- The paper introduces a fully automated, domain-agnostic pipeline that iteratively refines LLM-based extraction to produce structured, machine-readable regulatory rules.
- It employs deterministic normalization and schema-guided rule generation with multi-criteria LLM judgment, achieving extraction scores above 4.70/5.
- The approach demonstrates robust cross-domain performance and field-granular audits, enhancing compliance monitoring in finance, healthcare, and AI governance.
Overview and Motivation
De Jure introduces a fully automated, domain-agnostic pipeline designed to extract hierarchically structured, machine-readable regulatory rules from raw legal corpora without any human annotation, in-domain prompt engineering, or annotated gold data. The approach directly targets the operational bottleneck posed by regulatory text in high-stakes domains—such as finance, healthcare, and AI governance—where the precise identification and decomposition of legal requirements into executable rules is a prerequisite for compliance-aligned AI deployment. De Jure selectively leverages the semantic generalization and judgment abilities of LLMs, orchestrating a pipeline built on four sequential stages: deterministic normalization, schema-guided rule generation, multi-criteria LLM-judge evaluation, and targeted, field-level iterative repair.
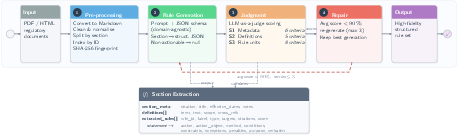
Figure 1: De Jure pipeline overview. Input documents are pre-processed into structured Markdown (Stage 1), parsed into JSON rule units via a domain-agnostic LLM prompt (Stage 2), scored by an LLM judge across 19 criteria in three stages (Stage 3), and iteratively repaired until the per-stage average score reaches 90% or the retry budget (max 3) is exhausted (Stage 4).
Pipeline Design and Methodology
Pre-processing and Normalization
The pipeline's initial phase ensures deterministic mapping from heterogeneous document formats (PDF/HTML) to structured Markdown, preserving regulatory section boundaries, list and table artifacts, and all relevant metadata. This normalized representation enables granular section-level traceability—every downstream extraction is anchored by a SHA-256 fingerprint of the input source, a critical feature for auditability in regulatory compliance contexts.
De Jure defines a uniform JSON schema that decomposes regulatory text per section into three typed components: section metadata, definitional glossary, and rule units. Rule units themselves are structured into fields for action, object, method, conditions, constraints, exceptions, penalties, source citations, verbatim spans, and summary labels. Extraction prompts are domain-agnostic, containing explicit instructions for negation, conditional segmentation, role resolution, and fine-grained operator labeling. The schema suppresses non-actionable passages and explicitly handles definitional overlaps.
Hierarchical, Multi-Criteria Judgment
Unlike prior pipelines relying on surface-form matching or flat quality heuristics, De Jure employs a sequential LLM-as-a-judge regime. Judgment criteria—nineteen in total, partitioned across three stages (metadata, definitions, rule units)—are enforced by a dedicated model (Compass) separate from the extraction backbone to preclude contamination/blind-spot effects. Judgment is both field-local and criterion-specific, generating not only a per-criterion 0–5 score but also actionable, natural-language critique for each detected defect.
Selective Iterative Repair
Repairs are strictly localized: only the failed fields as identified by the judge and only for the lowest-scoring pipeline stage. Iteration continues for each stage until the average normalized score exceeds a threshold (θ = 0.90) or the per-stage retry budget (r = 3) is exhausted. The top-scoring extraction is always retained, ensuring monotonic quality improvement and graceful fallback when regeneration does not succeed.
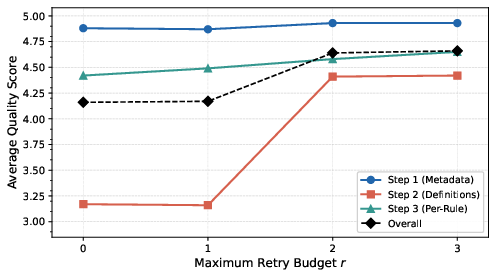
Figure 2: Average quality score per pipeline step as a function of retry budget r (scale 1–5; higher is better). Steps 1 and 3 are stable; Step 2 (definitions) exhibits high sensitivity to r. Gains saturate for r>2.
Field-Granular Audit and Case Study
The pipeline supports interpretable, field-wise audit trails. When an extraction fails, critiques are precise (e.g., label incompleteness, rule type misclassification) and guide targeted correction. For instance, in HIPAA §164.306, initial extraction yielded a sub-threshold average score due to two localized defects; a single repair iteration, guided by judge feedback, corrected only the flagged fields without disturbing the other components, resulting in a passing post-repair score.
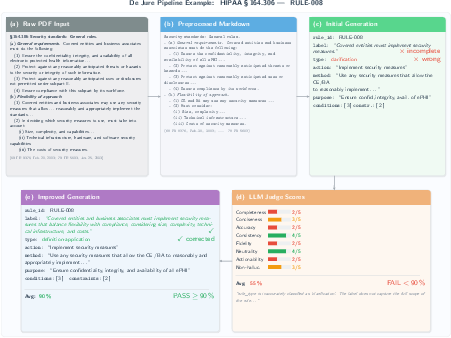
Figure 3: De Jure applied to HIPAA §164.306. Visualizes the pipeline’s iterative loop: initial extraction, judge feedback, targeted repair, and successful validation.
Experimental Results
Experiments span three regulatory domains (finance—SEC Advisers Act, healthcare—HIPAA, AI governance—EU AI Act), open- and closed-source LLM backbones, and comprehensive ablation analyses.
Extraction Quality, Generalization, and Model Comparison:
De Jure obtains averaged per-rule judge scores exceeding 4.70/5.00 in every model/domain combination, with consistent performance monotonicity from metadata to rule unit decomposition (complexity gradient). Notably, well-tuned open-source models (Qwen3-VL-8B) approach the performance of the best closed-source models (GPT-5-mini) with a gap of just 0.04. Extraction fidelity (non-hallucination) is uniformly perfect—an empirical refutation of naive hallucination risks in schema-constrained LLM extraction.
Cross-Domain Robustness:
The pipeline architecture is domain-robust: prompts, schema, and configuration are unchanged between corpora. Extraction performance degrades modestly across the structural regularity gradient (SEC > HIPAA > EU AI Act), revealing genuine sensitivity to textual complexity and section boundary ambiguity, but remains well above high-quality thresholds.
Downstream Regulatory RAG Evaluation:
RAG-based compliance QA—retrieving rules for LLM-generated questions—shows De Jure-extracted rules enable response sets preferred by a dedicated judge in up to 84% of pairwise comparisons (k=10 retrieval), with the fidelity advantage amplifying in aggregation regimes (k>1). The system’s compositional, field-exact labeling yields increased support for multi-rule, ambiguity-handling queries—directly demonstrating that improvements in extraction precision and definition linking yield measurable downstream gains.
Design Ablation Insights
Regeneration Budget:
Extraction quality exhibits non-linear sensitivity to the retry budget. A jump from r=1 to r=2 at Step 2 yields dramatic (25%) improvement; negligible gains occur past r=3, supporting its selection as a default.
Chunking Strategy:
Input segmentation is highly consequential: precise, section-aware chunking yields up to a 6.6% gain at the initial pipeline stage, with downstream amplification in later steps. Downstream refinement cannot compensate for incoherent or misaligned chunks.
Judgment Trigger:
The average-score trigger is as effective as per-criterion, more conservative triggers, provided the retry budget is sufficient—a result that simplifies pipeline design and inference cost management.
Theoretical and Practical Implications
De Jure demonstrates that explicit, interpretable, and sufficiently granular LLM-driven evaluation criteria can substitute for the absence of human annotation in regulatory rule extraction tasks, making scalable and auditable alignment feasible in annotation-scarce legal settings. Hierarchical decoupling and repair guard against the propagation of upstream errors—a critical property for any downstream system reliant on regulatory traceability. Its cross-domain generality and compositional field structure provide a scalable basis for LLM alignment to concrete legal obligations, not just subjective human preferences, opening a tractable path to regulatory-aware model control and rigorous compliance monitoring.
Future Directions
Challenges remain in further reducing failure rates on highly unstructured or exception-heavy text, scaling component-level judgment to nested cross-referential regimes, and integrating real-time rule updates from live regulatory feeds. Enhancements in prompt engineering for rare regulatory structures and direct integration with executable logic standards (e.g., for formal policy reasoning) are proposed vectors for follow-up investigation.
Conclusion
De Jure operationalizes an explicit, robust, and interpretable pipeline for the end-to-end extraction of structured regulatory rules from raw legal text using only LLMs. By decoupling extraction, judgment, and repair stages, it achieves domain-transfer, annotation-free rule mining at fidelity levels suitable for downstream compliance LLM alignment and auditable question answering. The approach substantiates the hypothesis that self-refined, multi-criteria LLM judgment can serve as an effective supervision surrogate in complex, high-stakes regulatory information extraction, supporting scalable and regulation-grounded AI deployment (2604.02276).

