- The paper establishes an auditable runtime that logs every action, enabling transparent study-level reasoning across uncurated 3D medical imaging studies.
- It introduces MedFlow-Bench, a comprehensive benchmark that evaluates agent performance in multi-sequence brain MRI and lung CT/PET scenarios using viewer-only, tool-use, and open-method tracks.
- The study reveals that while current VLMs show modest success in native viewing, their performance degrades with tool integration due to limitations in spatial grounding and control precision.
MedOpenClaw: Auditable Medical Imaging Agents Reasoning over Uncurated Full Studies
Motivation and Contributions
Conventional vision-LLM (VLM) evaluation in medical imaging has been limited to curated, static 2D image settings, omitting the essential complexity of clinical workflows where diagnostic decisions require navigating uncurated 3D volumes and synthesizing evidence across modalities and sequences. MedOpenClaw addresses this gap by providing an auditable runtime for agentic interaction with medical viewers (e.g., 3D Slicer) and exposing a transparent trace of every action for regulatory review and reproducibility. Complementing this, MedFlow-Bench systematically benchmarks full-study medical imaging reasoning, encompassing multi-sequence brain MRI and lung CT/PET scenarios across viewer-only, tool-use, and open-method tracks.
The paper’s central contribution is the establishment of a reproducible, auditable framework for evaluating agentic medical imaging workflows, shifting from static-image recognition to transparent, study-level inspection and reasoning. Notably, initial experiments reveal that current VLM agents achieve moderate success in viewer-native study navigation, but experience critical performance degradation when utilizing professional toolkits—rooted in limitations of spatial grounding and precise control.
MedOpenClaw Runtime: Architecture and Auditability
MedOpenClaw is implemented as an explicitly bounded API layer interfacing between backbone VLMs and clinical viewers without altering source code or expanding attack surfaces. The runtime architecture separates actions into three abstraction layers: primitive viewer operations (slice scrolling, windowing), evidence-capturing (bookmarks, masks, measurements), and expert-tool integration (e.g., MONAI-based segmentation). All external actions through MedOpenClaw are logged, including command arguments, resulting viewer states, and generated artifacts, ensuring reconstructable diagnostic trajectories and full auditability.
The contract restricts callable operations to well-documented REST endpoints and prohibits arbitrary code execution, constraining agent behavior to clinically vetted operations. This bounded surface mirrors the radiologist workflow and provides a foundation for downstream clinician-facing assistants such as MedCopilot, capable of automating complex viewer interactions while maintaining transparent, auditable traces.
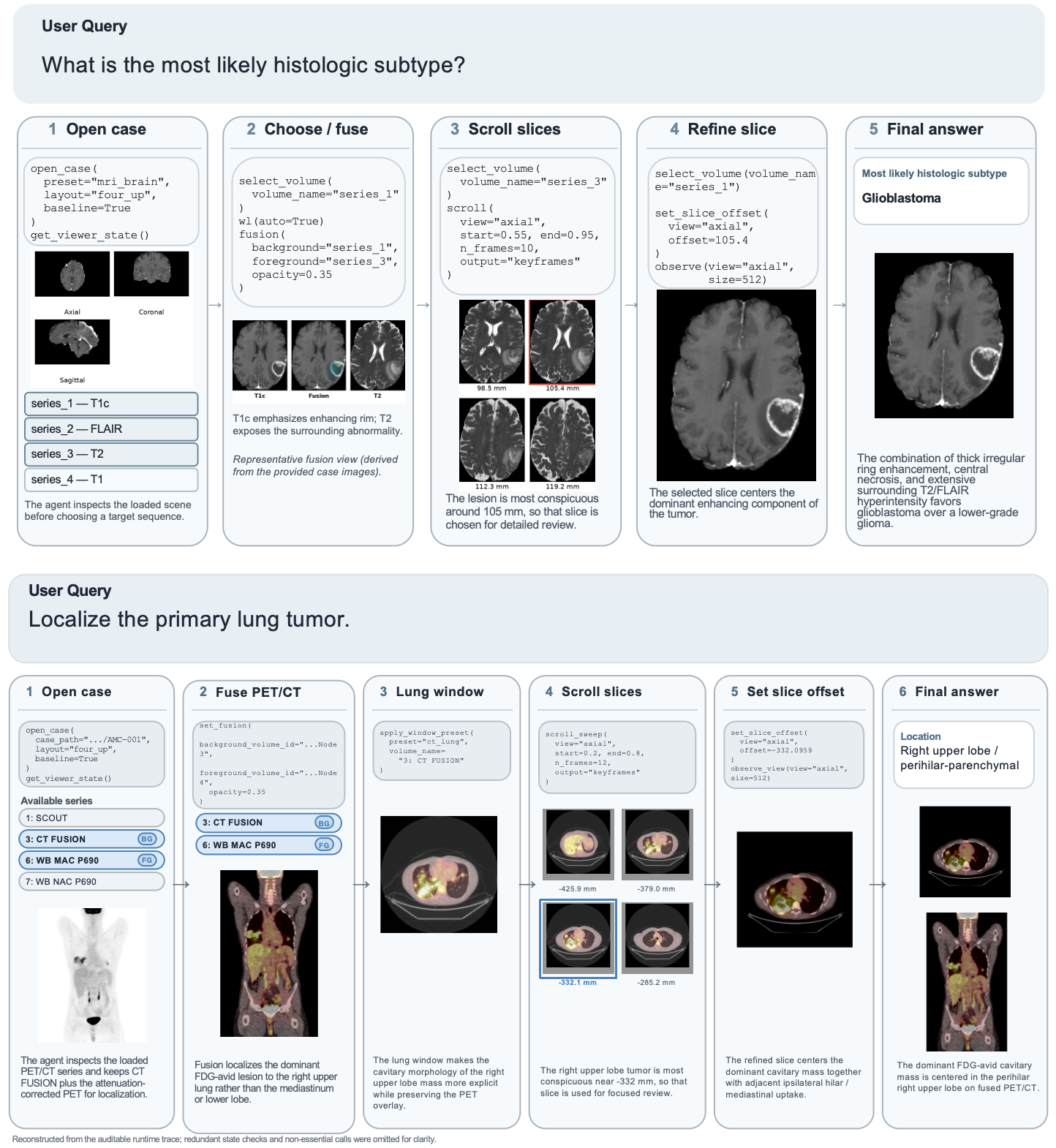
Figure 1: Representative execution traces in Brain MRI and Lung CT/PET, illustrating auditable decision workflows and evidence artifacts under Tool-Use.
MedFlow-Bench: Study-Level Benchmarking
MedFlow-Bench enables rigorous evaluation of agentic medical imaging reasoning across two core modules—multi-sequence brain MRI and lung CT/PET—built upon public datasets and standardized episode definitions. Each episode features comprehensive volumetric inputs, task prompts, restricted action spaces per track, and canonical answer schemas. Evaluation protocols are stratified into MCQ and open-ended settings, leveraging LLM-based judges for answer robustness.
MedFlow-Bench distinguishes itself from legacy benchmarks by supporting:
- Full-study interactive access
- Cross-imaging modality cases
- Sequential active exploration
- Differential diagnosis
- Requirement for agentic execution
Three distinct tracks are defined:
- Viewer-Only: Models interact exclusively with primitive tools, isolating visual navigation and synthesis.
- Tool-Use: Unrestricted access to expert modules tests model capacity for advanced tool invocation and integration.
- Open-Method: External pipelines, including foundation models or custom compressors, are benchmarked for universal comparison.
Experimental Results and Strong Claims
Baseline evaluations of GPT-5.4, Gemini 3.1 Pro, and other state-of-the-art VLMs demonstrate meaningful study-level reasoning in the viewer-native track, with Gemini 3.1 Pro achieving a case-level accuracy of 0.63 in Brain MRI. Performance in Lung CT/PET’s Tumor Location task yields moderate scores (0.46 for GPT-5.4), while Histopathological Grade remains near random-chance baseline, underscoring the intrinsic complexity of study-level tasks.
Crucially, activating segmentation toolpacks in the Tool-Use track paradoxically degrades agent performance: GPT-5.4’s Brain MRI accuracy drops from 0.61 to 0.57, and Lung CT/PET from 0.32 to 0.27, despite robust underlying algorithmic performance. This exposes a bottleneck in spatial grounding; VLMs fail to generate anatomically precise spatial coordinates for tool invocation, producing erroneous artifacts and misleading downstream reasoning.
Implications for Clinical Practice and AI Research
The introduction of MedOpenClaw and MedFlow-Bench signals a paradigm shift toward clinically realistic, auditable agentic benchmarks. Key takeaways include:
- Tool-Use Paradox: Access to expert clinical tools does not equate to superior outcomes unless spatial grounding and control precision are addressed at the VLM level.
- Auditability: Transparent execution traces are foundational for regulatory compliance and clinical trust, eliminating opaque, black-box decision processes.
- Workflow Alignment: Benchmark action spaces directly reflect clinical radiologist practices, facilitating transfer to real-world assistant systems and human-in-the-loop scenarios.
Future Developments and Roadmap
Subsequent expansions will:
- Scale MedFlow-Bench to diverse imaging modalities and longitudinal data
- Integrate multi-turn conversational tracks and comprehensive EHR synthesis tasks
- Enhance the tool ecosystem with specialized algorithms for spatial grounding assessment
Resolving the spatial control bottleneck is pivotal for unlocking robust, tool-augmented clinical workflows and for further aligning agentic systems with diagnostic expertise.
Conclusion
MedOpenClaw and MedFlow-Bench establish a new standard for auditable, study-level evaluation of medical imaging agents. Current VLMs exhibit competent viewer-native reasoning but lack reliable spatial grounding for clinically realistic tool-use. Bridging this gap is essential for deploying autonomous and assistant agents in medical practice, ensuring transparent evidence gathering, reproducibility, and actionable clinical insights (2603.24649).

