Learning Situated Awareness in the Real World
Abstract: A core aspect of human perception is situated awareness, the ability to relate ourselves to the surrounding physical environment and reason over possible actions in context. However, most existing benchmarks for multimodal foundation models (MFMs) emphasize environment-centric spatial relations (relations among objects in a scene), while largely overlooking observer-centric relationships that require reasoning relative to agent's viewpoint, pose, and motion. To bridge this gap, we introduce SAW-Bench (Situated Awareness in the Real World), a novel benchmark for evaluating egocentric situated awareness using real-world videos. SAW-Bench comprises 786 self-recorded videos captured with Ray-Ban Meta (Gen 2) smart glasses spanning diverse indoor and outdoor environments, and over 2,071 human-annotated question-answer pairs. It probes a model's observer-centric understanding with six different awareness tasks. Our comprehensive evaluation reveals a human-model performance gap of 37.66%, even with the best-performing MFM, Gemini 3 Flash. Beyond this gap, our in-depth analysis uncovers several notable findings; for example, while models can exploit partial geometric cues in egocentric videos, they often fail to infer a coherent camera geometry, leading to systematic spatial reasoning errors. We position SAW-Bench as a benchmark for situated spatial intelligence, moving beyond passive observation to understanding physically grounded, observer-centric dynamics.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
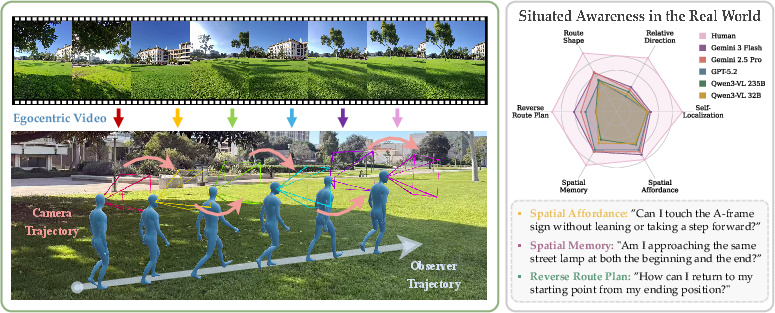
The paper introduces a new way to test whether AI can understand where it is and how it’s moving from its own point of view—kind of like how you know where you are when walking down a hallway, even if you’re turning your head. The authors call this skill “situated awareness.” They build a real-world video benchmark (called SAW: Situated Awareness in the Real World) using first‑person videos from smart glasses to see how well today’s video‑understanding AIs do on this kind of “from-my-eyes” spatial thinking.
What the researchers wanted to find out
The authors focused on simple but essential questions:
- Can AI tell where “it” is in a space from a first‑person view?
- Can AI track how it moves (and turns) over time?
- Can AI remember where things are, even when those things briefly leave view?
- Can AI plan how to get back to where it started?
- Can AI tell whether an action (like walking through a gap) is physically possible?
In short: they wanted to test whether AIs can reason about space the way people naturally do when moving through the real world.
How they tested it (in everyday terms)
They recorded lots of short, first‑person videos using smart glasses in many indoor and outdoor places—think classrooms, halls, yards, and plazas. The videos show a person walking around, sometimes turning their head, sometimes changing direction. For each video, they wrote multiple‑choice questions that require “observer‑centric” reasoning—answers depend on the camera wearer’s position and movement, not just what objects are in the scene.
They created six types of tasks:
- Self‑Localization: Where am I in this place?
- Relative Direction: Am I now left/right/ahead of where I started?
- Route Shape: What shape did my path make (straight, zigzag, etc.)?
- Reverse Route Plan: How do I get back to the start?
- Spatial Memory: Did something in the scene change between two moments?
- Spatial Affordance: Is an action possible from here (e.g., can I fit through that gap)?
Then they tested many state‑of‑the‑art AI models that can watch videos and read text (these are “multimodal foundation models,” like Gemini, GPT with vision, and open‑source models). The AIs watched the videos and answered the multiple‑choice questions. The team also compared the AIs to humans answering the same questions.
If a term sounds technical:
- Egocentric video = video from the person’s own viewpoint (like what your eyes see).
- Multimodal model = an AI that can process more than one kind of input (like video + text).
- Path integration (idea from psychology) = mentally keeping track of your steps and turns to know where you are, even without a map—like remembering how to get back to your room after walking around school.
What they discovered (main results)
The researchers found some clear patterns:
- There’s a big gap between humans and the best AIs. Humans got about 92% correct; the best AI scored about 54%. That’s a large difference for basic “from-my-eyes” spatial understanding.
- AIs often confuse turning your head with moving your body. If the camera wearer walks straight but looks left and right, many models think the path was zigzag. Humans easily tell the difference.
- The more the path involves turns, the worse most models do. Simple straight paths are easier; multiple turns cause big drops in accuracy.
- AIs struggle with persistent memory of the world. If an object goes out of view, models often act like it disappeared or never existed, instead of remembering it’s still there but off-camera.
- Indoor vs. outdoor doesn’t make a consistent difference. Bigger, more open outdoor spaces aren’t necessarily harder; sometimes indoor scenes are trickier because of clutter and complex layouts.
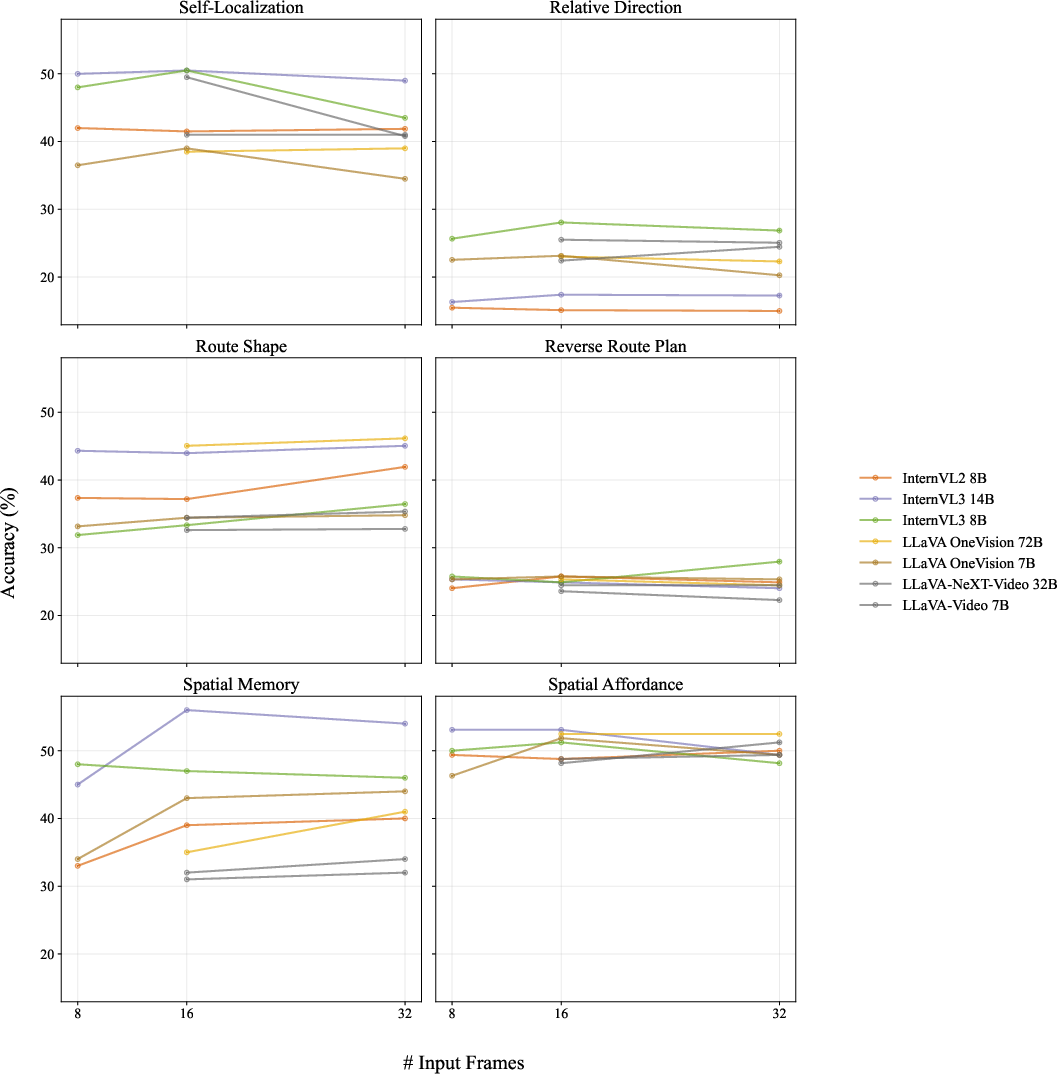
- Text‑only or “caption‑based” shortcuts don’t work. A text summary of the video isn’t enough. Models need detailed, frame‑by‑frame egocentric information to solve these tasks.
Why that’s important: it shows that current AIs are good at recognizing objects and describing scenes but still weak at the kind of grounded, body‑relative reasoning humans rely on all the time when moving around.
Why this matters (impact and what’s next)
- For robots and drones: A robot can’t just know “what a chair is.” It must know “where that chair is relative to me right now” and how to move around it safely. The benchmark highlights where robots might fail in the real world and how to improve them.
- For AR/VR and smart glasses: To keep virtual objects aligned with the real world and the wearer’s viewpoint, systems need solid situated awareness. Better performance means smoother, more reliable experiences.
- For assistive tech: Navigation aids or wearables that help people move safely must track position and movement correctly and remember where things are—even when out of view.
Overall, this benchmark gives the research community a clear, real‑world test of “observer‑centric” spatial understanding, points out common failure modes, and sets a path for building AIs that can move beyond just watching the world to truly understanding where they are within it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Limited sensing modality: videos are RGB-only and exclude audio and onboard IMU/GPS/odometry; it remains unknown how multimodal signals (e.g., inertial cues, head pose, audio, depth) affect situated awareness and rotation–translation disambiguation.
- No ground-truth camera pose/trajectory: the benchmark lacks precise 6-DoF pose or world-frame trajectories, preventing fine-grained evaluation of camera-geometry inference beyond multiple-choice accuracy.
- Device specificity: all data are captured with a single device (Ray-Ban Meta Gen 2), leaving cross-device generalization (different FOVs, stabilization, lens distortion, rolling shutter) untested.
- Scene and geography diversity: core data come from ~15 scenes (10 outdoor, 5 indoor) within a narrow geographic/cultural/architectural range; generalization across cities, countries, building styles, climates, and terrains remains unstudied.
- Temporal conditions: robustness to lighting (night/dusk), weather (rain/fog/snow), and seasonal changes is not evaluated.
- Dynamic settings: the benchmark underrepresents crowded or highly dynamic scenes (moving people/vehicles), leaving open how models track and maintain situated awareness under heavy occlusion and motion.
- Motion quality robustness: videos with rapid head motion, blur, or visibility issues were filtered out; the impact of such real-world artifacts on situated awareness remains unknown.
- Video length and memory limits: it is unclear how performance scales with longer trajectories and extended time horizons (e.g., minutes to hours), where path integration and drift become more pronounced.
- Sampling rate sensitivity: most evaluations use 2 fps; a systematic study across frame rates, frame counts, and temporal sampling strategies (beyond appendix sensitivity) is missing.
- Task label granularity: self-localization uses discrete reference locations and route-shape categories, not continuous spatial metrics; the ceiling effects and information loss of discretization are not quantified.
- Spatial affordance scope: affordance is treated mainly as feasibility; categories (passability, reachability, manipulability, stability, safety margins) and continuous constraints are not systematically enumerated or tested.
- Spatial memory construction: “Spatial Memory” uses concatenated clips pre/post controlled modifications; the ecological validity of this discontinuity and performance under continuous, unsegmented scene evolution remain open.
- Predefined trajectory bias: trajectories are limited to a finite set of shapes; generalization to free-form paths, loops, backtracking, vertical motion (stairs/elevators), and multi-level structures is not addressed.
- Annotator–recorder coupling: the same participants recorded and annotated, which may introduce bias or unintentional leakage; independent third-party annotations and validation are not reported.
- Inter-annotator reliability and ambiguity: while agreement is mentioned (appendix), the paper does not quantify per-task ambiguity, disagreement patterns, or difficult edge cases to guide future dataset refinement.
- Multiple-choice format limitations: MCQ evaluation risks answer-distribution priors and process-of-elimination strategies; free-form localization, trajectory sketches, or programmatic plans are not assessed.
- Class imbalance and chance levels: varying chance baselines (e.g., high for affordance) suggest label skew; the impact of answer distribution bias on model behavior is not disentangled.
- Evaluation metric breadth: only accuracy is reported; calibration, confidence, temporal consistency, and reasoning faithfulness are not measured, limiting insight into reliability and error severity.
- Answer parsing with another model: reliance on an external LLM for answer extraction may introduce evaluation noise/bias; robustness to parsing errors and model-to-model variability is not quantified.
- Proprietary-model reproducibility: closed-model scores may be unstable across versions/settings; detailed prompts and seeds are not fully analyzed for replicability and sensitivity.
- Model training and remediation: the paper diagnoses failure modes but does not explore training-time remedies (e.g., egocentric pretraining, geometry-aware objectives, world-models, or SLAM-informed supervision).
- World-state memory vs. view memory: the benchmark highlights persistence failures but does not test interventions (e.g., explicit object permanence memory, spatial maps, or long-context mechanisms) in a controlled manner.
- Rotation–translation disentanglement: error analyses suggest conflation, but there is no controlled ablation with ground-truth head pose to quantify and target this failure precisely.
- Correlation with embodied performance: it remains unknown whether SAW performance predicts downstream navigation, AR alignment, or robotic manipulation success; cross-benchmark transfer is untested.
- Real-time and compute constraints: no assessment of latency, efficiency, or performance under streaming constraints typical for AR/robotics deployment.
- Safety and failure-criticality: the benchmark does not measure how often models make high-risk spatial mistakes (e.g., misjudging passability) or how to detect/mitigate them via uncertainty estimates.
- Domain shift and adaptation: effects of fine-tuning, domain adaptation, or test-time adaptation on situated awareness are not studied.
- Data scale and growth: exact dataset size is not clearly stated in the main paper; pathways to scaling (more scenes, longer videos, varied conditions) and their projected impact are not examined.
- Multimodal integration strategies: the paper does not test whether combining captions, dense visual features, and explicit spatial state improves over single-stream processing.
- Benchmark extensibility: protocols to add new tasks (e.g., egocentric mapping, relocalization after teleportation, loop closure detection) are not outlined, limiting community-driven expansion.
Glossary
- Action feasibility: Whether a proposed action can be carried out given physical constraints and the environment. "action feasibility across varied layouts and physical constraints"
- Allocentric: A scene- or world-centered reference frame independent of the observer’s position or orientation. "these benchmarks remain largely allocentric, evaluating models as passive observers of scene-level events."
- Affordance: The action possibilities offered by the environment to an agent, given the agent’s capabilities. "and affordance \citep{gibson1960visual, gibson2014ecological} has studied these abilities as separable components"
- Bird’s-eye view: A top-down, global representation of a scene, independent of the observer’s local viewpoint. "without access to any birdâs-eye or global scene representations;"
- Camera geometry: The geometric configuration (e.g., position, orientation, intrinsics) of the camera that determines how 3D scenes project to images. "they often fail to infer a coherent camera geometry, leading to systematic spatial reasoning errors."
- Egocentric: A first-person perspective anchored to the observer/camera wearer’s viewpoint. "Egocentric video is a natural sensing modality for studying situated awareness"
- Egocentric camera rotation: Changes in the camera wearer’s orientation (rotations) independent of translational motion. "models often conflate egocentric camera rotation with translational movement;"
- Embodied agents: Agents that have a physical presence and viewpoint within an environment, experiencing and acting from their own perspective. "active embodied agents with their own view point, motion, and position."
- Grounding: Linking language expressions to specific entities, coordinates, or regions in the physical world. "evaluate the capability to ground natural language into specific 3D coordinates"
- Inter-annotator agreement: A measure of consistency between different human annotators on the same labels. "We report inter-annotator agreement score in \S \ref{app:meta_information_annotation}."
- Intentional arc: A phenomenological notion describing the continuity of intentions that structure perception and movement. "the ``intentional arc'' of their movements \citep{merleau2013phenomenology}."
- Meshes: Polygonal surface representations used to encode the shape of 3D objects or scenes. "reasoning over explicit, reconstructed geometric representations such as point clouds and meshes~\citep{jain2022bottom, hsu2023ns3d, huang2022multi, abdelrahman2023cot3dref}."
- Multimodal foundation models (MFMs): Large models that process and reason over multiple modalities (e.g., vision and language). "most existing benchmarks for multimodal foundation models (MFMs) emphasize environment-centric spatial relations"
- Object persistence: The notion that objects continue to exist even when they leave the camera’s field of view. "difficulty in maintaining object persistence across egocentric motion."
- Observer-centric: Defined relative to the observer’s position, orientation, and motion rather than an external frame. "observer-centric spatial reasoning"
- Observer-independent: Defined without reference to the observer’s state; world- or scene-centric. "observer-independent tasks."
- Path integration: Accumulating self-motion cues over time to update one’s estimate of position and orientation. "spatial intelligence relies on path integration, where local, situated updates are accumulated to a larger observer-aware map"
- Point clouds: Sets of 3D points sampling surfaces or volumes to represent scene geometry. "representations such as point clouds and meshes"
- Pose: The position and orientation of the camera/agent relative to the environment. "agent's viewpoint, pose, and motion."
- Radar plot: A radial chart used to compare multivariate performance across categories. "Radar plot compares human performance with representative MFMs across six situated awareness tasks in \ours."
- Regular-expression–based parser: A pattern-matching extractor that uses regular expressions to parse structured content from text. "we first apply a regular-expressionâbased parser to extract the predicted answer from each modelâs raw response."
- Socratic models: A method that composes multimodal reasoning by first captioning content and then using LLMs to answer questions. "Socratic models \citep{socratic_models}, which generate a single holistic caption for each video"
- Spatial affordance: Whether an action is feasible given spatial layout and physical constraints from the observer’s viewpoint. "Spatial Affordance (7.82\%): determine whether a specific action is feasible under physical constraints from the observer's viewpoint."
- Spatial memory: The ability to remember and compare spatial information over time. "Spatial Memory (4.83\%): reason about changes in the environment by comparing spatial information across time;"
- Spatial updating: Continuously revising the internal representation of space as one moves and reorients. "Spatial updating is an inherently accumulative process, where errors in estimating egocentric motion compound as the observer moves through an environment \citep{path_integration, hegarty, stangl2020sources}."
- Spatial working memory: Short-term storage and manipulation of spatial information. "spatial working memory \citep{luck1997capacity, simons1997change}"
- Situated awareness: Understanding space, actions, and changes relative to the observer’s ongoing position, orientation, and movement. "Collectively, these observer-centric capabilities constitute situated awareness \citep{flach1995situation, tversky2009spatial, sarter2017situation, endsley2017toward}"
- Translational movement: Motion that changes position (translation) without rotation. "models often conflate egocentric camera rotation with translational movement;"
- View-dependent evidence: Evidence based only on what is currently visible from a specific viewpoint, not on a persistent world model. "current MFMs rely primarily on view-dependent evidence, rather than maintaining a persistent world-state representation over time."
- Zero-shot setting: Evaluating models on tasks without task-specific training or fine-tuning. "We evaluate a diverse set of general-purpose MFMs in a zero-shot setting."
Practical Applications
Immediate Applications
The following applications can be deployed now using the benchmark, tasks, findings, and protocols introduced in the paper. They focus on evaluation, diagnostics, workflow design, and pragmatic integrations with existing tools.
- Benchmark-driven model gating and CI for embodied AI
- Sector(s): robotics, AR/VR, software
- Description: Integrate SAW (Situated Awareness in the Real World) as a pre-deployment test suite in CI/CD to automatically flag models that conflate camera rotation with translation, lose object persistence, or degrade on multi-turn trajectories. Use task-specific scores (self-localization, relative direction, route shape, reverse route plan, spatial memory, spatial affordance) to gate releases and select models fit-for-purpose.
- Potential tools/products/workflows: “SAW Compliance Dashboard” with task-wise metrics; failure-mode unit tests; regression tracking across model versions.
- Assumptions/dependencies: Requires egocentric video inputs similar to SAW; domain shifts (new environments, lenses, motion profiles) may impact transfer; privacy/compliance for internal video capture.
- Rotation–translation disentanglement pre-processing
- Sector(s): robotics, AR/VR, wearables, software
- Description: Add a lightweight visual odometry or head-orientation estimator to separate rotational pans from translational motion before feeding frames to MFMs. Provide models with explicit orientation deltas or stabilized views to reduce the “straight path misclassified as zigzag” error observed in SAW.
- Potential tools/products/workflows: Open-source SLAM/VO modules (e.g., ORB-SLAM) or IMU fusion; frame annotations for yaw/pitch/roll; stabilized trajectory summaries.
- Assumptions/dependencies: Access to sensors (IMU) or reliable VO; calibration for camera geometry; latency constraints for real-time use.
- Persistent world-state memory scaffolding
- Sector(s): robotics, AR/VR, software
- Description: Introduce a simple, external memory cache that tracks object existence and location across frames, mitigating “non-visible = non-existent” errors in spatial memory tasks. In AR, pin objects and occlusions persistently; in robots, maintain a “seen but currently out-of-view” map.
- Potential tools/products/workflows: Key–value object memory keyed by feature embeddings; temporal object graphs; “object-persistence adjudicator” module.
- Assumptions/dependencies: Requires consistent appearance embeddings; tuning for false persistence (e.g., moved/removed items); memory size vs. on-device constraints.
- Reverse route planner heuristics for short egocentric clips
- Sector(s): AR/VR navigation, assistive tech, robotics
- Description: Provide end-users a simple “return path” instruction set derived by inverting observed movement primitives (as demonstrated by stronger models in SAW). Useful for “find your way back” within buildings or campuses.
- Potential tools/products/workflows: Primitive action extractor (forward/left-turn/right-turn); route inversion; on-device “backtrack assistant.”
- Assumptions/dependencies: Works best when turns are cleanly segmented; performance drops with complex trajectories; needs user calibration for step length.
- Data collection and QA protocols for egocentric evaluation
- Sector(s): industry R&D, academia, software QA
- Description: Adopt SAW filming protocols (predefined reference points, coarse trajectory shapes, controlled environment changes) to build internal test sets tailored to target environments (warehouses, stores, campuses).
- Potential tools/products/workflows: “Egocentric filming playbook”; annotator agreement checks; human-in-the-loop verification.
- Assumptions/dependencies: Requires staff time; scene access permissions; privacy/consent management.
- Model selection and prompt engineering for egocentric tasks
- Sector(s): robotics, AR/VR, software
- Description: Use SAW scores to choose MFMs (e.g., prefer models stronger on reverse route planning for navigation features) and apply prompt scaffolds that explicitly separate orientation and translation, encourage step-wise temporal reasoning, and penalize shortcutting from “key frames.”
- Potential tools/products/workflows: Prompt templates: “List rotation vs. translation events per 2 seconds, then infer route shape”; chained frame-by-frame reasoning prompts.
- Assumptions/dependencies: Gains depend on model responsiveness to prompts; long-context handling costs and latency.
- Course modules and lab assignments for spatial cognition and HCI
- Sector(s): education, academia
- Description: Deploy SAW tasks as hands-on labs to teach path integration, observer-centric reasoning, and memory vs. visibility distinctions. Pair with basic VO/SLAM to demonstrate coordinate frames and error accumulation.
- Potential tools/products/workflows: Classroom datasets; Jupyter labs; visualization of trajectories vs. head rotation.
- Assumptions/dependencies: Institutional review for student filming; hardware availability (glasses or smartphone mounts).
- Product QA for AR affordances and safety checks
- Sector(s): AR/VR, consumer electronics
- Description: Use SAW’s spatial affordance tasks to ensure AR overlays don’t recommend infeasible actions (e.g., “walk through narrow gaps” that violate physical constraints).
- Potential tools/products/workflows: Affordance checklists; overlay-constraint validators; physics-aware placement rules.
- Assumptions/dependencies: Scene depth estimation reliability; occlusion handling; variability in environments.
- Procurement and risk assessment guidelines
- Sector(s): policy, enterprise IT, robotics buyers
- Description: Include observer-centric benchmarks (SAW-like tasks) in vendor evaluations for embodied AI or AR platforms to reduce deployment risk.
- Potential tools/products/workflows: RFP clauses with minimum task-level scores; independent validation reports.
- Assumptions/dependencies: Agreement on thresholds; vendor cooperation; standardized test protocols.
Long-Term Applications
These applications require further research, scaling, and productization to achieve reliability across diverse environments and operating conditions.
- Situated Awareness SDK combining MFMs with SLAM/IMU
- Sector(s): robotics, AR/VR, wearables, software
- Description: A unified SDK that fuses MFMs with geometric pipelines (SLAM/VO + IMU) and a persistent world-state memory. Provides observer-centric coordinate frames, robust path integration, and affordance checks out of the box for app developers.
- Potential tools/products/workflows: Real-time orientation/translation tags; temporal object graphs; affordance APIs; “return-to-origin” planner service.
- Assumptions/dependencies: Tight sensor fusion; efficient on-device inference; consistent performance under motion blur, low light, clutter.
- Certified evaluation standards for embodied multimodal systems
- Sector(s): policy, standards bodies, industry consortia
- Description: Formalize SAW-like observer-centric evaluations into certification programs for AR devices, service robots, and assistive wearables. Establish minimum passing criteria for tasks tied to safety-critical functions.
- Potential tools/products/workflows: Standard test suites; third-party accreditation; compliance reports.
- Assumptions/dependencies: Multi-stakeholder governance; legal frameworks; recurring audits.
- Robust egocentric spatial intelligence models specialized for real-world deployment
- Sector(s): robotics, AR/VR, software
- Description: Train new MFMs or hybrid models optimized on egocentric datasets (including SAW and scaled variants) to close the human–model gap (≈38%). Emphasize handling of head-rotation, complex trajectories, long-range memory, and inference under clutter.
- Potential tools/products/workflows: Curriculum learning with staged trajectory complexity; synthetic data generation with photorealistic agents; test-time adaptation via VO signals.
- Assumptions/dependencies: Large-scale data; compute budgets; robust data augmentation; domain generalization.
- Assistive orientation aids for populations with spatial deficits
- Sector(s): healthcare, assistive tech
- Description: Wearable systems that provide observer-centric guidance (e.g., “reverse route plans,” relative directions) to users with mild cognitive impairment or vestibular disorders. Includes safety-aware affordance feedback (“this path is feasible”) and memory prompts (“the exit was behind you 30m ago”).
- Potential tools/products/workflows: Privacy-preserving on-device inference; clinical validation studies; caregiver dashboards.
- Assumptions/dependencies: Medical regulatory approval; reliability across diverse settings; ethical safeguards for autonomy.
- Drone and mobile robot navigation in GPS-denied environments
- Sector(s): robotics, defense, industrial inspection
- Description: Deploy egocentric situated awareness to maintain orientation and route memory where GPS is unavailable (indoor, subterranean). Fuse camera and IMU to reduce trajectory drift and improve return-to-base reliability.
- Potential tools/products/workflows: VO-driven path integrators; “breadcrumb” memory; drift-aware planners.
- Assumptions/dependencies: Robustness under fast motion and low texture; energy constraints; environment variability.
- AR classroom and training experiences anchored to learner perspective
- Sector(s): education, training
- Description: Observer-centric content anchoring that adapts instructions and overlays to the user’s current orientation and motion (e.g., lab safety paths, equipment affordances, reverse route drills).
- Potential tools/products/workflows: Teacher dashboards; adaptive AR lesson plans; performance analytics based on SAW tasks.
- Assumptions/dependencies: Stable spatial mapping; content moderation; mixed device ecosystems.
- Retail, warehouse, and facility wayfinding with observer-aware guidance
- Sector(s): retail operations, logistics, smart buildings
- Description: Deploy situated guidance for picking routes, safety-aware affordances (e.g., constrained passages), and memory of item locations across large, cluttered indoor spaces, improving throughput and reducing errors.
- Potential tools/products/workflows: Observer-centric navigation microservices; route-shape validators; “reverse route to dock” assistance.
- Assumptions/dependencies: Accurate indoor mapping; scalability across layouts; worker privacy and consent.
- Insurability and risk modeling for embodied AI deployments
- Sector(s): finance/insurance, enterprise risk
- Description: Use standardized observer-centric scores to quantify operational risk (e.g., likelihood of navigation/affordance failures) when underwriting AR or robotics deployments.
- Potential tools/products/workflows: Risk scoring models tied to SAW task performance; premium adjustments; incident attribution frameworks.
- Assumptions/dependencies: Accepted correlation between benchmark scores and real-world incident rates; continuous monitoring.
Notes on Feasibility and Dependencies
- Input modality: SAW is built on egocentric video without audio; real-world systems may need audio, depth, or IMU for robustness.
- Hardware: Smart glasses or wearable cameras improve fidelity; smartphone mounts can suffice but may alter motion profiles.
- Privacy and ethics: Any real-world data collection must address consent, bystander privacy, and data governance.
- Computational constraints: Long-form reasoning over video is compute-intensive; edge deployment requires optimization.
- Generalization: SAW covers diverse indoor/outdoor scenes, but domain shift (different geographies, lighting, lenses) can reduce transfer; adaptation may be necessary.
- Human factors: Usability and trust hinge on consistent handling of head rotation vs. body translation and maintaining clear, reliable guidance under clutter and occlusion.
Collections
Sign up for free to add this paper to one or more collections.