- The paper introduces an open-source medical LLM built on Llama-2 with 70B parameters through targeted continued pretraining on 48.1B tokens from high-quality medical sources.
- The methodology combines efficient distributed training using Nvidia's Megatron-LM toolkit with techniques like activation recompute and FlashAttention to optimize performance.
- Results highlight competitive accuracy on benchmarks such as MedQA, surpassing several commercial LLMs and encouraging further open collaboration in medical AI.
"MEDITRON-70B: Scaling Medical Pretraining for LLMs"
Introduction
The paper "MEDITRON-70B: Scaling Medical Pretraining for LLMs" systematically outlines the development of Meditron, a large-scale medical LLM based on Llama-2, enhanced for medical domains with 7B and 70B parameters. This open-source solution aims to bridge the gap between the capabilities of proprietary LLMs like GPT-4 and accessible models tailored for medical purposes. The model leverages continued pretraining techniques on a carefully curated medical corpus, assessing its performance through standard benchmarks designed for medical reasoning.
Model Architecture
Meditron builds upon Llama-2 architecture, enhanced through Nvidia's Megatron-LM toolkit for distributed training. This infrastructure ensures that Meditron can scale efficiently across GPUs in a cluster, employing techniques such as Data Parallelism (DP), Pipeline Parallelism (PP), and Tensor Parallelism (TP). The adapted use of Activation Recompute and FlashAttention reduces memory footprint and speeds up training iterations.
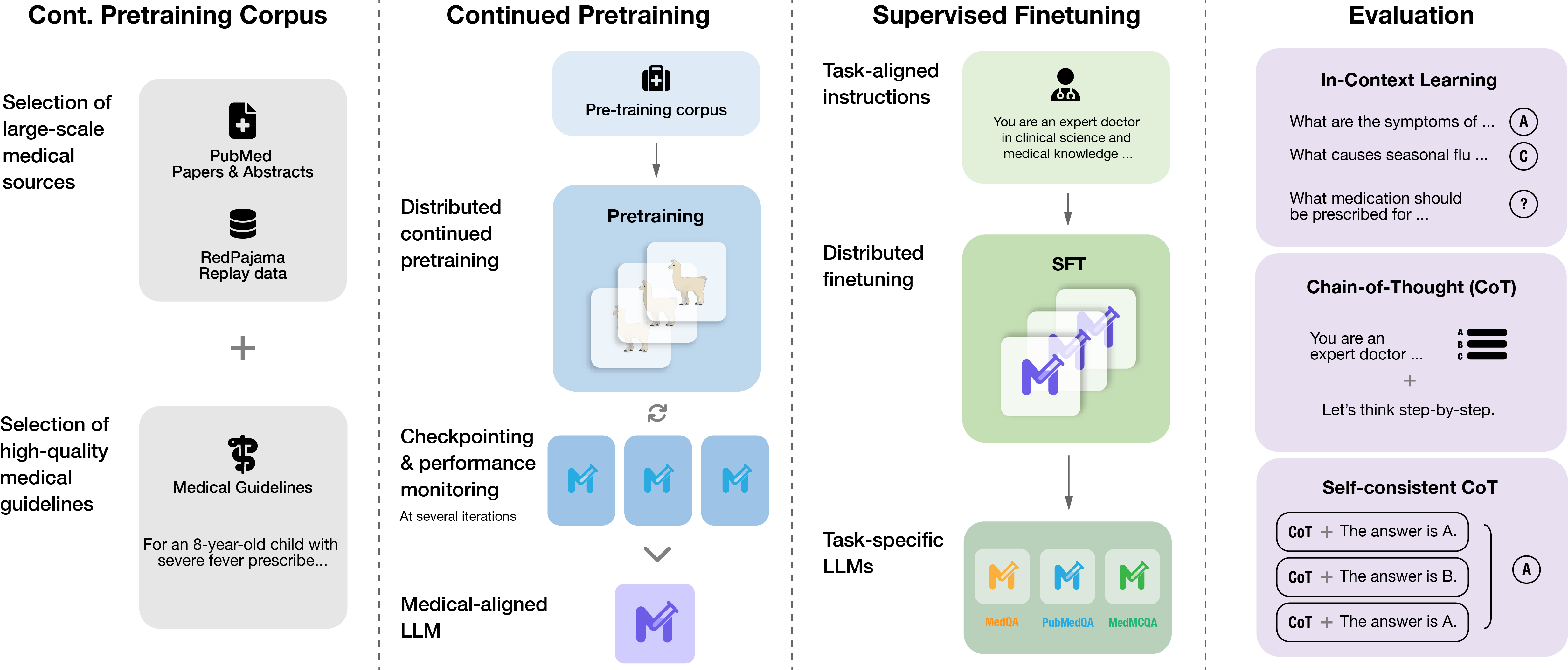
Figure 1: Meditron. The complete pipeline for continued pretraining, supervised finetuning, and evaluation of Meditron-7B and Meditron-70B.
Training Data
Meditron's pretraining corpus, GAP-replay, includes 48.1B tokens sourced from high-quality medical datasets. The core datasets consist of clinical guidelines, PubMed articles, abstracts, and replay data from general domains to prevent catastrophic forgetting. This comprehensive dataset stands out for its rigorous curation process, ensuring the high quality expected of clinical guidelines and practice recommendations.
Pretraining Methodology
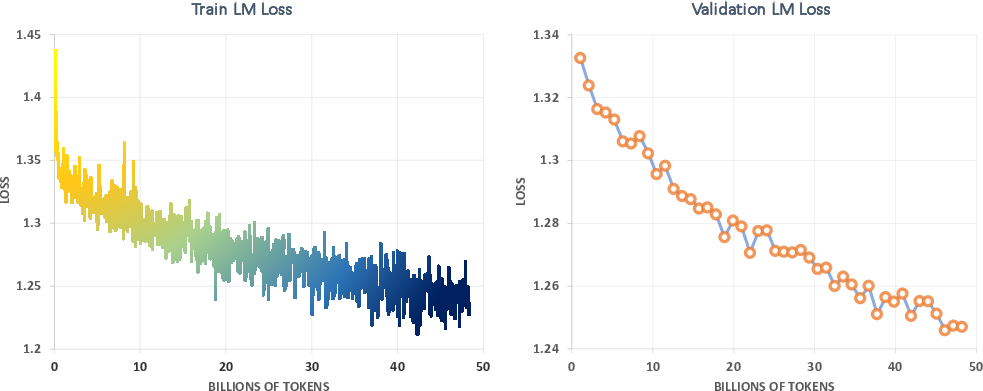
Figure 2: Training and validation loss during continued pretraining of the Meditron-70B model.
The pretraining strategy incorporated a mixture of medical literature and general domain content (Replay). Meditron exhibits enhanced proficiency in language modeling through a stringent validation process, confirming steady loss reduction as depicted in the training curves.
Results on Medical Benchmarks
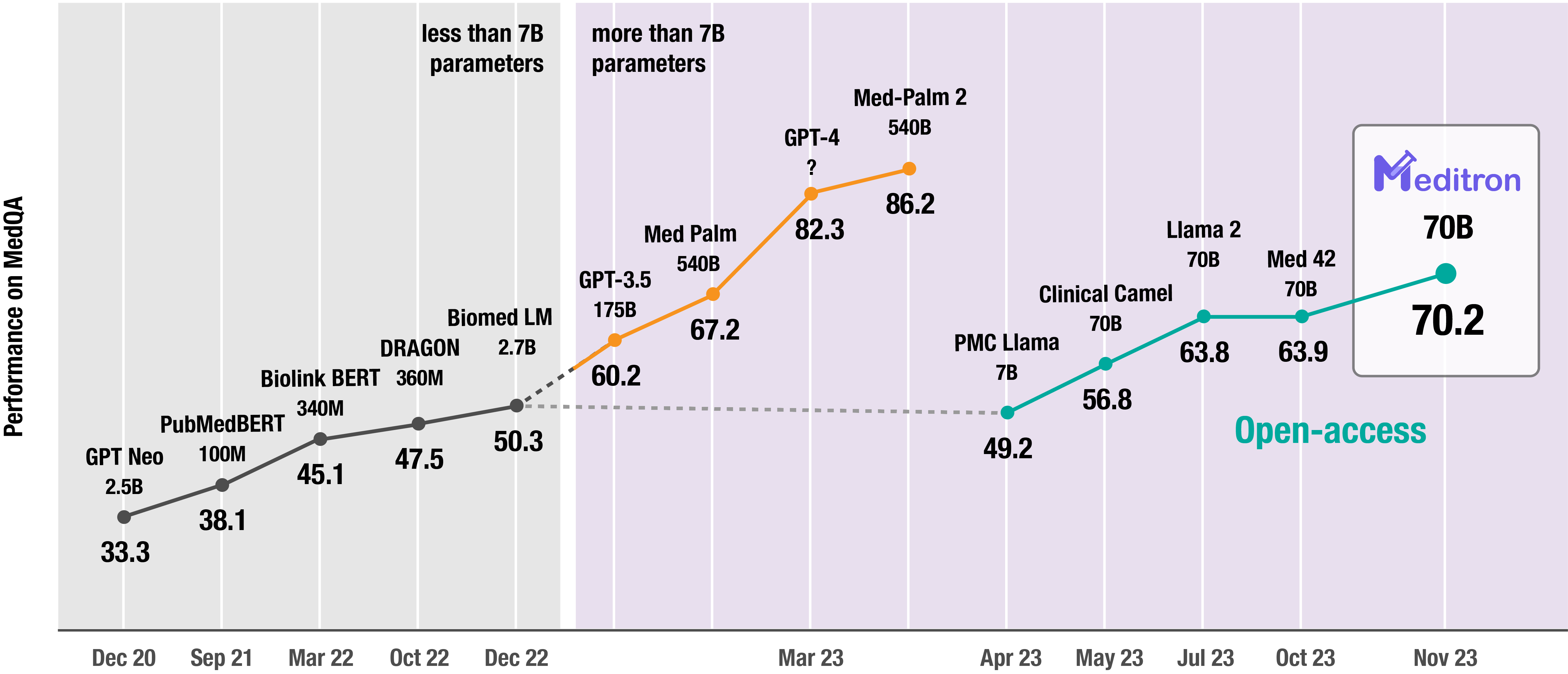
Figure 3: Meditron-70B's performance on MedQA Meditron-70B achieves an accuracy of 70.2\% on USMLE-style questions in the MedQA (4 options) dataset.
Meditron-70B achieves competitive performance on benchmarks like MedQA, MedMCQA, PubMedQA, and MMLU-Medical. Notably, Meditron surpasses several commercial LLMs, including GPT-3.5, and approaches within 5-10% of GPT-4 and Med-PaLM-2 on demanding tasks, affirming its robustness in medical reasoning.
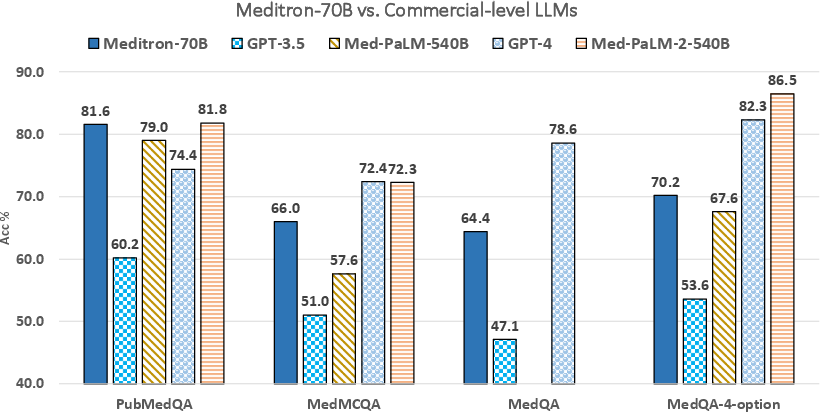
Figure 4: Main results of Meditron against commercial LLMs. We compare Meditron-70B's performance on four medical benchmarks against larger commercial LLMs.
Deployment Implications
Meditron's open-source release includes pretrained models and corresponding datasets, encouraging community engagement and further development in domain-specific areas. This accessibility aims to lower entry barriers and spur innovation in medical AI applications through open collaboration.
Conclusion
Meditron represents a significant step forward in making large-scale medical LLMs accessible by providing a strong, open-source alternative to proprietary models. The continued pretraining on meticulously chosen medical data showcases the potential for specialized LLMs in critical domains like healthcare, paving the way for future research on safety, ethics, and utility in medical AI applications.