- The paper presents E3VS-Bench, a rigorous benchmark requiring agents to actively explore photorealistic 3D Gaussian Splatting scenes for embodied visual search tasks.
- Methodologically, it uses 5-DoF agent control and strict dataset filtering to ensure episodes demand genuine exploration and visual evidence localization, enabling nuanced evaluation of spatial reasoning and object attribute tasks.
- Key findings reveal current visual language models lag behind humans in viewpoint planning and evidence acquisition, underscoring the need for improved multimodal memory and perception-action planning architectures.
E3VS-Bench: A Benchmark for Viewpoint-Dependent Active Perception in 3D Gaussian Splatting Scenes
Introduction and Motivation
E3VS-Bench advances embodied visual search by formulating the Embodied 3D Visual Search (E3VS) task within photorealistic 3D Gaussian Splatting (3DGS) reconstructions. Traditional benchmarks for visual search and embodied QA, such as REVERIE and EQA, constrain agent movement to planar navigation or limited viewpoint adjustment, thus omitting critical viewpoint-dependent phenomena—including occlusion resolution, vertical viewpoint shifts, and access to fine-grained object attributes—that are essential for real-world active perception. E3VS-Bench explicitly targets this deficiency, requiring agents to actively control their 5-DoF viewpoint to acquire visually grounded, task-critical evidence.

Figure 1: The E3VS task requires 5-DoF viewpoint control to resolve occlusions and access fine-grained visual evidence, with examples such as reading production area labels.
Benchmark Design and Dataset Construction
E3VS-Bench comprises 99 high-fidelity indoor scenes reconstructed from SceneSplat++ via 3D Gaussian Splatting, yielding photorealistic renderings that preserve minute visual details (e.g., small text, logos) often lost in mesh-based environments. Benchmark episodes (2,014 in total) are question-driven, necessitating active viewpoint manipulation for their resolution.
To ensure episodes demand genuine exploration, the dataset generation pipeline includes multi-stage filtering (Figure 2): (1) manual scene curation, (2) VLM-assisted QA pair generation, (3) human verification of QAs and viewpoint answerability, (4) annotation of answerable viewpoints, and (5) answerability filtering via a VLM-as-a-judge protocol that excludes episodes solvable without viewpoint transitions beyond prior knowledge or initial observation.
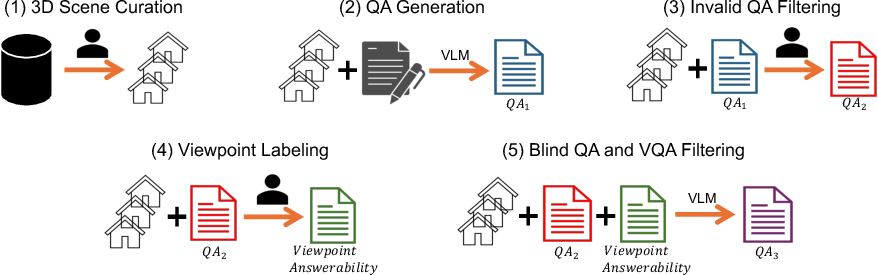
Figure 2: The dataset construction pipeline integrates VLM-driven QA generation, human annotation, and viewpoint filtering to ensure episodes require active exploration.
Statistical analysis demonstrates scene diversity and coverage of various QA categories: object search, context-guided search, object state, object attribute, spatial reasoning, and counting. All action types—including those involving vertical and rotational viewpoint changes—are well represented, underscoring the necessity of full 5-DoF control for effective task completion.
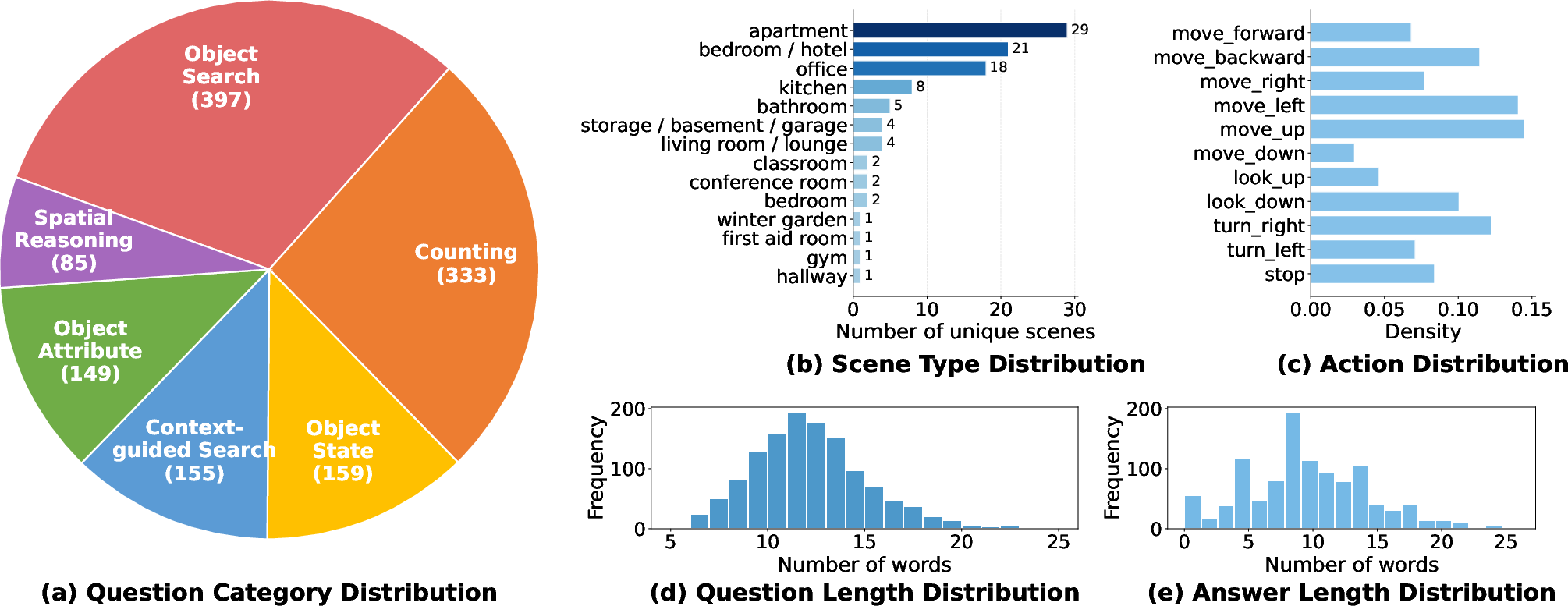
Figure 3: Dataset statistics reveal balanced distributions in question types, scene categories, action types, and QA lengths.

Figure 4: Representative E3VS episodes for each reasoning category, highlighting the variation in required viewpoint control for task resolution.
An E3VS episode consists of a (S,q,v0) triplet: a 3DGS scene S, natural-language question q, and initial viewpoint v0. The agent’s state is parameterized as vt=(xt,yt,zt,θt,ϕt), controlling translation and rotation in 3D space. The agent interacts via discrete actions in the environment until it issues a stop command, after which it generates an answer y^ from observation OT.
Correctness is assessed using a VLM-as-a-judge, scoring outputs on a 1–5 scale. This protocol incorporates semantic and visual grounding, with both agent-end and human-annotated goal images as reference to mitigate superficial matching in open-vocabulary QA. Judging reliability is supported by a moderate Spearman’s ρ=0.54 correlation with human evaluators.
Baselines and Experimental Analysis
E3VS-Bench benchmarks both proprietary (Gemini 2.5/3.0, GPT 5.1) and open-source (Qwen3-VL-8B/30B, InternVL3.5-8B, Step3-VL-10B) VLMs under the E3VS agent paradigm, as well as in static settings (blind VLM, VQA at start, birdview, goal, and single-image 2D visual search). Experiments are conducted in a zero-shot evaluation regime, with no optimization on train/val splits.
Key Findings
Ablation Results
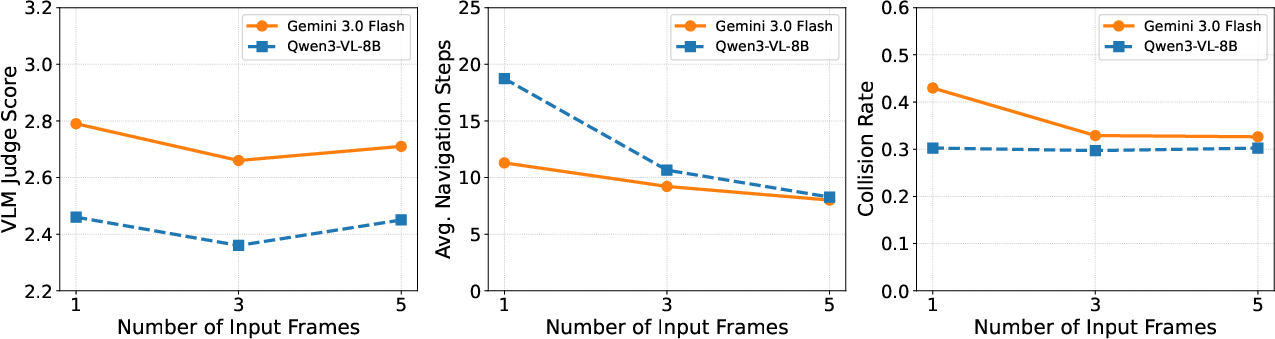
- Internal reasoning budget enhances GPT 5.1 viewpoint planning performance, but Gemini 3.0 Flash remains insensitive to the reasoning budget.
- Initializing agents at goal viewpoints confirms robust evidence recognition for Gemini models, with efficient stopping behavior relative to Qwen3-VL-8B.
- OA episodes are highly dependent on exploratory viewpoint discovery due to unpredictable evidence locations.
Qualitative Evaluation
Agent-selected viewpoints are frequently sub-optimal, failing to capture sufficient task-relevant evidence for robust answer justification. Human-selected viewpoints exhibit deliberate positioning for maximum visual clarity. The VLM-as-a-judge strictness penalizes answers unsupported by explicit visual grounding.

Figure 6: Comparison of predicted answers and judge scores for Gemini 3.0 Flash versus human responses underscores agent limitations in viewpoint selection and evidence acquisition.
Advanced Dataset Filtering
The appendix details advanced viewpoint filtering with VLM protocols (Figure 7) and QA generation (Figure 8), as well as penetrated viewpoint exclusion (Figure 9), ensuring physical plausibility and answerable QA pairs.

Figure 7: Sample viewpoint-to-QA filtering results, with green signifying accepted, red filtered viewpoints.

Figure 8: Examples of QA pairs generated by Gemini 2.5 Flash, illustrating the diversity and depth of instance-specific questions.

Figure 9: Penetrated viewpoint exclusion, where red denotes invalid camera positions due to geometric intersections.
Implications and Future Directions
E3VS-Bench establishes a rigorous evaluation platform for viewpoint-dependent embodied visual search, revealing persistent gaps between current VLM agents and human-level active perception. The benchmark exposes the criticality of evidence localization, trajectory planning, and visual grounding in complex 3D environments. Limitations in automated judging metrics—especially for viewpoint adequacy—suggest a need for refined evaluation protocols.
Practical: E3VS-Bench offers a standardized environment for testing embodied perception agents, with photorealistic details and strict open-vocabulary QA requirements. Deployment in robotic vision, AR, and navigation-centric AI systems is facilitated by the fidelity and granularity of benchmark tasks.
Theoretical: The dataset underscores the necessity for improved multimodal memory architectures, closed-loop perception-action planning, and compositional spatial reasoning capabilities in VLMs.
Future research paths: Incorporate trajectory-level evidence aggregation, memory-augmented architectures, reinforcement-driven viewpoint search, and more human-aligned evaluation criteria. Released splits enable learning-based agent optimization beyond zero-shot evaluation. Refining judge protocols and exploring the correlation of visual grounding with semantic correctness are critical for robust assessment.
Conclusion
E3VS-Bench systematically targets the limitations of embodied QA and visual search tasks by enforcing active, viewpoint-dependent exploration in high-fidelity 3DGS environments. Quantitative and qualitative analyses reveal persistent model deficits in spatial reasoning, evidence localization, and trajectory planning, with substantial performance divergence from humans. The benchmark sets an essential foundation for future advances in embodied active perception and multimodal reasoning (2604.17969).