LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation
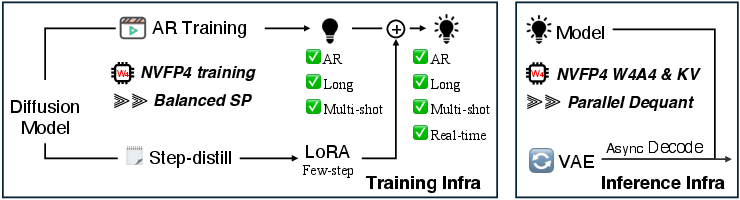
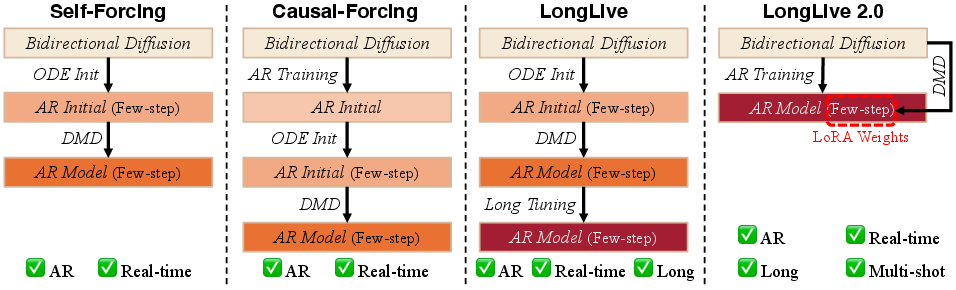
Abstract: We present LongLive-2.0, an NVFP4-based parallel infrastructure throughout the full training and inference workflow of long video generation, addressing speed and memory bottlenecks. For training, we introduce sequence-parallel autoregressive (AR) training, instantiated as Balanced SP, which co-designs the efficient teacher-forcing layout with SP execution by pairing clean-history and noisy-target temporal chunks on each rank, enabling a natural teacher-forcing mask with SP-aware chunked VAE encoding. Combined with NVFP4 precision, it reduces GPU memory cost and accelerates GEMM computation during training, the proportion of which increases as video length grows. Moreover, we show that a high-quality infrastructure and dataset enable a remarkably clean training pipeline. Unlike existing Self-Forcing series methods that rely on ODE initialization and subsequent distribution matching distillation (DMD), LongLive-2.0 directly tunes a diffusion model into a long, multi-shot, interactive auto-regressive (AR) diffusion model. It can be further converted to real-time generation (4 to 2 denoising steps) with standalone LoRA weights. For inference on Blackwell GPUs, we enable W4A4 NVFP4 inference, quantize KV cache into NVFP4 for memory savings, and boost end-to-end throughput with asynchronous streaming VAE decoding. On non-Blackwell GPU architectures, we deploy SP inference to match the speed on Blackwell GPUs, while the quantized KV cache can lower inter-GPU communication of SP. Experiments show up to 2.15x speedup in training, and 1.84x in inference. LongLive-2.0-5B achieves 45.7 FPS inference while attaining strong performance on benchmarks. To our knowledge, LongLive-2.0 is the first NVFP4 training and inference system for long video generation.
First 10 authors:


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “LongLive‑2.0: An NVFP4 Parallel Infrastructure for Long Video Generation”
What this paper is about (overview)
This paper shows how to make computers generate long, high‑quality videos much faster and with less memory. The authors built a system called LongLive‑2.0 that speeds up both “training” (when the model learns) and “inference” (when the model actually makes new videos). They do this by:
- Slicing long videos into manageable chunks and training efficiently across many GPUs in parallel.
- Using very compact numbers (called NVFP4, or 4‑bit floating point) so the computer has less work to do.
- Compressing and streaming parts of the process so the whole pipeline runs smoothly and in real time.
What questions the paper tries to answer (objectives)
In simple terms, the paper aims to:
- Make long video generation fast enough for real‑time use (like 30–45 frames per second).
- Cut down the huge memory needed to handle long videos.
- Keep video quality high even while using faster, smaller‑number math.
- Support “multi‑shot” and “interactive” generation, meaning you can create long videos with multiple scenes and edit or change prompts chunk by chunk.
How they did it (methods explained with everyday ideas)
The authors combine a few key ideas. Here they are with simple analogies:
- Chunked, auto‑regressive training (learning from short pieces in order)
- Imagine making a movie one scene (chunk) at a time. To create the next scene, the model looks at the earlier scenes it already made. This is “auto‑regressive” (AR): new content depends on past content.
- “Teacher forcing” is like practicing with an answer key: while learning, the model gets the correct past scenes as context so it learns quickly and doesn’t get confused.
- Balanced sequence parallelism (sharing the workload fairly across GPUs)
- Think of a long book split among many students (GPUs). Regular splitting can accidentally give some students all the hard pages.
- “Balanced SP” pairs each GPU with the same time chunk of both “clean history” (the right answer) and “noisy target” (what needs fixing), so every GPU does a fair share. It also ensures the video compression step (VAE encoding) is split the same way, saving time and memory for everyone.
- NVFP4 low‑precision numbers (doing math with fewer digits)
- Normal training uses big, precise numbers (like BF16). NVFP4 uses very small numbers (4‑bit floats), kind of like writing with fewer digits. This makes math and memory cheaper and faster.
- Special scaling tricks make sure the small numbers still keep important details, so quality doesn’t drop much.
- On NVIDIA Blackwell GPUs (new hardware), this tiny‑number math runs especially fast.
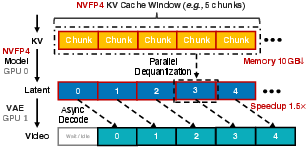
- KV‑cache compression (smaller memory for attention)
- The model keeps “notes” about what it has seen so far, called a KV cache. For long videos, these notes get huge.
- The paper compresses these notes using NVFP4 so they take about 3.6× less space, but can still be quickly read back when needed.
- Asynchronous streaming decoding (overlap steps to save time)
- After the model finishes a chunk, you must “decode” it back into video frames (like unzipping a file). Decoding used to create a pause.
- Now, one GPU decodes chunk c while other GPUs are already generating chunk c+1, like a factory assembly line. This hides the decoding time and speeds up the whole process.
- Few‑step generation via LoRA (plug‑in for real‑time speed)
- Diffusion models usually take many “denoising” steps to create a video. The authors add tiny adapter layers called LoRA (like a plug‑in) so the model can jump from 4 steps down to 2 steps for near real‑time video, without retraining everything.
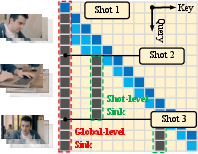
- Multi‑shot and interactive prompting (control each scene)
- Each chunk can have its own text prompt, so you can change the script at scene boundaries without messing up earlier scenes.
- A “multi‑shot attention sink” keeps important anchors from the start of the video and the start of the current scene, helping the video stay consistent across scenes.
What they found (main results) and why it matters
Here are the headline results reported in the paper:
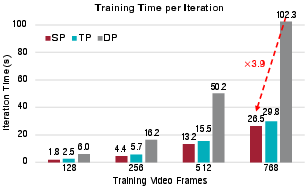
- Faster training and inference
- Up to 2.15× faster training and 1.84× faster inference compared to the BF16 baseline.
- On a 5‑billion‑parameter model (720p), they reach 45.7 FPS with 2 denoising steps, which is real‑time video generation.
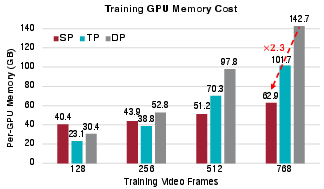
- Much lower memory
- Training memory dropped from about 35.4 GB to 19.4 GB per GPU in some settings.
- The attention “KV cache” is compressed to roughly 1/3 of its original size, which is crucial for long videos.
- Streaming decoding keeps GPU memory steady while the video length grows.
- Simple, cleaner training pipeline
- Previous methods needed complicated multi‑stage procedures (special initialization + extra distillation stages). LongLive‑2.0 fine‑tunes directly on long videos with AR training, then adds a small LoRA step for few‑step, real‑time generation.
- This makes the whole process easier to train, maintain, and deploy.
- Strong quality on benchmarks
- Good scores on VBench and VBench‑Long (60‑second videos), with particularly strong consistency of subjects and backgrounds across long scenes.
- NVFP4 models retain strong quality even at high speed.
These results matter because they show you can get fast, real‑time long video generation with good quality and reasonable hardware costs—something that used to be very hard.
What this could change (impact)
- Real‑time creative tools: Long, multi‑scene videos could be generated and edited on the fly, e.g., for storyboarding, education, or live content creation.
- Cheaper and greener AI: Using smaller numbers and better parallelism means less compute and less energy for the same output.
- Easier deployment: The cleaner pipeline (direct AR fine‑tuning + small LoRA for few steps) makes it simpler to build and ship video tools.
- Hardware awareness: The biggest speedups appear on the newest NVIDIA Blackwell GPUs. On older GPUs, their sequence‑parallel inference still gives meaningful speed gains.
In short, LongLive‑2.0 is like redesigning the video‑making factory so that:
- Workers share the right pieces at the right time,
- The instruction sheets are lighter but still accurate,
- Finished parts move down the line while the next parts are already being made,
- And you can easily switch scenes without breaking the story.
This combination delivers faster, longer, and more controllable AI‑generated videos, bringing real‑time long video creation much closer to everyday use.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. Each item is phrased to be directly actionable for future research.
- Balanced SP scalability: Lacks systematic scaling studies over number of GPUs, chunk counts, and sequence lengths, including breakdowns of communication, compute, and memory overheads versus naive SP and alternative SP variants.
- Formal analysis of load balance: No theoretical guarantees or models quantifying loss-token balance, communication complexity, or expected speedups of Balanced SP under diverse data distributions and masking patterns.
- VAE halo policy: No ablation of halo size versus quality/throughput trade-offs, nor guidance on adaptive halo selection across frame rates, motion regimes, or VAE receptive fields.
- NVFP4 quality impact: Limited analysis of perceptual or semantic degradation from FP4 (W4A4) versus BF16, especially for very long horizons, rare events, fine textures, and challenging motions.
- NVFP4 stability bounds: Sensitivity to quantization hyperparameters (block sizes, hierarchical scales, “4-over-6” scale search, RHT strength/placement) is not characterized; failure modes and recovery strategies are unclear.
- Generality across backbones: Transferability of Balanced SP + NVFP4 training to other diffusion backbones, sizes (sub-1B to >10B), and architectures (non-DiT, hybrid) remains untested.
- Hardware generalization: Claims that SP inference compensates on non-Blackwell GPUs lack quantitative benchmarking (latency/FPS, memory, efficiency) on A100/H100-class hardware and heterogeneous multi-node settings.
- Energy and cost efficiency: No measurements of energy per frame, footprint, or cost per training/inference hour across precision modes and hardware tiers.
- KV-cache quantization quality: Absence of detailed quality ablations versus cache bitwidths, block sizes, attention window lengths, and total history length; long-horizon drift and semantic retention are not quantified.
- KV normalization choices: The simple key mean subtraction is not compared to alternative normalization/centering schemes (e.g., per-head/layer normalization, whitening) for minimizing attention distortion under FP4.
- Inter-GPU communication with quantized KV: Reduction in SP communication volume due to NVFP4 KV cache is asserted but not empirically measured or profiled.
- Asynchronous decoding bandwidth limits: The impact of PCIe/NVLink bandwidth and CPU offload on end-to-end throughput and tail latency is not analyzed; behavior when t_VAE ≥ t_DiT (decoder becomes bottleneck) is unstudied.
- Resource-constrained deployments: Trade-offs for sharing the VAE and DiT on a single GPU (or small-GPU rigs) versus dedicating a VAE GPU are not evaluated; scheduling and memory pressure under such constraints are unknown.
- Multi-shot attention sink robustness: Requires manual or prompt-based shot boundaries; robustness to implicit or misdetected scene cuts and to mixed intra-shot edits remains untested; identity and style drift metrics are missing.
- Interactive editing latency: End-to-end responsiveness and recomputation costs for prompt switches, shot re-binding, and partial re-generation are not reported.
- Few-step LoRA distillation design: LoRA rank, per-layer placement, and merging strategies are not specified or ablated under W4A4; stability and optimality versus full-backbone or partial fine-tuning remain open.
- Teacher precision in DMD: Distilling from a W4A4-quantized teacher versus BF16 teacher is not compared; the effect on student quality and convergence is unknown.
- Data transparency: Training data composition, licensing, duration distribution, domain diversity, and potential biases are not disclosed; their effects on generalization, fairness, and safety are unexamined.
- Sequence-length limits: Performance and failure modes beyond 60–64 seconds (e.g., multi-minute) are unreported; behavior under extreme history lengths with sliding windows and quantized caches is unclear.
- Resolution scaling: Throughput/quality trade-offs and NVFP4 stability at 1080p and 4K are not evaluated; memory and bandwidth limits at higher resolutions remain unknown.
- Tokenization/chunking choices: Effects of chunk size, stride, attention window W, and patch embedding granularity on quality, compute, and cache pressure are not comprehensively ablated.
- Baseline comparability: Many baselines are at 480p whereas LongLive-2.0 is at 720p; normalized comparisons (same resolution, steps, and prompts) and cross-metric analyses are missing.
- Reproducibility/portability: Custom CUDA/Triton/NVFP4 kernels’ portability across driver/toolchain versions and alternative software stacks is not discussed; the extent of open-sourcing and test coverage is unclear.
- Safety and watermarking: No mechanisms or evaluations for watermarking, content filtering, or misuse mitigation are provided, despite higher-throughput, long-horizon generation.
- AR vs diffusion forcing: No analytical or empirical study of exposure bias, error accumulation, or train–test alignment differences between clean-context teacher forcing and diffusion forcing under the proposed infra.
- Multimodal extension: Applicability of Balanced SP + NVFP4 to audio-conditioned, text–image–video, or audio–video generation (and their cache/quantization peculiarities) is unexplored.
- Cross-attention under quantization: The impact of activation/weight/KV quantization on semantic faithfulness and prompt adherence in per-chunk cross-attention is not isolated or measured.
- Scheduling and kernel overlap: Detailed kernel-level timelines (attention, GEMMs, all-to-all, dequant, decoding) and overlap strategies are not provided, limiting guidance for further system co-design.
Practical Applications
Below is a consolidated analysis of practical, real-world applications enabled by LongLive-2.0’s findings and infrastructure (Balanced sequence-parallel AR training, NVFP4 W4A4 training/inference, KV-cache quantization, asynchronous streaming VAE decoding, multi-shot attention sink, and few-step LoRA distillation). The lists are grouped by deployment time horizon, with each item noting sectors, potential tools/workflows, and key assumptions or dependencies.
Immediate Applications
These can be deployed now using available cloud hardware (especially NVIDIA Blackwell GPUs) and the released LongLive-2.0 stack.
- Real-time long-form video generation services
- Sector: Media/entertainment, advertising, gaming, social platforms, software/cloud
- Tools/Workflows:
- Cloud APIs/SDKs offering 2–4 step, 720p, multi-shot generation (45.7 FPS reported) with chunk-wise prompts and multi-shot attention sink for coherence
- Hosted inference servers using W4A4 NVFP4 weights and NVFP4-quantized KV cache for lower memory and higher throughput
- Streamed decoding services with asynchronous VAE to reduce end-to-end latency for long videos
- Assumptions/Dependencies:
- Best performance requires NVIDIA Blackwell GPUs for native NVFP4 acceleration; on Ampere/Hopper, use SP inference for speed but expect lower gains
- Quality with 2–3 step LoRA depends on DMD-trained adapters; some content types may need more steps
- Provisioning a dedicated GPU for streaming VAE decoding improves E2E latency
- Interactive multi-shot story creation and editing
- Sector: Consumer apps, creative tools, education, marketing
- Tools/Workflows:
- Timeline-style UI with per-chunk prompts (“chunk-wise conditioning”) to edit future shots without disturbing history
- Multi-shot attention sink to preserve global identity and per-shot consistency during sliding-window generation
- Real-time preview via asynchronous VAE decoding and SP inference
- Assumptions/Dependencies:
- Requires integration into existing creative UIs (e.g., plugins for Adobe Premiere/After Effects, DaVinci Resolve, or custom web apps)
- Prompt-switch boundaries and sink parameters may require tuning for specific genres (e.g., rapid scene cuts vs. slow transitions)
- Previsualization and animatics in virtual production
- Sector: Film/TV, game development, broadcast
- Tools/Workflows:
- Rapid ideation of scene sequences with per-shot prompts, enabling quick iteration and alignment with storyboards
- Batch generation pipelines leveraging NVFP4 inference to reduce time/cost per version
- Assumptions/Dependencies:
- Higher resolutions (1080p/4K) may require additional distillation, hardware, or step count increases for quality
- Licensing constraints for training data and style-controlled LoRA packs must be respected
- Automated long-form ad creatives and A/B testing at scale
- Sector: Advertising, e-commerce, finance (marketing functions)
- Tools/Workflows:
- Batch generation of long-form ads with variant prompts per segment (product detail, lifestyle scene, call-to-action)
- Cost-effective serving using NVFP4 W4A4 inference and KV-cache quantization for high concurrency
- Assumptions/Dependencies:
- Brand/style consistency may require custom LoRA packs; human QA and compliance reviews remain necessary
- Content safety and watermarking pipelines need to be integrated
- Long-duration instructional and training videos
- Sector: Education, enterprise L&D, public sector
- Tools/Workflows:
- Chaptered explainer videos with chunk-wise prompts for each section
- Streaming generation and immediate CPU offload reduce memory and latency, enabling faster iteration cycles
- Assumptions/Dependencies:
- Factuality and pedagogy still require curation; generation quality for diagrams/math may need specialized conditioning
- Synthetic data generation for long-horizon perception and tracking
- Sector: Computer vision R&D, robotics simulation
- Tools/Workflows:
- Generate long, multi-shot sequences for training or benchmarking temporal consistency (e.g., tracking, long-horizon events)
- Balanced SP training and NVFP4-enabled training pipelines lower cost for domain adaptation or bespoke generators
- Assumptions/Dependencies:
- Domain fidelity may limit transfer to real-world tasks; may need style/domain-specific finetuning
- Infrastructure and training efficiency upgrades for labs and enterprises
- Sector: Academia, AI labs, cloud/ML platforms, energy-conscious datacenters
- Tools/Workflows:
- Adopt Balanced SP for uniform loss distribution and reduced VAE replication during long-sequence AR training
- NVFP4 training (with RHT where needed) to cut memory and speed up GEMMs; extendable to other long-sequence Transformers
- KV-cache NVFP4 compression to 3.6× smaller footprint for lower inter-GPU communication in SP settings
- Assumptions/Dependencies:
- Benefits are hardware-dependent; gains increase with sequence length
- Requires engineering to port kernels and ops to internal codebases
- Cost-optimized deployment on non-Blackwell GPUs
- Sector: Software/cloud, enterprises with mixed GPU fleets
- Tools/Workflows:
- Use SP inference to approach Blackwell-like throughput; enable NVFP4 KV-cache to reduce memory/comms even without FP4 compute acceleration
- Assumptions/Dependencies:
- Performance uplift lower than on Blackwell; careful partitioning/tuning of SP groups needed
- Style/speed LoRA marketplaces for few-step generation
- Sector: Media/entertainment, creator economy, software platforms
- Tools/Workflows:
- Distribute LoRA adapters that convert multi-step AR models to 2–3 step real-time variants while preserving base content capabilities
- Assumptions/Dependencies:
- Adapters should be versioned to backbone revisions (e.g., Wan2.2-TI2V-5B-based) and quality validated per domain
Long-Term Applications
These require further research, scaling, product integration, or broader hardware availability.
- In-editor, timeline-native generative video tools
- Sector: Creative software, M&E
- Tools/Workflows:
- Native integration of chunk-wise prompting, multi-shot attention sink, and streaming decode within NLEs (timeline tracks for prompts, sinks, and cross-attention caches)
- On-demand regeneration of selected chunks with preserved history for non-destructive editing
- Assumptions/Dependencies:
- Robust plugin APIs, standardized cache formats, and UI paradigms for generative timeline control
- On-device or edge real-time long video generation
- Sector: Consumer devices, mobile/AR
- Tools/Workflows:
- NVFP4-class compute on future consumer GPUs/NPUs enabling sub-10W real-time generation for 720p+; partial offload to CPU via streaming VAE
- Assumptions/Dependencies:
- Hardware support for FP4 and FP8 scaling; memory bandwidth and thermal constraints on edge devices
- 1080p–4K long-form real-time generation
- Sector: Broadcast, film, AAA gaming, live events
- Tools/Workflows:
- Enhanced distillation and model scaling (or cascaded VAEs) to preserve quality at higher resolutions with 2–3 steps
- Multi-GPU pipeline parallelism with quantized KV caches for high-res windows
- Assumptions/Dependencies:
- Additional research into high-res few-step distillation; increased memory and I/O requirements
- Live generative broadcast augmentation
- Sector: Sports, news, events
- Tools/Workflows:
- On-the-fly generation of b-roll, transitions, explainers, and scene context with coherent identities across segments
- Assumptions/Dependencies:
- Tight latency SLAs and integration with live ingest/graphics systems; editorial oversight
- Long-horizon agent workflows for story planning and video realization
- Sector: Software platforms, creative tech, gaming
- Tools/Workflows:
- LLM planners create per-shot outlines which are realized by the LongLive-2.0 AR generator using chunk-wise prompts and sinks; iterative revise-and-render loops
- Assumptions/Dependencies:
- Stable cross-modal interfaces (LLM→video prompts), evaluation schemes for narrative coherence
- Medical and educational personalization at scale
- Sector: Healthcare, education, public sector
- Tools/Workflows:
- Patient- or learner-specific long videos that adapt in chapters; support language localization and accessibility
- Assumptions/Dependencies:
- Rigorous validation, bias and safety controls, regulatory compliance (e.g., HIPAA/GDPR); expert-in-the-loop review
- Robotics learning from long generated videos
- Sector: Robotics, autonomy
- Tools/Workflows:
- Synthetic, long-horizon video curricula to pretrain perception or to support imitation learning frameworks
- Assumptions/Dependencies:
- Need domain fidelity and sim-to-real bridges; possible coupling with physics-grounded simulators
- Cross-domain generalization of Balanced SP and NVFP4 to other modalities
- Sector: Foundation models (LLMs, audio, multimodal)
- Tools/Workflows:
- Apply chunk-aligned SP layouts and FP4 hierarchically scaled quantization to train/infer long-context language, audio, and multimodal models more efficiently
- Assumptions/Dependencies:
- Kernel and optimizer support in those stacks; stability techniques (e.g., RHT) tuned per modality
- Standardized low-bit, long-context inference stacks for the public sector
- Sector: Government, nonprofits, education IT
- Tools/Workflows:
- Reference deployments for low-cost, low-power, long-video generation and archival, with integrated watermarking and audit trails
- Assumptions/Dependencies:
- Hardware refresh cycles to FP4-capable systems; policy frameworks for synthetic media provenance
- Safety, provenance, and watermarking integrated with low-bit pipelines
- Sector: Platform policy, compliance
- Tools/Workflows:
- FP4-friendly watermarking and detection methods embedded in the generation pipeline; policy tooling for large-scale content governance
- Assumptions/Dependencies:
- Co-design with quantized kernels and streaming decode to avoid significant performance regressions
- Ecosystem of LoRA adapters (style, domain, speed, and control)
- Sector: Creator economy, enterprise content teams
- Tools/Workflows:
- Curated, verifiable LoRA packs that modify artistic style, pacing, or step count; dynamic loading during NVFP4 inference
- Assumptions/Dependencies:
- Versioning, IP compliance, and quality control; universal adapter interfaces across backbone revisions
Notes on feasibility across the board:
- Hardware: NVFP4 acceleration is presently supported natively on NVIDIA Blackwell GPUs; performance on earlier architectures relies on SP and other software optimizations.
- Quality/latency trade-offs: Few-step (2–3) generation trades some quality for speed; content type and resolution influence the acceptable step budget.
- Data and governance: Long-video training requires large, properly licensed datasets; responsible deployment needs watermarking, moderation, and usage controls.
- Integration effort: Real-world adoption often requires custom kernels, plugin development, and infrastructure to orchestrate SP, KV-cache quantization, and streaming decode at scale.
Glossary
- Adaptive block scaling: A quantization technique that chooses per-block scaling factors to minimize quantization error. "We use adaptive block scaling via scale search to quantize NVFP4 weights and activations"
- All-to-All communication: A distributed communication pattern where each device exchanges data with all others. "after Ulysses All-to-All communication."
- Autoregressive (AR) training: Training that predicts the next tokens/chunks conditioned on previously generated ones. "we introduce sequence-parallel autoregressive (AR) training"
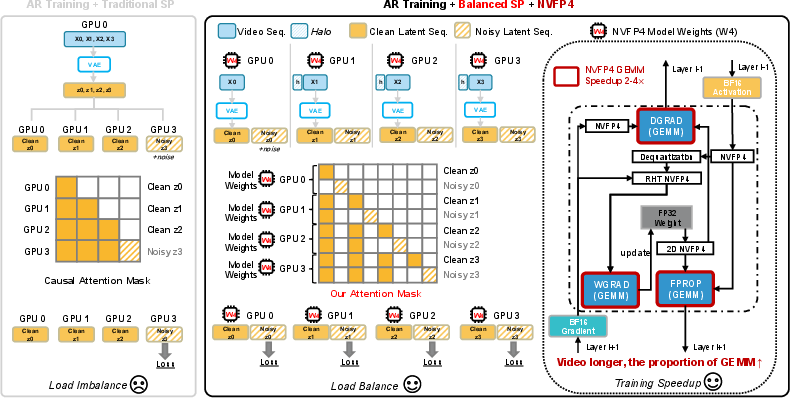
- Balanced SP: A sequence-parallel layout that assigns each GPU matching clean and noisy chunks to balance workload and avoid redundant preprocessing. "Balanced SP assigns each GPU the clean and noisy latents from the same temporal chunk."
- BF16: A 16-bit floating-point format (bfloat16) used for efficient training/inference with wide dynamic range. "NVFP4 preserves the overall scene composition, subject structure, and shot-level semantics of the BF16 baseline."
- Blackwell GPUs: NVIDIA’s GPU architecture generation with native NVFP4 support for low-precision acceleration. "On the inference side, Blackwell GPUs allow full NVFP4 alignment between training and inference for highly efficient W4A4 inference"
- Block-sparse AR mask: An attention mask with structured sparsity that restricts attention to relevant blocks for AR training. "A block-sparse AR mask lets each noisy chunk attend to preceding clean chunks and its own noisy tokens"
- Cross-attention: Attention mechanism that conditions generation on external inputs (e.g., text prompts). "Cross-attention is factorized per chunk as \text{CrossAttn}(\mathbf{Z}_i, \mathbf{T}_i)"
- Cross-attention cache: Stored key/value states for cross-attention reused across steps to reduce computation. "re-initializes the subsequent cross-attention cache"
- CUDA dequantization kernel: A GPU kernel that reconstructs low-precision tensors back to higher precision during inference/training. "we therefore implement a customized parallel CUDA dequantization kernel for efficient in-window reconstruction"
- DeepSpeed-Ulysses: A system for sequence parallelism and efficient all-to-all communication in long-sequence transformers. "We therefore co-design the AR training layout with the sequence-parallel data layout and instantiate it as Balanced SP on top of DeepSpeed-Ulysses"
- Diffusion Transformer (DiT): A transformer-based architecture for diffusion models. "Using to denote the DiT sequence after patch embedding"
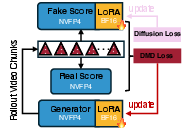
- Distribution Matching Distillation (DMD): A distillation method aligning student and teacher distributions for few-step generation. "distribution matching distillation (DMD)"
- E2M1 (FP4 format): A 4-bit floating-point format with 2 exponent bits and 1 mantissa bit used in NVFP4. "NVFP4 represents each tensor element using a 4-bit floating-point value in the E2M1~\cite{ocp2023mx} format together with hierarchical scaling"
- E4M3 (FP8 format): An 8-bit floating-point format with 4 exponent bits and 3 mantissa bits used for block scales. "stored in FP8 E4M3"
- Fake-Score model: The learned critic in DMD that guides the student by approximating the teacher’s score. "The trainable Fake-Score model and Generator use the same W4A4 NVFP4 backbone"
- Flex attention: A programming model/library for generating optimized attention kernels. "we construct the AR mask directly on this communication-native order and compile it with flex_attention"
- GEMM: General matrix–matrix multiplication; a core compute kernel for linear layers and attention. "accelerates GEMM computation during training"
- Halo (temporal): Extra context frames added around chunk boundaries to cover a model’s receptive field. "plus a left halo that covers the VAE temporal receptive field"
- Head dimension: The dimensionality of each attention head in multi-head attention. "and be the head dimension."
- Hierarchical scaling: Multi-level scaling (e.g., tensor-wise and block-wise) used to dequantize low-precision values. "together with hierarchical scaling"
- K-smoothing: Mean-centering of key vectors before quantization to improve robustness. "For keys, we first apply a simple -smoothing:"
- KV cache: Stored keys and values from previous tokens/frames used to speed up autoregressive attention. "we further quantize the KV cache into NVFP4 for substantial memory savings"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank adapters into layers. "It can be further converted to real-time generation (4 to 2 denoising steps) with standalone LoRA weights."
- Multi-shot attention sink: A dual-anchor attention strategy with global and per-shot sinks to preserve identity and local coherence. "we introduce a multi-shot attention sink with two cooperating anchor sets"
- NVFP4: NVIDIA’s FP4 format and training/inference stack using hierarchical scaling for low-precision efficiency. "We present LongLive-2.0, an NVFP4-based parallel infrastructure"
- Patch embedding: The transformation of spatiotemporal patches into token embeddings for transformer inputs. "Using to denote the DiT sequence after patch embedding"
- Post-training quantization (PTQ): Quantization applied after training without retraining the model. "quantization-based methods only adopt post-training quantization (PTQ)"
- Random Hadamard Transform (RHT): A randomized orthogonal transform used to stabilize low-bit gradient computations. "notably Random Hadamard Transform (RHT) before quantization on the operands of the weight-gradient GEMM."
- Real-Score model: The teacher (reference) score network evaluated in low precision during DMD. "The Real-Score model is quantized to W4A4 for NVFP4 inference."
- Scale search: A procedure that tries alternative target magnitudes to choose the lowest-error quantization scale. "We use adaptive block scaling via scale search"
- Sequence parallelism (SP): Distributed execution that shards sequence tokens across devices to fit memory and scale compute. "Naively applying SP to AR video training leaves two inefficiencies."
- Sliding-window self-attention: Self-attention limited to a moving window to bound compute and memory in long sequences. "we adopt sliding-window self-attention with KV caching to cap the per-step compute footprint"
- Teacher forcing: Training strategy that conditions on ground-truth history instead of model predictions to avoid compounding errors. "We use clean-context teacher forcing rather than diffusion forcing to avoid the train-test gap"
- Ulysses All-to-All: The specific all-to-all communication mechanism used by DeepSpeed-Ulysses for sequence sharding. "After Ulysses All-to-All, the paired layout naturally produces an interleaved global token order."
- Variational Autoencoder (VAE): A generative model used here for latent video encoding/decoding around the diffusion transformer. "The final variational autoencoder (VAE) decoding step is often a major bottleneck in video generation."
- W4A4: 4-bit weights and 4-bit activations configuration for low-precision inference/training. "we enable W4A4 NVFP4 inference"
Collections
Sign up for free to add this paper to one or more collections.