Live Avatar: Streaming Real-time Audio-Driven Avatar Generation with Infinite Length
Abstract: Existing diffusion-based video generation methods are fundamentally constrained by sequential computation and long-horizon inconsistency, limiting their practical adoption in real-time, streaming audio-driven avatar synthesis. We present Live Avatar, an algorithm-system co-designed framework that enables efficient, high-fidelity, and infinite-length avatar generation using a 14-billion-parameter diffusion model. Our approach introduces Timestep-forcing Pipeline Parallelism (TPP), a distributed inference paradigm that pipelines denoising steps across multiple GPUs, effectively breaking the autoregressive bottleneck and ensuring stable, low-latency real-time streaming. To further enhance temporal consistency and mitigate identity drift and color artifacts, we propose the Rolling Sink Frame Mechanism (RSFM), which maintains sequence fidelity by dynamically recalibrating appearance using a cached reference image. Additionally, we leverage Self-Forcing Distribution Matching Distillation to facilitate causal, streamable adaptation of large-scale models without sacrificing visual quality. Live Avatar demonstrates state-of-the-art performance, reaching 20 FPS end-to-end generation on 5 H800 GPUs, and, to the best of our knowledge, is the first to achieve practical, real-time, high-fidelity avatar generation at this scale. Our work establishes a new paradigm for deploying advanced diffusion models in industrial long-form video synthesis applications.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces “Live Avatar,” a system that can turn a live audio stream (like someone speaking into a microphone) into a realistic talking video avatar in real time, and keep it going smoothly for as long as you want—even for hours. It focuses on making the avatar look sharp, move naturally, sync its lips to the audio, and stay consistent over long periods (no drifting face or weird colors), all while running fast enough to be used live.
What questions does the paper try to answer?
To make live avatars practical, the authors aim to solve two big problems:
- How can we keep high visual quality while generating video fast enough for real-time use?
- How can we keep the person’s identity and appearance stable over very long videos without slowly drifting or changing?
How does the system work? (Explained with simple ideas)
Live Avatar is built on “diffusion models,” a type of AI that creates images or video by starting with random noise and gently removing that noise step by step until a clear picture appears—like cleaning a foggy window one wipe at a time. That’s great for quality, but it can be slow, because there are many “denoising steps.”
To make this fast and steady, the paper combines three key ideas:
Timestep-forcing Pipeline Parallelism (TPP)
Think of an assembly line:
- Instead of one machine doing all the cleaning steps one after another, the system spreads the steps across multiple GPUs (powerful computer chips).
- Each GPU is in charge of one fixed step (like “step 4 always happens on GPU #4”).
- The video frames flow through the GPUs like cars through an assembly line. Once the line is full, every GPU is always busy, so the whole system speeds up.
Why it helps:
- This breaks the usual bottleneck of diffusion models needing to do steps in strict sequence.
- The system reaches real-time speed (20 frames per second) even with a very large, high-quality model.
Rolling Sink Frame Mechanism (RSFM)
Imagine having a “reference photo” of the avatar that reminds the AI what the person should look like:
- The system keeps a special frame (the “sink frame”) that locks in the person’s identity (face, colors, overall look).
- As the video runs, it smartly updates and re-aligns this reference so it always matches the current scene and timing.
- This prevents long-term problems like the face slowly changing shape or colors drifting over time.
Why it helps:
- Keeps the avatar recognizable and stable, even over hours of generation.
Self-Forcing Distribution Matching Distillation
This is a teacher–student training trick:
- A big, slow “teacher” model shows a smaller “student” how to produce similar results with fewer steps.
- The student is trained to work in a “causal” way (it only looks at past frames, not future ones), which is necessary for live streaming.
- The training includes noisy memories of past frames (like slightly messy notes), so the student becomes robust and doesn’t break down in long videos.
Why it helps:
- The student model runs faster while keeping high visual quality.
- It matches the teacher’s “style” and realism without needing all the teacher’s slow steps.
What did they find?
- Live Avatar runs at 20 FPS (frames per second) using 5 H800 GPUs, which is fast enough for real-time streaming.
- It uses a large 14-billion-parameter diffusion model without sacrificing quality.
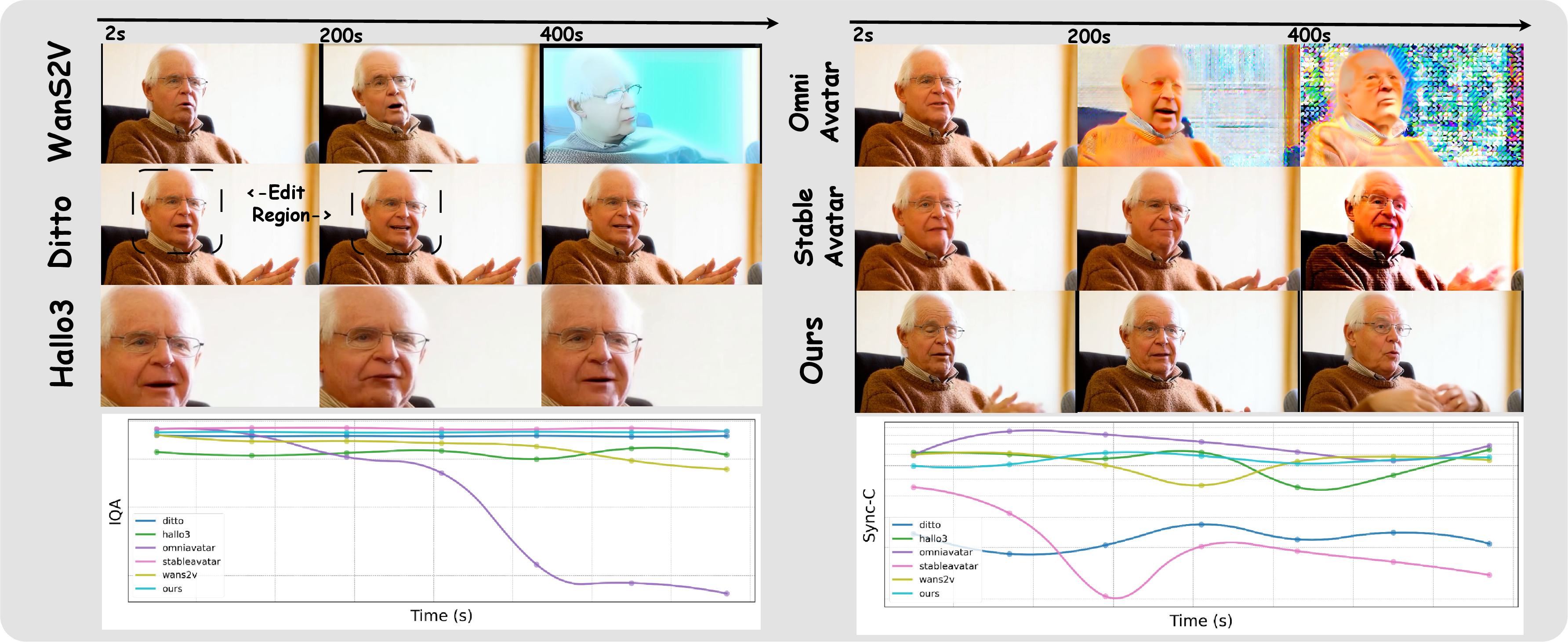
- It keeps the avatar consistent over long periods—reducing “identity drift” (the face changing) and color issues.
- In tests, it outperformed or matched other top methods in video quality and sync, especially on long videos.
- User studies showed the videos look natural and stay coherent, not just “lip-sync good” but overall movement and expressions sensible.
Why it matters:
- Most live avatar systems have had to choose between “fast but low quality” and “beautiful but too slow.” Live Avatar shows you can have both: real-time speed and high fidelity, even over very long streams.
What does this mean for the future?
- Better live digital humans: More realistic virtual hosts, teachers, support agents, game characters, and streamers.
- Long live shows without glitches: You can run a digital avatar for hours, and it keeps looking like the same person.
- Industrial uses: The techniques (especially the pipeline design) show how to deploy large diffusion models in real-time settings, opening the door to practical products.
Simple note on limitations:
- The time-to-first-frame (the delay before the very first frame appears) still needs improvement for snappier interactions.
- The system relies on the rolling sink frame to stay stable; super complex scenes may still be challenging.
Overall: Live Avatar combines smart training (teacher–student distillation), clever system design (GPU “assembly line”), and a steady identity anchor (sink frame) to make high-quality, real-time, long-form talking avatars possible.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to enable concrete follow-up research:
- Time-to-first-frame (TTFF) remains high: TPP improves throughput (FPS) but does not reduce TTFF; explore prefill/warm-start strategies, speculative decoding, or partial early-exit sampling to reduce end-to-first-frame latency for interactive use.
- Robustness of RSFM in complex settings is unclear: Identify failure modes when the rolling sink frame conflicts with rapid pose changes, occlusions, lighting shifts, or camera cuts; develop adaptive re-anchoring or multi-reference strategies with automatic triggers.
- Sink-frame update policy design: The method replaces the sink with the first generated frame; evaluate alternative policies (periodic refresh, quality-triggered refresh, identity similarity-based refresh) and their impact on identity stability vs. drift.
- Generalization beyond AVSpeech: Training is limited to AVSpeech; test on more diverse, in-the-wild corpora with varied head/body motion, camera framing, and environments to assess domain robustness.
- Synthetic OOD benchmark validity: GenBench is synthetic and lacks ground-truth videos; establish real, public long-form benchmarks with human subjects, ground-truth references, and identity annotations to evaluate identity consistency and perceptual realism over hours.
- Identity consistency measurement: Current metrics (ASE, IQA, Sync-C/D, DINO-S) inadequately capture long-horizon identity stability; design and validate identity drift metrics sensitive to subtle, cumulative deviations.
- User study scale and scope: The user study involves 20 participants; replicate with larger, more diverse cohorts, controlled protocols, and task-driven evaluations (e.g., intelligibility, perceived latency, presence) to validate perceptual claims.
- Audio robustness: No evaluation under realistic audio degradations (noise, reverberation, bandwidth limits, packet loss, clock drift); benchmark A/V sync, expressiveness, and intelligibility under adverse audio conditions and streaming jitter.
- Multilingual and prosody coverage: Assess cross-lingual generalization, code-switching, singing, emotional/prosodic diversity, and mapping accuracy from audio prosody to facial expressions beyond lip-sync.
- Full-body and gesture fidelity: Although some results include half/full body, training predominantly uses talking-head data; quantify and improve body/hand motion naturalness, temporal coherence, and camera framing robustness.
- Expressive control and editability: The model accepts text prompts and audio but lacks explicit controls for emotion, style, gaze, and head pose; investigate disentangled controls and guardrails for predictable, user-driven behaviors.
- TPP scalability and fault tolerance: TPP assumes fixed per-GPU timesteps; analyze performance under heterogeneous GPUs, stragglers, and GPU failures; study scheduling policies, elastic scaling, and micro-batching for multi-tenant settings.
- Multi-node deployment: TPP is described for multi-GPU (likely single-node) setups; characterize inter-node latency, bandwidth needs, and pipeline efficiency over fabric (e.g., NVLink vs. InfiniBand), and propose communication-aware scheduling.
- VAE decoding as a bottleneck: VAE decode is identified as a latency limiter; explore VAE distillation, neural codecs, or partially decoded preview frames to reduce decode latency without sacrificing quality.
- Memory and KV-cache management: Long-horizon rolling KV caches may hit memory ceilings; study window-length/quality trade-offs, cache compression/quantization, eviction policies, and their effects on coherence.
- Same-timestep vs. clean KV-cache theory: The empirical advantage of same-noise KV caches is reported; provide principled analysis or theoretical justification and delineate regimes where clean caches may help (e.g., small NFE, higher SNR steps).
- Distillation compute cost: Training requires ~500 GPU-days; investigate compute-efficient alternatives (teacher-free distillation, trajectory subsampling, curriculum NFE schedules, progressive pruning/quantization) with quantified trade-offs.
- Step-count vs. quality frontier: The paper fixes NFE to 4–5; map the Pareto front between NFE, quality (identity, sync), and latency to guide deployment choices across hardware tiers.
- Applicability to other backbones and VAEs: The method inherits Wan-S2V architecture; validate generality on different DiT variants, latent spaces (e.g., different 3D VAEs), and alternative positional encodings beyond RoPE.
- Long-run stability beyond single sink: Rolling RoPE aligns the sink across time; test whether multi-anchor identity embedding (e.g., learned identity tokens or face-ID vectors) improves stability under large pose/illumination changes.
- Failure cases and diagnostics: Provide systematic failure analyses (fast motion, profile views, occlusions, accessories, extreme lighting, background motion) and tools to detect impending drift for proactive correction.
- Edge and low-resource deployment: The system targets 5×H800 GPUs; benchmark on lower-tier GPUs/edge devices, evaluate quantization (W4–W8), activation/kv quantization, and mixed-precision impacts on quality and latency.
- Energy and cost profiling: Report energy consumption and $/hour for real-time streaming; explore energy-aware scheduling, dynamic NFE, and adaptive framerate under load to reduce operational cost.
- Real-time streaming integration: End-to-end latency with audio capture, VAD, network stack, and rendering is not reported; build an RTC pipeline and quantify holistic QoE (glass-to-glass latency, jitter tolerance).
- Safety, consent, and provenance: Technical mechanisms (watermarking, on-device liveness checks, identity-consent verification, tamper-evident logs) are not integrated; evaluate robustness of watermarks under compression and adversarial edits.
- Deepfake detection interplay: Study whether RSFM/TPP impact detectability by current deepfake detectors; co-design generation that remains verifiable without degrading fidelity.
- Identity onboarding and personalization: Explore few-shot identity conditioning, rapid subject enrollment, and privacy-preserving fine-tuning (e.g., LoRA on-device) with safeguards against identity leakage.
- Content moderation and bias: Assess demographic/linguistic bias, failure disparities across skin tones, accents, headwear, and accessibility scenarios; devise datasets and metrics to audit and mitigate bias.
- Reproducibility and releases: The paper references a project page; clarify availability of code, inference pipelines for TPP/RSFM, pretrained weights, and standardized configs to enable independent verification.
- Benchmarking fairness: Baselines differ in model size, resolution, and hardware; provide normalized comparisons (e.g., matched resolution/FPS/compute) and statistical tests to support “state-of-the-art” claims.
- Extreme-duration validation: The supplement claims stability up to 10,000 seconds; release the full quantitative results and stress-test protocols, including memory behavior, drift curves, and catastrophic failure rates.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed with the paper’s current capabilities (real-time, infinite-length, audio-driven avatar generation at ~20 FPS on 5×H800 GPUs), along with sector tags, implementation notes, and feasibility assumptions.
- Live customer-support avatars — software/communications, retail, finance
- Description: Replace voice-only bots with photorealistic, lip-synced digital agents that speak and sustain identity coherently over long sessions.
- Tools/products/workflows: “Avatar-as-a-Service” API; WebRTC streaming pipeline; TPP-enabled inference cluster; CRM integration for context.
- Assumptions/dependencies: Multi-GPU (≥5×H800 per high-fidelity stream at 720×400), robust audio ASR/NLU backends; consent and watermarking for synthetic media; TTFF ~3 s may need UI mitigation (e.g., pre-roll).
- VTubers and live entertainment — media/creator economy
- Description: Real-time avatars for live streaming (Twitch, YouTube Live), sustaining identity and aesthetics for hours.
- Tools/products/workflows: OBS/Streamlabs plugin; avatar studio app; RSFM-enabled long-run mode; audio-to-avatar pipeline with TPP.
- Assumptions/dependencies: GPU budget per stream; background compositing pipeline; clear policy labels for synthetic broadcast.
- Real-time localization/dubbing previews — media/localization
- Description: Interactive lip-synced previews for dubbing sessions; directors and linguists can iterate quickly.
- Tools/products/workflows: NLE integration (Premiere/Resolve plugin); preview server using TPP; RSFM to avoid identity/color drift in extended takes.
- Assumptions/dependencies: 720×400 output may need upscaling; studio-grade output requires post-processing; rights to reanimate faces.
- Privacy-preserving video calling — workplace software
- Description: Replace camera feed with a persistent avatar (user-provided reference) driven by voice during meetings, maintaining identity without raw video exposure.
- Tools/products/workflows: Zoom/Teams plugin; identity enrollment flow; RSFM for consistent appearance; watermark/marker overlays.
- Assumptions/dependencies: Enterprise policy approvals; compute either cloud-side or powerful local GPU; TTFF and initial enrollment latency.
- Digital signage and kiosks — retail, public services, travel
- Description: In-mall or airport assistant avatars that respond to voice queries for extended shifts without visual degradation.
- Tools/products/workflows: Edge server with TPP; kiosk HMI; knowledge-base integration; RSFM to suppress drift; audio front-end with beamforming mics.
- Assumptions/dependencies: On-prem GPU clusters; robust noise cancellation; security hardening; signage compliance guidelines.
- E-learning presenters and micro-courses — education
- Description: Teachers or institutions generate live or recorded lessons with expressive avatars, synchronized to voice scripts.
- Tools/products/workflows: LMS plugin; text-to-speech + avatar pipeline; batch rendering or streaming; RSFM for long lectures.
- Assumptions/dependencies: Instructor consent for identity use; GPU scheduling for live classes; content watermarking for provenance.
- Accessibility aids (visual speech cues) — healthcare, daily life
- Description: Audio-driven avatars offering clear lip cues for individuals with hearing loss or auditory processing challenges.
- Tools/products/workflows: Companion app; real-time transcription + avatar; RSFM for stability over conversations; integration with hearing aids or AR.
- Assumptions/dependencies: Medical-grade UX requirements; edge compute or low-latency cloud; privacy and HIPAA-like compliance where relevant.
- Media previsualization and previz boards — film/TV production
- Description: Rapid, long-form previz of talking scenes to plan blocking, pacing, and style before full VFX.
- Tools/products/workflows: Studio pipeline nodes; TPP inference farm; RSFM to avoid identity drift across scene beats; shot management tooling.
- Assumptions/dependencies: Moderate resolution; creative review loops; licensing and identity permissions.
- Contact center quality monitoring with synthetic faces — operations, compliance
- Description: Convert audio-only calls into anonymized avatar videos for quality audits and training while avoiding real face capture.
- Tools/products/workflows: Batch pipeline; configurable generic identities; RSFM for multi-hour calls; watermarking and audit logs.
- Assumptions/dependencies: Policy support for synthetic audit media; compute costs for at-scale conversion; privacy-by-design practices.
- ML platform optimization using TPP — software, cloud/ML infra
- Description: Adopt TPP to pipeline diffusion steps across GPUs for other video/image diffusion workloads to cut latency bottlenecks.
- Tools/products/workflows: Inference server implementing TPP; same-timestep KV cache design; VAE offload GPU; monitoring for TTFF vs throughput.
- Assumptions/dependencies: Models must support noise-aligned KV use; NVLink/fast interconnect improves handoff latency; engineering to integrate.
- Drift suppression module (RSFM) for existing video generators — software, media tech
- Description: Integrate RSFM and Rolling RoPE into third-party diffusion/DiT pipelines to reduce identity/color drift in long videos.
- Tools/products/workflows: RSFM middleware; sink-frame management; RoPE adjustment service; alignment tests for model compatibility.
- Assumptions/dependencies: Access to KV caches and positional encoding; model architecture should tolerate sink-frame substitution.
Long-Term Applications
Below are applications that require further research, scaling, or engineering (e.g., smaller models, integration with additional modalities, policy frameworks, or consumer-grade deployment).
- Codec Avatars for bandwidth-light video calls — software/communications
- Description: Send only audio + lightweight control signals; reconstruct realistic avatars at the receiver, dramatically reducing bandwidth.
- Tools/products/workflows: Sender-side audio encoders; receiver-side avatar generator; streaming protocols; client GPU or specialized accelerators.
- Assumptions/dependencies: Student models distilled to fit consumer hardware; robust real-time watermarking and authenticity indicators.
- Multilingual real-time dubbing with expressive alignment — media/localization, education
- Description: Integrate translation/TTS and emotion prosody to produce natural cross-lingual lip-sync avatars live.
- Tools/products/workflows: Translation + TTS engines; emotion prosody estimation; avatar orchestration; QA for cultural/phonetic fidelity.
- Assumptions/dependencies: High-quality prosody transfer; bias/fairness audits across languages; compute budget per session.
- Full-body and embodied avatars — gaming, robotics, telepresence
- Description: Extend beyond head/face to whole-body motion with consistent identity over hours, enabling embodied NPCs and telepresence robots.
- Tools/products/workflows: Multimodal motion capture or audio-to-body models; 3D kinematics; environment-aware rendering; RSFM generalization to body identity.
- Assumptions/dependencies: Datasets for long-form body motion; performance at higher resolution; latency constraints for robotics control.
- Consumer-grade deployment on laptops/phones — software, daily life
- Description: Make avatars run locally with acceptable quality using smaller, quantized student models and hardware acceleration.
- Tools/products/workflows: Aggressive distillation/quantization; mobile GPU/NPU offloading; dynamic-step inference; thermal and battery management.
- Assumptions/dependencies: New training regimes maintaining quality at small scales; vendor acceleration (Apple/Qualcomm/NVIDIA Jetson).
- Telemedicine digital clinicians and care companions — healthcare
- Description: Realistic, long-duration avatar clinicians for triage, follow-ups, and health education with empathetic cues.
- Tools/products/workflows: Clinical NLU; safety rails; verified identity frameworks; audit trails; low-latency cloud or edge nodes in hospitals.
- Assumptions/dependencies: Regulatory approval; rigorous safety testing; integration with EHR; accessibility features.
- Personalized tutors and coaching avatars — education, HR/L&D
- Description: Individualized long-form coaching with natural expressions, sustained identity, and real-time responsiveness.
- Tools/products/workflows: Adaptive learning stack; tutor profile enrollment; TPP-backed cloud; fairness and pedagogical effectiveness studies.
- Assumptions/dependencies: Proven pedagogy; explainability; accessibility accommodations; lower-cost inference for scale.
- Synthetic media provenance and governance — policy, platform trust & safety
- Description: Standards and tooling for watermarking, disclosure, consent management, and misuse detection for audio-driven avatars.
- Tools/products/workflows: Embedded watermarks resilient to compression; disclosure UX; consent registries; synthetic-media detection services.
- Assumptions/dependencies: Multi-stakeholder standardization; legal frameworks; interoperable provenance metadata.
- Avatar-based accessibility in AR wearables — healthcare, XR
- Description: On-glasses visualization of lip cues and expressive avatars for noisy environments and hearing assistance.
- Tools/products/workflows: AR runtime; low-latency edge offload; miniaturized accelerators; RSFM tuned for wearable constraints.
- Assumptions/dependencies: Hardware form-factor; low-power inference; safe and comfortable UX.
- Long-form content automation (podcasts, lectures, audiobooks) — media/education
- Description: Auto-generate avatar video from long audio assets with consistent identity and style templates.
- Tools/products/workflows: Batch pipelines; template libraries; style transfer modules; quality control and post-production hooks.
- Assumptions/dependencies: Scalable cluster scheduling; rights to identity/style use; editorial approval workflows.
- Enterprise “digital human” portals — software/enterprise IT
- Description: Company-wide portals where verified avatars deliver announcements, policy updates, and training at scale.
- Tools/products/workflows: Identity verification; HR/IT integration; content approval pipelines; uptime SLAs for streaming services.
- Assumptions/dependencies: Organizational buy-in; cost models; robust governance to prevent impersonation.
- Safety-critical training simulations — defense, emergency services
- Description: Realistic human avatars for long, stressful training scenarios with stable identities and visual coherence.
- Tools/products/workflows: Scenario generation; multi-user synchronization; compliance with training standards; after-action review tooling.
- Assumptions/dependencies: Domain-specific datasets; controlled environments; strict access and audit controls.
- Generalized diffusion inference acceleration using TPP — ML research/industry
- Description: Adapt TPP and same-timestep KV strategies to other diffusion domains (e.g., text-to-video, image editing), improving throughput without sacrificing quality.
- Tools/products/workflows: TPP libraries; scheduler abstractions; benchmarking harnesses; guidelines for KV noise alignment.
- Assumptions/dependencies: Architectural compatibility; careful validation of quality under pipelining; hardware interconnect performance.
Notes on Assumptions and Dependencies
- Compute and latency:
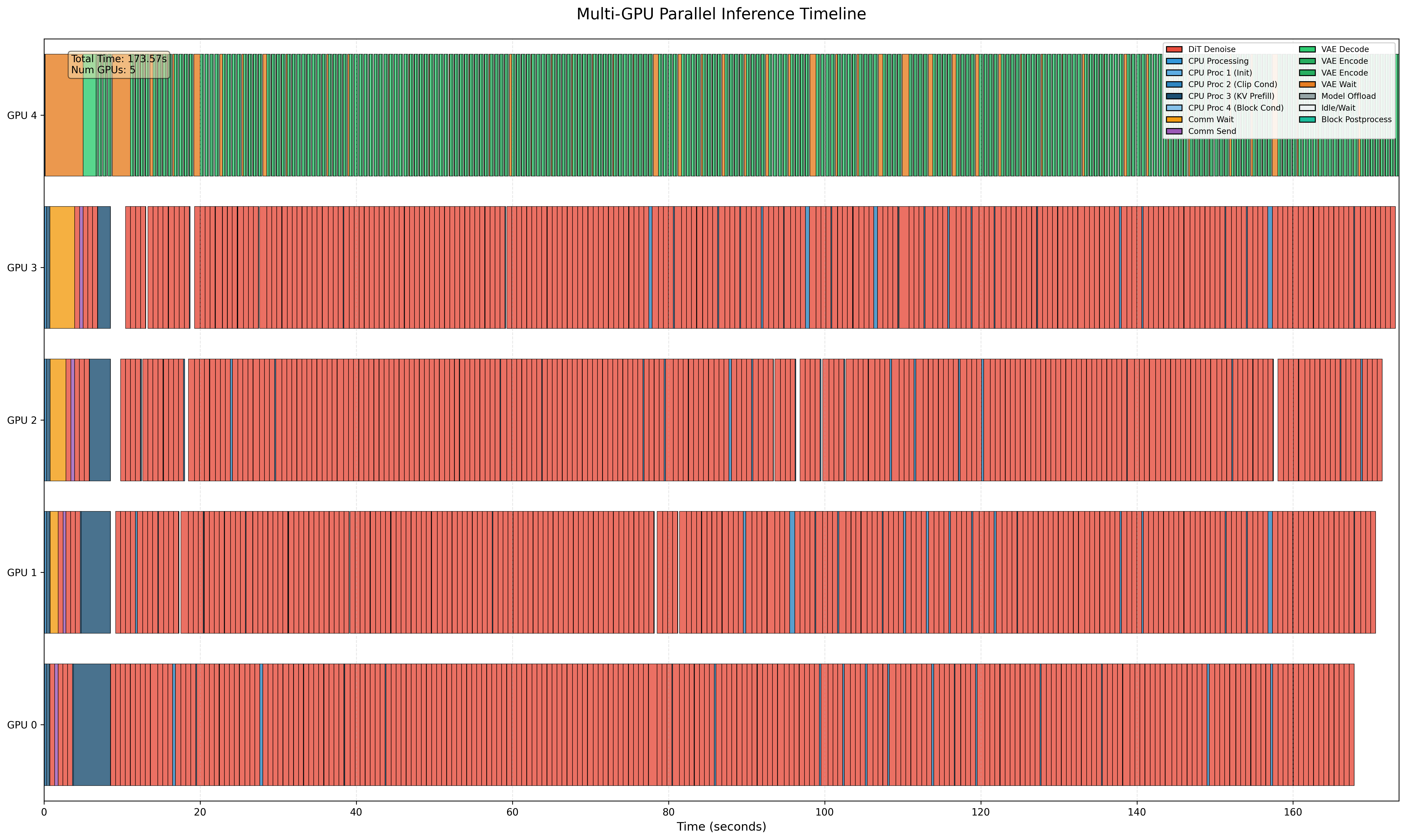
- Current real-time performance (~20 FPS) is demonstrated at 720×400 resolution on 5×H800 GPUs; TTFF is ~2.9 s and may affect interactive feel.
- VAE decode is a bottleneck; offloading to separate GPU is recommended.
- Model design and training:
- Same-timestep KV cache alignment is a key architectural assumption for TPP and quality; switching to clean KV caches reduces throughput and may hurt perceptual quality.
- RSFM and Rolling RoPE are crucial for long-horizon identity/semantic stability.
- Data rights and ethics:
- Use of real identities requires consent, provenance tracking, and watermarking; policy frameworks should address impersonation risks.
- Integration:
- Real-world deployments need audio ASR/NLU, TTS (for scripted content), and streaming infrastructure (WebRTC/CDN).
- For mass scale, further distillation/quantization and hardware acceleration are necessary to reduce per-stream GPU costs.
Glossary
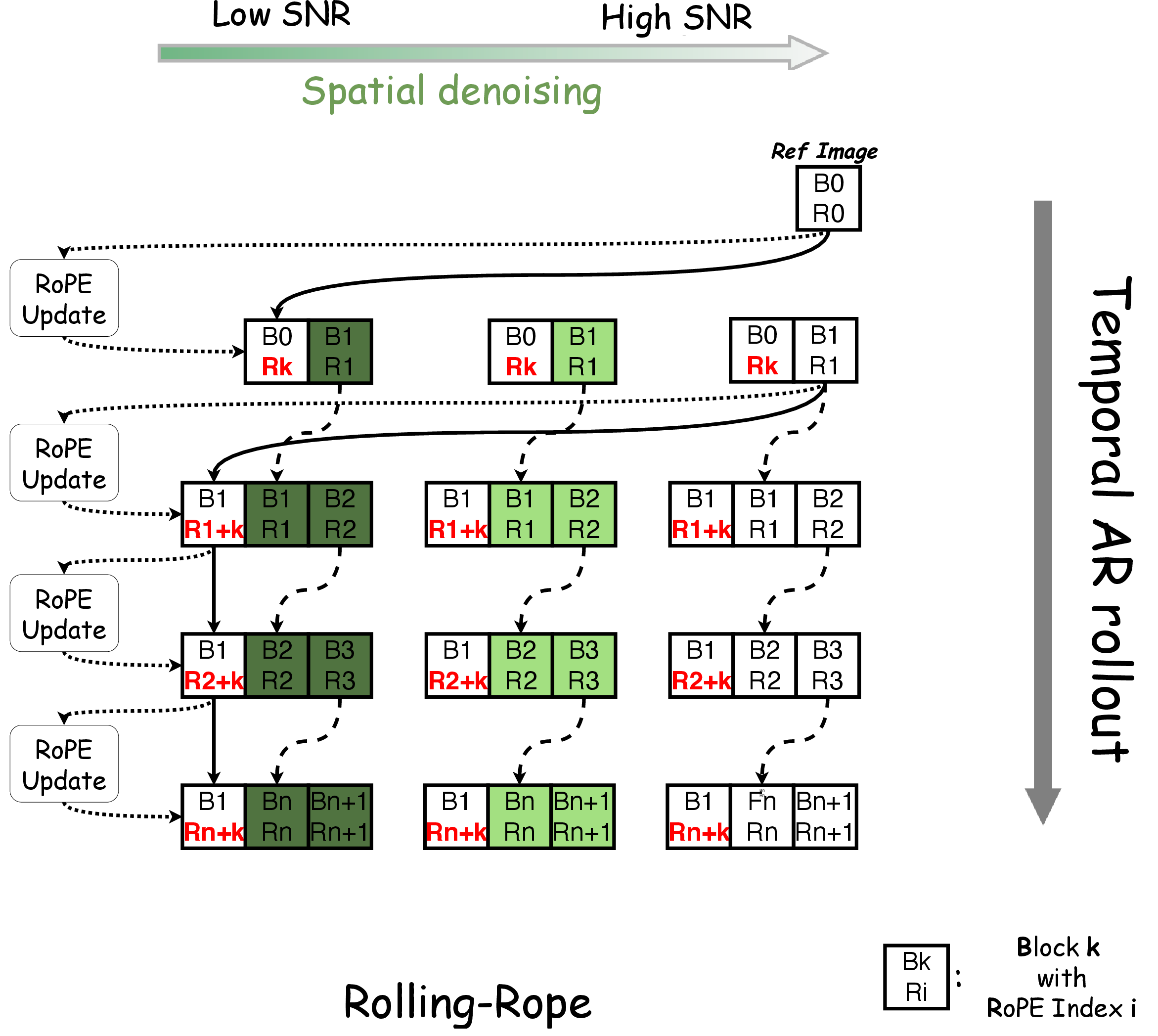
- Adaptive Attention Sink (AAS): A strategy that replaces the original reference frame with the model’s first generated frame to keep conditioning within the learned distribution and stabilize long-term generation. "To counteract distribution drift, we propose Adaptive Attention Sink (AAS)"
- attention sink mechanisms: Techniques that provide stable attention anchors in long sequences to reduce errors and improve coherence. "Rolling Forcing~\cite{liu2025rolling} proposes rolling window joint denoising and attention sink mechanisms for reduced error and improved coherence."
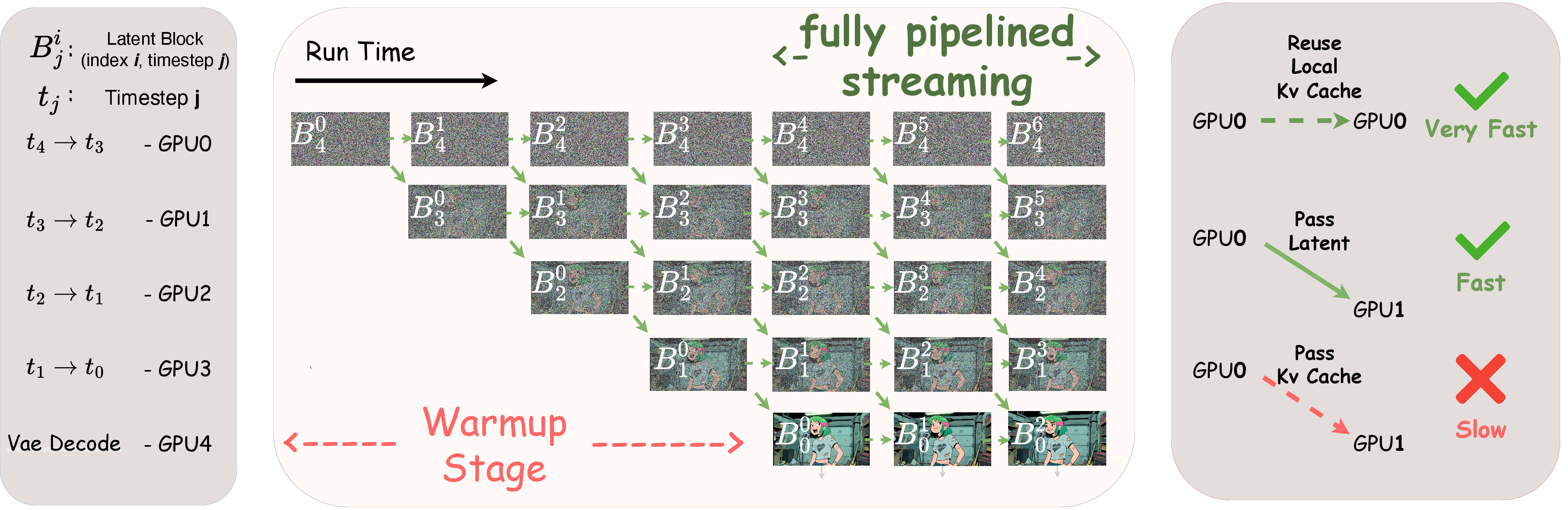
- autoregressive denoising bottleneck: The latency constraint caused by diffusion models’ need to perform denoising steps sequentially, limiting throughput. "This approach breaks the autoregressive denoising bottleneck inherent to diffusion models"
- autoregressive generation: A generation process where each output step conditions on previously generated outputs to produce the next. "the Live Avatar adopt autoregressive generation"
- Block-wise Gradient Accumulation: A training strategy that accumulates gradients across blocks of frames to manage memory use while maintaining learning efficacy. "Block-wise Gradient Accumulation training strategies"
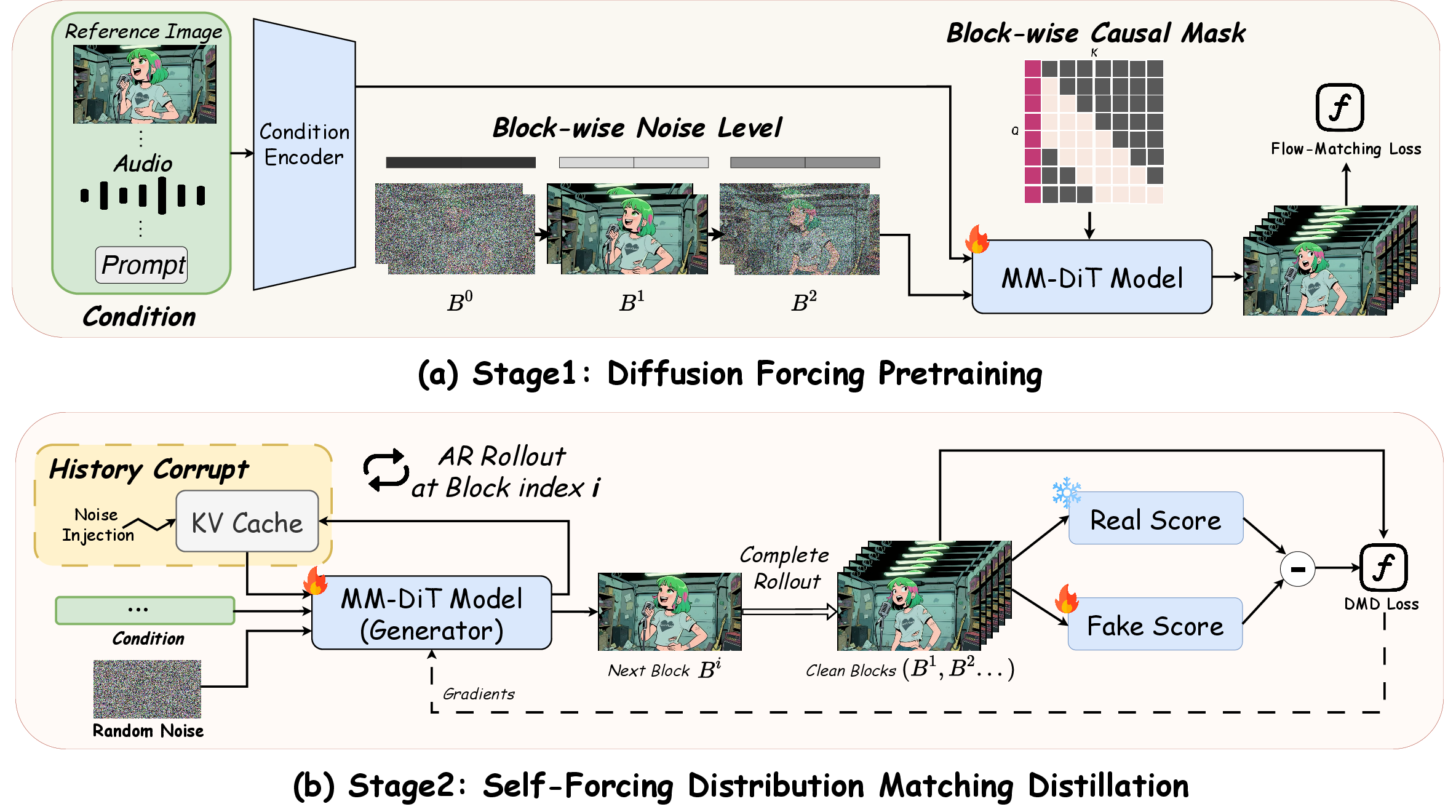
- causal 3D VAE: A video autoencoder that encodes/decodes temporally while preventing future-frame information leakage during training. "We use a causal 3D VAE to encode input videos into temporal-latent representations, ensuring that future frames do not leak during training."
- causal masks: Attention masks enforcing that each block or token only attends to past context, enabling causal inference. "We apply causal masks during training following CausVid\cite{yin2025slow} and X-Streamer\cite{xie2025x}."
- clean-kv-cache: A setting where attention keys/values are kept in a unified, fully denoised cache rather than at the same noise level as current latents. "Clean-kv-cache, where all latents attend to a unified clean cache"
- compressed latent space: A reduced-dimensional representation in which diffusion operates to lower computation cost. "most modern video diffusion models operate in a compressed latent space."
- Consistency Models: Distillation methods that train generators to produce consistent outputs in one or a few steps. "Consistency Models\cite{song2023consistency,zheng2025large,lu2024simplifying}"
- DINOv2 similarity: A semantic consistency metric based on DINOv2 features, often reported as Dino-S. "drop in the DINOv2 similarity metric."
- Diffusion Forcing: A training approach that introduces structured noise into targets to enable longer and more stable generation. "Stage 1 Diffusion Forcing Pretraining"
- Distribution Matching Distillation (DMD): A distillation technique minimizing divergence between student and teacher diffusion distributions at each timestep to enable few-step sampling. "Distribution Matching Distillation (DMD)\cite{yin2024one} aims to distill a pre-trained teacher diffusion model into a student model that operates with fewer sampling steps."
- FID: Fréchet Inception Distance; a metric for image-level quality comparing generated and real distributions. "frame-level image quality using FID"
- flow matching: A continuous-time training objective that matches a velocity field to transport noise to data, used as an alternative to standard diffusion loss. "we adopt the flow matching~\cite{lipman2022flow}"
- FSDP: Fully Sharded Data Parallel; a distributed training method that shards model states across devices to reduce memory. "we adopt FSDP with gradient accumulation"
- FVD: Fréchet Video Distance; a metric for video-level temporal coherence and quality. "overall video coherence with FVD"
- History Corrupt: A robustness technique that injects random noise into historical KV caches during distillation to prevent error accumulation. "removing both the Adaptive Attention Sink and the History Corrupt strategy leads to a sharp decline"
- IQA: Image Quality Assessment; a perceptual quality score for frames or videos. "perceptual quality (IQA)"
- KV cache: The stored keys and values from attention layers used to efficiently reuse context across timesteps/blocks. "KV cache"
- KV-recache mechanism: A streaming strategy that refreshes or rebuilds the KV cache to extend temporal horizons. "LongLive~\cite{yang2025longlive} uses a KV-recache mechanism and short window attention"
- KullbackâLeibler (KL) divergence: A measure of distributional difference; DMD uses the reverse KL to match student to teacher distributions. "reverse KullbackâLeibler (KL) divergence"
- LoRA: Low-Rank Adaptation; a parameter-efficient finetuning method that injects small trainable matrices into large models. "We train models with a LoRA, whose rank and alpha are set to 128 and 64, respectively."
- long-horizon: Refers to very long or infinite-length generation requiring sustained temporal stability. "The second challenge is the long-horizon consistency."
- NFE: Number of Function Evaluations; the count of denoising steps or network calls in sampling, directly affecting speed. "number of function evaluations (NFE)"
- Q-align: A model-based assessor used to evaluate perceptual quality (IQA) and aesthetic appeal (ASE). "we employ the Q-align\cite{qalign} model to evaluate the final video's perceptual quality (IQA) and aesthetic appeal (ASE)."
- Rolling RoPE: A mechanism that dynamically shifts positional embeddings so the sink frame remains properly aligned with current timesteps during long generation. "we introduce Rolling RoPE"
- Rolling Sink Frame Mechanism (RSFM): A method that periodically reuses and realigns a reference frame to suppress identity drift and color artifacts over long sequences. "Rolling Sink Frame Mechanism (RSFM)"
- rolling-KV-cache: A practice of maintaining and advancing the KV cache across autoregressive steps to extend temporal context. "rolling-KV-cache~\cite{huang2025self}"
- RoPE: Rotary Position Embeddings; a positional encoding scheme enabling relative position awareness in attention. "controllable RoPE shift"
- score functions: Gradients of the log-density w.r.t. inputs; in DMD, real and fake score functions guide distribution matching. "score functions corresponding to the pre-trained teacher diffusion model and the student generator"
- Self-Forcing: A training paradigm that conditions on previously generated frames to reduce exposure bias and align train/inference behavior. "self-forcing paradigm"
- Self-Forcing Distribution Matching Distillation: A distillation framework that combines self-conditioning with DMD to produce a causal few-step student. "Self-Forcing Distribution Matching Distillation"
- sequence parallelism: A multi-GPU scheme that splits sequences across devices; here contrasted with TPP for efficiency. "sequence parallelism of 4 GPUs"
- sink frame: A designated appearance reference frame cached for conditioning to preserve identity across generation. "The sink frame is permanently cached in KV cache"
- Sync-C: A metric for audio-visual synchronization measuring lip-to-audio correspondence. "Sync-C"
- Sync-D: A synchronization metric capturing temporal deviation between audio and visual motion. "Sync-D"
- TDM: Trajectory-aware Distribution Matching; extends DMD to multi-step distillation with trajectory awareness. "TDM\cite{luo2025learning} establishes a trajectory-aware distribution matching framework"
- Timestep-forcing Pipeline Parallelism (TPP): A distributed inference scheme that assigns fixed timesteps to GPUs, turning sequential denoising into a spatial pipeline. "Timestep-forcing Pipeline Parallelism (TPP)"
- TTFF: Time-To-First-Frame; the end-to-end latency before the first frame is produced. "TTFF measures the end-to-end time-to-first-frame"
- VAE decoding: Conversion from latent space to pixel space by the decoder of a variational autoencoder, often a runtime bottleneck. "the VAE decoding stage is offloaded to an additional dedicated GPU"
- Variational Autoencoder (VAE): A generative model that encodes data into a latent space and decodes back, used here to compress video for diffusion. "3D VAE"
- window attention: Attention restricted to local temporal/spatial windows to reduce computation and support streaming. "StreamDiT~\cite{kodaira2025streamdit} supports streaming and interactive generation using window attention and multistep distillation."
Collections
Sign up for free to add this paper to one or more collections.