- The paper introduces Medmarks, the largest open-source LLM benchmark suite that assesses 30 diverse medical tasks using both verifiable and open-ended protocols.
- The paper details robust grading methodologies, including dual LLM-Judge systems and weighted mean win rate metrics, to ensure accurate model performance evaluation.
- The paper reveals that API-based models outperform open-weight variants in efficiency and reasoning, while domain-specific finetuning yields significant performance gains.
Medmarks: A Comprehensive Open-Source LLM Benchmark Suite for Medical Tasks
Introduction
"Medmarks: A Comprehensive Open-Source LLM Benchmark Suite for Medical Tasks" (2605.01417) introduces the largest fully open-source evaluation suite for assessing the clinical and medical task capabilities of LLMs. The motivation is rooted in the observed limitations of extant benchmarks: saturation of multiple-choice Q&A datasets, restricted or inaccessible datasets (e.g., via proprietary constraints), and underrepresentation of critical clinical tasks such as open-ended reasoning or EHR integration. Medmarks aims to systematically and reproducibly address these gaps by supporting both verifiable, automatable metrics and open-ended LLM-as-a-Judge protocols across a breadth of publicly accessible medical datasets.
Benchmark Construction and Methodology
Medmarks organizes 30 medical benchmarks into two principal subsets:
- Medmarks-V: Verifiable benchmarks including multiple-choice question answering (MCQA), medical calculations, and tasks with deterministic checking.
- Medmarks-OE: Open-ended tasks where grading uses LLM-as-a-Judge, accounting for semantic alignment and clinical appropriateness.
Multiple task formats are supported, including question answering, information extraction, EHR interaction, numerical calculation, and agentic multi-turn environments. Eight datasets possess defined train/test splits (Medmarks-T), facilitating reinforcement learning (RL) environments with precise reward functions for model post-training.
Grading methods are rigorously adapted. For MCQA, the paper details robust normalization and grading logic, mitigating errors due to output formatting drift. Open-ended tasks take a dual LLM-Judge approach, pairing a main evaluation model (e.g., GPT-5 mini) with a secondary model (e.g., Gemini 3 Flash Preview or Grok 4.1 Fast) to minimize judge-specific bias and leverage advancements in small/medium LLMs for judgment.
Model Coverage and Evaluation Protocol
Medmarks evaluates 61 models covering 71 configurations, including recent proprietary APIs and open-weight baselines, quantized variants, and domain-specific finetunes. All models are assessed with their recommended generation settings. Evaluation leverages the verifiers environment library, enabling composable, reward-specified RL environments for compatible datasets.
A weighted mean win rate (MWR) is used as the principal aggregation metric, which penalizes or rewards models relative to their performance against all others on each dataset, weighted by dataset size.
Key Results
The top-performing models on Medmarks are dominated by recent “frontier” reasoning APIs such as Gemini 3 Pro Preview, GPT-5.1, and Grok 4, with win rates in the $0.63$–$0.66$ range (Medmarks-V). Open-weight large models like GLM 4.7 and Qwen3 235B-A22B Thinking closely follow but exhibit lower token and cost efficiency.
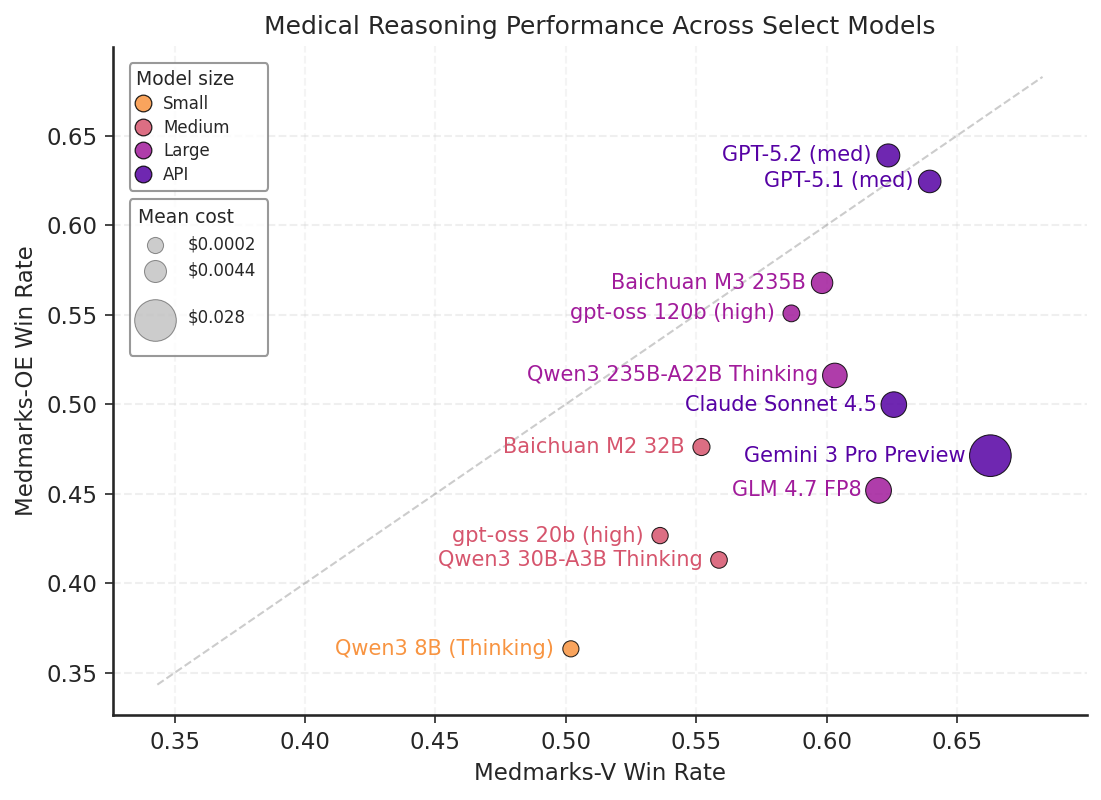
Figure 1: Results on Medmarks-V and Medmarks-OE for subset of models evaluated on both benchmarks.
Notably, API-based models show strong performance on both verifiable and open-ended benchmarks, but some (e.g., Gemini 3 Pro Preview) experience a relative drop for open-ended tasks.
Scaling Laws and Domain Finetuning
Larger models generally outperform their smaller counterparts, especially on mid-to-high difficulty tasks. Exceptions exist; for instance, Qwen3 reasoning models are notably “parameter efficient,” outperforming models with larger parameter counts on multiple tasks.
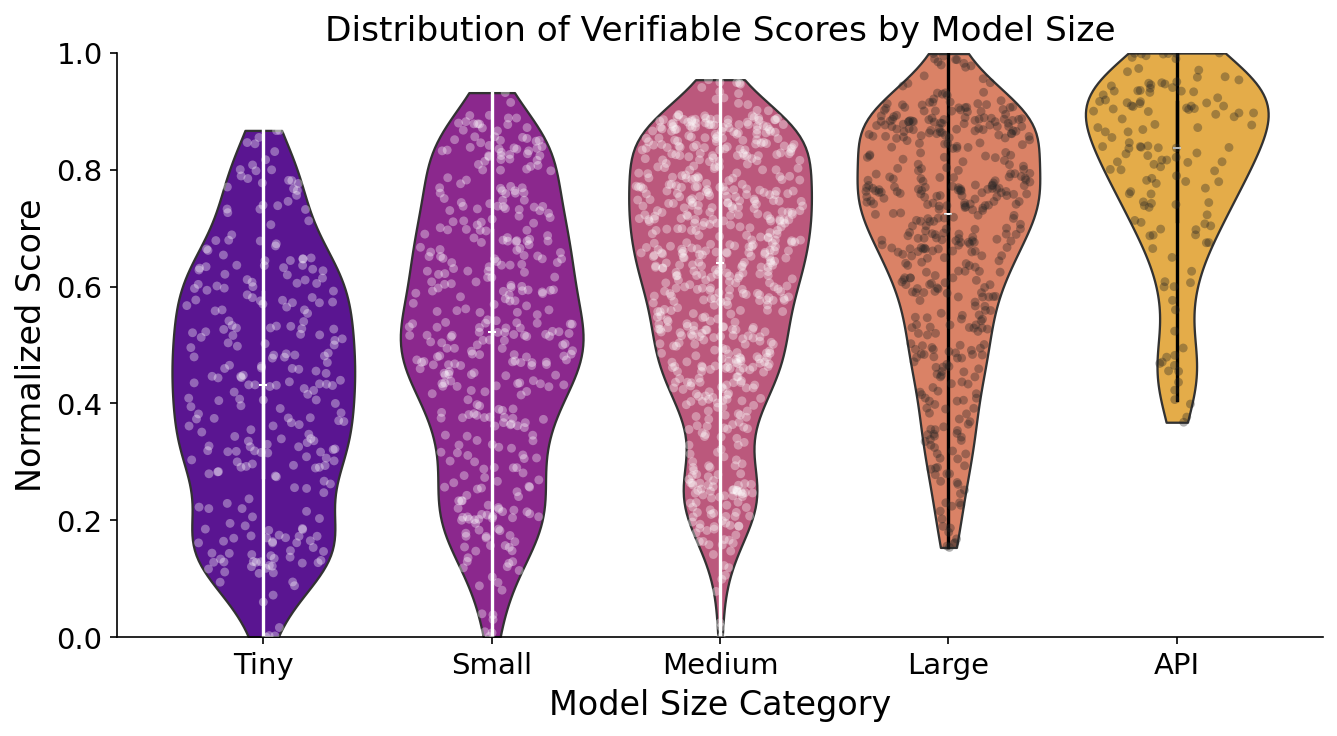
Figure 2: Distribution of model scores based on model category for the Medmarks-V subset.
Domain-specific finetuning confers clear, quantifiable benefits; specialized variants (e.g., MedGemma, AntAngelMed, Baichuan M2/M3) typically achieve higher MWRs relative to their general-purpose base models.
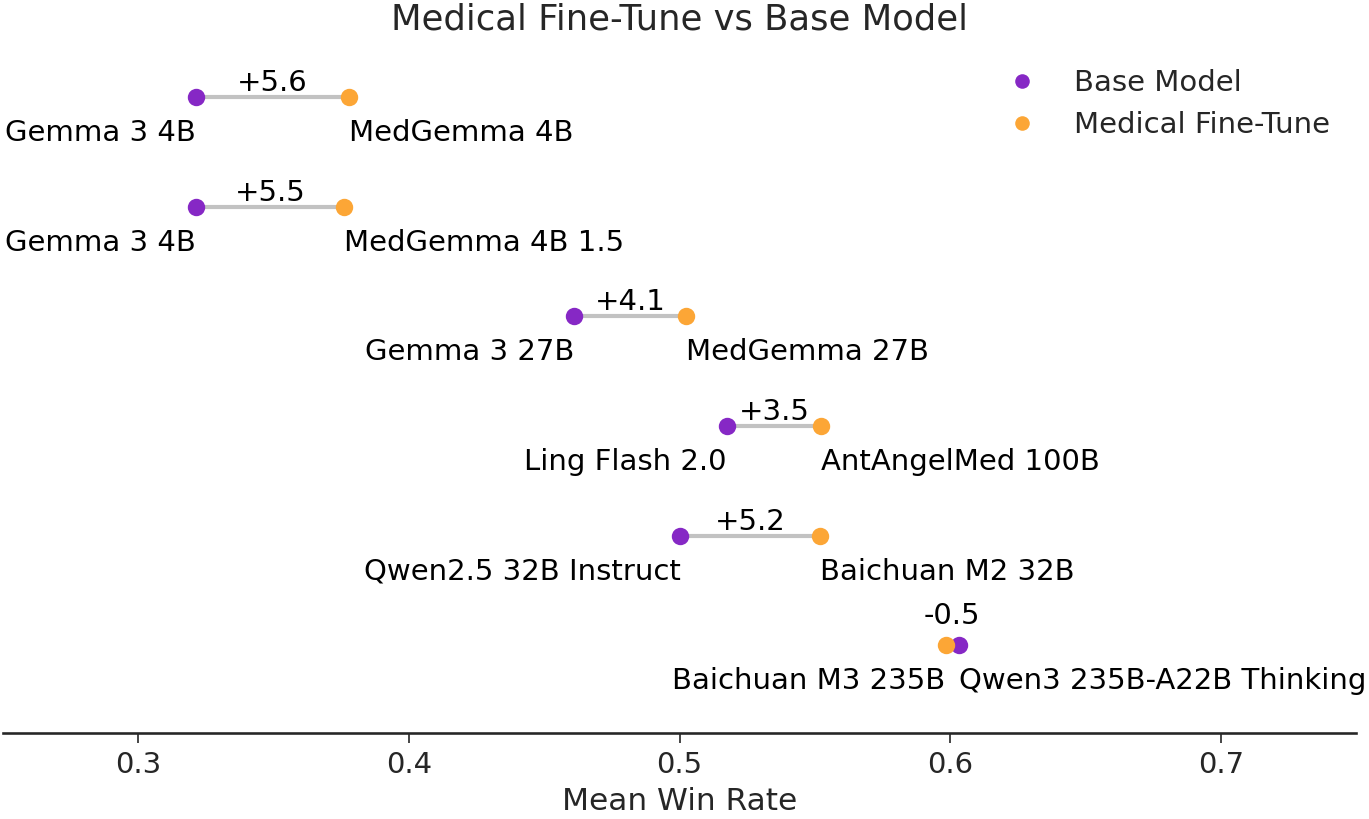
Figure 3: Win Rate change between medical finetunes and their base models.
There are cases where newer generalist models match or slightly surpass medical-specific finetunes within particular subclasses, hinting at rapid cross-domain generalization in frontier LLMs.
Cost and Computational Efficiency
A crucial empirical finding is that state-of-the-art proprietary models are up to 5× more token-efficient than their open-weight counterparts at equivalent performance levels. Token budgets for large open-weight models (e.g., GLM-4.7 FP8, Qwen3 235B) are significantly higher for each output, leading to increased inference costs and reduced deployability.
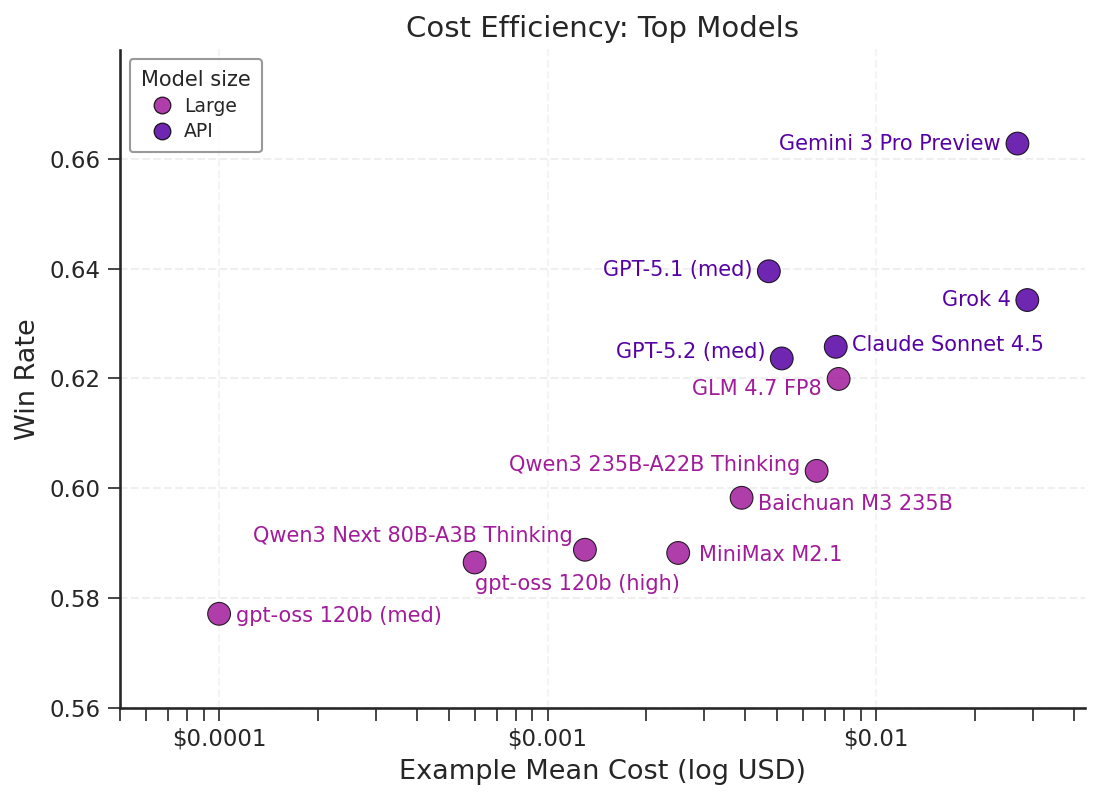
Figure 4: A scatter plot of the mean win rate on Medmarks-V by cost for the model APIs evaluated.
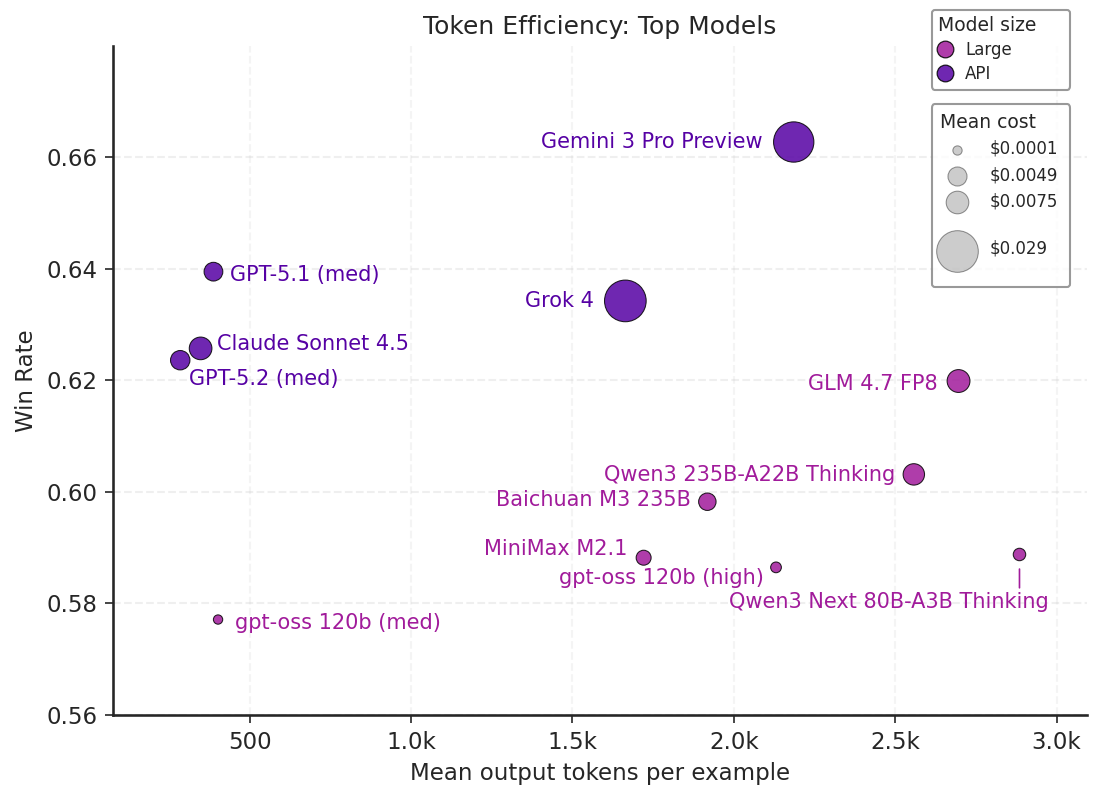
Figure 5: A scatter plot of mean win rate on Medmarks-V by tokens for top 12 models evaluated.
Open-weight models, while competitive in final accuracy, are yet to close the efficiency gap necessary for realistic clinical deployment.
Effects of Reasoning Post-Training
Reasoning-focused post-training regimes (“thinking models”) generally improve accuracy and robustness, but certain families (e.g., Ministral) show degraded performance, implicating possible issues in reasoning data quality, reward hacking, or catastrophic forgetting.
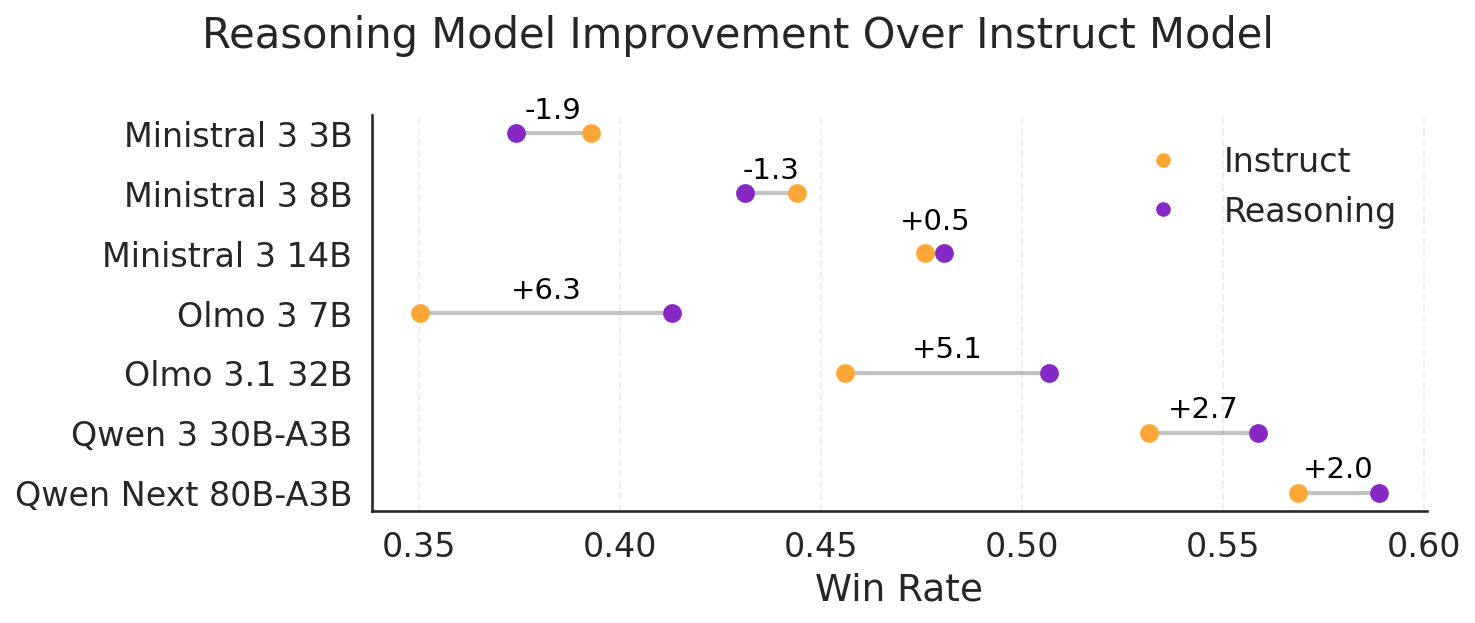
Figure 6: Win Rate change between instruction and reasoning models.
Increasing the explicit “reasoning effort” (e.g., higher allowed reasoning token budgets in gpt-oss) correlates with near-monotonic performance gains, although an overthinking penalty exists with excessive generation when failing on difficult questions.
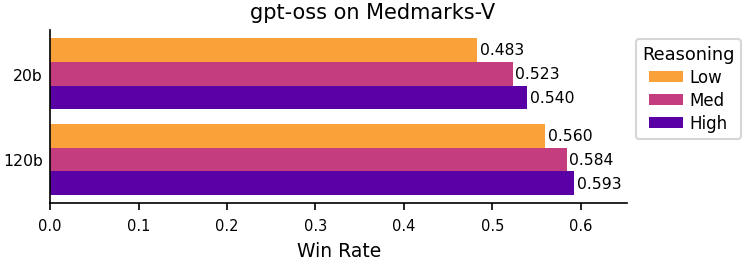
Figure 7: Win Rate change between gpt-oss reasoning level.
Token-length analysis corroborates that models on average “overthink” failed tasks, generating more tokens for incorrect than for correct answers.
Quantization and Robustness
Quantization to 8-bit precision introduces minimal performance penalties, but more aggressive 4-bit quantization yields consistent accuracy losses across tasks and models.
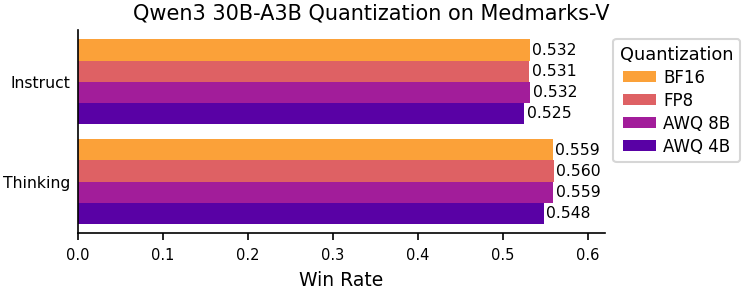
Figure 8: Win Rate change between quantized models.
Prompt Order Sensitivity and Distractibility
Choice order in MCQA can elicit order bias, particularly in smaller models and even certain frontier models (e.g., Grok 4). Introducing an additional distractor choice causes substantial performance degradation, indicating residual distractibility even in modern architectures.
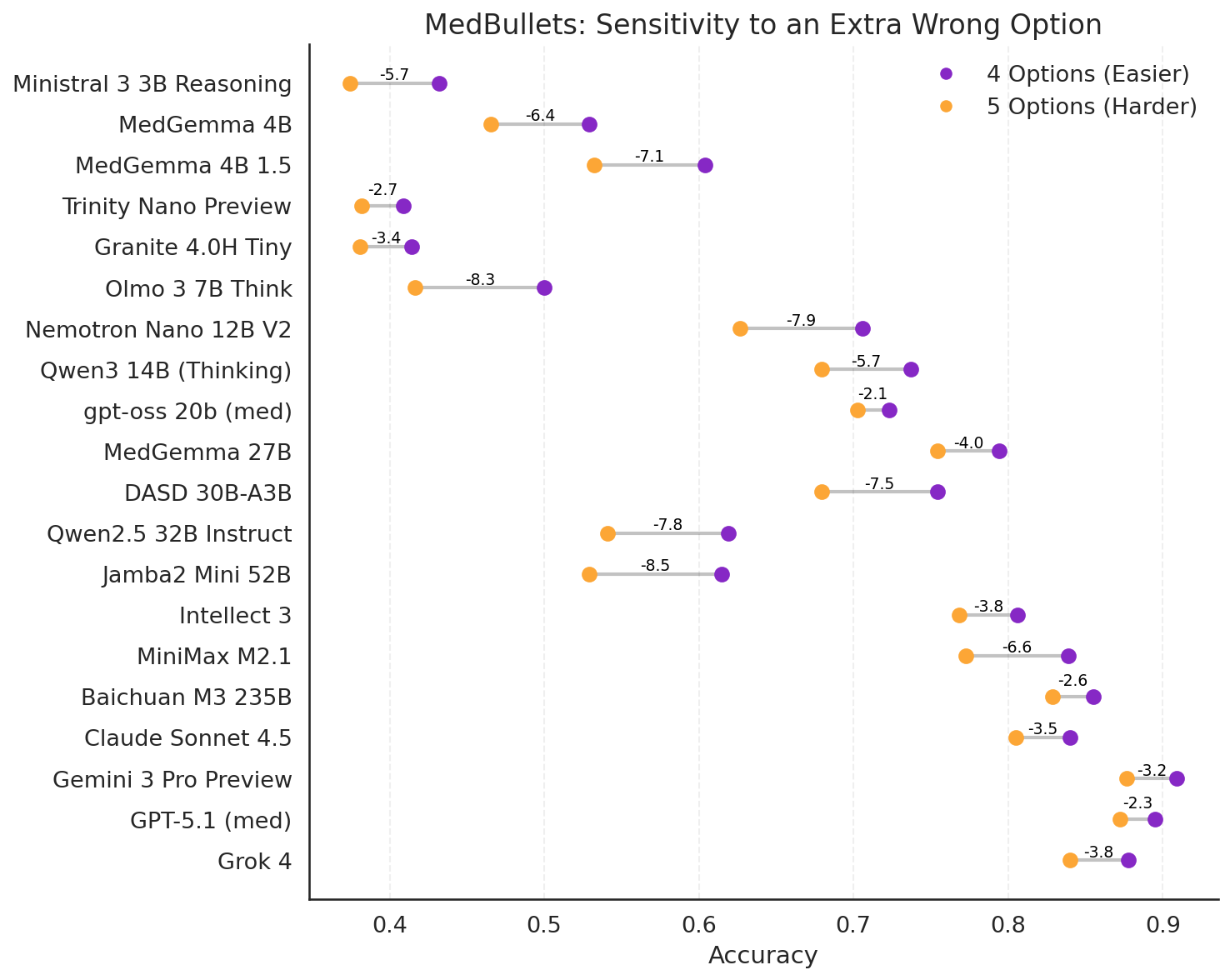
Figure 9: Comparing model performance with and without an extra option on the Medbullets benchmark.
RL-based Post-Training
The Medmarks-T subset demonstrates utility as RL training environments for medical-specific post-training. Preliminary results with Qwen-3-4B-Instruct trained on MedCalc-Bench, MedMCQA, and MedCaseReasoning show clear improvements in both training reward and test accuracy, supporting the use of Medmarks for RL research.
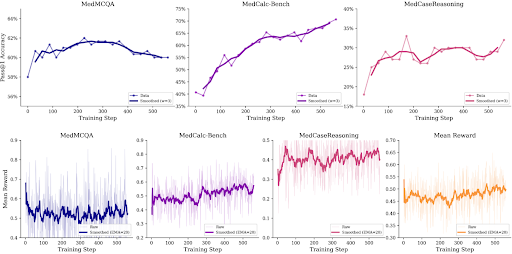
Figure 10: Test accuracy and training reward for Qwen-3-4B-Instruct-0725 trained on MedCalc-Bench, MedMCQA, and MedCaseReasoning over the course of training for 330 steps.
Discussion and Implications
Medmarks establishes an open, extensible, and fine-grained benchmark for the systematic, replicable evaluation of LLMs in clinical and medical settings. The broad inclusion of verifiable, open-ended, and agentic tasks across a large model pool addresses saturation and overfitting seen in prior medical QA datasets, and enables nuanced differentiation between knowledge recall, reasoning capacity, and cost efficiency.
Key practical implications:
- Medical-specific post-training is not obsolete; clear Pareto gains are attainable relative to generalist models, especially in smaller architectures and open-weight models.
- Token and cost efficiency, not just raw accuracy, are differentiating factors for regulatory- and practice-ready LLM selection.
- High-order tasks (e.g., expert-level reasoning, multi-hop EHR tasks, hallucination detection) remain unsolved, leaving significant headroom for both research and engineering advances.
Theoretical implications include:
- The persistent gap between open-weight and API models on efficiency grounds signals distinct advances in optimization, compression, or RLHF not yet fully captured by the public LLM ecosystem.
- The evident prompt and order sensitivity—even in large models—necessitates deeper study into prompt universalization/robustification for safety-critical applications.
- The compositional approach (verifiers environments as RL environments) paves the way for unified pipelines of medical RL, few-shot adaptation, and rapidly iterated post-training.
Future Directions
Medmarks currently prioritizes text-only, single-turn, and structured clinical reasoning tasks. Integrating multimodal data (e.g., radiology, EHR images), multi-agent reasoning, fairness and bias auditing, and expanding open-ended conversational agentic capabilities are important next steps for the community. Medmarks' open structure and growing leaderboard will facilitate these advancements.
Conclusion
Medmarks delivers a robust, open-source foundation for the evaluation and evolution of LLMs in medicine, bridging existing gaps in benchmark coverage, reproducibility, and RL-based research. Its quantitative analyses reveal the leading capabilities and limitations of modern LLMs, as well as emergent challenges for safe, efficient, and clinically useful deployment. The suite provides immediate utility as a reproducible benchmarking standard and a development platform for future medical LLM innovations.
Reference: “Medmarks: A Comprehensive Open-Source LLM Benchmark Suite for Medical Tasks” (2605.01417)

