- The paper introduces a training-free method that prunes redundant latent tokens based on temporal similarities in video frames.
- It bridges traditional video compression techniques with diffusion transformers by employing an attention recovery mechanism to maintain video quality.
- Experimental results on the DAVIS dataset show a 44.8% speed increase, achieving 12.44 FPS while preserving structural and perceptual video fidelity.
Introduction
"Latent Inter-Frame Pruning: A Training-Free Method Bridging Traditional Video Compression and Modern Diffusion Transformers for Efficient Generation" (2604.23858) presents a training-free acceleration method for video generation under the Latent Diffusion Models (LDM) paradigm by introducing temporal redundancy-based token pruning in latent space. The method adapts the longstanding principle of inter-frame redundancy in traditional video codecs to state-of-the-art transformer-based diffusion video generation, aiming to enhance computational efficiency while preserving video quality.
Methodology
The proposed framework leverages the observation that the compressed latent representations of videos, obtained via an autoencoder (VAE) in LDM, exhibit considerable temporal redundancy. This redundancy manifests as nearly identical latent patches across adjacent frames, analogous to patterns exploited in MPEG video compression.
Pruning proceeds by computing the L1 distance between spatially aligned latent patches from consecutive frames. If the distance falls below a threshold θ, the newer patch is deemed redundant and omitted from further computation. This strategy directly reduces the number of input tokens for the Diffusion Transformer, leveraging the quadratic complexity (O(N2)) with respect to sequence length.
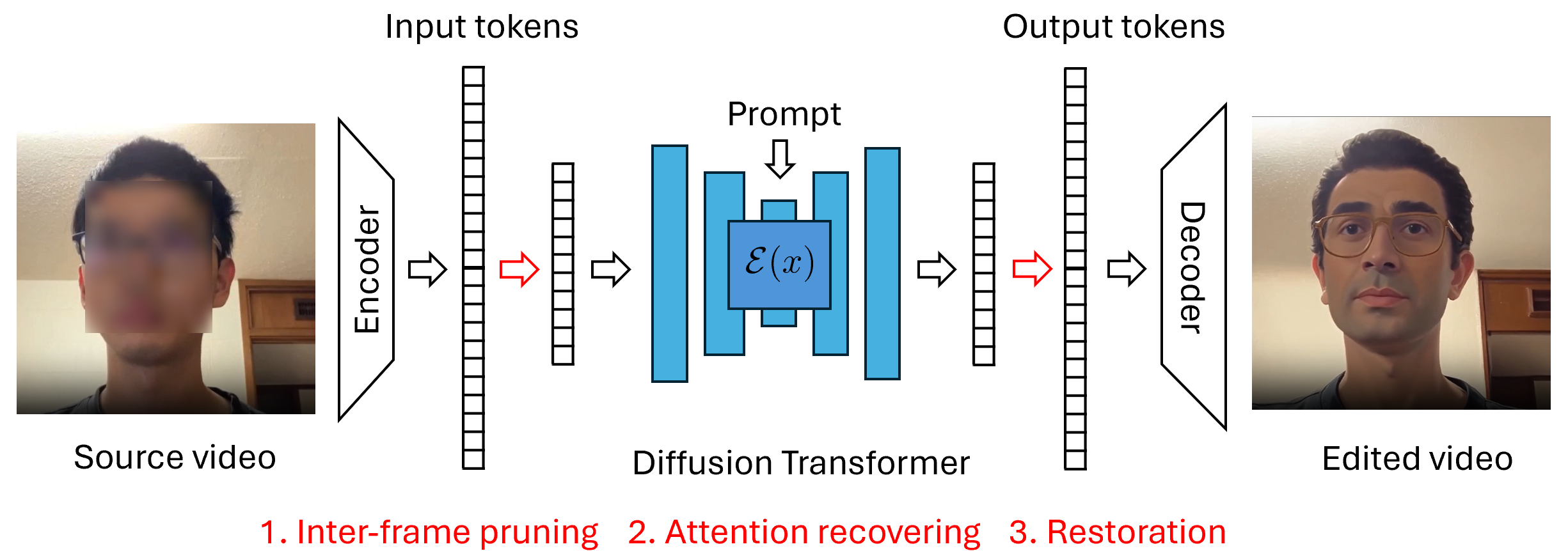
Figure 1: The framework operates in three stages: Inter-Frame Pruning, Attention Recovery, and Token Restoration.
However, generation tasks impose stricter requirements than standard understanding tasks, necessitating restoration of pruned details for faithful dense output. Direct pruning at inference, given full-token training, triggers visible artifacts due to input distribution shift—predominantly affecting self-attention computations in the transformer. To resolve this, the framework introduces an Attention Recovery mechanism that analytically approximates self-attention results for pruned sequences, adjusting computations to match those expected from a full token set. This approximation maintains compatibility with hardware-optimized attention variants such as FlashAttention.
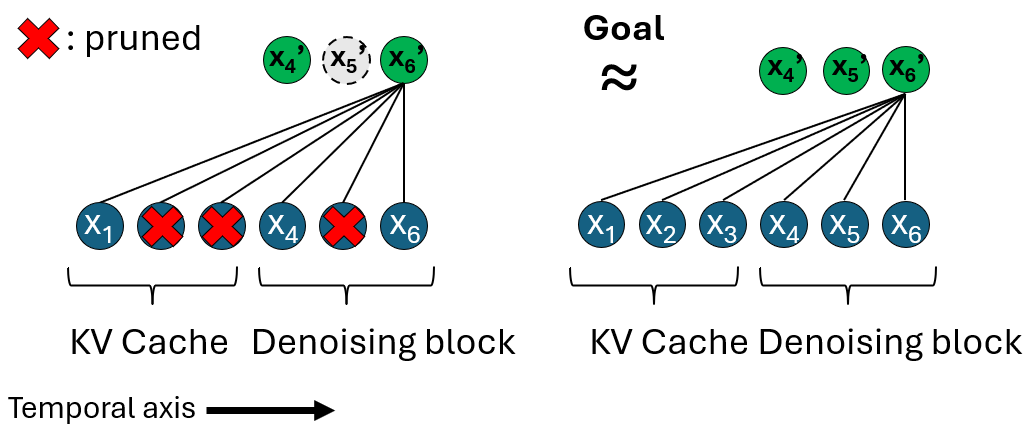
Figure 2: Self-attention approximation for pruned versus full-length latent token sequences.
During approximation, special care is taken in handling noise: directly duplicating tokens, including their Gaussian noise, would artificially induce correlation, violating the i.i.d. noise assumptions critical for diffusion-based models. The method introduces Noise-Aware Duplication, which disentangles signal and noise, duplicating only estimated clean content for key-value (KV) cache utilization. Extra constraints ensure tokens designated for substitution in the KV-cache remain sufficiently similar, preserving generative fidelity.
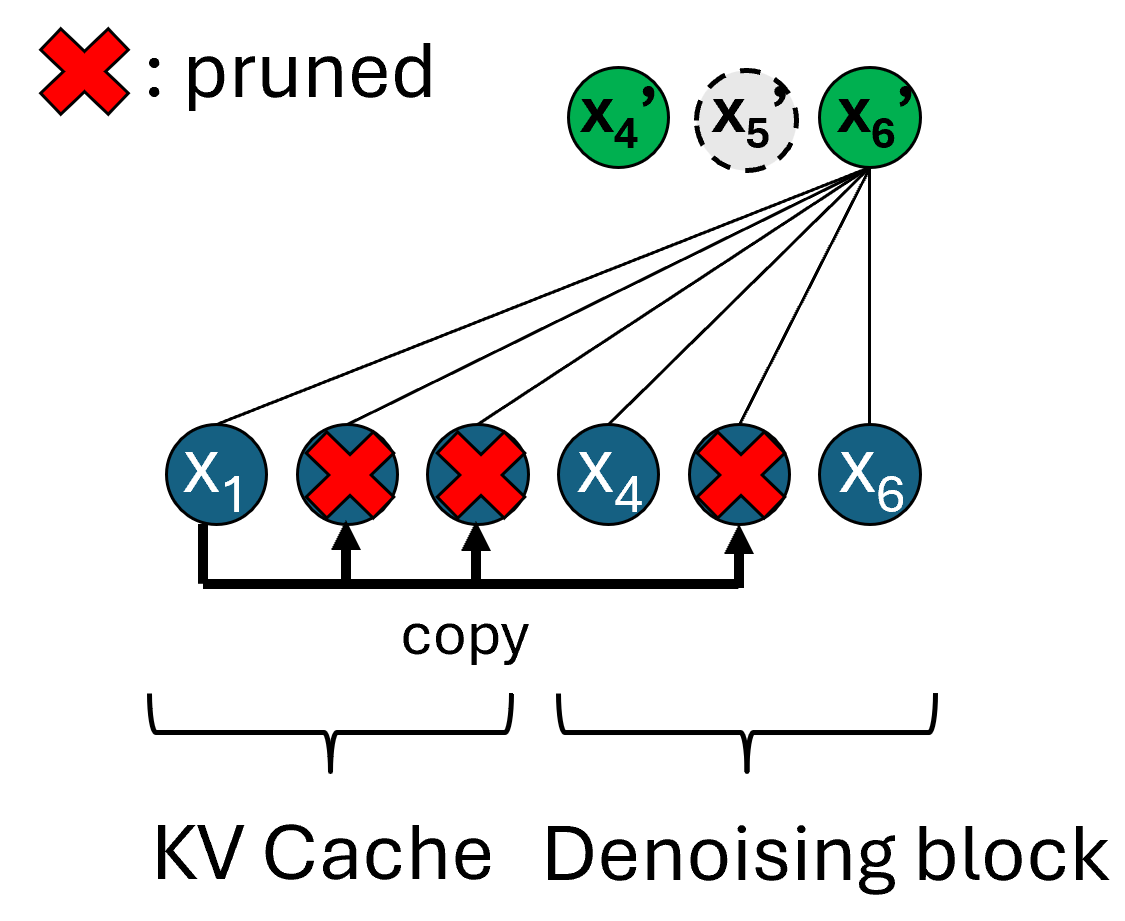
Figure 3: Illustration of noise-aware unpruning, ensuring robust recovery without noise correlation.
After denoising, the fixed-size decoder input necessitates restoration of the original token count. This is accomplished by duplicating clean tokens from proximate temporal locations, assuming that the generated edits maintain the temporal structural similarity observed in the input video.
Experimental Evaluation
The effectiveness of Latent Inter-Frame Pruning is rigorously assessed on the DAVIS dataset using the Self-Forcing model—a robust diffusion transformer variant. Performance is measured by both video quality, using the comprehensive VBench benchmark, and inference throughput (FPS).
Quantitative evaluation demonstrates that, with carefully tuned pruning thresholds, the framework sustains video quality metrics comparable to the unpruned baseline across multiple categories, including subject and background consistency, motion, aesthetic, and imaging smoothness.
Crucially, the pruning method achieves a 44.8% increase in inference speed, attaining an average of 12.44 FPS on an NVIDIA RTX 6000 GPU—a 1.44× throughput improvement without compromising the fidelity of edited videos.
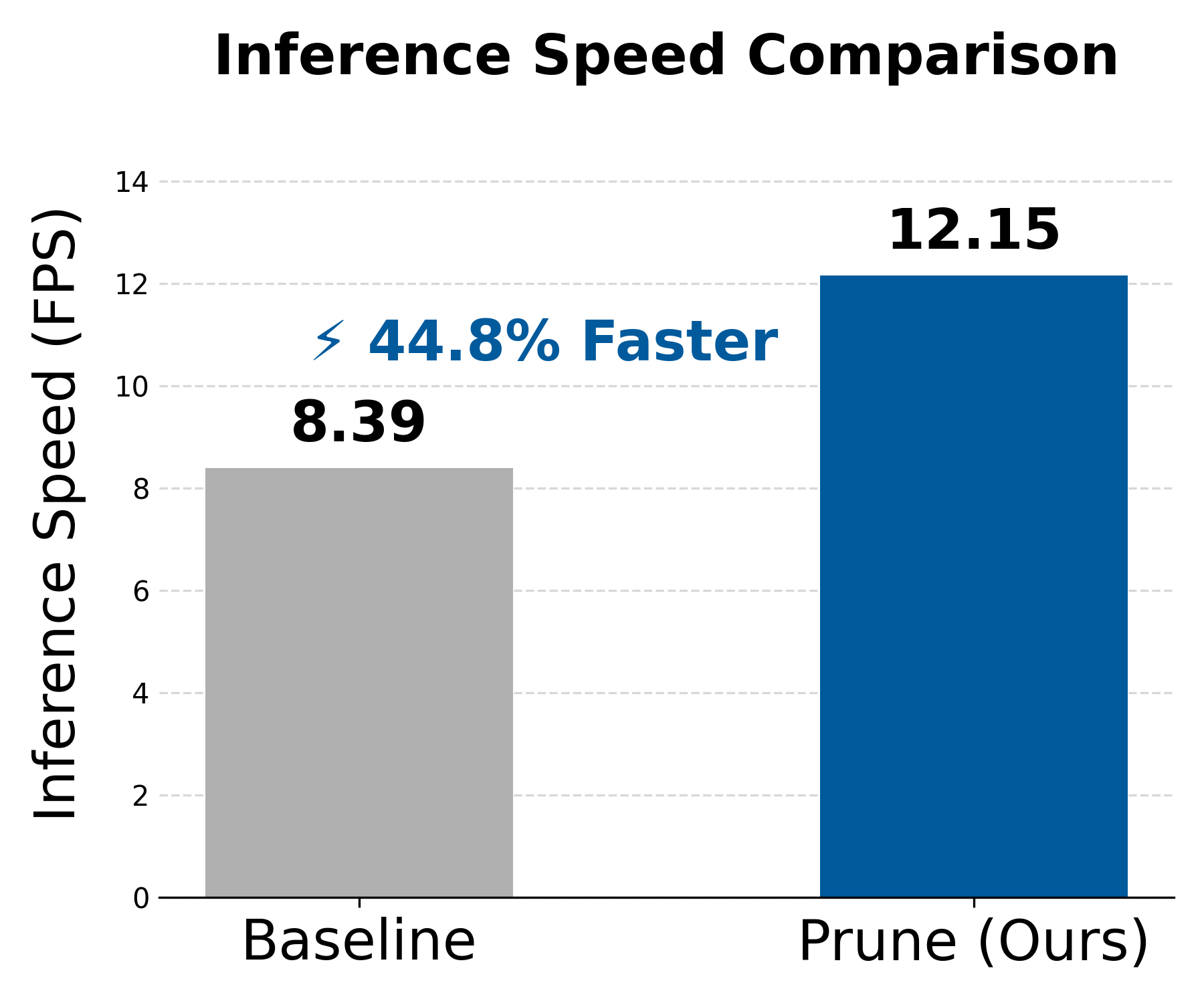
Figure 4: Benchmark comparison reveals a substantive inference speedup using latent inter-frame pruning versus the full baseline.
Discussion and Implications
This approach establishes a systematic, training-free pathway to infuse classical video compression tenets into modern diffusion-based video generation. Its design aligns with both hardware efficiency trends and the growing demand for real-time, high-quality generative video pipelines. Notably, the method's attention recovery mechanism demonstrates that compensatory analytical corrections—rather than architectural retraining—are viable for bridging train-test discrepancies induced by aggressive pruning.
Theoretically, this research advocates deeper integration of signal processing perspectives into generative modeling, particularly in leveraging redundancy inherent in high-dimensional spatiotemporal data. The reliance on content-aware, noise-aware processing further demonstrates the nuanced requirements of pruning within generation, in contrast to understanding.
In practice, the framework's modularity enables immediate deployment on LDM-based transformers, including those using causal attention with KV caching. The methodology also anticipates broader generalization, with potential to extend into spatial redundancy exploitation (spatial patch pruning), adaptive pruning rates, and even broader domains where data exhibits intrinsic repetitive structure.
Conclusion
Latent Inter-Frame Pruning provides a principled, hardware-compatible, and training-free acceleration method for video generation in diffusion transformer architectures. By responsibly pruning redundant latent patches and introducing an analytically grounded attention recovery scheme, the method achieves a substantial inference speedup while rigorously preserving perceptual and structural quality. Continuing this line of research is likely to yield increasingly efficient, theoretically grounded, and practical generative video systems, especially as diffusion models scale in complexity and real-time deployment becomes paramount.