- The paper introduces the first fully open pipeline for clinical LLMs that ensures complete auditability of data, processes, and generation.
- It integrates clinician-audited public datasets with synthetic and guideline-derived QA to enhance coverage of emergency and life-threatening cases.
- Empirical results demonstrate state-of-the-art accuracy and clinical preference improvements, underpinning reproducible and safe medical AI deployment.
Fully Open Meditron: An Auditable Pipeline for Clinical LLMs
Motivation and Conceptual Foundations
Clinical deployment of LLMs imposes requirements unattainable by conventional open-weight approaches: scrutability, auditability, and reproducibility across the complete data, code, and adaptation pipeline. Most medical LLMs labeled as "open" refer only to parameter release, not to full data, process, and generation pipeline transparency, leaving researchers and clinicians unable to inspect or reproduce critical sources of behavioral bias, contamination, or misalignment. The absence of any medical LLM with true full-stack transparency inhibits robust regulatory and clinical validation. Fully Open Meditron addresses this gap by introducing the first truly fully open (FO) pipeline for LLM-CDSS, differentiating itself from open-weight models in both process and resource accessibility.
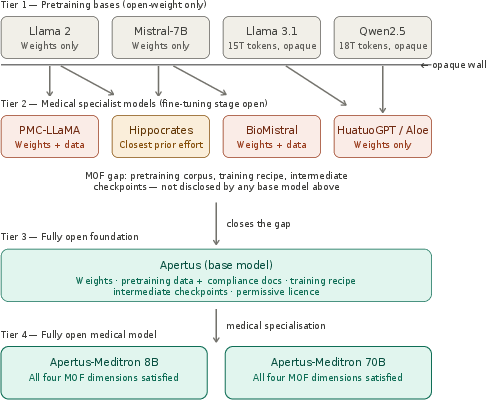
Figure 2: Openness taxonomy spanning closed, open-weight, partially open, and fully open medical LLMs according to released artifacts and provenance.
Auditable Corpus Construction and Data Management
Fully Open Meditron centers its knowledge base on a clinician-audited, open-source corpus uniting eight public medical QA datasets (MedQA, MedMCQA, PubMedQA, MedExpQA, HealthSearchQA, LiveQA, AfriMed-QA v1/v2), augmented by extensive synthetic expansion along three axes: exam-style QA, guideline-derived QA (46,469 clinical guidelines from 16 global institutions), and open-ended vignettes from expert-written MOOVE scenarios. Hallucinations in synthetic segments are mitigated by gold-label rejection sampling. Distributional and compositional analyses reveal that naïve aggregation of public benchmarks dramatically underrepresents urgent, life-threatening, and low-resource clinical contexts. Clinician-guided synthetic extension (incorporating global health, emergency, pediatrics, and epidemiological context) increases the share of emergency-care coverage from 15.0% to 38.7% and life-threatening cases from 8.6% to 31.8% in relevant subsets, as demonstrated in content stratification studies. The pipeline enforces system-wide, rigorous decontamination (n-gram and token alignment) against evaluation references, minimizing data leakage and contamination.
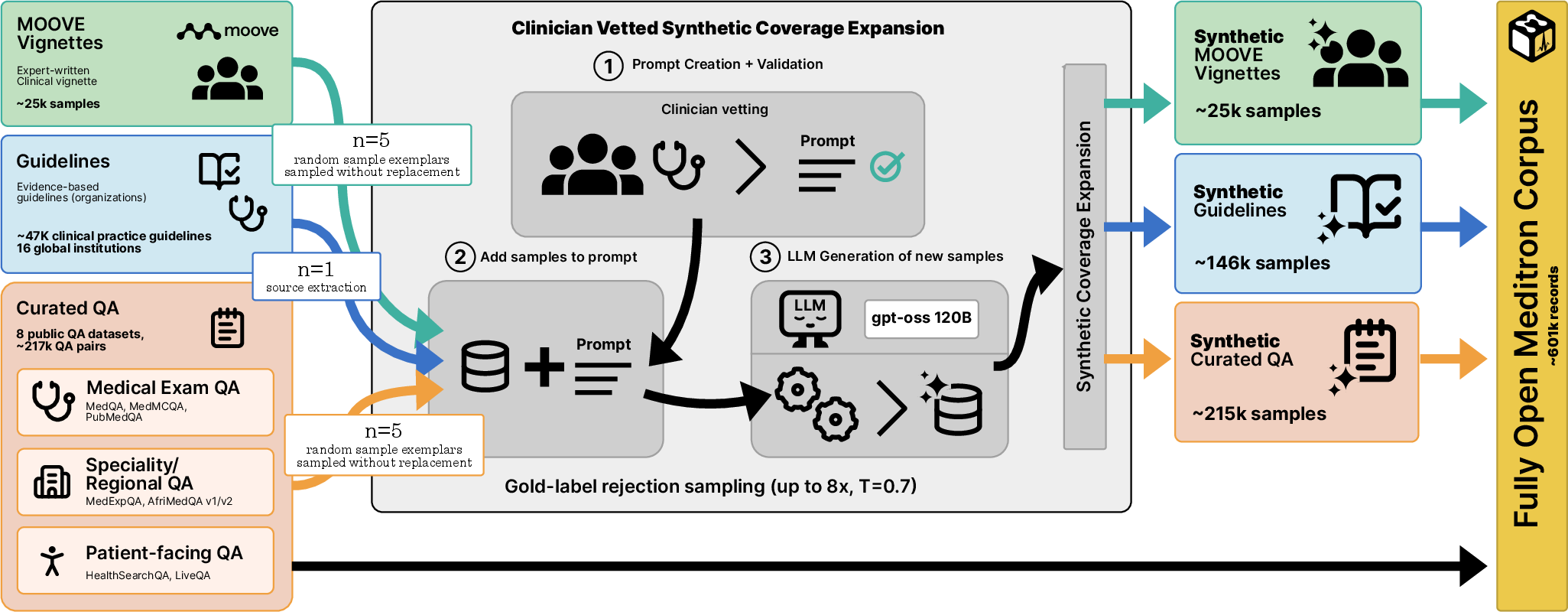
Figure 3: Pipeline for construction of the MeditronFO corpus integrating curated public QA, guidelines, expert vignettes, and synthetic QA with clinician audit and decontamination.
Compositionally, synthetic data comprises ∼64% of the final 601,519-example, 150M-token corpus. Specialty, urgency, and difficulty redistributions are confirmed by zero-shot LLM classifiers, supporting the pipeline's efficacy in mitigating prior coverage gaps.
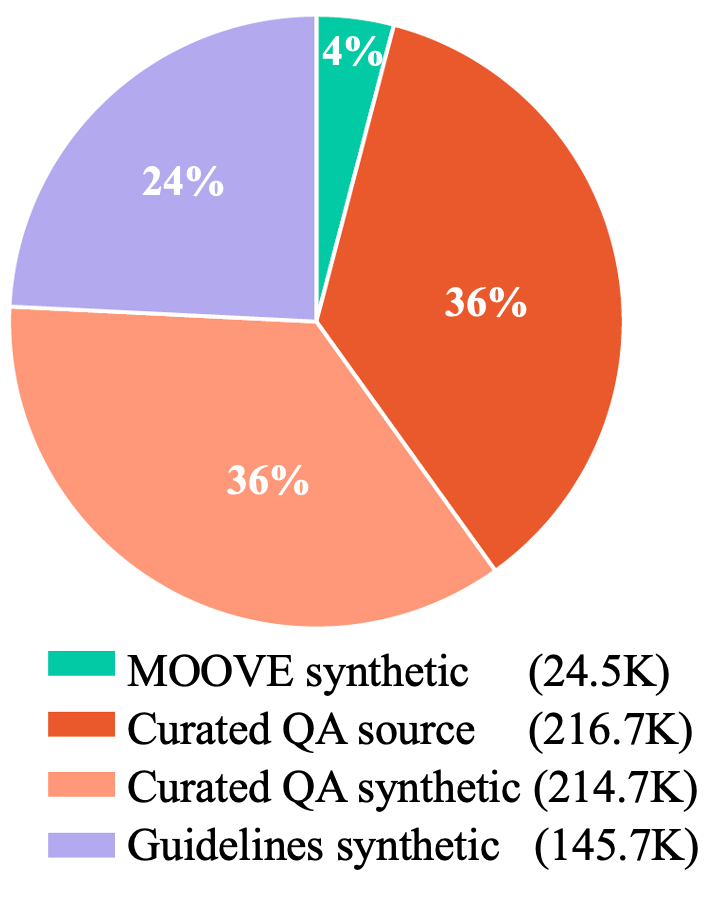
Figure 4: Breakdown of component counts in the fully open Meditron datasets.
Model Training, Instruction Alignment, and Evaluation Protocols
The corpus is used to supervise the fine-tuning of five fully open base models spanning the Apertus, OLMo, and EuroLLM families across various parameter scales (8B–70B). Training uses fully reproducible Axolotl configurations, preserving native chat templates and utilizing bfloat16 mixed precision, ZeRO-3 or FSDP v2 strategies, sample-packing at sequence length 4096, and non-proprietary infrastructure.
To surpass the limitations of traditional multiple-choice clinical evaluation, two major open-ended evaluation strategies are employed:
- HealthBench: Open-ended, rubric-driven scoring (multi-axis physician-authored).
- Auto-MOOVE: LLM-as-a-judge framework measuring pairwise clinical preference and per-criterion Likert ratings (criteria include harm, fairness, contextual awareness; 9 axes in total). Judge validation against 204 human raters yields a Cohen's κ statistically indistinguishable from median panelists.
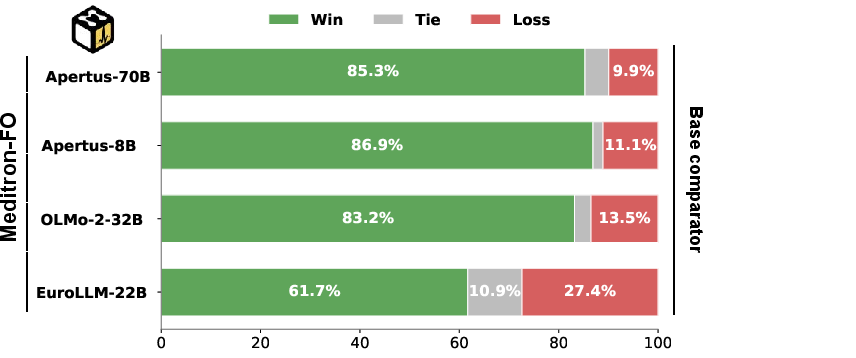
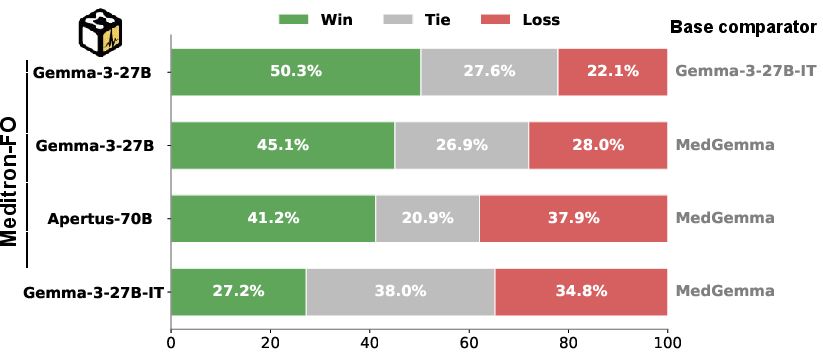
Figure 5: Auto-MOOVE pairwise win rates for MeditronFO variants against base models and MedGemma, showing consistent model preferences.
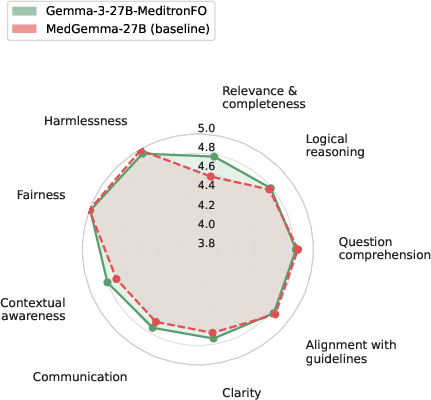
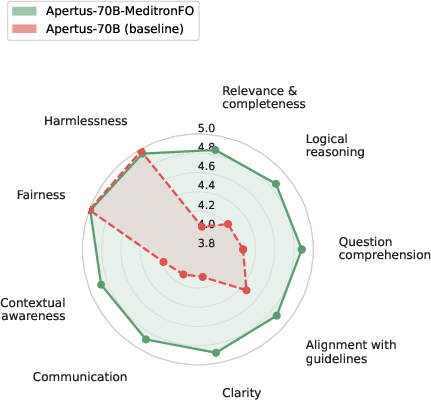
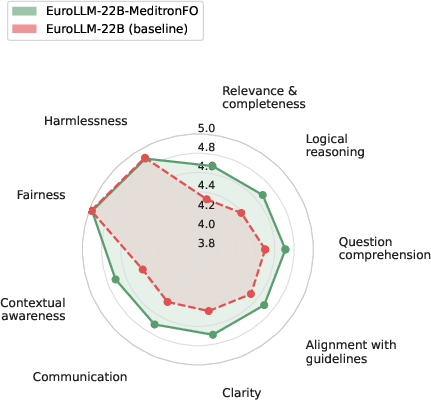
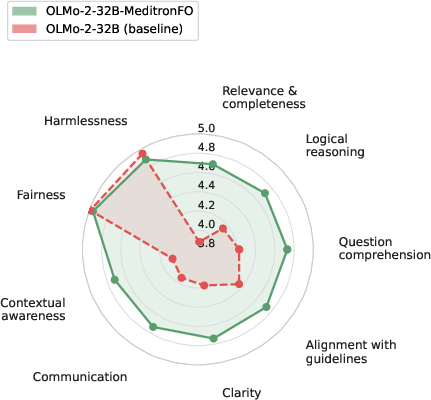
Figure 6: Averaged per-criterion Likert profiles across nine axes for MeditronFO and corresponding base models, indicating multidimensional improvements.
Empirical and Comparative Results
Apertus-70B-MeditronFO establishes a new state-of-the-art among fully open medical specialists, improving from 47.2% to 53.8% average accuracy across MedMCQA, MedQA, PubMedQA, MedXpertQA, and HealthBench. Across all MeditronFO-finetuned models, consistent gains are observed both in accuracy (up to +12.8 absolute for smaller EuroLLM/Apertus bases) and open-ended clinical preference (Auto-MOOVE adjusted win rates 67%–92%). In cross-family evaluation, Gemma-3-27B-MeditronFO outperforms MedGemma (58.6% vs 55.9% HealthBench; preference in 58.6% LLM-judge pairwise contests), directly contradicting the assumption that proprietary synthetic or undisclosed data pipelines are necessary for clinical SoTA.
Ablation studies on corpus components reveal that exam-style QA and Clinical Vignette data are crucial not only for MCQA metrics but for open-ended preference and reasoning axes as well; removal of guideline QA slightly raises MCQA but does not improve open-interaction competence. Removal of synthetic MOOVE scenarios, in particular, significantly lowers model ratings on contextual and reasoning dimensions, substantiating the necessity of comprehensive training coverage.
Robustness, Limitations, and Implications
Despite system-wide decontamination, the syntactic (not strictly semantic) nature of contamination filtering leaves residual risk of paraphrased benchmark leakage. The single-teacher/single-judge constraint introduces stylistic biases, though ablation across judge models confirms robustness of the main claims. Auto-MOOVE, though validated against human raters, underperforms human discriminators—especially on safety-centric axes such as harmlessness/fairness—as corroborated by agreement studies.
Pragmatically, the fully open pipeline enables transparent, reproducible development and evaluation of LLM-CDSS, directly facilitating regulatory, clinical, and academic auditing. The work demonstrates FO training does not inherently result in inferior clinical LLMs; with disciplined validation and corpus construction, it is feasible to achieve or approach proprietary, closed-data performance (particularly when model and compute scales are matched).
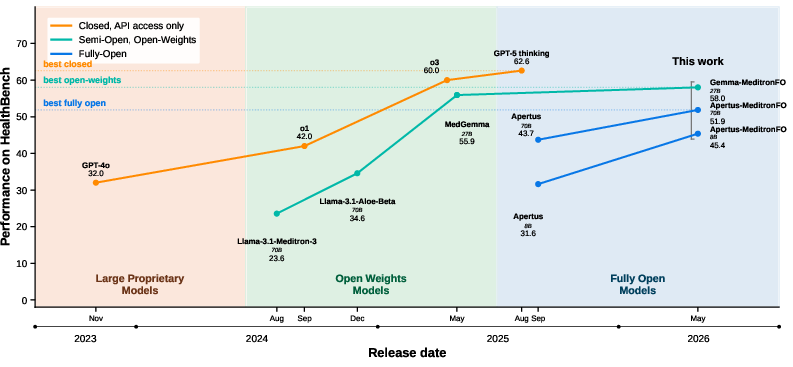
Figure 7: Timeline of HealthBench performance across closed, open-weight, and fully open medical LLMs, highlighting the closing gap due to MeditronFO models.
Future Directions
Potential avenues include integration of open-preference optimization, semantic decontamination, deeper clinician-in-the-loop supervision, and generalization to multilingual settings. Expanding semantic analysis of contamination, optimizing replay schedules for generalist instruction capability retention, and deploying end-to-end FO teacher models to minimize transfer of biases in synthetic data remain to be pursued. These would further consolidate the auditability and global applicability of open medical LLMs in both research and practical deployments.
Conclusion
Fully Open Meditron demonstrates, with strong empirical support, that rigorous auditing, clinician-guided data construction, and transparent adaptation pipelines can yield clinically competitive medical LLMs without recourse to undisclosed or proprietary resources. The FO paradigm, as instantiated here, balances domain-specific metric improvement with critical requirements for auditable, reproducible, and safe clinical model deployment. The resources and process disclosed establish a reusable foundation for further development in open medical AI and set a new benchmark for transparency and scientific rigor in high-stakes LLM adaptations.
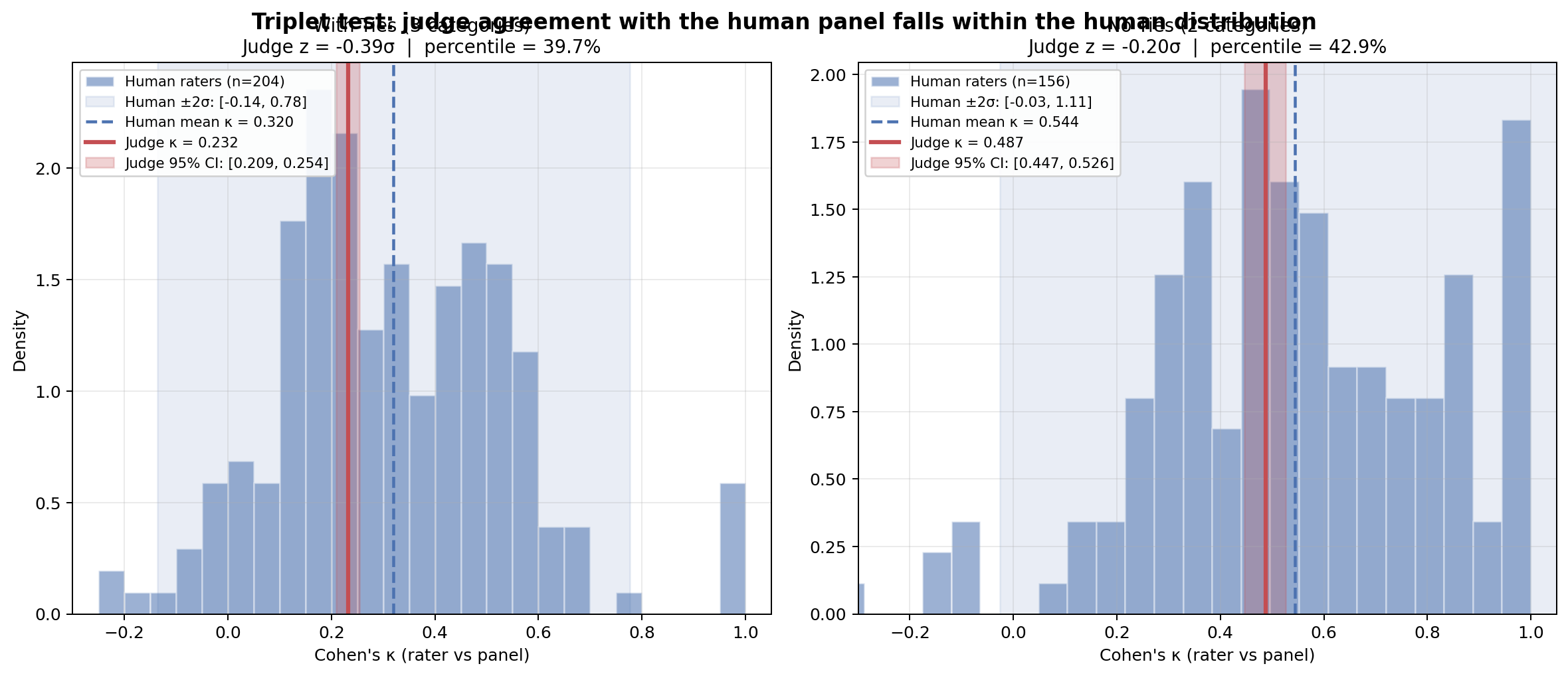
Figure 9: Distribution of per-rater κ among the human panel with Auto-MOOVE judge's agreement, validating LLM-judge equivalency for clinical reasoning preference evaluation.