is limited understanding of whether they can match humans in embodied, continuous, real-time 3D spatial decision-making—particularly in complex, semantic-rich urban airspaces. The work "How Far Are Large Multimodal Models from Human-Level Spatial Action? A Benchmark for Goal-Oriented Embodied Navigation in Urban Airspace" (2604.07973) presents a rigorous empirical framework for quantifying this question.
This essay provides a detailed synthesis of the paper’s methodology, experimental protocols, main results, error analysis, ablation studies, and forward-looking implications for LMM-based embodied intelligence.
Urban Airspace Navigation Benchmark: Design and Dataset
The core contribution is a new large-scale benchmark explicitly designed for goal-oriented embodied navigation in realistic urban environments. Unlike prior works predominately focused on ground-level, indoor, or route-based tasks, this benchmark targets the true urban 3D problem setting: goal instructions are free-form linguistic descriptions (not step-by-step routes), the UAVs must operate in simulated urban airspace, and both horizontal and vertical motions are equally required to complete tasks. The dataset comprises 5,037 human-demonstrated, semantically annotated navigation trajectories, systematically annotated using rigorous protocols to ensure alignment with real-world task dynamics.

Figure 1: The benchmark formalizes goal-oriented navigation in urban airspace: agents receive only linguistic goal instructions and must sequentially act using continuous observations, revealing substantial performance gaps between LMMs and humans.
To generate this dataset, the authors utilize a high-fidelity Unreal Engine/AirSim-based urban simulator. Sample routes are collected by expert UAV operators who demonstrate navigation from randomized urban start points to semantically described goals while capturing rich multimodal observation and action sequences. The dataset exhibits robust distributional characteristics: an average trajectory length ≈203 m; horizontal, vertical, and rotational action proportions at 45.0%, 28.2%, and 26.8%, highlighting the essential vertical complexity absent from most prior benchmarks.
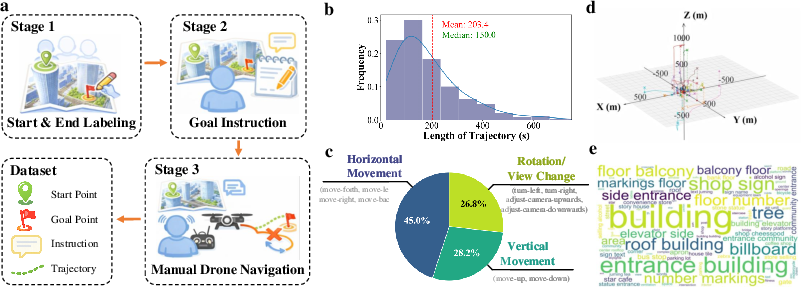
Figure 2: Dataset construction pipeline, trajectory length and action distributions, trajectory position statistics, and word cloud over goal instruction set.
Evaluation uses strict spatial navigation metrics—Success Rate (SR), Success weighted by Path Length (SPL), and Distance to Goal (DTG)—to thoroughly quantify policy effectiveness relative to human-level performance in spatial action.
Experimental Protocol: Models and Evaluation
The study benchmarks 17 models spanning the spectrum of:
- Non-reasoning LMMs (e.g., Qwen2.5-VL, GLM-4.6V, Gemini-2.0, GPT-4.1/4o)
- Reasoning LMMs (e.g., GPT-5.1, Qwen3-VL-Plus, Gemini-2.5)
- Agent-based navigation pipelines (SayNav, PRPSearcher, STMR)
- Vision-Language-Action (VLA) token models (OpenFly, Uni-NaVid)
Three generic paradigms are instantiated: "action-as-language" (direct language command generation), "action-as-reasoning" (hierarchical planning), and "action-as-token" (end-to-end discrete action token prediction).
Main Experimental Findings
A pronounced performance gap persists between LMMs and human operators. While human demonstrators achieve 92.0% SR, SOTA LMMs peak at 34.0% SR overall and 52.9% on short-range segments—even in zero-shot settings. All LMMs show drastic accuracy decay as trajectory length and task complexity increase. Notably, "reasoning" LMMs with explicit chain-of-thought/planning outperform both non-reasoning and direct action models on tasks requiring long-horizon spatial credit assignment.
Failures are strongly non-linear: the study identifies and formalizes the Critical Decision Bifurcation (CDB) phenomenon. Rather than error accumulation being gradual, single pivotal action choices (bifurcations) trigger persistent divergence from the optimal route—after which the model cannot recover, as shown by the sharp progress decay post-CDB.

Figure 3: Progress curves over navigation steps reveal the CDB effect—deviation from the goal explodes after a single critical error point, especially for non-reasoning LMMs and token-action models.
Model Reasoning and Trajectory Qualitative Analysis
Detailed comparative case studies elucidate the reasoning and error modes. SOTA LMMs such as GPT-5.1, at their best, exhibit human-like strategic action and reasoning, incorporating local observation, goal alignment, iterative adjustment, and route correction.
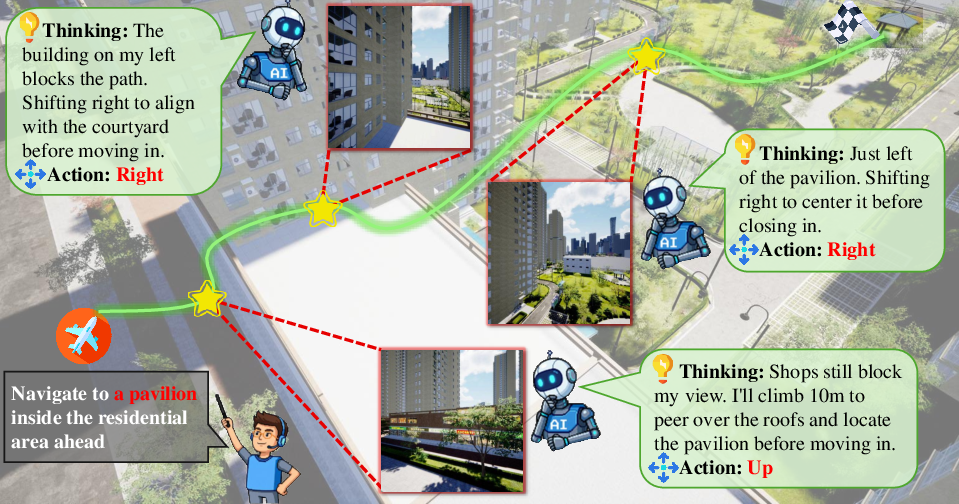
Figure 4: Visualization of GPT-5.1’s navigation steps, thoughts, and trajectories demonstrates sequences closely matching human reasoning and intent.
However, most model failures manifest as compounded perceptual, geometric, and planning errors, frequently at CDBs. Failure analyses reveal four primary axes where LMM spatial intelligence is fundamentally insufficient.

Figure 5: Comparison of model and human navigation trajectories exposes critical failure points—misperceptions, loss of cross-view context, lack of action-consequence anticipation, and memory/planning breakdowns.
Analysis of Spatial Action Limitations in LMMs
Quantitative and qualitative analysis across the navigation corpus yields four central limiting factors:
- Insufficient urban semantic and geometric perception: LMMs exhibit instability and unreliability in basic geometric property inference, object/landmark localization, and spatial relation grounding.
- Limited cross-view scene understanding: LMMs lack robust mechanisms to integrate temporally contiguous but disparate egocentric observations into a coherent spatial scene graph or consistent map-level state.
- Deficient action-consequence modeling ("spatial imagination"): There is minimal anticipation of observation/planning outcome resulting from chosen motion commands; models do not simulate/predict the resulting viewpoint change prior to acting.
- Inadequate long-term episodic memory/goal persistence: Over sustained trajectories, LMMs forget original instructions and/or previously acquired spatial evidence, degrading global plan alignment.
Targeted Ablation Studies: Interventions for Spatial Action
To validate error mechanisms and offer actionable directions, four targeted architectural and input augmentations are explored:
- Geometric Perception Enhancement: Integrating object grounding modules (e.g., GroundingDINO) to explicitly localize referenced targets prior to action selection. This yields up to 9.5% SR improvements but exposes limits in latent geometric representation in current LMMs.
- Cross-View Understanding: Feeding LMMs 360° panoramic observations at each step rather than a single FOV substantially improves orientation and target reacquisition, supporting the hypothesis that temporal/egocentric context integration is a critical achievable enhancement.
- Spatial Imagination (World Model Feedback): Incorporating explicit “imagination” steps (e.g., using the simulator as a model oracle for future observation) enhances the ability to select actions based on their predicted consequences.
- Sparse Memory: Token and context length bottlenecks are mitigated by only preserving significant (non-overlapping) frames in episodic memory, modestly boosting sustained performance.

Figure 6: Four intervention strategies—geometric perception, cross-view understanding, spatial imagination, and sparse memory—are systematically studied to dissect model errors and inform new LMM design.
Implications and Future Directions
This work lays a formal empirical foundation for spatial action benchmarking in high-dimensional, semantically complex settings. Strong claims include:
- LMMs do not yet demonstrate human-level spatial agency in even idealized, simulated urban airspace settings.
- Scaling and reasoning augmentations yield incremental improvements, but fundamental limitations—geometric encoding, cross-view memory, world-modeling, and episodic retention—prevent near-term parity.
- The CDB phenomenon suggests that robust spatial behavior will require models that both anticipate consequence and integrate local-global state knowledge, not simply larger scale or output modality tuning.
Practical implication: For robotics, aerial routing, and downstream embodied AI applications (e.g., drone delivery, autonomous inspection, disaster response), current foundation LMMs are not yet ready for unsupervised goal-oriented deployment and require structured augmentations.
Theoretically, these results motivate a hybridization of embodied LMMs with explicit geometric, cross-view, and world-model-based modules, analogous to those in classical robotics and SLAM, but differentiable and end-to-end tunable. Future research will likely prioritize unified architectures incorporating text, vision, persistent spatial memory, and action simulation in a causally integrated fashion.
Conclusion
The presented benchmark and study constitute a rigorous, actionable quantification of the embodied spatial intelligence gap in LMMs for high-realism urban airspace navigation (2604.07973). While progress is observable in the emergence of rudimentary spatial action capacities, the gap to human-level embodied reasoning is substantial and locally irreversible, especially in the face of cascading error at key decision junctures. Model composition with geometric encoders, memory systems, cross-view fusion, and world prediction is essential to tractable human-level agency. The benchmark and CDB analysis set new baselines for the field, and the dataset is positioned to facilitate direct, reproducible, and realistic evaluation for future spatially competent foundation models.