Qalb: Largest State-of-the-Art Urdu Large Language Model for 230M Speakers with Systematic Continued Pre-training
Abstract: Despite remarkable progress in LLMs, Urdu-a language spoken by over 230 million people-remains critically underrepresented in modern NLP systems. Existing multilingual models demonstrate poor performance on Urdu-specific tasks, struggling with the language's complex morphology, right-to-left Nastaliq script, and rich literary traditions. Even the base LLaMA-3.1 8B-Instruct model shows limited capability in generating fluent, contextually appropriate Urdu text. We introduce Qalb, an Urdu LLM developed through a two-stage approach: continued pre-training followed by supervised fine-tuning. Starting from LLaMA 3.1 8B, we perform continued pre-training on a dataset of 1.97 billion tokens. This corpus comprises 1.84 billion tokens of diverse Urdu text-spanning news archives, classical and contemporary literature, government documents, and social media-combined with 140 million tokens of English Wikipedia data to prevent catastrophic forgetting. We then fine-tune the resulting model on the Alif Urdu-instruct dataset. Through extensive evaluation on Urdu-specific benchmarks, Qalb demonstrates substantial improvements, achieving a weighted average score of 90.34 and outperforming the previous state-of-the-art Alif-1.0-Instruct model (87.1) by 3.24 points, while also surpassing the base LLaMA-3.1 8B-Instruct model by 44.64 points. Qalb achieves state-of-the-art performance with comprehensive evaluation across seven diverse tasks including Classification, Sentiment Analysis, and Reasoning. Our results demonstrate that continued pre-training on diverse, high-quality language data, combined with targeted instruction fine-tuning, effectively adapts foundation models to low-resource languages.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Qalb, a new AI LLM that understands and writes Urdu much better than previous systems. Urdu is spoken by over 230 million people, but most big AI models are trained mostly on English and a few other languages. Because of that, they don’t handle Urdu’s right-to-left script, grammar, and culture very well. Qalb aims to fix this by giving an existing model a lot more high‑quality Urdu reading practice and then teaching it how to follow instructions in Urdu.
What were the researchers trying to do?
In simple terms, they wanted to:
- Help an AI become truly good at Urdu, not just “okay.”
- Show that giving a model more reading practice in the target language (Urdu) before teaching it to chat makes a big difference.
- Beat the best existing Urdu models on real tasks like translation, answering questions, and understanding feelings in text.
How did they do it?
Think of training a LLM like training a student:
- Pre‑training: Like reading tons of books to learn general language patterns.
- Continued pre‑training: Like moving to a country where Urdu is spoken and reading even more Urdu so you get fluent.
- Fine‑tuning: Like hiring a coach to practice specific skills, such as how to answer questions clearly.
Here’s their approach, step by step:
- Building a big, clean Urdu reading set They collected a huge amount of Urdu text from different places—news sites, classic and modern literature, government documents, and social media. In total, the model read about 1.97 billion “tokens.” A token is like a small piece of text (often part of a word). About 1.84 billion tokens were Urdu; 140 million were from English Wikipedia.
Why include English at all? To prevent “catastrophic forgetting.” That’s when you learn something new (lots of Urdu) and accidentally forget what you already knew (like reasoning skills learned from English). Mixing in some English helps the model keep its balance.
- Continued pre‑training (more Urdu practice) They started with an existing model (LLaMA 3.1 with 8 billion parameters) and gave it extra Urdu practice. Instead of changing the entire model (which is expensive), they used a smart method called LoRA. You can imagine LoRA like adding small adjustable attachments to the model’s layers—so you improve it without rebuilding the whole engine. This made training cheaper and possible on a single powerful GPU.
- Instruction fine‑tuning (coaching the model to be a helpful assistant) After the extra Urdu practice, they trained the model to follow instructions in Urdu using a special dataset (Alif Urdu‑instruct). This step teaches the model how to respond politely, stay on topic, and format answers in a chat.
- Testing the model They tested Qalb on seven kinds of tasks:
- Generation (writing text)
- Translation (Urdu ↔ English)
- Ethics (moral reasoning)
- Reasoning (logic and commonsense)
- Classification (sorting text into categories)
- Sentiment analysis (detecting feelings)
- Question answering (giving factual answers)
An advanced AI system (GPT‑4o) graded the answers using clear rules, and human Urdu speakers double‑checked many of the results. The AI judge and humans agreed over 85% of the time.
They also made a compressed version of Qalb (a “4‑bit quantized” model). Think of this like shrinking a high‑quality photo so it takes less space but still looks good. That helps run the model on smaller computers.
What did they find, and why does it matter?
Qalb set a new record for Urdu performance across the full set of tasks. Key results:
- Overall score: 90.34 out of 100. That’s higher than the previous best Urdu model, Alif (87.1), and far higher than the original base model before Urdu practice (45.7).
- Big gains in:
- Translation (+5.11 points over Alif)
- Reasoning (+5.09)
- Question answering (+6.6)
- Classification and sentiment also improved
- While another model did slightly better in open‑ended creative writing, Qalb was more reliable overall, especially at following instructions and giving direct, accurate answers.
- The small, compressed version kept about 95% of the performance while using much less memory.
Why it matters: It proves that giving a model lots of high‑quality reading in a specific language (continued pre‑training) plus coaching (fine‑tuning) can make it truly strong in that language—even if that language is underrepresented online.
What’s the bigger impact?
- Better tools for Urdu speakers: Qalb can help with education, translation, search, and writing assistance in more natural, culturally aware Urdu.
- A recipe for other languages: The same method (build a clean dataset, do continued pre‑training, then fine‑tune) can lift performance for other under‑served languages like Pashto, Sindhi, and Punjabi.
- More accessible AI: The compressed version means the model can run on cheaper hardware, making it easier to deploy in schools, offices, and mobile apps.
The authors also note some limits and risks: the model can still pick up biases from its training data, sometimes produces extra text it shouldn’t (like signature‑style lines), and shouldn’t be used as the only source for serious advice (like medical or legal). Still, Qalb shows a clear, practical path to making AI much more helpful for large communities that have been overlooked.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. These items are framed to enable targeted follow-up by future researchers.
- English capability retention is asserted but not evidenced: no pre/post evaluation on English (or other languages originally supported by LLaMA-3.1) to quantify catastrophic forgetting or cross-lingual trade-offs.
- No ablation on the mixed-corpus ratio: the choice of 140M English tokens (~7%) is untested; optimal proportions, curriculum schedules, or replay strategies for minimizing forgetting remain unknown.
- Tokenizer suitability for Urdu is unexamined: no vocabulary coverage analysis, OOV/byte-level share, subword segmentation quality, or comparison against Urdu-optimized tokenizers; impact on morphology, diacritics, and Nastaliq-specific orthographic phenomena is unclear.
- Roman Urdu and code-switching are not evaluated: handling of Latin-script Urdu, Urdu–English code-mixing, and transliteration variants is untested despite being common in real-world usage.
- Normalization choices are unspecified: Unicode normalization, ZWNJ handling, diacritics stripping/retention, punctuation variants, and numeral scripts are not documented or evaluated for downstream effects.
- Data licensing and compliance are unclear: source-specific licenses (e.g., literature archives, religious texts, news sites), copyright status, consent, and dataset redistribution permissions are not detailed.
- Privacy and PII safeguards are not described: no explicit PII detection/removal, redaction, or auditing process is presented for scraped government or social media content.
- Dataset “Urdu word purity” metric is insufficiently specified: methodology, thresholds, error analysis, and failure modes for language identification are not provided.
- Data contamination checks are missing: no deduplication or overlap analysis with evaluation sets (and with Alif-instruct SFT data) to rule out leakage that could inflate benchmark scores.
- Domain/bias profiling is absent: domain distribution, topic balance (e.g., religion vs. news vs. social media), stylistic skew, and bias audits (gender, sectarian, ethnic, regional) are not reported.
- Stability and persistence of knowledge with LoRA-based continued pre-training are untested: no comparison to full-parameter updates, adapter merging strategies, or long-term retention after SFT.
- Hyperparameter and design ablations are missing: no sensitivity analyses for LoRA rank/targets, sequence length, optimizer settings, learning rates, or training steps; compute–quality trade-offs are unknown.
- Scaling behavior is unexplored: no experiments across token budgets, model sizes, or training durations to determine Urdu-specific scaling laws and optimal compute allocation.
- Long-context capability is unassessed: maximum context is 2048 tokens; no evaluation of long-document understanding, retrieval-augmented QA, or context window extensions for Urdu.
- Robustness and OOD generalization are untested: no adversarial or stress tests (noisy orthography, typos, dialectal variants, mixed numerals), nor performance under distribution shift.
- Safety and alignment are only qualitatively acknowledged: no Urdu-specific toxicity/hate/harassment benchmarks, disinformation evaluations, or safety fine-tuning (RLHF/DPO) and red-teaming results.
- Hallucinated “signature” artifacts lack mitigation: no targeted data filtering, post-hoc detoxification, or fine-tuning strategies to eliminate forum/email-style signatures and boilerplate hallucinations.
- Evaluation relies heavily on GPT-4o as judge: potential judge bias for Urdu, limited transparency about rubric adherence, and lack of classic task-specific metrics (e.g., BLEU/COMET for translation, EM/F1 for QA).
- Human evaluation depth is limited: only an “85% agreement” is reported; details on sample size, inter-annotator agreement statistics (e.g., Cohen’s κ), annotator instructions, and error taxonomy are missing.
- Weighted average scoring lacks transparency: task weighting scheme, variance, and confidence intervals are not provided; no statistical significance testing of improvements (e.g., bootstrap or paired tests).
- Multi-turn dialogue and instruction-following robustness are not tested: no evaluation of conversational memory, context tracking, or refusal/grounding behavior over extended turns in Urdu.
- Practical deployment metrics are lacking: latency, throughput, and memory footprint under 4-bit quantization across diverse hardware are not reported; only accuracy is compared.
- Quantization breadth is limited: impact of different bit-widths (3/4/8-bit), quantization-aware fine-tuning, and task-specific degradation profiles are not explored.
- Cross-model generality is unclear: adaptation was only demonstrated from LLaMA-3.1-8B; it remains unknown how well the method transfers to other backbones (Mistral, Qwen, Gemma) or larger/smaller sizes.
- Comparative fairness across baselines is incomplete: several baselines lack scores for some tasks; the comparability of weighted averages and evaluation conditions is uncertain.
- QA evaluation methodology lacks exact-match grounding: no EM/F1 or retrieval-grounded assessment; reliance on LLM-as-judge can mask factuality or reasoning errors.
- Absence of domain-specific evaluations: medical, legal, and educational performance (and corresponding risk analyses) are not assessed despite being proposed as future directions.
- Environmental impact is unreported: training time, energy consumption, and carbon footprint for continued pre-training and SFT are not quantified.
- Release status and reproducibility gaps: the paper states the model and data “will be released” but are not yet publicly available; until then, independent verification and replication are blocked.
- Legal and cultural risk assessment is limited: no structured evaluation of culturally sensitive content, political persuasion, or region-specific misinformation risks in Urdu contexts.
- Benchmark transparency is limited: full benchmark definitions, test splits, and prompts (especially for GPT-4o judging) are not fully enumerated for external reproduction.
These gaps suggest concrete next steps: add English and multilingual regression tests; conduct tokenizer and normalization studies; perform contamination checks and bias audits; broaden evaluation with standard task metrics and human studies; run ablations on data mix and LoRA settings; test long-context, robustness, and safety; and release artifacts for full reproducibility.
Glossary
- AdamW-8bit: An optimizer based on AdamW that uses 8-bit quantization to reduce memory footprint during training. "We utilized the AdamW-8bit optimizer to further conserve memory, employing a cosine learning rate schedule with a warmup ratio of 0.05."
- bfloat16: A 16-bit floating-point format with an 8-bit exponent, offering wide dynamic range with lower memory use than FP32. "Training was performed in bfloat16 precision with gradient checkpointing enabled to maximize batch sizes within available memory."
- Catastrophic forgetting: When a model loses previously learned abilities while being further trained on new data. "combined with 140 million tokens of English Wikipedia data to prevent catastrophic forgetting."
- Chinchilla scaling laws: Empirical laws relating optimal model size and number of training tokens for compute-efficient training. "As demonstrated by the seminal "Chinchilla" scaling laws \cite{hoffmann2022training}, model performance is driven as much by the number of training tokens as by parameter count."
- Continued pre-training: Extending the pre-training phase of a foundation model on new, targeted data. "Starting from LLaMA 3.1 8B, we perform continued pre-training on a dataset of 1.97 billion tokens."
- Control tokens: Special markers in chat models that delineate roles and structure within a prompt. "which utilizes distinct control tokens (e.g., <|start_header_id|>) to demarcate System, User, and Assistant roles."
- Cosine learning rate schedule: A learning rate strategy that decays following a cosine curve, often with an initial warmup. "employing a cosine learning rate schedule with a warmup ratio of 0.05."
- Foundation model: A large, general-purpose pretrained model serving as a base for downstream adaptation. "continued pre-training, which involves taking an existing foundation model and extending its pre-training on target language data"
- Gradient checkpointing: Technique that trades computation for memory by recomputing intermediate activations during backpropagation. "Training was performed in bfloat16 precision with gradient checkpointing enabled to maximize batch sizes within available memory."
- Headless browser architecture: A browser running without a GUI to render dynamic web content for scraping. "crawl4ai leverages a headless browser architecture (via Playwright) to accurately render and capture dynamic content, including JavaScript-heavy pages."
- Instruction fine-tuning: Supervised tuning to improve a model’s ability to follow user instructions. "combined with targeted instruction fine-tuning"
- Language adaptation: Adapting a pretrained model to perform better in a specific language or domain. "Continued Pre-training for Language Adaptation."
- LLM-as-a-judge: Using a LLM to automatically evaluate outputs instead of human annotators. "This LLM-as-a-judge approach has been shown to correlate well with human evaluations while enabling systematic large-scale assessment."
- LoRA: A parameter-efficient method that injects low-rank adapters to fine-tune LLMs without updating all weights. "We perform continued pre-training on the unsloth/Meta-Llama-3.1-8B base model using Low-Rank Adaptation (LoRA) \cite{hu2021lora}."
- Loss masking: Excluding parts of the input from the loss computation to focus learning on desired outputs. "and applied loss masking to the user instructions to focus learning solely on the response generation."
- Low-rank decomposition matrices: Factorizations with small rank added to model layers to enable efficient adaptation. "LoRA introduces trainable low-rank decomposition matrices into the model's layers, significantly reducing memory requirements and computational costs while maintaining model quality."
- Low-resource NLP: NLP for languages with limited annotated data or pretraining corpora. "low-resource NLP"
- Nastaliq script: A right-to-left Perso-Arabic calligraphic writing style used for Urdu. "right-to-left Nastaliq script"
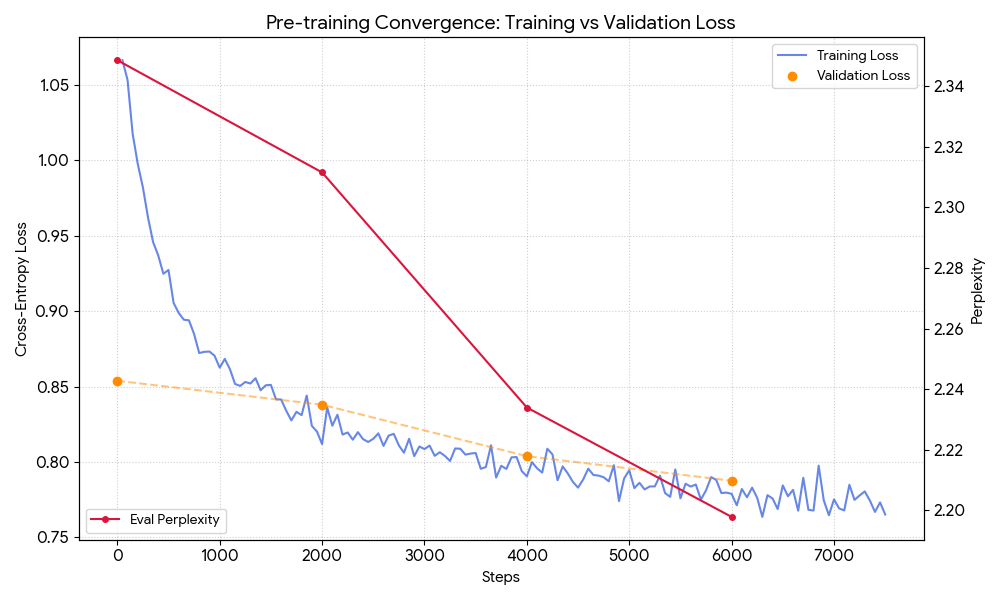
- Perplexity: A measure of how well a LLM predicts a sample; lower values indicate better performance. "The red line displays perplexity on the right y-axis"
- Prompt template: A standardized prompt structure used to format inputs for consistent model behavior. "we utilize a structured prompt template that compares generated model outputs against reference ground-truth responses"
- QLoRA: Fine-tuning method on quantized weights that preserves performance while reducing memory requirements. "a 4-bit quantized version of Qalb using QLoRA techniques \cite{dettmers2024qlora}"
- Quantization (4-bit): Reducing numerical precision of model weights to 4 bits to lower memory and compute. "a 4-bit quantized version of Qalb"
- Replay buffer: A retained dataset used during training to prevent forgetting prior skills or knowledge. "This addition serves as a replay buffer to maintain the model's general reasoning capabilities and prevent the degradation of its original English performance."
- State-of-the-Art (SOTA): The best performance achieved to date on a benchmark or task. "State-of-the-Art (SOTA) performance"
- Token density: The volume of tokens for a language seen during training; affects learned competence. "they lack the sufficient token density needed to model Urdu's unique characteristics"
- Warmup ratio: The fraction of training steps used to gradually increase the learning rate from zero. "employing a cosine learning rate schedule with a warmup ratio of 0.05."
Practical Applications
Practical, real-world applications of Qalb (Urdu LLM) and its methodology
Below are actionable use cases derived from the paper’s findings, methods, and innovations, grouped by deployment horizon. Each item lists sectors, potential tools/products/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Customer support and helpdesk automation in Urdu — Sectors: telecommunications, banking/fintech, e‑commerce, utilities, travel — Tools/products/workflows: Urdu-first chat/email agents; bilingual (Urdu–English) escalation handoffs; knowledge-base QA in Urdu; IVR back-ends (text layer), ticket triage and summarization; 4-bit on-prem deployment for data-sensitive orgs — Assumptions/dependencies: guardrails for safety and hallucinations; domain RAG pipelines for accuracy; data privacy controls; RTL UI support; evaluation and human-in-the-loop escalation
- Urdu–English translation and localization at scale — Sectors: media, government services, education, NGOs, healthcare — Tools/products/workflows: translation APIs/plugins (CMS, newsroom, LMS, CRM); batch localization pipelines for websites, policy docs, forms, curricula; glossary/terminology control for domain consistency — Assumptions/dependencies: quality assurance for legal/medical text; terminology management; handling of mixed-script and code-switched inputs; OCR for scanned Nastaliq where needed
- Sentiment analysis, topic classification, and content moderation for Urdu — Sectors: social media, news/media platforms, brand monitoring, customer experience — Tools/products/workflows: Urdu-native sentiment dashboards; toxicity/abuse filters; brand reputation monitoring; automated tagging and routing of user-generated content — Assumptions/dependencies: domain calibration to reduce bias; continuous human review for edge cases; clear moderation guidelines in Urdu; handling Roman Urdu and dialectal variation
- Urdu question answering and retrieval-augmented generation (RAG) — Sectors: enterprise knowledge management, public sector portals, higher education — Tools/products/workflows: document ingestion and indexing in Urdu; bilingual search; FAQ assistants for benefits, licensing, and public schemes; course-handout QA for universities — Assumptions/dependencies: high-quality Urdu document stores; effective embeddings for Urdu; robust retrieval (hybrid lexical+semantic); governance for updates and versioning
- Newsroom and content operations — Sectors: media/publishing, marketing — Tools/products/workflows: headline/summary generation, fact-focused rewrites, Urdu copy editing; cross-lingual briefs (English→Urdu and Urdu→English); editorial assistants tuned to outlet style — Assumptions/dependencies: editorial oversight to prevent hallucinations; attribution and plagiarism checks; style guides codified as system prompts
- Government and civic service chatbots in Urdu — Sectors: public administration, municipal services, judiciary information portals — Tools/products/workflows: citizen-facing chat for form filling, eligibility checks, procedure guidance; bilingual form translation; policy summarization in plain Urdu — Assumptions/dependencies: verified sources via RAG; compliance review; accessibility (RTL, low-bandwidth modes); monitoring for misinformation and political neutrality
- Education and tutoring assistants in Urdu — Sectors: K–12, higher education, test prep — Tools/products/workflows: curriculum-aligned Q&A, step-by-step reasoning for math/science in Urdu; assignment feedback; bilingual glossaries for STEM; practice exam generation — Assumptions/dependencies: curricular alignment and pedagogy review; age-appropriate safety filters; teacher-in-the-loop deployment; careful handling of open-ended generation
- Healthcare information and admin support (non-diagnostic) — Sectors: healthcare providers, insurers, NGOs — Tools/products/workflows: discharge/consent translation; appointment/scheduling chat; patient education handouts in Urdu; claims and benefits Q&A — Assumptions/dependencies: strict scope limits (no clinical decision-making); compliance (HIPAA-like regimes where applicable); medical terminology consistency; human oversight
- Domain-adaptive fine-tuning via LoRA on modest hardware — Sectors: SMEs, startups, research labs, NGOs in the Urdu ecosystem — Tools/products/workflows: reproducible pipeline for continued pre-training and SFT using LoRA; organization-specific adapters (banking, telecom, education) trained on a single high-end GPU; adapter swapping per task — Assumptions/dependencies: access to clean, domain data; responsible data governance and licensing; prompt templates adapted to Urdu; continuous evaluation with LLM-as-judge plus human audits
- Edge/on‑prem deployments using 4‑bit quantization — Sectors: regulated industries (finance, healthcare, public sector), rural connectivity contexts — Tools/products/workflows: local inference on workstations/edge servers; offline agents for field operations; data-residency‑compliant deployments — Assumptions/dependencies: suitable hardware (>=1 consumer GPU or capable CPU server); performance–latency trade-offs; private RAG for accuracy; model monitoring
- Urdu NLP research workflows and benchmarking — Sectors: academia, labs, R&D groups — Tools/products/workflows: open benchmarks across seven tasks; LLM-as-judge evaluation protocol replicated for Urdu; dataset curation using crawl4ai pipeline; reproducible training configs on Hugging Face — Assumptions/dependencies: access to the released model/datasets; IRB/ethics for data; periodic human validation to cross-check automated judging
- Compliance and KYC document understanding in Urdu — Sectors: banking/fintech, telecom — Tools/products/workflows: document classification, key-value extraction, form normalization, bilingual summaries for auditors and agents — Assumptions/dependencies: OCR for Nastaliq scans; template variation handling; strict accuracy thresholds; human verification for critical fields
- Agricultural and public information assistants — Sectors: agriculture extension, disaster management, utilities — Tools/products/workflows: Urdu advice bots for crop practices and market prices; bilingual alerts and FAQs for heatwaves/floods; SMS/WhatsApp bot interfaces — Assumptions/dependencies: reliable, up-to-date knowledge bases; low-resource UX; strong safety and scope boundaries; multilingual fallback where data sparse
- Developer and product localization support — Sectors: software, app ecosystems, documentation teams — Tools/products/workflows: Urdu localization of UIs/docs; glossary enforcement; commit-time checks via CI plugins; doc search in Urdu for dev portals — Assumptions/dependencies: developer workflows for RTL; style/glossary management; review loops for technical accuracy
Long-Term Applications
- Voice-native Urdu assistants (end-to-end speech) — Sectors: consumer devices, call centers, automotive, smart home — Tools/products/workflows: full ASR→LLM→TTS stacks with Urdu code-switching; on-device/federated variants for privacy — Assumptions/dependencies: robust Urdu ASR/TTS; latency-optimized inference; background noise robustness; safety alignment for spoken interactions
- High-stakes domain copilots (medical, legal, financial advice) — Sectors: healthcare, legal services, wealth management — Tools/products/workflows: expert-tuned copilots that cite sources; verified RAG over clinical guidelines/laws/regulations; continuous post-deployment auditing — Assumptions/dependencies: rigorous fine-tuning with vetted corpora; outcome-based validation; liability and regulatory frameworks; calibrated uncertainty and abstention behavior
- Code-switching and dialect-aware Urdu LLMs — Sectors: social platforms, education, media analytics — Tools/products/workflows: robust processing of Roman Urdu and regional dialects; mixed Urdu–English generation with register control — Assumptions/dependencies: curated dialectal datasets; normalization pipelines; evaluation sets covering code-switching; bias and fairness audits for dialect coverage
- Multilingual South Asian LLMs leveraging shared scripts and morphology — Sectors: public sector, NGOs, regional platforms — Tools/products/workflows: adaptation of Qalb methodology to Pashto, Sindhi, Punjabi, Saraiki; shared subword vocabularies and multi-task adapters — Assumptions/dependencies: high-quality corpora per language; script/orthography harmonization; cross-lingual evaluation; data governance across jurisdictions
- Urdu-native safety, alignment, and red-teaming frameworks — Sectors: platform safety, regulatory tech, enterprise governance — Tools/products/workflows: Urdu safety classifiers (toxicity, harassment, political persuasion); culturally aware refusal policies; adversarial test suites in Urdu — Assumptions/dependencies: annotated safety datasets in Urdu; human red teams; ongoing drift monitoring; alignment research for low-resource contexts
- Legal and administrative modernization (end-to-end Urdu e‑governance) — Sectors: government, judiciary, public records — Tools/products/workflows: Urdu-first drafting aids for laws/policies; bilingual canonical records; searchable archives with summarization and cross-references — Assumptions/dependencies: digitization and OCR of legacy Nastaliq; provenance tracking; strong auditability and version control; public transparency norms
- Educational content generation and adaptive learning in Urdu — Sectors: EdTech, public education systems — Tools/products/workflows: curriculum-mapped lesson planning; adaptive quizzes with difficulty calibration; teacher dashboards with mastery insights — Assumptions/dependencies: efficacy studies and pilots; psychometric validation; bias checks across regions/genders; integration with local curricula standards
- Enterprise-grade Urdu RAG platforms with verifiable reasoning — Sectors: banking, energy, manufacturing, pharma — Tools/products/workflows: citation-grounded answers; provenance chains; evaluation harnesses for Urdu with SLAs on accuracy/latency — Assumptions/dependencies: document lifecycle governance; scalable retrieval infrastructure; robust monitoring (hallucination detection); contractually defined quality metrics
- Urdu misinformation detection, fact-checking, and election integrity tooling — Sectors: media, civil society, election commissions — Tools/products/workflows: claim extraction and ranking; cross-lingual evidence retrieval; explainable verdicts; rapid response workflows for moderators — Assumptions/dependencies: partnerships with fact-checkers; high-quality reference corpora; minimization of political bias; transparent error reporting
- Data pipelines and corpora marketplaces for low-resource languages — Sectors: AI tooling, data vendors, research consortia — Tools/products/workflows: crawl4ai-based data collection kits; de-duplication and quality filters for RTL scripts; licensing-cleared corpora and LoRA adapters — Assumptions/dependencies: rights management; community curation; sustainability models; standardized benchmarks and datasheets for datasets/models
- Hardware-efficient Urdu AI on mobile and low-connectivity settings — Sectors: consumer apps, field operations, humanitarian tech — Tools/products/workflows: distilled 1–3B Urdu models; hybrid on-device + edge inference; caching strategies for offline use — Assumptions/dependencies: model compression/distillation research; memory/latency constraints on mobile; privacy-preserving telemetry; UX for intermittent networks
Notes on cross-cutting assumptions and risks
- Model quality: While Qalb is SOTA in Urdu across seven tasks, sensitive uses require RAG, human oversight, and domain-specific evaluation.
- Safety: Urdu-native safety/guardrail layers are essential to mitigate biases, stereotypes, and hallucinations.
- Data governance: Scraped content must be legally licensed where required; privacy and consent are critical in regulated domains.
- Evaluation: LLM-as-judge correlates with human ratings but should be complemented by human audits, especially for high-stakes contexts.
- RTL and script issues: Robust handling of Nastaliq, OCR for scanned documents, and Roman Urdu normalization may be necessary depending on the workflow.
- Availability: Applications assume the public release of the model, datasets, and training configs as indicated in the paper.
Collections
Sign up for free to add this paper to one or more collections.